",
"service_tier": "flex"
}'
```
#### API request timeouts
Due to slower processing speeds with Flex processing, request timeouts are more likely. Here are some considerations for handling timeouts:
- **Default timeout**: The default timeout is **10 minutes** when making API requests with an official OpenAI SDK. You may need to increase this timeout for lengthy prompts or complex tasks.
- **Configuring timeouts**: Each SDK will provide a parameter to increase this timeout. In the Python and JavaScript SDKs, this is `timeout` as shown in the code samples above.
- **Automatic retries**: The OpenAI SDKs automatically retry requests that result in a `408 Request Timeout` error code twice before throwing an exception.
## Resource unavailable errors
Flex processing may sometimes lack sufficient resources to handle your requests, resulting in a `429 Resource Unavailable` error code. **You will not be charged when this occurs.**
Consider implementing these strategies for handling resource unavailable errors:
- **Retry requests with exponential backoff**: Implementing exponential backoff is suitable for workloads that can tolerate delays and aims to minimize costs, as your request can eventually complete when more capacity is available. For implementation details, see [this cookbook](https://developers.openai.com/cookbook/examples/how_to_handle_rate_limits?utm_source=chatgpt.com#retrying-with-exponential-backoff).
- **Retry requests with standard processing**: When receiving a resource unavailable error, implement a retry strategy with standard processing if occasional higher costs are worth ensuring successful completion for your use case. To do so, set `service_tier` to `auto` in the retried request, or remove the `service_tier` parameter to use the default mode for the project.
---
# Frontend prompt instructions
These instructions target GPT-5.5, but many of the patterns apply to other model versions as well.
```prompt
## Frontend guidance
You follow these instructions when building applications with a frontend experience:
### Build with empathy
- If working with an existing design or given a design framework in context, you pay careful attention to existing conventions and ensure that what you build is consistent with the frameworks used and design of the existing application.
- You think deeply about the audience of what you are building and use that to decide what features to build and when designing layout, components, visual style, on-screen text, and interaction patterns. Using your application should feel rich and sophisticated.
- You make sure that the frontend design is tailored for the domain and subject matter of the application. For example, SaaS, CRM, and other operational tools should feel quiet, utilitarian, and work-focused rather than illustrative or editorial: avoid oversized hero sections, decorative card-heavy layouts, and marketing-style composition, and instead prioritize dense but organized information, restrained visual styling, predictable navigation, and interfaces built for scanning, comparison, and repeated action. A game can be more illustrative, expressive, animated, and playful.
- You make sure that common workflows within the app are ergonomic, efficient, and comprehensive, so the user of your application can seamlessly navigate in and out of different views and pages in the application.
### Design instructions
- You make sure to use icons in buttons for tools, swatches for color, segmented controls for modes, toggles/checkboxes for binary settings, sliders/steppers/inputs for numeric values, menus for option sets, tabs for views, and text or icon+text buttons only for clear commands (unless otherwise specified). Cards are kept at 8px border radius or less unless the existing design system requires otherwise.
- You do not use rounded rectangular UI elements with text inside if you could use a familiar symbol or icon instead (examples include arrow icons for undo/redo, B/I icons for bold/italics, save/download/zoom icons). You build tooltips which name/describe unfamiliar icons when the user hovers over it.
- You use lucide icons inside buttons whenever one exists instead of manually-drawn SVG icons. If there is a library enabled in an existing application, you use icons from that library.
- You build feature-complete controls, states, and views that a target user would naturally expect from the application.
- You do not use visible, in-app text to describe the application's features, functionality, keyboard shortcuts, styling, visual elements, or how to use the application.
- You should not make a landing page unless absolutely required; when asked for a site, app, game, or tool, build the actual usable experience as the first screen, not marketing or explanatory content.
- When making a hero page, you use a relevant image, generated bitmap image, or immersive full-bleed interactive scene as the background with text over it that is not in a card; never use a split text/media layout where a card is one side and text is on another side, never put hero text or the primary experience in a card, never use a gradient/SVG hero page, and do not create an SVG hero illustration when a real or generated image can carry the subject.
- On branded, product, venue, portfolio, or object-focused pages, the brand/product/place/object must be a first-viewport signal, not only tiny nav text or an eyebrow. Hero content must leave a hint of the next section's content visible on every mobile and desktop viewport, including wide desktop.
- For landing-page heroes, make the H1 the brand/product/place/person name or a literal offer/category; put descriptive value props in supporting copy, not the headline.
- Websites and games must use visual assets. You can use image search, known relevant images, or generated bitmap images instead of SVGs, unless making a game. Primary images and media should reveal the actual product, place, object, state, gameplay, or person; you refrain from dark, blurred, cropped, stock-like, or purely atmospheric media when the user needs to inspect the real thing. For highly specific game assets you use custom SVG/Three.js/etc.
- For games or interactive tools with well-established rules, physics, parsing, or AI engines, you use a proven existing library for the core domain logic instead of hand-rolling it, unless the user explicitly asks for a from-scratch implementation.
- You use Three.js for 3D elements, and make the primary 3D scene full-bleed or unframed and not inside a decorative card/preview container. Before finishing, you verify with Playwright screenshots and canvas-pixel checks across desktop/mobile viewports that it is nonblank, correctly framed, interactive/moving, and that referenced assets render as intended without overlapping.
- You do not put UI cards inside other cards. Do not style page sections as floating cards. Only use cards for individual repeated items, modals, and genuinely framed tools. Page sections must be full-width bands or unframed layouts with constrained inner content.
- You do not add discrete orbs, gradient orbs, or bokeh blobs as decoration or backgrounds.
- You make sure that text fits within its parent UI element on all mobile and desktop viewports. Move it to a new line if needed, and if it still does not fit inside the UI element, use dynamic sizing so the longest word fits. Text must also not occlude preceding or subsequent content. Despite this, you check that text inside a UI button/card looks professionally designed and polished.
- Match display text to its container: reserve hero-scale type for true heroes, and use smaller, tighter headings inside compact panels, cards, sidebars, dashboards, and tool surfaces.
- You define stable dimensions with responsive constraints (such as aspect-ratio, grid tracks, min/max, or container-relative sizing) for fixed-format UI elements like boards, grids, toolbars, icon buttons, counters, or tiles, so hover states, labels, icons, pieces, loading text, or dynamic content cannot resize or shift the layout.
- You do not scale font size with viewport width. Letter spacing must be 0, not negative.
- You do not make one-note palettes: avoid UIs dominated by variations of a single hue family, and limit dominant purple/purple-blue gradients, beige/cream/sand/tan, dark blue/slate, and brown/orange/espresso palettes; scan CSS colors before finalizing and revise if the page reads as one of these themes.
- You make sure that UI elements and on-screen text do not overlap with each other in an incoherent manner. This is extremely important because overlap can lead to a jarring user experience.
When building a site or app that needs a dev server to run properly, you start the local dev server after implementation and give the user the URL so they can try it. If there's already a server on that port, you use another one. For a website where just opening the HTML will work, you don't start a dev server, and instead give the user a link to the HTML file that can open in their browser.
```
---
# Function calling
**Function calling** (also known as **tool calling**) provides a powerful and flexible way for OpenAI models to interface with external systems and access data outside their training data. This guide shows how you can connect a model to data and actions provided by your application. We'll show how to use function tools (defined by a JSON schema) and custom tools which work with free form text inputs and outputs.
If your application has many functions or large schemas, you can pair function calling with [tool search](https://developers.openai.com/api/docs/guides/tools-tool-search) to defer rarely used tools and load them only when the model needs them. Only `gpt-5.4` and later models support `tool_search`.
## How it works
Let's begin by understanding a few key terms about tool calling. After we have a shared vocabulary for tool calling, we'll show you how it's done with some practical examples.
Tools - functionality we give the model
A **function** or **tool** refers in the abstract to a piece of functionality that we tell the model it has access to. As a model generates a response to a prompt, it may decide that it needs data or functionality provided by a tool to follow the prompt's instructions.
You could give the model access to tools that:
- Get today's weather for a location
- Access account details for a given user ID
- Issue refunds for a lost order
Or anything else you'd like the model to be able to know or do as it responds to a prompt.
When we make an API request to the model with a prompt, we can include a list of tools the model could consider using. For example, if we wanted the model to be able to answer questions about the current weather somewhere in the world, we might give it access to a `get_weather` tool that takes `location` as an argument.
Tool calls - requests from the model to use tools
A **function call** or **tool call** refers to a special kind of response we can get from the model if it examines a prompt, and then determines that in order to follow the instructions in the prompt, it needs to call one of the tools we made available to it.
If the model receives a prompt like "what is the weather in Paris?" in an API request, it could respond to that prompt with a tool call for the `get_weather` tool, with `Paris` as the `location` argument.
Tool call outputs - output we generate for the model
A **function call output** or **tool call output** refers to the response a tool generates using the input from a model's tool call. The tool call output can either be structured JSON or plain text, and it should contain a reference to a specific model tool call (referenced by `call_id` in the examples to come).
To complete our weather example:
- The model has access to a `get_weather` **tool** that takes `location` as an argument.
- In response to a prompt like "what's the weather in Paris?" the model returns a **tool call** that contains a `location` argument with a value of `Paris`
- The **tool call output** might return a JSON object (e.g., `{"temperature": "25", "unit": "C"}`, indicating a current temperature of 25 degrees), [Image contents](https://developers.openai.com/api/docs/guides/images), or [File contents](https://developers.openai.com/api/docs/guides/file-inputs).
We then send all of the tool definition, the original prompt, the model's tool call, and the tool call output back to the model to finally receive a text response like:
```
The weather in Paris today is 25C.
```
Functions versus tools
- A function is a specific kind of tool, defined by a JSON schema. A function definition allows the model to pass data to your application, where your code can access data or take actions suggested by the model.
- In addition to function tools, there are custom tools (described in this guide) that work with free text inputs and outputs.
- There are also [built-in tools](https://developers.openai.com/api/docs/guides/tools) that are part of the OpenAI platform. These tools enable the model to [search the web](https://developers.openai.com/api/docs/guides/tools-web-search), [execute code](https://developers.openai.com/api/docs/guides/tools-code-interpreter), access the functionality of an [MCP server](https://developers.openai.com/api/docs/guides/tools-remote-mcp), and more.
### The tool calling flow
Tool calling is a multi-step conversation between your application and a model via the OpenAI API. The tool calling flow has five high level steps:
1. Make a request to the model with tools it could call
1. Receive a tool call from the model
1. Execute code on the application side with input from the tool call
1. Make a second request to the model with the tool output
1. Receive a final response from the model (or more tool calls)
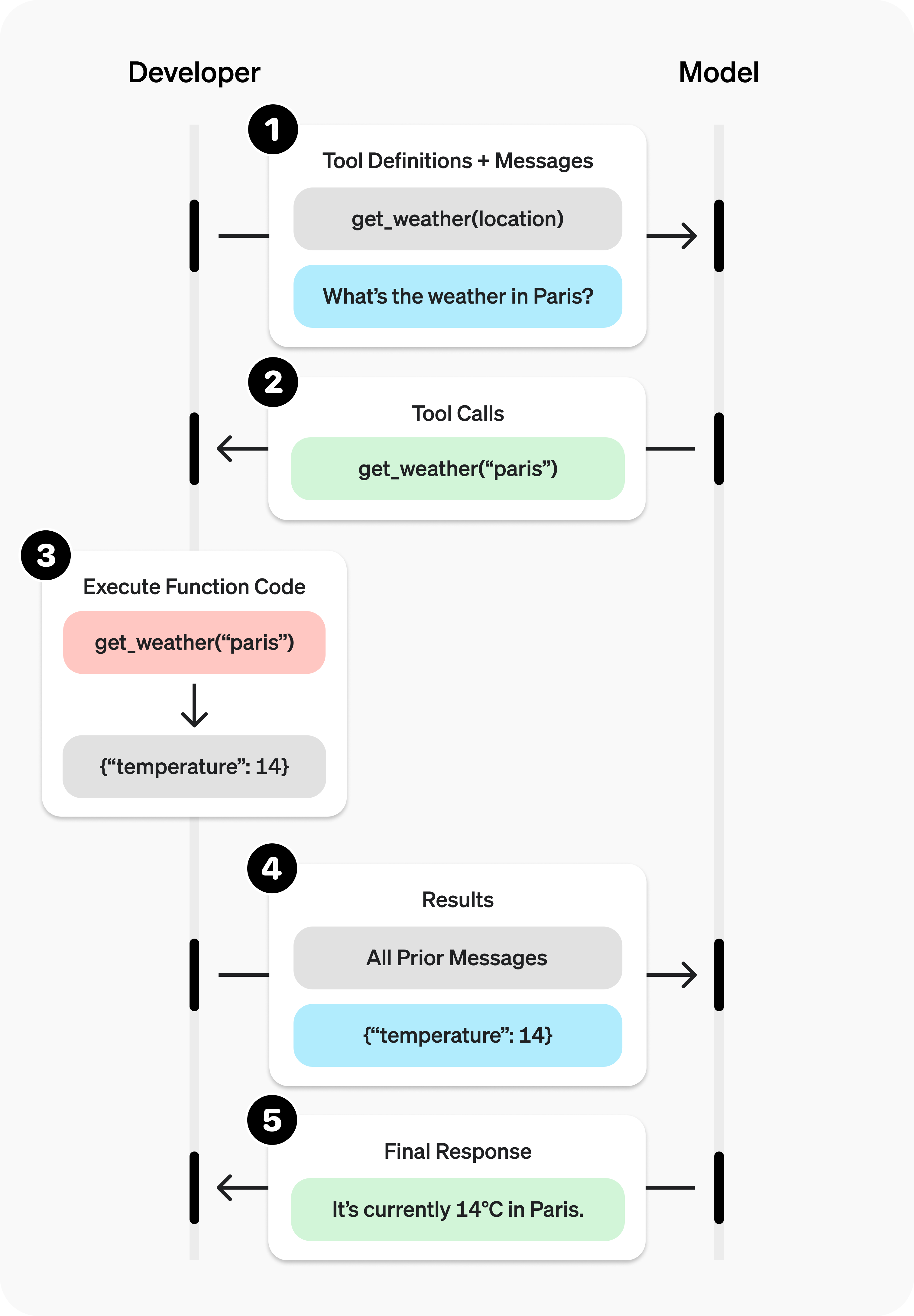
## Function tool example
Let's look at an end-to-end tool calling flow for a `get_horoscope` function that gets a daily horoscope for an astrological sign.
Note that for reasoning models like GPT-5 or o4-mini, any reasoning items
returned in model responses with tool calls must also be passed back with tool
call outputs.
## Defining functions
Functions are usually declared in the `tools` parameter of each API request. With [tool search](https://developers.openai.com/api/docs/guides/tools-tool-search), your application can also load deferred functions later in the interaction. Either way, each callable function uses the same schema shape. A function definition has the following properties:
| Field | Description |
| ------------- | ------------------------------------------------------------------------------- |
| `type` | This should always be `function` |
| `name` | The function's name (e.g. `get_weather`) |
| `description` | Details on when and how to use the function |
| `parameters` | [JSON schema](https://json-schema.org/) defining the function's input arguments |
| `strict` | Whether to enforce strict mode for the function call |
Here is an example function definition for a `get_weather` function
```json
{
"type": "function",
"name": "get_weather",
"description": "Retrieves current weather for the given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
},
"units": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "Units the temperature will be returned in."
}
},
"required": ["location", "units"],
"additionalProperties": false
},
"strict": true
}
```
Because the `parameters` are defined by a [JSON schema](https://json-schema.org/), you can leverage many of its rich features like property types, enums, descriptions, nested objects, and, recursive objects.
## Defining namespaces
Use namespaces to group related tools by domain, such as `crm`, `billing`, or `shipping`. Namespaces help organize similar tools and are especially useful when the model must choose between tools that serve different systems or purposes, such as one search tool for your CRM and another for your support ticketing system.
```json
{
"type": "namespace",
"name": "crm",
"description": "CRM tools for customer lookup and order management.",
"tools": [
{
"type": "function",
"name": "get_customer_profile",
"description": "Fetch a customer profile by customer ID.",
"parameters": {
"type": "object",
"properties": {
"customer_id": { "type": "string" }
},
"required": ["customer_id"],
"additionalProperties": false
}
},
{
"type": "function",
"name": "list_open_orders",
"description": "List open orders for a customer ID.",
"defer_loading": true,
"parameters": {
"type": "object",
"properties": {
"customer_id": { "type": "string" }
},
"required": ["customer_id"],
"additionalProperties": false
}
}
]
}
```
## Tool search
If you need to give the model access to a large ecosystem of tools, you can defer loading some or all of those tools with `tool_search`. The `tool_search` tool lets the model search for relevant tools, add them to the model context, and then use them. Only `gpt-5.4` and later models support it. Read the [tool search guide](https://developers.openai.com/api/docs/guides/tools-tool-search) to learn more.
### Best practices for defining functions
1. **Write clear and detailed function names, parameter descriptions, and instructions.**
- **Explicitly describe the purpose of the function and each parameter** (and its format), and what the output represents.
- **Use the system prompt to describe when (and when not) to use each function.** Generally, tell the model _exactly_ what to do.
- **Include examples and edge cases**, especially to rectify any recurring failures. (**Note:** Adding examples may hurt performance for [reasoning models](https://developers.openai.com/api/docs/guides/reasoning).)
- **For deferred tools, put detailed guidance in the function description and keep the namespace description concise.** The namespace helps the model choose what to load; the function description helps it use the loaded tool correctly.
1. **Apply software engineering best practices.**
- **Make the functions obvious and intuitive**. ([principle of least surprise](https://en.wikipedia.org/wiki/Principle_of_least_astonishment))
- **Use enums** and object structure to make invalid states unrepresentable. (e.g. `toggle_light(on: bool, off: bool)` allows for invalid calls)
- **Pass the intern test.** Can an intern/human correctly use the function given nothing but what you gave the model? (If not, what questions do they ask you? Add the answers to the prompt.)
1. **Offload the burden from the model and use code where possible.**
- **Don't make the model fill arguments you already know.** For example, if you already have an `order_id` based on a previous menu, don't have an `order_id` param – instead, have no params `submit_refund()` and pass the `order_id` with code.
- **Combine functions that are always called in sequence.** For example, if you always call `mark_location()` after `query_location()`, just move the marking logic into the query function call.
1. **Keep the number of initially available functions small for higher accuracy.**
- **Evaluate your performance** with different numbers of functions.
- **Aim for fewer than 20 functions available at the start of a turn** at any one time, though this is just a soft suggestion.
- **Use tool search** to defer large or infrequently used parts of your tool surface instead of exposing everything up front.
1. **Leverage OpenAI resources.**
- **Generate and iterate on function schemas** in the [Playground](https://platform.openai.com/playground).
- **Consider [fine-tuning](https://developers.openai.com/api/docs/guides/fine-tuning) to increase function calling accuracy** for large numbers of functions or difficult tasks. ([cookbook](https://developers.openai.com/cookbook/examples/fine_tuning_for_function_calling))
### Token Usage
Under the hood, functions are injected into the system message in a syntax the model has been trained on. This means callable function definitions count against the model's context limit and are billed as input tokens. If you run into token limits, we suggest limiting the number of functions loaded up front, shortening descriptions where possible, or using [tool search](https://developers.openai.com/api/docs/guides/tools-tool-search) so deferred tools are loaded only when needed.
It is also possible to use [fine-tuning](https://developers.openai.com/api/docs/guides/fine-tuning#fine-tuning-examples) to reduce the number of tokens used if you have many functions defined in your tools specification.
## Handling function calls
When the model calls a function, you must execute it and return the result. Since model responses can include zero, one, or multiple calls, it is best practice to assume there are several.
The response `output` array contains an entry with the `type` having a value of `function_call`. Each entry with a `call_id` (used later to submit the function result), `name`, and JSON-encoded `arguments`.
If you are using [tool search](https://developers.openai.com/api/docs/guides/tools-tool-search), you may also see `tool_search_call` and `tool_search_output` items before a `function_call`. Once the function is loaded, handle the function call in the same way shown here.
In the example above, we have a hypothetical `call_function` to route each call. Here’s a possible implementation:
### Formatting results
The result you pass in the `function_call_output` message should typically be a string, where the format is up to you (JSON, error codes, plain text, etc.). The model will interpret that string as needed.
For functions that return images or files, you can pass an [array of image or file objects](https://developers.openai.com/api/docs/api-reference/responses/create#responses_create-input-input_item_list-item-function_tool_call_output-output) instead of a string.
If your function has no return value (e.g. `send_email`), simply return a string that indicates success or failure. (e.g. `"success"`)
### Incorporating results into response
After appending the results to your `input`, you can send them back to the model to get a final response.
## Additional configurations
### Tool choice
By default the model will determine when and how many tools to use. You can force specific behavior with the `tool_choice` parameter.
1. **Auto:** (_Default_) Call zero, one, or multiple functions. `tool_choice: "auto"`
1. **Required:** Call one or more functions.
`tool_choice: "required"`
1. **Forced Function:** Call exactly one specific function.
`tool_choice: {"type": "function", "name": "get_weather"}`
1. **Allowed tools:** Restrict the tool calls the model can make to a subset of
the tools available to the model.
**When to use allowed_tools**
You might want to configure an `allowed_tools` list in case you want to make only
a subset of tools available across model requests, but not modify the list of tools you pass in, so you can maximize savings from [prompt caching](https://developers.openai.com/api/docs/guides/prompt-caching).
```json
"tool_choice": {
"type": "allowed_tools",
"mode": "auto",
"tools": [
{ "type": "function", "name": "get_weather" },
{ "type": "function", "name": "search_docs" }
]
}
}
```
You can also set `tool_choice` to `"none"` to imitate the behavior of passing no functions.
When you use tool search, `tool_choice` still applies to the tools that are currently callable in the turn. This is most useful after you load a subset of tools and want to constrain the model to that subset.
### Parallel function calling
Parallel function calling is not possible when using [built-in
tools](https://developers.openai.com/api/docs/guides/tools).
The model may choose to call multiple functions in a single turn. You can prevent this by setting `parallel_tool_calls` to `false`, which ensures exactly zero or one tool is called.
**Note:** Currently, if you are using a fine tuned model and the model calls multiple functions in one turn then [strict mode](#strict-mode) will be disabled for those calls.
**Note for `gpt-4.1-nano-2025-04-14`:** This snapshot of `gpt-4.1-nano` can sometimes include multiple tools calls for the same tool if parallel tool calls are enabled. It is recommended to disable this feature when using this nano snapshot.
### Strict mode
Setting `strict` to `true` will ensure function calls reliably adhere to the function schema, instead of being best effort. We recommend always enabling strict mode.
Under the hood, strict mode works by leveraging our [structured outputs](https://developers.openai.com/api/docs/guides/structured-outputs) feature and therefore introduces a couple requirements:
1. `additionalProperties` must be set to `false` for each object in the `parameters`.
1. All fields in `properties` must be marked as `required`.
You can denote optional fields by adding `null` as a `type` option (see example below).
If you send `strict: true` and your schema does not meet the requirements above,
the request will be rejected with details about the missing constraints. If you
omit `strict`, the default depends on the API: Responses requests will
normalize your schema into strict mode (for example, by setting
`additionalProperties: false` and marking all fields as required), which can
make previously optional fields mandatory, while Chat Completions requests
remain non-strict by default. To opt out of strict mode in Responses and keep
non-strict, best-effort function calling, explicitly set `strict: false`.
All schemas generated in the
[playground](https://platform.openai.com/playground) have strict mode enabled.
While we recommend you enable strict mode, it has a few limitations:
1. Some features of JSON schema are not supported. (See [supported schemas](https://developers.openai.com/api/docs/guides/structured-outputs?context=with_parse#supported-schemas).)
Specifically for fine tuned models:
1. Schemas undergo additional processing on the first request (and are then cached). If your schemas vary from request to request, this may result in higher latencies.
2. Schemas are cached for performance, and are not eligible for [zero data retention](https://developers.openai.com/api/docs/models#how-we-use-your-data).
## Streaming
Streaming can be used to surface progress by showing which function is called as the model fills its arguments, and even displaying the arguments in real time.
Streaming function calls is very similar to streaming regular responses: you set `stream` to `true` and get different `event` objects.
Instead of aggregating chunks into a single `content` string, however, you're aggregating chunks into an encoded `arguments` JSON object.
When the model calls one or more functions an event of type `response.output_item.added` will be emitted for each function call that contains the following fields:
| Field | Description |
| -------------- | ------------------------------------------------------------------------------------------------------------ |
| `response_id` | The id of the response that the function call belongs to |
| `output_index` | The index of the output item in the response. This represents the individual function calls in the response. |
| `item` | The in-progress function call item that includes a `name`, `arguments` and `id` field |
Afterwards you will receive a series of events of type `response.function_call_arguments.delta` which will contain the `delta` of the `arguments` field. These events contain the following fields:
| Field | Description |
| -------------- | ------------------------------------------------------------------------------------------------------------ |
| `response_id` | The id of the response that the function call belongs to |
| `item_id` | The id of the function call item that the delta belongs to |
| `output_index` | The index of the output item in the response. This represents the individual function calls in the response. |
| `delta` | The delta of the `arguments` field. |
Below is a code snippet demonstrating how to aggregate the `delta`s into a final `tool_call` object.
When the model has finished calling the functions an event of type `response.function_call_arguments.done` will be emitted. This event contains the entire function call including the following fields:
| Field | Description |
| -------------- | ------------------------------------------------------------------------------------------------------------ |
| `response_id` | The id of the response that the function call belongs to |
| `output_index` | The index of the output item in the response. This represents the individual function calls in the response. |
| `item` | The function call item that includes a `name`, `arguments` and `id` field. |
## Custom tools
Custom tools work in much the same way as JSON schema-driven function tools. But rather than providing the model explicit instructions on what input your tool requires, the model can pass an arbitrary string back to your tool as input. This is useful to avoid unnecessarily wrapping a response in JSON, or to apply a custom grammar to the response (more on this below).
The following code sample shows creating a custom tool that expects to receive a string of text containing Python code as a response.
Just as before, the `output` array will contain a tool call generated by the model. Except this time, the tool call input is given as plain text.
```json
[
{
"id": "rs_6890e972fa7c819ca8bc561526b989170694874912ae0ea6",
"type": "reasoning",
"content": [],
"summary": []
},
{
"id": "ctc_6890e975e86c819c9338825b3e1994810694874912ae0ea6",
"type": "custom_tool_call",
"status": "completed",
"call_id": "call_aGiFQkRWSWAIsMQ19fKqxUgb",
"input": "print(\"hello world\")",
"name": "code_exec"
}
]
```
### Context-free grammars
A [context-free grammar](https://en.wikipedia.org/wiki/Context-free_grammar) (CFG) is a set of rules that define how to produce valid text in a given format. For custom tools, you can provide a CFG that will constrain the model's text input for a custom tool.
You can provide a custom CFG using the `grammar` parameter when configuring a custom tool. Currently, we support two CFG syntaxes when defining grammars: `lark` and `regex`.
#### Lark CFG
The output from the tool should then conform to the Lark CFG that you defined:
```json
[
{
"id": "rs_6890ed2b6374819dbbff5353e6664ef103f4db9848be4829",
"type": "reasoning",
"content": [],
"summary": []
},
{
"id": "ctc_6890ed2f32e8819daa62bef772b8c15503f4db9848be4829",
"type": "custom_tool_call",
"status": "completed",
"call_id": "call_pmlLjmvG33KJdyVdC4MVdk5N",
"input": "4 + 4",
"name": "math_exp"
}
]
```
Grammars are specified using a variation of [Lark](https://lark-parser.readthedocs.io/en/stable/index.html). Model sampling is constrained using [LLGuidance](https://github.com/guidance-ai/llguidance/blob/main/docs/syntax.md). Some features of Lark are not supported:
- Lookarounds in lexer regexes
- Lazy modifiers (`*?`, `+?`, `??`) in lexer regexes
- Priorities of terminals
- Templates
- Imports (other than built-in `%import` common)
- `%declare`s
We recommend using the [Lark IDE](https://www.lark-parser.org/ide/) to experiment with custom grammars.
### Keep grammars simple
Try to make your grammar as simple as possible. The OpenAI API may return an error if the grammar is too complex, so you should ensure that your desired grammar is compatible before using it in the API.
Lark grammars can be tricky to perfect. While simple grammars perform most reliably, complex grammars often require iteration on the grammar definition itself, the prompt, and the tool description to ensure that the model does not go out of distribution.
### Correct versus incorrect patterns
Correct (single, bounded terminal):
```
start: SENTENCE
SENTENCE: /[A-Za-z, ]*(the hero|a dragon|an old man|the princess)[A-Za-z, ]*(fought|saved|found|lost)[A-Za-z, ]*(a treasure|the kingdom|a secret|his way)[A-Za-z, ]*\./
```
Do NOT do this (splitting across rules/terminals). This attempts to let rules partition free text between terminals. The lexer will greedily match the free-text pieces and you'll lose control:
```
start: sentence
sentence: /[A-Za-z, ]+/ subject /[A-Za-z, ]+/ verb /[A-Za-z, ]+/ object /[A-Za-z, ]+/
```
Lowercase rules don't influence how terminals are cut from the input—only terminal definitions do. When you need “free text between anchors,” make it one giant regex terminal so the lexer matches it exactly once with the structure you intend.
### Terminals versus rules
Lark uses terminals for lexer tokens (by convention, `UPPERCASE`) and rules for parser productions (by convention, `lowercase`). The most practical way to stay within the supported subset and avoid surprises is to keep your grammar simple and explicit, and to use terminals and rules with a clear separation of concerns.
The regex syntax used by terminals is the [Rust regex crate syntax](https://docs.rs/regex/latest/regex/#syntax), not Python's `re` [module](https://docs.python.org/3/library/re.html).
### Key ideas and best practices
**Lexer runs before the parser**
Terminals are matched by the lexer (greedily / longest match wins) before any CFG rule logic is applied. If you try to "shape" a terminal by splitting it across several rules, the lexer cannot be guided by those rules—only by terminal regexes.
**Prefer one terminal when you're carving text out of freeform spans**
If you need to recognize a pattern embedded in arbitrary text (e.g., natural language with “anything” between anchors), express that as a single terminal. Do not try to interleave free‑text terminals with parser rules; the greedy lexer will not respect your intended boundaries and it is highly likely the model will go out of distribution.
**Use rules to compose discrete tokens**
Rules are ideal when you're combining clearly delimited terminals (numbers, keywords, punctuation) into larger structures. They're not the right tool for constraining "the stuff in between" two terminals.
**Keep terminals simple, bounded, and self-contained**
Favor explicit character classes and bounded quantifiers (`{0,10}`, not unbounded `*` everywhere). If you need "any text up to a period", prefer something like `/[^.\n]{0,10}*\./` rather than `/.+\./` to avoid runaway growth.
**Use rules to combine tokens, not to steer regex internals**
Good rule usage example:
```
start: expr
NUMBER: /[0-9]+/
PLUS: "+"
MINUS: "-"
expr: term (("+"|"-") term)*
term: NUMBER
```
**Treat whitespace explicitly**
Don't rely on open-ended `%ignore` directives. Using unbounded ignore directives may cause the grammar to be too complex and/or may cause the model to go out of distribution. Prefer threading explicit terminals wherever whitespace is allowed.
### Troubleshooting
- If the API rejects the grammar because it is too complex, simplify the rules and terminals and remove unbounded `%ignore`s.
- If custom tools are called with unexpected tokens, confirm terminals aren’t overlapping; check greedy lexer.
- When the model drifts "out‑of‑distribution" (shows up as the model producing excessively long or repetitive outputs, it is syntactically valid but is semantically wrong):
- Tighten the grammar.
- Iterate on the prompt (add few-shot examples) and tool description (explain the grammar and instruct the model to reason and conform to it).
- Experiment with a higher reasoning effort (e.g, bump from medium to high).
#### Regex CFG
The output from the tool should then conform to the Regex CFG that you defined:
```json
[
{
"id": "rs_6894f7a3dd4c81a1823a723a00bfa8710d7962f622d1c260",
"type": "reasoning",
"content": [],
"summary": []
},
{
"id": "ctc_6894f7ad7fb881a1bffa1f377393b1a40d7962f622d1c260",
"type": "custom_tool_call",
"status": "completed",
"call_id": "call_8m4XCnYvEmFlzHgDHbaOCFlK",
"input": "August 7th 2025 at 10AM",
"name": "timestamp"
}
]
```
As with the Lark syntax, regexes use the [Rust regex crate syntax](https://docs.rs/regex/latest/regex/#syntax), not Python's `re` [module](https://docs.python.org/3/library/re.html).
Some features of Regex are not supported:
- Lookarounds
- Lazy modifiers (`*?`, `+?`, `??`)
### Key ideas and best practices
**Pattern must be on one line**
If you need to match a newline in the input, use the escaped sequence `\n`. Do not use verbose/extended mode, which allows patterns to span multiple lines.
**Provide the regex as a plain pattern string**
Don't enclose the pattern in `//`.
---
# Getting started with datasets
Evaluations (often called **evals**) test model outputs to ensure they meet your specified style and content criteria. Writing evals is an essential part of building reliable applications. [Datasets](https://platform.openai.com/evaluation/datasets), a feature of the OpenAI platform, provide a quick way to get started with evals and test prompts.
If you need advanced features such as evaluation against external models, want
to interact with your eval runs via API, or want to run evaluations on a
larger scale, consider using [Evals](https://developers.openai.com/api/docs/guides/evals) instead.
## Create a dataset
First, create a dataset in the dashboard.
1. On the [evaluation page](https://platform.openai.com/evaluation), navigate to the **Datasets** tab.
1. Click the **Create** button in the top right to get started.
1. Add a name for your dataset in the input field. In this guide, we'll name our dataset “Investment memo generation."
1. Add data. To build your dataset from scratch, click **Create** and start adding data through our visual interface. If you already have a saved prompt or a CSV with data, upload it.
We recommend using your dataset as a dynamic space, expanding your set of evaluation data over time. As you identify edge cases or blind spots that need monitoring, add them using the dashboard interface.
### Uploading a CSV
We have a simple CSV containing company names and actual values for their revenue from past quarters.
The columns in your CSV are accessible to both your prompt and graders. For example, our CSV contains input columns (`company`) and ground truth columns (`correct_revenue`, `correct_income`) for our graders to use as reference.
### Using the visual data interface
After opening your dataset, you can manipulate your data in the **Data** tab. Click a cell to edit its contents. Add a row to add more data. You can also delete or duplicate rows in the overflow menu at the right edge of each row.
To save your changes, click **Save** button in the top right.
## Build a prompt
The tabs in the datasets dashboard let multiple prompts interact with the same data.
1. To add a new prompt, click **Add prompt**.
Datasets are designed to be used with your OpenAI [prompts](https://developers.openai.com/api/docs/guides/prompt-engineering#reusable-prompts). If you’ve saved a prompt on the OpenAI platform, you’ll be able to select it from the dropdown and make changes in this interface. To save your prompt changes, click **Save**.
Our prompts use a versioning system so you can safely make updates.
Clicking **Save** creates a new version of your prompt, which you can refer
to or use anywhere in the OpenAI platform.
1. In the prompt panel, use the provided fields and settings to control the inference call:
- Click the slider icon in the top right to control model [`temperature`](https://developers.openai.com/api/docs/api-reference/responses/create#responses-create-temperature) and [`top_p`](https://developers.openai.com/api/docs/api-reference/responses/create#responses-create-top_p).
- Add tools to grant your inference call the ability to access the web, use an MCP, or complete other tool-call actions.
- Add variables. The prompt and your [graders](#adding-graders) can both refer to these variables.
- Type your system message directly, or click the pencil icon to have a model help generate a prompt for you, based on basic instructions you provide.
In our example, we'll add the [web search](https://developers.openai.com/api/docs/guides/tools-web-search) tool so our model call can pull financial data from the internet. In our variables list, we'll add `company` so our prompt can reference the company column in our dataset. And for the prompt, we’ll generate one by telling the model to “generate a financial report."
## Generate and annotate outputs
With your data and prompt set up, you’re ready to generate outputs. The model's output gives you a sense of how the model performs your task with the prompt and tools you provided. You'll then annotate the outputs so the model can improve its performance over time.
1. In the top right, click **Generate output**.
You’ll see a new special **output** column in the dataset begin to populate with results. This column contains the results from running your prompt on each row in your dataset.
1. Once your generated outputs are ready, annotate them. Open the annotation view by clicking the **output**, **rating**, or **output_feedback** column.
Annotate as little or as much as you want. Datasets are designed to work with any degree and type of annotation, but the higher quality of information you can provide, the better your results will be.
### What annotation does
Annotations are a key part of evaluating and improving model output. A good annotation:
- Serves as ground truth for desired model behavior, even for highly specific cases—including subjective elements, like style and tone
- Provides information-dense context enabling automatic prompt improvement (via our prompt optimizer)
- Enables diagnosing prompt shortcomings, particularly in subtle or infrequent cases
- Helps ensure that graders are aligned with your intent
You can choose to annotate as little or as much as you want. Datasets are designed to work with any degree and type of annotation, but the higher quality of information you can provide, the better your results will be. Additionally, if you’re not an expert on the contents of your dataset, we recommend that a subject matter expert performs the annotation — this is the most valuable way for their expertise to be incorporated into your optimization process. Explore [our cookbook](https://developers.openai.com/cookbook/examples/evaluation/building_resilient_prompts_using_an_evaluation_flywheel) to learn more about what we have found to be most effective in using evals to improve our prompt resilience.
### Annotation starting points
Here are a few types of annotations you can use to get started:
- A Good/Bad rating, indicating your judgment of the output
- A text critique in the **output_feedback** section
- Custom annotation categories that you added in the **Columns** dropdown in the top right
### Incorporate expert annotations
If you’re not an expert on the contents of your dataset, have a subject matter expert perform the annotation. This is the best way to incorporate expertise into the optimization process. Explore [our cookbook](https://developers.openai.com/cookbook/examples/evaluation/building_resilient_prompts_using_an_evaluation_flywheel) to learn more.
## Add graders
While annotations are the most effective way to incorporate human feedback into your evaluation process, graders let you run evaluations at scale. Graders are automated assessments that can produce a variety of inputs depending on their type.
| **Type** | **Details** | **Use case** |
| ------------------------- | --------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------- |
| **String check** | Compares model output to the reference using exact string matching | Check whether your response exactly matches a ground truth column |
| **Text similarity** | Uses embeddings to compute semantic similarity between model output and reference | Check how close your response is to your ground truth reference, when exact matching is not needed |
| **Score model grader** | Uses an LLM to assign a numeric score | Measure subjective properties such as friendliness on a numeric scale |
| **Label model grader** | Uses an LLM to select a categorical label | Categorize your response based on fix labels, such as "concise" or "verbose" |
| **Python code execution** | Runs custom Python code to compute a result programmatically | Check whether the output contains fewer than 50 words |
1. In the top right, navigate to Grade > **New grader**.
1. From the dropdown, choose your grader type, and fill out the form to compose your grader.
1. Reference the columns from your dataset to check against ground truth values.
1. Create the grader.
1. Once you’ve added at least one grader, use the **Grade** dropdown menu to run specific graders or all graders on your dataset. When a run is complete, you’ll see pass/fail ratings in your dataset in a dedicated column for each grader.
After saving your dataset, graders persist as you make changes to your dataset and prompt, making them a great way to quickly assess whether a prompt or model parameter change leads to improvements, or whether adding edge cases reveals shortcomings in your prompt. The datasets dashboard supports multiple tabs for simultaneously tracking results from automated graders across multiple variants of a prompt.
Learn more about our [graders](https://developers.openai.com/api/docs/guides/graders).
## Next steps
Datasets are great for rapid iteration. When you're ready to track performance over time or run at scale, export your dataset to an [Eval](https://developers.openai.com/api/docs/guides/evals). Evals run asynchronously, support larger data volumes, and let you monitor performance across versions.
For more inspiration, visit the [OpenAI Cookbook](https://developers.openai.com/cookbook/topic/evals), which contains example code and links to third-party resources, or learn more about our evaluation tools:
Operate a flywheel of continuous improvement using evaluations.
Evaluate against external models, interact with evals via API, and more.
Use your dataset to automatically improve your prompts.
[
Build sophisticated graders to improve the effectiveness of your evals.
](https://developers.openai.com/api/docs/guides/graders)
---
# Graders
Graders are a way to evaluate your model's performance against reference answers. Our [graders API](https://developers.openai.com/api/docs/api-reference/graders) is a way to test your graders, experiment with results, and improve your fine-tuning or evaluation framework to get the results you want.
## Overview
Graders let you compare reference answers to the corresponding model-generated answer and return a grade in the range from 0 to 1. It's sometimes helpful to give the model partial credit for an answer, rather than a binary 0 or 1.
Graders are specified in JSON format, and there are several types:
- [String check](#string-check-graders)
- [Text similarity](#text-similarity-graders)
- [Score model grader](#score-model-graders)
- [Python code execution](#python-graders)
In reinforcement fine-tuning, you can nest and combine graders by using [multigraders](#multigraders).
Use this guide to learn about each grader type and see starter examples. To build a grader and get started with reinforcement fine-tuning, see the [RFT guide](https://developers.openai.com/api/docs/guides/reinforcement-fine-tuning). Or to get started with evals, see the [Evals guide](https://developers.openai.com/api/docs/guides/evals).
## Templating
The inputs to certain graders use a templating syntax to grade multiple examples with the same configuration. Any string with `{{ }}` double curly braces will be substituted with the variable value.
Each input inside the `{{}}` must include a _namespace_ and a _variable_ with the following format `{{ namespace.variable }}`. The only supported namespaces are `item` and `sample`.
All nested variables can be accessed with JSON path like syntax.
### Item namespace
The item namespace will be populated with variables from the input data source for evals, and from each dataset item for fine-tuning. For example, if a row contains the following
```json
{
"reference_answer": "..."
}
```
This can be used within the grader as `{{ item.reference_answer }}`.
### Sample namespace
The sample namespace will be populated with variables from the model sampling step during evals or during the fine-tuning step. The following variables are included
- `output_text`, the model output content as a string.
- `output_json`, the model output content as a JSON object, only if `response_format` is included in the sample.
- `output_tools`, the model output `tool_calls`, which have the same structure as output tool calls in the [chat completions API](https://developers.openai.com/api/docs/api-reference/chat/object).
- `choices`, the output choices, which has the same structure as output choices in the [chat completions API](https://developers.openai.com/api/docs/api-reference/chat/object).
- `output_audio`, the model audio output object containing Base64-encoded `data` and a `transcript`.
For example, to access the model output content as a string, `{{ sample.output_text }}` can be used within the grader.
Details on grading tool calls
When training a model to improve tool-calling behavior, you will need to write your grader to operate over the `sample.output_tools` variable. The contents of this variable will be the same as the contents of the `response.choices[0].message.tool_calls` ([see function calling docs](https://developers.openai.com/api/docs/guides/function-calling?api-mode=chat)).
A common way of grading tool calls is to use two graders, one that checks the name of the tool that is called and another that checks the arguments of the called function. An example of a grader that does this is shown below:
```json
{
"type": "multi",
"graders": {
"function_name": {
"name": "function_name",
"type": "string_check",
"input": "get_acceptors",
"reference": "{{sample.output_tools[0].function.name}}",
"operation": "eq"
},
"arguments": {
"name": "arguments",
"type": "string_check",
"input": "{\"smiles\": \"{{item.smiles}}\"}",
"reference": "{{sample.output_tools[0].function.arguments}}",
"operation": "eq"
}
},
"calculate_output": "0.5 * function_name + 0.5 * arguments"
}
```
This is a `multi` grader that combined two simple `string_check` graders, the first checks the name of the tool called via the `sample.output_tools[0].function.name` variable, and the second checks the arguments of the called function via the `sample.output_tools[0].function.arguments` variable. The `calculate_output` field is used to combine the two scores into a single score.
The `arguments` grader is prone to under-rewarding the model if the function arguments are subtly incorrect, like if `1` is submitted instead of the floating point `1.0`, or if a state name is given as an abbreviation instead of spelling it out. To avoid this, you can use a `text_similarity` grader instead of a `string_check` grader, or a `score_model` grader to have a LLM check for semantic similarity.
## String check grader
Use these simple string operations to return a 0 or 1. String check graders are good for scoring straightforward pass or fail answers—for example, the correct name of a city, a yes or no answer, or an answer containing or starting with the correct information.
```json
{
"type": "string_check",
"name": string,
"operation": "eq" | "ne" | "like" | "ilike",
"input": string,
"reference": string,
}
```
Operations supported for string-check-grader are:
- `eq`: Returns 1 if the input matches the reference (case-sensitive), 0 otherwise
- `neq`: Returns 1 if the input does not match the reference (case-sensitive), 0 otherwise
- `like`: Returns 1 if the input contains the reference (case-sensitive), 0 otherwise
- `ilike`: Returns 1 if the input contains the reference (not case-sensitive), 0 otherwise
## Text similarity grader
Use text similarity graders when to evaluate how close the model-generated output is to the reference, scored with various evaluation frameworks.
This is useful for open-ended text responses. For example, if your dataset contains reference answers from experts in paragraph form, it's helpful to see how close your model-generated answer is to that content, in numerical form.
```json
{
"type": "text_similarity",
"name": string,
"input": string,
"reference": string,
"pass_threshold": number,
"evaluation_metric": "fuzzy_match" | "bleu" | "gleu" | "meteor" | "cosine" | "rouge_1" | "rouge_2" | "rouge_3" | "rouge_4" | "rouge_5" | "rouge_l"
}
```
Operations supported for `string-similarity-grader` are:
- `fuzzy_match`: Fuzzy string match between input and reference, using `rapidfuzz`
- `bleu`: Computes the BLEU score between input and reference
- `gleu`: Computes the Google BLEU score between input and reference
- `meteor`: Computes the METEOR score between input and reference
- `cosine`: Computes Cosine similarity between embedded input and reference, using `text-embedding-3-large`. Only available for evals.
- `rouge-*`: Computes the ROUGE score between input and reference
## Model graders
In general, using a model grader means prompting a separate model to grade the outputs of the model you're fine-tuning. Your two models work together to do reinforcement fine-tuning. The _grader model_ evaluates the _training model_.
### Score model graders
A score model grader will take the input and return a numeric score based on the prompt within the given range.
```json
{
"type": "score_model",
"name": string,
"input": Message[],
"model": string,
"pass_threshold": number,
"range": number[],
"sampling_params": {
"seed": number,
"top_p": number,
"temperature": number,
"max_completions_tokens": number,
"reasoning_effort": "minimal" | "low" | "medium" | "high"
}
}
```
Where each message is of the following form:
```json
{
"role": "system" | "developer" | "user" | "assistant",
"content": str
}
```
To use a score model grader, the input is a list of chat messages, each containing a `role` and `content`. The output of the grader will be truncated to the given `range`, and default to 0 for all non-numeric outputs.
Within each message, the same templating can be used as with other common graders to reference the ground truth or model sample.
Here’s a full runnable code sample:
```python
import os
import requests
# get the API key from environment
api_key = os.environ["OPENAI_API_KEY"]
headers = {"Authorization": f"Bearer {api_key}"}
# define a dummy grader for illustration purposes
grader = {
"type": "score_model",
"name": "my_score_model",
"input": [
{
"role": "system",
"content": "You are an expert grader. If the reference and model answer are exact matches, output a score of 1. If they are somewhat similar in meaning, output a score in 0.5. Otherwise, give a score of 0."
},
{
"role": "user",
"content": "Reference: {{ item.reference_answer }}. Model answer: {{ sample.output_text }}"
}
],
"pass_threshold": 0.5,
"model": "o4-mini-2025-04-16",
"range": [0, 1],
"sampling_params": {
"max_completions_tokens": 32768,
"top_p": 1,
"reasoning_effort": "medium"
},
}
# validate the grader
payload = {"grader": grader}
response = requests.post(
"https://api.openai.com/v1/fine_tuning/alpha/graders/validate",
json=payload,
headers=headers
)
print("validate response:", response.text)
# run the grader with a test reference and sample
payload = {
"grader": grader,
"item": {
"reference_answer": 1.0
},
"model_sample": "0.9"
}
response = requests.post(
"https://api.openai.com/v1/fine_tuning/alpha/graders/run",
json=payload,
headers=headers
)
print("run response:", response.text)
```
#### Score model grader outputs
Under the hood, the `score_model` grader will query the requested model with the provided prompt and sampling parameters and will request a response in a specific response format. The response format that is used is provided below
```json
{
"result": float,
"steps": ReasoningStep[],
}
```
Where each reasoning step is of the form
```json
{
description: string,
conclusion: string
}
```
This format queries the model not just for the numeric `result` (the reward value for the query), but also provides the model some space to think through the reasoning behind the score. When you are writing your grader prompt, it may be useful to refer to these two fields by name explicitly (e.g. "include reasoning about the type of chemical bonds present in the molecule in the conclusion of your reasoning step", or "return a value of -1.0 in the `result` field if the inputs do not satisfy condition X").
### Model grader constraints
- Only the following models are supported for the `model` parameter`
- `gpt-4o-2024-08-06`
- `gpt-4o-mini-2024-07-18`
- `gpt-4.1-2025-04-14`
- `gpt-4.1-mini-2025-04-14`
- `gpt-4.1-nano-2025-04-14`
- `o1-2024-12-17`
- `o3-mini-2025-01-31`
- `o3-2025-04-16`
- `o4-mini-2025-04-16`
- `temperature` changes not supported for reasoning models.
- `reasoning_effort` is not supported for non-reasoning models.
### How to write grader prompts
Writing grader prompts is an iterative process. The best way to iterate on a model grader prompt is to create a model grader eval. To do this, you need:
1. **Task prompts**: Write extremely detailed prompts for the desired task, with step-by-step instructions and many specific examples in context.
1. **Answers generated by a model or human expert**: Provide many high quality examples of answers, both from the model and trusted human experts.
1. **Corresponding ground truth grades for those answers**: Establish what a good grade looks like. For example, your human expert grades should be 1.
Then you can automatically evaluate how effectively the model grader distinguishes answers of different quality levels. Over time, add edge cases into your model grader eval as you discover and patch them with changes to the prompt.
For example, say you know from your human experts which answers are best:
```
answer_1 > answer_2 > answer_3
```
Verify that the model grader's answers match that:
```
model_grader(answer_1, reference_answer) > model_grader(answer_2, reference_answer) > model_grader(answer_3, reference_answer)
```
### Grader hacking
Models being trained sometimes learn to exploit weaknesses in model graders, also known as “grader hacking” or “reward hacking." You can detect this by checking the model's performance across model grader evals and expert human evals. A model that's hacked the grader will score highly on model grader evals but score poorly on expert human evaluations. Over time, we intend to improve observability in the API to make it easier to detect this during training.
## Python graders
This grader allows you to execute arbitrary python code to grade the model output. The grader expects a grade function to be present that takes in two arguments and outputs a float value. Any other result (exception, invalid float value, etc.) will be marked as invalid and return a 0 grade.
```json
{
"type": "python",
"source": "def grade(sample, item):\n return 1.0",
"image_tag": "2025-05-08"
}
```
The python source code must contain a grade function that takes in exactly two arguments and returns a float value as a grade.
```python
from typing import Any
def grade(sample: dict[str, Any], item: dict[str, Any]) -> float:
# your logic here
return 1.0
```
The first argument supplied to the grading function will be a dictionary populated with the model’s output during training for you to grade. `output_json` will only be populated if the output uses `response_format`.
```json
{
"choices": [...],
"output_text": "...",
"output_json": {},
"output_tools": [...],
"output_audio": {}
}
```
The second argument supplied is a dictionary populated with input grading context. For evals, this will include keys from the data source. For fine-tuning this will include keys from each training data row.
```json
{
"reference_answer": "...",
"my_key": {...}
}
```
Here's a working example:
```python
import os
import requests
# get the API key from environment
api_key = os.environ["OPENAI_API_KEY"]
headers = {"Authorization": f"Bearer {api_key}"}
grading_function = """
from rapidfuzz import fuzz, utils
def grade(sample, item) -> float:
output_text = sample["output_text"]
reference_answer = item["reference_answer"]
return fuzz.WRatio(output_text, reference_answer, processor=utils.default_process) / 100.0
"""
# define a dummy grader for illustration purposes
grader = {
"type": "python",
"source": grading_function
}
# validate the grader
payload = {"grader": grader}
response = requests.post(
"https://api.openai.com/v1/fine_tuning/alpha/graders/validate",
json=payload,
headers=headers
)
print("validate request_id:", response.headers["x-request-id"])
print("validate response:", response.text)
# run the grader with a test reference and sample
payload = {
"grader": grader,
"item": {
"reference_answer": "fuzzy wuzzy had no hair"
},
"model_sample": "fuzzy wuzzy was a bear"
}
response = requests.post(
"https://api.openai.com/v1/fine_tuning/alpha/graders/run",
json=payload,
headers=headers
)
print("run request_id:", response.headers["x-request-id"])
print("run response:", response.text)
```
**Tip:**
If you don't want to manually put your grading function in a string, you can also load it from a Python file using `importlib` and `inspect`. For example, if your grader function is in a file named `grader.py`, you can do:
```python
import importlib
import inspect
grader_module = importlib.import_module("grader")
grader = {
"type": "python",
"source": inspect.getsource(grader_module)
}
```
This will automatically use the entire source code of your `grader.py` file as the grader which can be helpful for longer graders.
### Technical constraints
- Your uploaded code must be less than `256kB` and will not have network access.
- The grading execution itself is limited to 2 minutes.
- At runtime you will be given a limit of 2Gb of memory and 1Gb of disk space to use.
- There's a limit of 2 CPU cores—any usage above this amount will result in throttling
The following third-party packages are available at execution time for the image tag `2025-05-08`
```
numpy==2.2.4
scipy==1.15.2
sympy==1.13.3
pandas==2.2.3
rapidfuzz==3.10.1
scikit-learn==1.6.1
rouge-score==0.1.2
deepdiff==8.4.2
jsonschema==4.23.0
pydantic==2.10.6
pyyaml==6.0.2
nltk==3.9.1
sqlparse==0.5.3
rdkit==2024.9.6
scikit-bio==0.6.3
ast-grep-py==0.36.2
```
Additionally the following nltk corpora are available:
```
punkt
stopwords
wordnet
omw-1.4
names
```
## Multigraders
> Currently, this grader is only used for Reinforcement fine-tuning
A `multigrader` object combines the output of multiple graders to produce a single score. Multigraders work by computing grades over the fields of other grader objects and turning those sub-grades into an overall grade. This is useful when a correct answer depends on multiple things being true—for example, that the text is similar _and_ that the answer contains a specific string.
As an example, say you wanted the model to output JSON with the following two fields:
```json
{
"name": "John Doe",
"email": "john.doe@gmail.com"
}
```
You'd want your grader to compare the two fields and then take the average between them.
You can do this by combining multiple graders into an object grader, and then defining a formula to calculate the output score based on each field:
```json
{
"type": "multi",
"graders": {
"name": {
"name": "name_grader",
"type": "text_similarity",
"input": "{{sample.output_json.name}}",
"reference": "{{item.name}}",
"evaluation_metric": "fuzzy_match",
"pass_threshold": 0.9
},
"email": {
"name": "email_grader",
"type": "string_check",
"input": "{{sample.output_json.email}}",
"reference": "{{item.email}}",
"operation": "eq"
}
},
"calculate_output": "(name + email) / 2"
}
```
In this example, it’s important for the model to get the email exactly right (`string_check` returns either 0 or 1) but we tolerate some misspellings on the name (`text_similarity` returns range from 0 to 1). Samples that get the email wrong will score between 0-0.5, and samples that get the email right will score between 0.5-1.0.
You cannot create a multigrader with a nested multigrader inside.
The calculate output field will have the keys of the input `graders` as possible variables and the following features are supported:
**Operators**
- `+` (addition)
- `-` (subtraction)
- `*` (multiplication)
- `/` (division)
- `^` (power)
**Functions**
- `min`
- `max`
- `abs`
- `floor`
- `ceil`
- `exp`
- `sqrt`
- `log`
## Limitations and tips
Designing and creating graders is an iterative process. Start small, experiment, and continue to make changes to get better results.
### Design tips
To get the most value from your graders, use these design principles:
- **Produce a smooth score, not a pass/fail stamp**. A score that shifts gradually as answers improve helps the optimizer see which changes matter.
- **Guard against reward hacking**. This happens when the model finds a shortcut that earns high scores without real skill. Make it hard to loophole your grading system.
- **Avoid skewed data**. Datasets in which one label shows up most of the time invite the model to guess that label. Balance the set or up‑weight rare cases so the model must think.
- **Use an LLM‑as‑a-judge when code falls short**. For rich, open‑ended answers, ask another language model to grade. When building LLM graders, run multiple candidate responses and ground truths through your LLM judge to ensure grading is stable and aligned with preference. Provide few-shot examples of great, fair, and poor answers in the prompt.
---
# Guardrails and human review
Use guardrails for automatic checks and human review for approval decisions. Together, they define when a run should continue, pause, or stop.
- **Guardrails** validate input, output, or tool behavior automatically.
- **Human review** pauses the run so a person or policy can approve or reject a sensitive action.
## Choose the right control
| Use case | Start with |
| --------------------------------------------------------------------------------------------- | --------------------------- |
| Block disallowed user requests before the main model runs | Input guardrails |
| Validate or redact the final output before it leaves the system | Output guardrails |
| Check arguments or results around a function tool call | Tool guardrails |
| Pause before side effects like cancellations, edits, shell commands, or sensitive MCP actions | Human-in-the-loop approvals |
## Add a blocking guardrail
Use input guardrails when you want a fast validation step to run before the expensive or side-effecting part of the workflow starts.
Block a request with an input guardrail
```typescript
import {
Agent,
InputGuardrailTripwireTriggered,
run,
} from "@openai/agents";
import { z } from "zod";
const guardrailAgent = new Agent({
name: "Homework check",
instructions: "Detect whether the user is asking for math homework help.",
outputType: z.object({
isMathHomework: z.boolean(),
reasoning: z.string(),
}),
});
const agent = new Agent({
name: "Customer support",
instructions: "Help customers with support questions.",
inputGuardrails: [
{
name: "Math homework guardrail",
runInParallel: false,
async execute({ input, context }) {
const result = await run(guardrailAgent, input, { context });
return {
outputInfo: result.finalOutput,
tripwireTriggered: result.finalOutput?.isMathHomework === true,
};
},
},
],
});
try {
await run(agent, "Can you solve 2x + 3 = 11 for me?");
} catch (error) {
if (error instanceof InputGuardrailTripwireTriggered) {
console.log("Guardrail blocked the request.");
}
}
```
```python
import asyncio
from pydantic import BaseModel
from agents import (
Agent,
GuardrailFunctionOutput,
InputGuardrailTripwireTriggered,
RunContextWrapper,
Runner,
TResponseInputItem,
input_guardrail,
)
class MathHomeworkOutput(BaseModel):
is_math_homework: bool
reasoning: str
guardrail_agent = Agent(
name="Homework check",
instructions="Detect whether the user is asking for math homework help.",
output_type=MathHomeworkOutput,
)
@input_guardrail
async def math_guardrail(
ctx: RunContextWrapper[None],
agent: Agent,
input: str | list[TResponseInputItem],
) -> GuardrailFunctionOutput:
result = await Runner.run(guardrail_agent, input, context=ctx.context)
return GuardrailFunctionOutput(
output_info=result.final_output,
tripwire_triggered=result.final_output.is_math_homework,
)
agent = Agent(
name="Customer support",
instructions="Help customers with support questions.",
input_guardrails=[math_guardrail],
)
async def main() -> None:
try:
await Runner.run(agent, "Can you solve 2x + 3 = 11 for me?")
except InputGuardrailTripwireTriggered:
print("Guardrail blocked the request.")
if __name__ == "__main__":
asyncio.run(main())
```
Use blocking execution when the cost or risk of starting the main agent is too high. Use parallel guardrails when lower latency matters more than avoiding speculative work.
## Pause for human review
Approvals are the human-in-the-loop path for tool calls. The model can still decide that an action is needed, but the run pauses until you approve or reject it.
Pause for approval before a sensitive action
```typescript
import { Agent, run, tool } from "@openai/agents";
import { z } from "zod";
const cancelOrder = tool({
name: "cancel_order",
description: "Cancel a customer order.",
parameters: z.object({ orderId: z.number() }),
needsApproval: true,
async execute({ orderId }) {
return \`Cancelled order \${orderId}\`;
},
});
const agent = new Agent({
name: "Support agent",
instructions: "Handle support requests and ask for approval when needed.",
tools: [cancelOrder],
});
let result = await run(agent, "Cancel order 123.");
if (result.interruptions?.length) {
const state = result.state;
for (const interruption of result.interruptions) {
state.approve(interruption);
}
result = await run(agent, state);
}
console.log(result.finalOutput);
```
```python
import asyncio
from agents import Agent, Runner, function_tool
@function_tool(needs_approval=True)
async def cancel_order(order_id: int) -> str:
return f"Cancelled order {order_id}"
agent = Agent(
name="Support agent",
instructions="Handle support requests and ask for approval when needed.",
tools=[cancel_order],
)
async def main() -> None:
result = await Runner.run(agent, "Cancel order 123.")
if result.interruptions:
state = result.to_state()
for interruption in result.interruptions:
state.approve(interruption)
result = await Runner.run(agent, state)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
```
This same interruption pattern applies even when the approving tool lives deeper in the workflow, such as after a handoff or inside a nested call.
## Approval lifecycle
When a tool call needs review, the SDK follows the same pattern every time:
1. The run records an approval interruption instead of executing the tool.
2. The result returns `interruptions` plus a resumable `state`.
3. Your application approves or rejects the pending items.
4. You resume the same run from `state` instead of starting a new user turn.
If the review might take time, serialize `state`, store it, and resume later. That's still the same run.
## Workflow boundaries matter
Agent-level guardrails don't run everywhere:
- Input guardrails run only for the first agent in the chain.
- Output guardrails run only for the agent that produces the final output.
- Tool guardrails run on the function tools they're attached to.
If you need checks around every custom tool call in a manager-style workflow, don't rely only on agent-level input or output guardrails. Put validation next to the tool that creates the side effect.
## Streaming and delayed review use the same state model
Streaming doesn't create a separate approval system. If a streamed run pauses, wait for it to settle, inspect `interruptions`, resolve the approvals, and resume from the same `state`. If the review happens later, store the serialized state and continue the same run when the decision arrives.
## Next steps
Once the control boundaries are clear, continue with the guide that covers the runtime or tool surface around them.
---
# Image generation
## Overview
The OpenAI API lets you generate and edit images from text prompts using GPT Image models, including our latest, `gpt-image-2`. You can access image generation capabilities through two APIs:
### Image API
Starting with `gpt-image-1` and later models, the [Image API](https://developers.openai.com/api/docs/api-reference/images) provides two endpoints, each with distinct capabilities:
- **Generations**: [Generate images](#generate-images) from scratch based on a text prompt
- **Edits**: [Modify existing images](#edit-images) using a new prompt, either partially or entirely
The Image API also includes a variations endpoint for models that support it, such as DALL·E 2.
### Responses API
The [Responses API](https://developers.openai.com/api/docs/api-reference/responses/create#responses-create-tools) allows you to generate images as part of conversations or multi-step flows. It supports image generation as a [built-in tool](https://developers.openai.com/api/docs/guides/tools?api-mode=responses), and accepts image inputs and outputs within context.
Compared to the Image API, it adds:
- **Multi-turn editing**: Iteratively make high fidelity edits to images with prompting
- **Flexible inputs**: Accept image [File](https://developers.openai.com/api/docs/api-reference/files) IDs as input images, not just bytes
The Responses API image generation tool uses its own GPT Image model selection. For details on mainline models that support calling this tool, refer to the [supported models](#supported-models) below.
### Choosing the right API
- If you only need to generate or edit a single image from one prompt, the Image API is your best choice.
- If you want to build conversational, editable image experiences with GPT Image, go with the Responses API.
Both APIs let you [customize output](#customize-image-output) by adjusting quality, size, format, and compression. Transparent backgrounds depend on model support.
This guide focuses on GPT Image.
To ensure these models are used responsibly, you may need to complete the [API
Organization
Verification](https://help.openai.com/en/articles/10910291-api-organization-verification)
from your [developer
console](https://platform.openai.com/settings/organization/general) before
using GPT Image models, including `gpt-image-2`, `gpt-image-1.5`,
`gpt-image-1`, and `gpt-image-1-mini`.

## Generate Images
You can use the [image generation endpoint](https://developers.openai.com/api/docs/api-reference/images/create) to create images based on text prompts, or the [image generation tool](https://developers.openai.com/api/docs/guides/tools?api-mode=responses) in the Responses API to generate images as part of a conversation.
To learn more about customizing the output (size, quality, format, compression), refer to the [customize image output](#customize-image-output) section below.
You can set the `n` parameter to generate multiple images at once in a single request (by default, the API returns a single image).
Responses API
Generate an image
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5.5",
input: "Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools: [{type: "image_generation"}],
});
// Save the image to a file
const imageData = response.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData.length > 0) {
const imageBase64 = imageData[0];
const fs = await import("fs");
fs.writeFileSync("otter.png", Buffer.from(imageBase64, "base64"));
}
```
```python
from openai import OpenAI
import base64
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
input="Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools=[{"type": "image_generation"}],
)
# Save the image to a file
image_data = [
output.result
for output in response.output
if output.type == "image_generation_call"
]
if image_data:
image_base64 = image_data[0]
with open("otter.png", "wb") as f:
f.write(base64.b64decode(image_base64))
```
Image API
Generate an image
```javascript
import OpenAI from "openai";
import fs from "fs";
const openai = new OpenAI();
const prompt = \`
A children's book drawing of a veterinarian using a stethoscope to
listen to the heartbeat of a baby otter.
\`;
const result = await openai.images.generate({
model: "gpt-image-2",
prompt,
});
// Save the image to a file
const image_base64 = result.data[0].b64_json;
const image_bytes = Buffer.from(image_base64, "base64");
fs.writeFileSync("otter.png", image_bytes);
```
```python
from openai import OpenAI
import base64
client = OpenAI()
prompt = """
A children's book drawing of a veterinarian using a stethoscope to
listen to the heartbeat of a baby otter.
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt
)
image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
# Save the image to a file
with open("otter.png", "wb") as f:
f.write(image_bytes)
```
```bash
curl -X POST "https://api.openai.com/v1/images/generations" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-type: application/json" \\
-d '{
"model": "gpt-image-2",
"prompt": "A childrens book drawing of a veterinarian using a stethoscope to listen to the heartbeat of a baby otter."
}' | jq -r '.data[0].b64_json' | base64 --decode > otter.png
```
```cli
openai images generate \\
--model gpt-image-2 \\
--prompt "A childrens book drawing of a veterinarian using a stethoscope to listen to the heartbeat of a baby otter." \\
--raw-output \\
--transform 'data.0.b64_json' | base64 --decode > otter.png
```
### Multi-turn image generation
With the Responses API, you can build multi-turn conversations involving image generation either by providing image generation calls outputs within context (you can also just use the image ID), or by using the [`previous_response_id` parameter](https://developers.openai.com/api/docs/guides/conversation-state?api-mode=responses#openai-apis-for-conversation-state).
This lets you iterate on images across multiple turns—refining prompts, applying new instructions, and evolving the visual output as the conversation progresses.
With the Responses API image generation tool, supported tool models can choose whether to generate a new image or edit one already in the conversation. The optional `action` parameter controls this behavior: keep `action: "auto"` to let the model decide, set `action: "generate"` to always create a new image, or set `action: "edit"` to force editing when an image is in context.
Force image creation with action
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5.5",
input: "Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools: [{type: "image_generation", action: "generate"}],
});
// Save the image to a file
const imageData = response.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData.length > 0) {
const imageBase64 = imageData[0];
const fs = await import("fs");
fs.writeFileSync("otter.png", Buffer.from(imageBase64, "base64"));
}
```
```python
from openai import OpenAI
import base64
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
input="Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools=[{"type": "image_generation", "action": "generate"}],
)
# Save the image to a file
image_data = [
output.result
for output in response.output
if output.type == "image_generation_call"
]
if image_data:
image_base64 = image_data[0]
with open("otter.png", "wb") as f:
f.write(base64.b64decode(image_base64))
```
If you force `edit` without providing an image in context, the call will return an error. Leave `action` at `auto` to have the model decide when to generate or edit.
Using previous response ID
Multi-turn image generation
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5.5",
input:
"Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools: [{ type: "image_generation" }],
});
const imageData = response.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData.length > 0) {
const imageBase64 = imageData[0];
const fs = await import("fs");
fs.writeFileSync("cat_and_otter.png", Buffer.from(imageBase64, "base64"));
}
// Follow up
const response_fwup = await openai.responses.create({
model: "gpt-5.5",
previous_response_id: response.id,
input: "Now make it look realistic",
tools: [{ type: "image_generation" }],
});
const imageData_fwup = response_fwup.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData_fwup.length > 0) {
const imageBase64 = imageData_fwup[0];
const fs = await import("fs");
fs.writeFileSync(
"cat_and_otter_realistic.png",
Buffer.from(imageBase64, "base64")
);
}
```
```python
from openai import OpenAI
import base64
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
input="Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools=[{"type": "image_generation"}],
)
image_data = [
output.result
for output in response.output
if output.type == "image_generation_call"
]
if image_data:
image_base64 = image_data[0]
with open("cat_and_otter.png", "wb") as f:
f.write(base64.b64decode(image_base64))
# Follow up
response_fwup = client.responses.create(
model="gpt-5.5",
previous_response_id=response.id,
input="Now make it look realistic",
tools=[{"type": "image_generation"}],
)
image_data_fwup = [
output.result
for output in response_fwup.output
if output.type == "image_generation_call"
]
if image_data_fwup:
image_base64 = image_data_fwup[0]
with open("cat_and_otter_realistic.png", "wb") as f:
f.write(base64.b64decode(image_base64))
```
Using image ID
Multi-turn image generation
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5.5",
input:
"Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools: [{ type: "image_generation" }],
});
const imageGenerationCalls = response.output.filter(
(output) => output.type === "image_generation_call"
);
const imageData = imageGenerationCalls.map((output) => output.result);
if (imageData.length > 0) {
const imageBase64 = imageData[0];
const fs = await import("fs");
fs.writeFileSync("cat_and_otter.png", Buffer.from(imageBase64, "base64"));
}
// Follow up
const response_fwup = await openai.responses.create({
model: "gpt-5.5",
input: [
{
role: "user",
content: [{ type: "input_text", text: "Now make it look realistic" }],
},
{
type: "image_generation_call",
id: imageGenerationCalls[0].id,
},
],
tools: [{ type: "image_generation" }],
});
const imageData_fwup = response_fwup.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData_fwup.length > 0) {
const imageBase64 = imageData_fwup[0];
const fs = await import("fs");
fs.writeFileSync(
"cat_and_otter_realistic.png",
Buffer.from(imageBase64, "base64")
);
}
```
```python
import openai
import base64
response = openai.responses.create(
model="gpt-5.5",
input="Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools=[{"type": "image_generation"}],
)
image_generation_calls = [
output
for output in response.output
if output.type == "image_generation_call"
]
image_data = [output.result for output in image_generation_calls]
if image_data:
image_base64 = image_data[0]
with open("cat_and_otter.png", "wb") as f:
f.write(base64.b64decode(image_base64))
# Follow up
response_fwup = openai.responses.create(
model="gpt-5.5",
input=[
{
"role": "user",
"content": [{"type": "input_text", "text": "Now make it look realistic"}],
},
{
"type": "image_generation_call",
"id": image_generation_calls[0].id,
},
],
tools=[{"type": "image_generation"}],
)
image_data_fwup = [
output.result
for output in response_fwup.output
if output.type == "image_generation_call"
]
if image_data_fwup:
image_base64 = image_data_fwup[0]
with open("cat_and_otter_realistic.png", "wb") as f:
f.write(base64.b64decode(image_base64))
```
#### Result
|
"Generate an image of gray tabby cat hugging an otter with an orange
scarf"
|

|
|
"Now make it look realistic"
|

|
### Streaming
The Responses API and Image API support streaming image generation. You can stream partial images as the APIs generate them, providing a more interactive experience.
You can adjust the `partial_images` parameter to receive 0-3 partial images.
- If you set `partial_images` to 0, you will only receive the final image.
- For values larger than zero, you may not receive the full number of partial images you requested if the full image is generated more quickly.
Responses API
Stream an image
```javascript
import OpenAI from "openai";
import fs from "fs";
const openai = new OpenAI();
const stream = await openai.responses.create({
model: "gpt-5.5",
input:
"Draw a gorgeous image of a river made of white owl feathers, snaking its way through a serene winter landscape",
stream: true,
tools: [{ type: "image_generation", partial_images: 2 }],
});
for await (const event of stream) {
if (event.type === "response.image_generation_call.partial_image") {
const idx = event.partial_image_index;
const imageBase64 = event.partial_image_b64;
const imageBuffer = Buffer.from(imageBase64, "base64");
fs.writeFileSync(\`river\${idx}.png\`, imageBuffer);
}
}
```
```python
from openai import OpenAI
import base64
client = OpenAI()
stream = client.responses.create(
model="gpt-5.5",
input="Draw a gorgeous image of a river made of white owl feathers, snaking its way through a serene winter landscape",
stream=True,
tools=[{"type": "image_generation", "partial_images": 2}],
)
for event in stream:
if event.type == "response.image_generation_call.partial_image":
idx = event.partial_image_index
image_base64 = event.partial_image_b64
image_bytes = base64.b64decode(image_base64)
with open(f"river{idx}.png", "wb") as f:
f.write(image_bytes)
```
Image API
Stream an image
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const prompt =
"Draw a gorgeous image of a river made of white owl feathers, snaking its way through a serene winter landscape";
const stream = await openai.images.generate({
prompt: prompt,
model: "gpt-image-2",
stream: true,
partial_images: 2,
});
for await (const event of stream) {
if (event.type === "image_generation.partial_image") {
const idx = event.partial_image_index;
const imageBase64 = event.b64_json;
const imageBuffer = Buffer.from(imageBase64, "base64");
fs.writeFileSync(\`river\${idx}.png\`, imageBuffer);
}
}
```
```python
from openai import OpenAI
import base64
client = OpenAI()
stream = client.images.generate(
prompt="Draw a gorgeous image of a river made of white owl feathers, snaking its way through a serene winter landscape",
model="gpt-image-2",
stream=True,
partial_images=2,
)
for event in stream:
if event.type == "image_generation.partial_image":
idx = event.partial_image_index
image_base64 = event.b64_json
image_bytes = base64.b64decode(image_base64)
with open(f"river{idx}.png", "wb") as f:
f.write(image_bytes)
```
#### Result
| Partial 1 | Partial 2 | Final image |
| ------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------- |
|

|

|

|
Prompt: Draw a gorgeous image of a river made of white owl feathers, snaking
its way through a serene winter landscape
### Revised prompt
When using the image generation tool in the Responses API, the mainline model (for example, `gpt-5.5`) will automatically revise your prompt for improved performance.
You can access the revised prompt in the `revised_prompt` field of the image generation call:
Revised prompt response
```json
{
"id": "ig_123",
"type": "image_generation_call",
"status": "completed",
"revised_prompt": "A gray tabby cat hugging an otter. The otter is wearing an orange scarf. Both animals are cute and friendly, depicted in a warm, heartwarming style.",
"result": "..."
}
```
## Edit Images
The [image edits](https://developers.openai.com/api/docs/api-reference/images/createEdit) endpoint lets you:
- Edit existing images
- Generate new images using other images as a reference
- Edit parts of an image by uploading an image and mask that identifies the areas to replace
### Create a new image using image references
You can use one or more images as a reference to generate a new image.
In this example, we'll use 4 input images to generate a new image of a gift basket containing the items in the reference images.
Image API
Edit an image
```python
import base64
from openai import OpenAI
client = OpenAI()
prompt = """
Generate a photorealistic image of a gift basket on a white background
labeled 'Relax & Unwind' with a ribbon and handwriting-like font,
containing all the items in the reference pictures.
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("body-lotion.png", "rb"),
open("bath-bomb.png", "rb"),
open("incense-kit.png", "rb"),
open("soap.png", "rb"),
],
prompt=prompt
)
image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
# Save the image to a file
with open("gift-basket.png", "wb") as f:
f.write(image_bytes)
```
```javascript
import fs from "fs";
import OpenAI, { toFile } from "openai";
const client = new OpenAI();
const prompt = \`
Generate a photorealistic image of a gift basket on a white background
labeled 'Relax & Unwind' with a ribbon and handwriting-like font,
containing all the items in the reference pictures.
\`;
const imageFiles = [
"bath-bomb.png",
"body-lotion.png",
"incense-kit.png",
"soap.png",
];
const images = await Promise.all(
imageFiles.map(async (file) =>
await toFile(fs.createReadStream(file), null, {
type: "image/png",
})
),
);
const response = await client.images.edit({
model: "gpt-image-2",
image: images,
prompt,
});
// Save the image to a file
const image_base64 = response.data[0].b64_json;
const image_bytes = Buffer.from(image_base64, "base64");
fs.writeFileSync("basket.png", image_bytes);
```
```bash
curl -s -D >(grep -i x-request-id >&2) \\
-o >(jq -r '.data[0].b64_json' | base64 --decode > gift-basket.png) \\
-X POST "https://api.openai.com/v1/images/edits" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-F "model=gpt-image-2" \\
-F "image[]=@body-lotion.png" \\
-F "image[]=@bath-bomb.png" \\
-F "image[]=@incense-kit.png" \\
-F "image[]=@soap.png" \\
-F 'prompt=Generate a photorealistic image of a gift basket on a white background labeled "Relax & Unwind" with a ribbon and handwriting-like font, containing all the items in the reference pictures'
```
```cli
openai images edit \\
--model gpt-image-2 \\
--image body-lotion.png \\
--image bath-bomb.png \\
--image incense-kit.png \\
--image soap.png \\
--prompt 'Generate a photorealistic image of a gift basket on a white background labeled "Relax & Unwind" with a ribbon and handwriting-like font, containing all the items in the reference pictures' \\
--raw-output \\
--transform 'data.0.b64_json' | base64 --decode > gift-basket.png
```
### Edit an image using a mask
You can provide a mask to indicate which part of the image should be edited.
When using a mask with GPT Image, additional instructions are sent to the model to help guide the editing process accordingly.
Masking with GPT Image is entirely prompt-based. The model uses the mask as
guidance, but may not follow its exact shape with complete precision.
If you provide multiple input images, the mask will be applied to the first image.
Responses API
Edit an image with a mask
```python
from openai import OpenAI
client = OpenAI()
fileId = create_file("sunlit_lounge.png")
maskId = create_file("mask.png")
response = client.responses.create(
model="gpt-5.5",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": "generate an image of the same sunlit indoor lounge area with a pool but the pool should contain a flamingo",
},
{
"type": "input_image",
"file_id": fileId,
}
],
},
],
tools=[
{
"type": "image_generation",
"quality": "high",
"input_image_mask": {
"file_id": maskId,
}
},
],
)
image_data = [
output.result
for output in response.output
if output.type == "image_generation_call"
]
if image_data:
image_base64 = image_data[0]
with open("lounge.png", "wb") as f:
f.write(base64.b64decode(image_base64))
```
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const fileId = await createFile("sunlit_lounge.png");
const maskId = await createFile("mask.png");
const response = await openai.responses.create({
model: "gpt-5.5",
input: [
{
role: "user",
content: [
{
type: "input_text",
text: "generate an image of the same sunlit indoor lounge area with a pool but the pool should contain a flamingo",
},
{
type: "input_image",
file_id: fileId,
}
],
},
],
tools: [
{
type: "image_generation",
quality: "high",
input_image_mask: {
file_id: maskId,
}
},
],
});
const imageData = response.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData.length > 0) {
const imageBase64 = imageData[0];
const fs = await import("fs");
fs.writeFileSync("lounge.png", Buffer.from(imageBase64, "base64"));
}
```
Image API
Edit an image with a mask
```python
from openai import OpenAI
client = OpenAI()
result = client.images.edit(
model="gpt-image-2",
image=open("sunlit_lounge.png", "rb"),
mask=open("mask.png", "rb"),
prompt="A sunlit indoor lounge area with a pool containing a flamingo"
)
image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
# Save the image to a file
with open("composition.png", "wb") as f:
f.write(image_bytes)
```
```javascript
import fs from "fs";
import OpenAI, { toFile } from "openai";
const client = new OpenAI();
const rsp = await client.images.edit({
model: "gpt-image-2",
image: await toFile(fs.createReadStream("sunlit_lounge.png"), null, {
type: "image/png",
}),
mask: await toFile(fs.createReadStream("mask.png"), null, {
type: "image/png",
}),
prompt: "A sunlit indoor lounge area with a pool containing a flamingo",
});
// Save the image to a file
const image_base64 = rsp.data[0].b64_json;
const image_bytes = Buffer.from(image_base64, "base64");
fs.writeFileSync("lounge.png", image_bytes);
```
```bash
curl -s -D >(grep -i x-request-id >&2) \\
-o >(jq -r '.data[0].b64_json' | base64 --decode > lounge.png) \\
-X POST "https://api.openai.com/v1/images/edits" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-F "model=gpt-image-2" \\
-F "mask=@mask.png" \\
-F "image[]=@sunlit_lounge.png" \\
-F 'prompt=A sunlit indoor lounge area with a pool containing a flamingo'
```
```cli
openai images edit \\
--model gpt-image-2 \\
--image sunlit_lounge.png \\
--mask mask.png \\
--prompt "A sunlit indoor lounge area with a pool containing a flamingo" \\
--raw-output \\
--transform 'data.0.b64_json' | base64 --decode > out.png
```
| Image | Mask | Output |
| ------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|

|

|
|
Prompt: a sunlit indoor lounge area with a pool containing a flamingo
#### Mask requirements
The image to edit and mask must be of the same format and size (less than 50MB in size).
The mask image must also contain an alpha channel. If you're using an image editing tool to create the mask, make sure to save the mask with an alpha channel.
You can modify a black and white image programmatically to add an alpha channel.
Add an alpha channel to a black and white mask
```python
from PIL import Image
from io import BytesIO
# 1. Load your black & white mask as a grayscale image
mask = Image.open(img_path_mask).convert("L")
# 2. Convert it to RGBA so it has space for an alpha channel
mask_rgba = mask.convert("RGBA")
# 3. Then use the mask itself to fill that alpha channel
mask_rgba.putalpha(mask)
# 4. Convert the mask into bytes
buf = BytesIO()
mask_rgba.save(buf, format="PNG")
mask_bytes = buf.getvalue()
# 5. Save the resulting file
img_path_mask_alpha = "mask_alpha.png"
with open(img_path_mask_alpha, "wb") as f:
f.write(mask_bytes)
```
### Image input fidelity
The `input_fidelity` parameter controls how strongly a model preserves details from input images during edits and reference-image workflows. For `gpt-image-2`, omit this parameter; the API doesn't allow changing it because the model processes every image input at high fidelity automatically.
Because `gpt-image-2` always processes image inputs at high fidelity, image
input tokens can be higher for edit requests that include reference images. To
understand the cost implications, refer to the [vision
costs](https://developers.openai.com/api/docs/guides/images-vision?api-mode=responses#calculating-costs)
section.
## Customize Image Output
You can configure the following output options:
- **Size**: Image dimensions (for example, `1024x1024`, `1024x1536`)
- **Quality**: Rendering quality (for example, `low`, `medium`, `high`)
- **Format**: File output format
- **Compression**: Compression level (0-100%) for JPEG and WebP formats
- **Background**: Opaque or automatic
`size`, `quality`, and `background` support the `auto` option, where the model will automatically select the best option based on the prompt.
`gpt-image-2` doesn't currently support transparent backgrounds. Requests with
`background: "transparent"` aren't supported for this model.
### Size and quality options
`gpt-image-2` accepts any resolution in the `size` parameter when it satisfies the constraints below. Square images are typically fastest to generate.
| Popular sizes |
-
1024x1024 (square)
-
1536x1024 (landscape)
-
1024x1536 (portrait)
-
2048x2048 (2K square)
-
2048x1152 (2K landscape)
-
3840x2160 (4K landscape)
-
2160x3840 (4K portrait)
-
auto (default)
|
| Size constraints |
-
Maximum edge length must be less than or equal to{" "}
3840px
-
Both edges must be multiples of
16px
-
Long edge to short edge ratio must not exceed
3:1
-
Total pixels must be at least
655,360 and no more than{" "}
8,294,400
|
| Quality options |
-
low
-
medium
-
high
-
auto (default)
|
Use `quality: "low"` for fast drafts, thumbnails, and quick iterations. It is
the fastest option and works well for many common use cases before you move to
`medium` or `high` for final assets.
Outputs that contain more than `2560x1440` (`3,686,400`) total pixels,
typically referred to as 2K, are considered experimental.
### Output format
The Image API returns base64-encoded image data.
The default format is `png`, but you can also request `jpeg` or `webp`.
If using `jpeg` or `webp`, you can also specify the `output_compression` parameter to control the compression level (0-100%). For example, `output_compression=50` will compress the image by 50%.
Using `jpeg` is faster than `png`, so you should prioritize this format if
latency is a concern.
## Limitations
GPT Image models (`gpt-image-2`, `gpt-image-1.5`, `gpt-image-1`, and `gpt-image-1-mini`) are powerful and versatile image generation models, but they still have some limitations to be aware of:
- **Latency:** Complex prompts may take up to 2 minutes to process.
- **Text Rendering:** Although significantly improved, the model can still struggle with precise text placement and clarity.
- **Consistency:** While capable of producing consistent imagery, the model may occasionally struggle to maintain visual consistency for recurring characters or brand elements across multiple generations.
- **Composition Control:** Despite improved instruction following, the model may have difficulty placing elements precisely in structured or layout-sensitive compositions.
### Content Moderation
All prompts and generated images are filtered in accordance with our [content policy](https://openai.com/policies/usage-policies/).
For image generation using GPT Image models (`gpt-image-2`, `gpt-image-1.5`, `gpt-image-1`, and `gpt-image-1-mini`), you can control moderation strictness with the `moderation` parameter. This parameter supports two values:
- `auto` (default): Standard filtering that seeks to limit creating certain categories of potentially age-inappropriate content.
- `low`: Less restrictive filtering.
### Supported models
When using image generation in the Responses API, `gpt-5` and newer models should support the image generation tool. [Check the model detail page for your model](https://developers.openai.com/api/docs/models) to confirm if your desired model can use the image generation tool.
## Cost and latency
### `gpt-image-2` output tokens
For `gpt-image-2`, use the calculator to estimate output tokens from the requested `quality` and `size`:
### Models prior to `gpt-image-2`
GPT Image models prior to `gpt-image-2` generate images by first producing specialized image tokens. Both latency and eventual cost are proportional to the number of tokens required to render an image—larger image sizes and higher quality settings result in more tokens.
The number of tokens generated depends on image dimensions and quality:
| Quality | Square (1024×1024) | Portrait (1024×1536) | Landscape (1536×1024) |
| ------- | ------------------ | -------------------- | --------------------- |
| Low | 272 tokens | 408 tokens | 400 tokens |
| Medium | 1056 tokens | 1584 tokens | 1568 tokens |
| High | 4160 tokens | 6240 tokens | 6208 tokens |
Note that you will also need to account for [input tokens](https://developers.openai.com/api/docs/guides/images-vision?api-mode=responses#calculating-costs): text tokens for the prompt and image tokens for the input images if editing images.
Because `gpt-image-2` always processes image inputs at high fidelity, edit requests that include reference images can use more input tokens.
Refer to the [pricing page](https://developers.openai.com/api/docs/pricing#image-generation) for current
text and image token prices, and use the [Calculating costs](#calculating-costs)
section below to estimate request costs.
The final cost is the sum of:
- input text tokens
- input image tokens if using the edits endpoint
- image output tokens
### Calculating costs
Use the pricing calculator below to estimate request costs for GPT Image models.
`gpt-image-2` supports thousands of valid resolutions; the table below lists the
same sizes used for previous GPT Image models for comparison. For GPT Image 1.5,
GPT Image 1, and GPT Image 1 Mini, the legacy per-image output pricing table is
also listed below. You should still account for text and image input tokens when
estimating the total cost of a request.
A larger non-square resolution can sometimes produce fewer output tokens than
a smaller or square resolution at the same quality setting.
| Model |
Quality
|
1024 x 1024 |
1024 x 1536 |
1536 x 1024 |
GPT Image 2
Additional sizes available
|
Low |
$0.006 |
$0.005 |
$0.005 |
| Medium |
$0.053 |
$0.041 |
$0.041 |
| High |
$0.211 |
$0.165 |
$0.165 |
|
GPT Image 1.5
|
Low |
$0.009 |
$0.013 |
$0.013 |
| Medium |
$0.034 |
$0.05 |
$0.05 |
| High |
$0.133 |
$0.2 |
$0.2 |
|
GPT Image 1
|
Low |
$0.011 |
$0.016 |
$0.016 |
| Medium |
$0.042 |
$0.063 |
$0.063 |
| High |
$0.167 |
$0.25 |
$0.25 |
|
GPT Image 1 Mini
|
Low |
$0.005 |
$0.006 |
$0.006 |
| Medium |
$0.011 |
$0.015 |
$0.015 |
| High |
$0.036 |
$0.052 |
$0.052 |
### Partial images cost
If you want to [stream image generation](#streaming) using the `partial_images` parameter, each partial image will incur an additional 100 image output tokens.
---
# Image generation
The image generation tool allows you to generate images using a text prompt, and optionally image inputs. It uses GPT Image models, including `gpt-image-2`, `gpt-image-1.5`, `gpt-image-1`, and `gpt-image-1-mini`, and automatically optimizes text inputs for improved performance.
To learn more about image generation, refer to our dedicated [image generation
guide](https://developers.openai.com/api/docs/guides/image-generation?api=responses).
## Usage
When you include the `image_generation` tool in your request, the model can decide when and how to generate images as part of the conversation, using your prompt and any provided image inputs.
The `image_generation_call` tool call result will include a base64-encoded image.
Generate an image
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5.5",
input: "Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools: [{type: "image_generation"}],
});
// Save the image to a file
const imageData = response.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData.length > 0) {
const imageBase64 = imageData[0];
const fs = await import("fs");
fs.writeFileSync("otter.png", Buffer.from(imageBase64, "base64"));
}
```
```python
from openai import OpenAI
import base64
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
input="Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools=[{"type": "image_generation"}],
)
# Save the image to a file
image_data = [
output.result
for output in response.output
if output.type == "image_generation_call"
]
if image_data:
image_base64 = image_data[0]
with open("otter.png", "wb") as f:
f.write(base64.b64decode(image_base64))
```
You can [provide input images](https://developers.openai.com/api/docs/guides/image-generation?image-generation-model=gpt-image#edit-images) using file IDs or base64 data.
To force the image generation tool call, you can set the parameter `tool_choice` to `{"type": "image_generation"}`.
### Tool options
You can configure the following output options as parameters for the [image generation tool](https://developers.openai.com/api/docs/api-reference/responses/create#responses-create-tools):
- Size: Image dimensions, for example, 1024 × 1024 or 1024 × 1536
- Quality: Rendering quality, for example, low, medium, or high
- Format: File output format
- Compression: Compression level (0-100%) for JPEG and WebP formats
- Background: Transparent or opaque
- Action: Whether the request should automatically choose, generate, or edit an image
`size`, `quality`, and `background` support the `auto` option, where the model will automatically select the best option based on the prompt.
`gpt-image-2` supports flexible `size` values that meet its [resolution constraints](https://developers.openai.com/api/docs/guides/image-generation#size-and-quality-options). It doesn't currently support transparent backgrounds, so requests with `background: "transparent"` fail.
For more details on available options, refer to the [image generation guide](https://developers.openai.com/api/docs/guides/image-generation#customize-image-output).
When using the Responses API image generation tool, supported GPT Image models can choose whether to generate a new image or edit one already in the conversation. The optional `action` parameter controls this behavior: keep `action` set to `auto` so the model chooses whether to generate or edit, or set it to `generate` or `edit` to force that behavior. If not specified, the default is `auto`.
### Revised prompt
When using the image generation tool, the mainline model, for example, `gpt-5.5`, will automatically revise your prompt for improved performance.
You can access the revised prompt in the `revised_prompt` field of the image generation call:
```json
{
"id": "ig_123",
"type": "image_generation_call",
"status": "completed",
"revised_prompt": "A gray tabby cat hugging an otter. The otter is wearing an orange scarf. Both animals are cute and friendly, depicted in a warm, heartwarming style.",
"result": "..."
}
```
### Prompting tips
Image generation works best when you use terms like `draw` or `edit` in your prompt.
For example, if you want to combine images, instead of saying `combine` or `merge`, you can say something like "edit the first image by adding this element from the second image."
## Multi-turn editing
You can iteratively edit images by referencing previous response or image IDs. This allows you to refine images across conversation turns.
Using previous response ID
Multi-turn image generation
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5.5",
input:
"Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools: [{ type: "image_generation" }],
});
const imageData = response.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData.length > 0) {
const imageBase64 = imageData[0];
const fs = await import("fs");
fs.writeFileSync("cat_and_otter.png", Buffer.from(imageBase64, "base64"));
}
// Follow up
const response_fwup = await openai.responses.create({
model: "gpt-5.5",
previous_response_id: response.id,
input: "Now make it look realistic",
tools: [{ type: "image_generation" }],
});
const imageData_fwup = response_fwup.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData_fwup.length > 0) {
const imageBase64 = imageData_fwup[0];
const fs = await import("fs");
fs.writeFileSync(
"cat_and_otter_realistic.png",
Buffer.from(imageBase64, "base64")
);
}
```
```python
from openai import OpenAI
import base64
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
input="Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools=[{"type": "image_generation"}],
)
image_data = [
output.result
for output in response.output
if output.type == "image_generation_call"
]
if image_data:
image_base64 = image_data[0]
with open("cat_and_otter.png", "wb") as f:
f.write(base64.b64decode(image_base64))
# Follow up
response_fwup = client.responses.create(
model="gpt-5.5",
previous_response_id=response.id,
input="Now make it look realistic",
tools=[{"type": "image_generation"}],
)
image_data_fwup = [
output.result
for output in response_fwup.output
if output.type == "image_generation_call"
]
if image_data_fwup:
image_base64 = image_data_fwup[0]
with open("cat_and_otter_realistic.png", "wb") as f:
f.write(base64.b64decode(image_base64))
```
Using image ID
Multi-turn image generation
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5.5",
input:
"Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools: [{ type: "image_generation" }],
});
const imageGenerationCalls = response.output.filter(
(output) => output.type === "image_generation_call"
);
const imageData = imageGenerationCalls.map((output) => output.result);
if (imageData.length > 0) {
const imageBase64 = imageData[0];
const fs = await import("fs");
fs.writeFileSync("cat_and_otter.png", Buffer.from(imageBase64, "base64"));
}
// Follow up
const response_fwup = await openai.responses.create({
model: "gpt-5.5",
input: [
{
role: "user",
content: [{ type: "input_text", text: "Now make it look realistic" }],
},
{
type: "image_generation_call",
id: imageGenerationCalls[0].id,
},
],
tools: [{ type: "image_generation" }],
});
const imageData_fwup = response_fwup.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData_fwup.length > 0) {
const imageBase64 = imageData_fwup[0];
const fs = await import("fs");
fs.writeFileSync(
"cat_and_otter_realistic.png",
Buffer.from(imageBase64, "base64")
);
}
```
```python
import openai
import base64
response = openai.responses.create(
model="gpt-5.5",
input="Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools=[{"type": "image_generation"}],
)
image_generation_calls = [
output
for output in response.output
if output.type == "image_generation_call"
]
image_data = [output.result for output in image_generation_calls]
if image_data:
image_base64 = image_data[0]
with open("cat_and_otter.png", "wb") as f:
f.write(base64.b64decode(image_base64))
# Follow up
response_fwup = openai.responses.create(
model="gpt-5.5",
input=[
{
"role": "user",
"content": [{"type": "input_text", "text": "Now make it look realistic"}],
},
{
"type": "image_generation_call",
"id": image_generation_calls[0].id,
},
],
tools=[{"type": "image_generation"}],
)
image_data_fwup = [
output.result
for output in response_fwup.output
if output.type == "image_generation_call"
]
if image_data_fwup:
image_base64 = image_data_fwup[0]
with open("cat_and_otter_realistic.png", "wb") as f:
f.write(base64.b64decode(image_base64))
```
## Streaming
The image generation tool supports streaming partial images while it generates the final result. This provides faster visual feedback for users and improves perceived latency.
You can set the number of partial images (1-3) with the `partial_images` parameter.
Stream an image
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const prompt =
"Draw a gorgeous image of a river made of white owl feathers, snaking its way through a serene winter landscape";
const stream = await openai.images.generate({
prompt: prompt,
model: "gpt-image-2",
stream: true,
partial_images: 2,
});
for await (const event of stream) {
if (event.type === "image_generation.partial_image") {
const idx = event.partial_image_index;
const imageBase64 = event.b64_json;
const imageBuffer = Buffer.from(imageBase64, "base64");
fs.writeFileSync(\`river\${idx}.png\`, imageBuffer);
}
}
```
```python
from openai import OpenAI
import base64
client = OpenAI()
stream = client.images.generate(
prompt="Draw a gorgeous image of a river made of white owl feathers, snaking its way through a serene winter landscape",
model="gpt-image-2",
stream=True,
partial_images=2,
)
for event in stream:
if event.type == "image_generation.partial_image":
idx = event.partial_image_index
image_base64 = event.b64_json
image_bytes = base64.b64decode(image_base64)
with open(f"river{idx}.png", "wb") as f:
f.write(image_bytes)
```
## Supported models
The following models support the image generation tool:
- `gpt-4o`
- `gpt-4o-mini`
- `gpt-4.1`
- `gpt-4.1-mini`
- `gpt-4.1-nano`
- `o3`
- `gpt-5`
- `gpt-5.4-mini`
- `gpt-5.4-nano`
- `gpt-5-nano`
- `gpt-5.5`
- `gpt-5.2`
The model used for the image generation process is always a GPT Image model, including `gpt-image-2`, `gpt-image-1.5`, `gpt-image-1`, and `gpt-image-1-mini`, but these models aren't valid values for the `model` field in the Responses API. Use a text-capable mainline model (for example, `gpt-5.5` or `gpt-5`) with the hosted `image_generation` tool.
---
# Images and vision
## Overview
In this guide, you will learn about building applications involving images with the OpenAI API.
If you know what you want to build, find your use case below to get started. If you're not sure where to start, continue reading to get an overview.
### A tour of image-related use cases
Recent language models can process image inputs and analyze them—a capability known as **vision**. GPT Image models can use text and image inputs to create new images or edit existing ones.
The OpenAI API offers several endpoints to process images as input or generate them as output, enabling you to build powerful multimodal applications.
| API | Supported use cases |
| ---------------------------------------------------- | --------------------------------------------------------------------- |
| [Responses API](https://developers.openai.com/api/docs/api-reference/responses) | Analyze images and use them as input and/or generate images as output |
| [Images API](https://developers.openai.com/api/docs/api-reference/images) | Generate images as output, optionally using images as input |
| [Chat Completions API](https://developers.openai.com/api/docs/api-reference/chat) | Analyze images and use them as input to generate text or audio |
To learn more about the input and output modalities supported by our models, refer to our [models page](https://developers.openai.com/api/docs/models).
## Generate or edit images
You can generate or edit images using the Image API or the Responses API.
The state-of-the-art image generation model, `gpt-image-2`, can understand text and images and use broad world knowledge to generate images with strong instruction following and contextual awareness.
Generate images with Responses
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-4.1-mini",
input: "Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools: [{type: "image_generation"}],
});
// Save the image to a file
const imageData = response.output
.filter((output) => output.type === "image_generation_call")
.map((output) => output.result);
if (imageData.length > 0) {
const imageBase64 = imageData[0];
const fs = await import("fs");
fs.writeFileSync("cat_and_otter.png", Buffer.from(imageBase64, "base64"));
}
```
```python
from openai import OpenAI
import base64
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-mini",
input="Generate an image of gray tabby cat hugging an otter with an orange scarf",
tools=[{"type": "image_generation"}],
)
// Save the image to a file
image_data = [
output.result
for output in response.output
if output.type == "image_generation_call"
]
if image_data:
image_base64 = image_data[0]
with open("cat_and_otter.png", "wb") as f:
f.write(base64.b64decode(image_base64))
```
```cli
openai responses create \\
--model gpt-5.5 \\
--raw-output \\
--transform 'output.#(type=="image_generation_call").result' <<'YAML' | base64 --decode > cat_and_otter.png
tools:
- type: image_generation
input: Generate an image of a gray tabby cat hugging an otter with an orange scarf.
YAML
```
You can learn more about image generation in our [Image
generation](https://developers.openai.com/api/docs/guides/image-generation) guide.
### Using world knowledge for image generation
GPT Image models can use visual understanding of the world to generate lifelike images including real-life details without a reference.
For example, if you prompt GPT Image to generate an image of a glass cabinet with the most popular semi-precious stones, the model knows enough to select gemstones like amethyst, rose quartz, jade, etc, and depict them in a realistic way.
## Analyze images
**Vision** is the ability for a model to "see" and understand images. If there is text in an image, the model can also understand the text.
It can understand most visual elements, including objects, shapes, colors, and textures, even if there are some [limitations](#limitations).
### Giving a model images as input
You can provide images as input to generation requests in multiple ways:
- By providing a fully qualified URL to an image file
- By providing an image as a Base64-encoded data URL
- By providing a file ID (created with the [Files API](https://developers.openai.com/api/docs/api-reference/files))
You can provide multiple images as input in a single request by including multiple images in the `content` array, but keep in mind that [images count as tokens](#calculating-costs) and will be billed accordingly.
Passing a URL
Analyze the content of an image
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-4.1-mini",
input: [{
role: "user",
content: [
{ type: "input_text", text: "what's in this image?" },
{
type: "input_image",
image_url: "https://api.nga.gov/iiif/a2e6da57-3cd1-4235-b20e-95dcaefed6c8/full/!800,800/0/default.jpg",
},
],
}],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-mini",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"image_url": "https://api.nga.gov/iiif/a2e6da57-3cd1-4235-b20e-95dcaefed6c8/full/!800,800/0/default.jpg",
},
],
}],
)
print(response.output_text)
```
```csharp
using OpenAI.Responses;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5", apiKey: key);
Uri imageUrl = new("https://api.nga.gov/iiif/a2e6da57-3cd1-4235-b20e-95dcaefed6c8/full/!800,800/0/default.jpg");
OpenAIResponse response = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("What is in this image?"),
ResponseContentPart.CreateInputImagePart(imageUrl)
])
]);
Console.WriteLine(response.GetOutputText());
```
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-4.1-mini",
"input": [
{
"role": "user",
"content": [
{"type": "input_text", "text": "what is in this image?"},
{
"type": "input_image",
"image_url": "https://api.nga.gov/iiif/a2e6da57-3cd1-4235-b20e-95dcaefed6c8/full/!800,800/0/default.jpg"
}
]
}
]
}'
```
```cli
openai responses create \\
--model gpt-5.5 \\
--raw-output \\
--transform 'output.#(type=="message").content.0.text' <<'YAML'
input:
- role: user
content:
- type: input_text
text: What is in this image?
- type: input_image
image_url: https://api.nga.gov/iiif/a2e6da57-3cd1-4235-b20e-95dcaefed6c8/full/!800,800/0/default.jpg
YAML
```
Passing a Base64 encoded image
Analyze the content of an image
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const imagePath = "path_to_your_image.jpg";
const base64Image = fs.readFileSync(imagePath, "base64");
const response = await openai.responses.create({
model: "gpt-4.1-mini",
input: [
{
role: "user",
content: [
{ type: "input_text", text: "what's in this image?" },
{
type: "input_image",
image_url: \`data:image/jpeg;base64,\${base64Image}\`,
},
],
},
],
});
console.log(response.output_text);
```
```python
import base64
from openai import OpenAI
client = OpenAI()
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the Base64 string
base64_image = encode_image(image_path)
response = client.responses.create(
model="gpt-4.1",
input=[
{
"role": "user",
"content": [
{ "type": "input_text", "text": "what's in this image?" },
{
"type": "input_image",
"image_url": f"data:image/jpeg;base64,{base64_image}",
},
],
}
],
)
print(response.output_text)
```
```csharp
using OpenAI.Responses;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5", apiKey: key);
Uri imageUrl = new("https://openai-documentation.vercel.app/images/cat_and_otter.png");
using HttpClient http = new();
// Download an image as stream
using var stream = await http.GetStreamAsync(imageUrl);
OpenAIResponse response1 = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("What is in this image?"),
ResponseContentPart.CreateInputImagePart(BinaryData.FromStream(stream), "image/png")
])
]);
Console.WriteLine($"From image stream: {response1.GetOutputText()}");
// Download an image as byte array
byte[] bytes = await http.GetByteArrayAsync(imageUrl);
OpenAIResponse response2 = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("What is in this image?"),
ResponseContentPart.CreateInputImagePart(BinaryData.FromBytes(bytes), "image/png")
])
]);
Console.WriteLine($"From byte array: {response2.GetOutputText()}");
```
Passing a file ID
Analyze the content of an image
```javascript
import OpenAI from "openai";
import fs from "fs";
const openai = new OpenAI();
// Function to create a file with the Files API
async function createFile(filePath) {
const fileContent = fs.createReadStream(filePath);
const result = await openai.files.create({
file: fileContent,
purpose: "vision",
});
return result.id;
}
// Getting the file ID
const fileId = await createFile("path_to_your_image.jpg");
const response = await openai.responses.create({
model: "gpt-4.1-mini",
input: [
{
role: "user",
content: [
{ type: "input_text", text: "what's in this image?" },
{
type: "input_image",
file_id: fileId,
},
],
},
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
# Function to create a file with the Files API
def create_file(file_path):
with open(file_path, "rb") as file_content:
result = client.files.create(
file=file_content,
purpose="vision",
)
return result.id
# Getting the file ID
file_id = create_file("path_to_your_image.jpg")
response = client.responses.create(
model="gpt-4.1-mini",
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": "what's in this image?"},
{
"type": "input_image",
"file_id": file_id,
},
],
}],
)
print(response.output_text)
```
```csharp
using OpenAI.Files;
using OpenAI.Responses;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5", apiKey: key);
string filename = "cat_and_otter.png";
Uri imageUrl = new($"https://openai-documentation.vercel.app/images/{filename}");
using var http = new HttpClient();
// Download an image as stream
using var stream = await http.GetStreamAsync(imageUrl);
OpenAIFileClient files = new(key);
OpenAIFile file = await files.UploadFileAsync(BinaryData.FromStream(stream), filename, FileUploadPurpose.Vision);
OpenAIResponse response = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("what's in this image?"),
ResponseContentPart.CreateInputImagePart(file.Id)
])
]);
Console.WriteLine(response.GetOutputText());
```
### Image input requirements
Input images must meet the following requirements to be used in the API.
| Supported file types |
- PNG (`.png`) - JPEG (`.jpeg` and `.jpg`) - WEBP (`.webp`) - Non-animated
GIF (`.gif`)
|
| Size limits |
- Up to 512 MB total payload size per request - Up to 1500 individual
image inputs per request
|
| Other requirements |
- No watermarks or logos - No NSFW content - Clear enough for a human to
understand
|
### Choose an image detail level
The `detail` parameter tells the model what level of detail to use when processing and understanding the image (`low`, `high`, `original`, or `auto`). If you skip the parameter, the model will use `auto`. This behavior is the same in both the Responses API and the Chat Completions API. On `gpt-5.5`, `auto` and the default omitted behavior are equivalent to `original`.
Use the following guidance to choose a detail level:
| Detail level | Best for |
| ------------ | ---------------------------------------------------------------------------------------------------------------------------------------------- |
| `low` | Fast, low-cost understanding when fine visual detail is not important. The model receives a low-resolution 512px x 512px version of the image. |
| `high` | Standard high-fidelity image understanding. |
| `original` | Large, dense, spatially sensitive, or computer-use images. Available on `gpt-5.4` and future models. |
| `auto` | Automatic detail selection. On `gpt-5.5`, `auto` and the omitted/default behavior are equivalent to `original`. |
For computer use, localization, and click-accuracy use cases on `gpt-5.4` and future models, we recommend `"detail": "original"`. See the [Computer use guide](https://developers.openai.com/api/docs/guides/tools-computer-use) for more detail.
Read more about how models resize images in the [Model sizing
behavior](#model-sizing-behavior) section, and about token costs in the
[Calculating costs](#calculating-costs) section below.
### Model sizing behavior
Different models use different resizing rules before image tokenization:
| Model family |
Supported detail levels |
Patch and resizing behavior |
gpt-5.5
|
low, high, original,
auto
|
high allows up to 2,500 patches or a 2048-pixel maximum
dimension. original allows up to 10,000 patches or a
6000-pixel maximum dimension. If either limit is exceeded, we resize the
image while preserving aspect ratio to fit within the lesser of those two
constraints for the selected detail level. auto and omitted
detail use the same sizing behavior as
original. [Full resizing details
below.](#patch-based-image-tokenization)
|
gpt-5.4
|
low, high, original,
auto
|
high allows up to 2,500 patches or a 2048-pixel maximum
dimension. original allows up to 10,000 patches or a
6000-pixel maximum dimension. If either limit is exceeded, we resize the
image while preserving aspect ratio to fit within the lesser of those two
constraints for the selected detail level. auto and omitted
detail use the same sizing behavior as
high.[Full resizing details
below.](#patch-based-image-tokenization)
|
gpt-5.4-mini, gpt-5.4-nano,
gpt-5-mini, gpt-5-nano, gpt-5.2,
gpt-5.3-codex, gpt-5-codex-mini,
gpt-5.1-codex-mini, gpt-5.2-codex,
gpt-5.2-chat-latest, o4-mini, and the{" "}
gpt-4.1-mini and gpt-4.1-nano 2025-04-14
snapshot variants
|
low, high, auto
|
high allows up to 1,536 patches or a 2048-pixel maximum
dimension. If either limit is exceeded, we resize the image while
preserving aspect ratio to fit within the lesser of those two constraints.
[Full resizing details below.](#patch-based-image-tokenization)
|
GPT-4o, GPT-4.1, GPT-4o-mini,
computer-use-preview, and o-series models except
o4-mini
|
low, high, auto
|
Use tile-based resizing behavior. See{" "}
the detailed behavior below
|
## Calculating costs
Image inputs are metered and charged in token units similar to text inputs. How images are converted to text token inputs varies based on the model. You can find a vision pricing calculator in the FAQ section of the [pricing page](https://openai.com/api/pricing/).
### Patch-based image tokenization
Some models tokenize images by covering them with 32px x 32px patches. Each model defines a maximum patch budget. The token cost of an image is determined as follows:
A. Compute how many 32px x 32px patches are needed to cover the original image. A patch may extend beyond the image boundary.
```
original_patch_count = ceil(width/32)×ceil(height/32)
```
B. If the original image would exceed the model's patch budget, scale it down proportionally until it fits within that budget. Then adjust the scale so the final resized image stays within budget after converting to integer pixel dimensions and computing patch coverage.
```
shrink_factor = sqrt((32^2 * patch_budget) / (width * height))
adjusted_shrink_factor = shrink_factor * min(
floor(width * shrink_factor / 32) / (width * shrink_factor / 32),
floor(height * shrink_factor / 32) / (height * shrink_factor / 32)
)
```
C. Convert the adjusted scale into integer pixel dimensions, then compute the number of patches needed to cover the resized image. This resized patch count is the image-token count before applying the model multiplier, and it is capped by the model's patch budget.
```
resized_patch_count = ceil(resized_width/32)×ceil(resized_height/32)
```
D. Apply a multiplier based on the model to get the total tokens:
| Model | Multiplier |
| --------------- | ---------- |
| `gpt-5.4-mini` | 1.62 |
| `gpt-5.4-nano` | 2.46 |
| `gpt-5-mini` | 1.62 |
| `gpt-5-nano` | 2.46 |
| `gpt-4.1-mini*` | 1.62 |
| `gpt-4.1-nano*` | 2.46 |
| `o4-mini` | 1.72 |
_For `gpt-4.1-mini` and `gpt-4.1-nano`, this applies to the 2025-04-14 snapshot variants._
**Cost calculation examples for a model with a 1,536-patch budget**
- A 1024 x 1024 image has a post-resize patch count of **1024**
- A. `original_patch_count = ceil(1024 / 32) * ceil(1024 / 32) = 32 * 32 = 1024`
- B. `1024` is below the `1,536` patch budget, so no resize is needed.
- C. `resized_patch_count = 1024`
- Resized patch count before the model multiplier: `1024`
- Multiply by the model's token multiplier to get the billed token units.
- A 1800 x 2400 image has a post-resize patch count of **1452**
- A. `original_patch_count = ceil(1800 / 32) * ceil(2400 / 32) = 57 * 75 = 4275`
- B. `4275` exceeds the `1,536` patch budget, so we first compute `shrink_factor = sqrt((32^2 * 1536) / (1800 * 2400)) = 0.603`.
- We then adjust that scale so the final integer pixel dimensions stay within budget after patch counting: `adjusted_shrink_factor = 0.603 * min(floor(1800 * 0.603 / 32) / (1800 * 0.603 / 32), floor(2400 * 0.603 / 32) / (2400 * 0.603 / 32)) = 0.586`.
- Resized image in integer pixels: `1056 x 1408`
- C. `resized_patch_count = ceil(1056 / 32) * ceil(1408 / 32) = 33 * 44 = 1452`
- Resized patch count before the model multiplier: `1452`
- Multiply by the model's token multiplier to get the billed token units.
### Tile-based image tokenization
#### GPT-4o, GPT-4.1, GPT-4o-mini, CUA, and o-series (except o4-mini)
The token cost of an image is determined by two factors: size and detail.
Any image with `"detail": "low"` costs a set, base number of tokens. This amount varies by model. To calculate the cost of an image with `"detail": "high"`, we do the following:
- Scale to fit in a 2048px x 2048px square, maintaining original aspect ratio
- Scale so that the image's shortest side is 768px long
- Count the number of 512px squares in the image. Each square costs a set amount of tokens, shown below.
- Add the base tokens to the total
| Model | Base tokens | Tile tokens |
| ------------------------ | ----------- | ----------- |
| gpt-5, gpt-5-chat-latest | 70 | 140 |
| 4o, 4.1, 4.5 | 85 | 170 |
| 4o-mini | 2833 | 5667 |
| o1, o1-pro, o3 | 75 | 150 |
| computer-use-preview | 65 | 129 |
### GPT Image 1
For GPT Image 1, we calculate the cost of an image input the same way as described above, except that we scale down the image so that the shortest side is 512px instead of 768px.
The price depends on the dimensions of the image and the [input fidelity](https://developers.openai.com/api/docs/guides/image-generation?image-generation-model=gpt-image-1#input-fidelity).
When input fidelity is set to low, the base cost is 65 image tokens, and each tile costs 129 image tokens.
When using high input fidelity, we add a set number of tokens based on the image's aspect ratio in addition to the image tokens described above.
- If your image is square, we add 4160 extra input image tokens.
- If it is closer to portrait or landscape, we add 6240 extra tokens.
To see pricing for image input tokens, refer to our [pricing page](https://developers.openai.com/api/docs/pricing#latest-models).
## Limitations
While models with vision capabilities are powerful and can be used in many situations, it's important to understand the limitations of these models. Here are some known limitations:
- **Medical images**: The model is not suitable for interpreting specialized medical images like CT scans and shouldn't be used for medical advice.
- **Non-English**: The model may not perform optimally when handling images with text of non-Latin alphabets, such as Japanese or Korean.
- **Small text**: Enlarge text within the image to improve readability. When available, using `"detail": "original"` can also help performance.
- **Rotation**: The model may misinterpret rotated or upside-down text and images.
- **Visual elements**: The model may struggle to understand graphs or text where colors or styles—like solid, dashed, or dotted lines—vary.
- **Spatial reasoning**: The model struggles with tasks requiring precise spatial localization, such as identifying chess positions.
- **Accuracy**: The model may generate incorrect descriptions or captions in certain scenarios.
- **Image shape**: The model struggles with panoramic and fisheye images.
- **Metadata and resizing**: The model doesn't process original file names or metadata. Depending on image size and `detail` level, images may be resized before analysis, affecting their original dimensions.
- **Counting**: The model may give approximate counts for objects in images.
- **CAPTCHAS**: For safety reasons, our system blocks the submission of CAPTCHAs.
---
We process images at the token level, so each image we process counts towards your tokens per minute (TPM) limit.
For the most precise and up-to-date estimates for image processing, please use our image pricing calculator available [here](https://openai.com/api/pricing/).
---
# Integrations and observability
After the workflow shape is clear, the next questions are which external surfaces should live inside the agent loop and how you will inspect what actually happened at runtime.
## Choose what lives in the SDK
| Need | Start with | Why |
| --------------------------------------------------------- | ----------------------------------------------------- | ------------------------------------------------------------------- |
| Give an agent access to public, remotely hosted MCP tools | Hosted MCP tools in the SDK | The model can call the remote MCP server through the hosted surface |
| Connect local or private MCP servers from your runtime | SDK-managed MCP servers over stdio or streamable HTTP | Your runtime owns the connection, approvals, and network boundaries |
| Debug prompts, tools, handoffs, or approvals | Built-in tracing | Traces show the end-to-end record before you formalize evals |
Tool capability semantics still live in [Using tools](https://developers.openai.com/api/docs/guides/tools). This page focuses on the SDK-specific MCP wiring and observability loop.
## MCP
Use hosted MCP tools when the remote server should run through the model surface.
Attach a hosted MCP server
```typescript
import { Agent, hostedMcpTool } from "@openai/agents";
const agent = new Agent({
name: "MCP assistant",
instructions: "Use the MCP tools to answer questions.",
tools: [
hostedMcpTool({
serverLabel: "gitmcp",
serverUrl: "https://gitmcp.io/openai/codex",
}),
],
});
```
```python
from agents import Agent, HostedMCPTool
agent = Agent(
name="MCP assistant",
instructions="Use the MCP tools to answer questions.",
tools=[
HostedMCPTool(
tool_config={
"type": "mcp",
"server_label": "gitmcp",
"server_url": "https://gitmcp.io/openai/codex",
"require_approval": "never",
}
)
],
)
```
Use local transports when your application should connect to the MCP server directly.
Connect a local MCP server
```typescript
import { Agent, MCPServerStdio, run } from "@openai/agents";
const server = new MCPServerStdio({
name: "Filesystem MCP Server",
fullCommand: "npx -y @modelcontextprotocol/server-filesystem ./sample_files",
});
await server.connect();
try {
const agent = new Agent({
name: "Filesystem assistant",
instructions: "Read files with the MCP tools before answering.",
mcpServers: [server],
});
const result = await run(agent, "Read the files and list them.");
console.log(result.finalOutput);
} finally {
await server.close();
}
```
```python
import asyncio
from agents import Agent, Runner
from agents.mcp import MCPServerStdio
async def main() -> None:
async with MCPServerStdio(
name="Filesystem MCP Server",
params={
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"./sample_files",
],
},
) as server:
agent = Agent(
name="Filesystem assistant",
instructions="Read files with the MCP tools before answering.",
mcp_servers=[server],
)
result = await Runner.run(agent, "Read the files and list them.")
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
```
The practical split is:
- Use **hosted MCP** for public remote servers that fit the platform trust model.
- Use **local or private MCP** when your runtime should own connectivity, filtering, or approvals.
For the platform-wide concept, trust model, and product support story, keep [MCP and Connectors](https://developers.openai.com/api/docs/guides/tools-connectors-mcp) as the canonical reference.
## Tracing
Tracing is built into the Agents SDK and is enabled by default in the normal server-side SDK path. Every run can emit a structured record of model calls, tool calls, handoffs, guardrails, and custom spans, which you can inspect in the [Traces dashboard](https://platform.openai.com/traces).
The default trace usually gives you:
- the overall run or workflow
- each model call
- tool calls and their outputs
- handoffs and guardrails
- any custom spans you wrap around the workflow
If you need less tracing, use the SDK-level or per-run tracing controls rather than removing all observability from the workflow.
Wrap multiple runs in one trace
```typescript
import { Agent, run, withTrace } from "@openai/agents";
const agent = new Agent({
name: "Joke generator",
instructions: "Tell funny jokes.",
});
await withTrace("Joke workflow", async () => {
const first = await run(agent, "Tell me a joke");
const second = await run(agent, \`Rate this joke: \${first.finalOutput}\`);
console.log(first.finalOutput);
console.log(second.finalOutput);
});
```
```python
import asyncio
from agents import Agent, Runner, trace
agent = Agent(
name="Joke generator",
instructions="Tell funny jokes.",
)
async def main() -> None:
with trace("Joke workflow"):
first = await Runner.run(agent, "Tell me a joke")
second = await Runner.run(
agent,
f"Rate this joke: {first.final_output}",
)
print(first.final_output)
print(second.final_output)
if __name__ == "__main__":
asyncio.run(main())
```
Use traces for two jobs:
- Debug one workflow run and understand what happened.
- Feed higher-signal examples into [agent workflow evaluation](https://developers.openai.com/api/docs/guides/agent-evals) once you are ready to score behavior systematically.
## Next steps
Once the external surfaces are wired in, continue with the guide that covers capability design, review boundaries, or evaluation.
---
# Latency optimization
This guide covers the core set of principles you can apply to improve latency across a wide variety of LLM-related use cases. These techniques come from working with a wide range of customers and developers on production applications, so they should apply regardless of what you're building – from a granular workflow to an end-to-end chatbot.
While there's many individual techniques, we'll be grouping them into **seven principles** meant to represent a high-level taxonomy of approaches for improving latency.
At the end, we'll walk through an [example](#example) to see how they can be applied.
### Seven principles
1. [Process tokens faster.](#process-tokens-faster)
2. [Generate fewer tokens.](#generate-fewer-tokens)
3. [Use fewer input tokens.](#use-fewer-input-tokens)
4. [Make fewer requests.](#make-fewer-requests)
5. [Parallelize.](#parallelize)
6. [Make your users wait less.](#make-your-users-wait-less)
7. [Don't default to an LLM.](#don-t-default-to-an-llm)
## Process tokens faster
**Inference speed** is probably the first thing that comes to mind when addressing latency (but as you'll see soon, it's far from the only one). This refers to the actual **rate at which the LLM processes tokens**, and is often measured in TPM (tokens per minute) or TPS (tokens per second).
The main factor that influences inference speed is **model size** – smaller models usually run faster (and cheaper), and when used correctly can even outperform larger models. To maintain high quality performance with smaller models you can explore:
- using a longer, [more detailed prompt](https://developers.openai.com/api/docs/guides/prompt-engineering#tactic-specify-the-steps-required-to-complete-a-task),
- adding (more) [few-shot examples](https://developers.openai.com/api/docs/guides/prompt-engineering#tactic-provide-examples), or
- [fine-tuning](https://developers.openai.com/api/docs/guides/model-optimization) / distillation.
You can also employ inference optimizations like our [**Predicted outputs**](https://developers.openai.com/api/docs/guides/predicted-outputs) feature. Predicted outputs let you significantly reduce latency of a generation when you know most of the output ahead of time, such as code editing tasks. By giving the model a prediction, the LLM can focus more on the actual changes, and less on the content that will remain the same.
Other factors that affect inference speed are the amount of{" "}
compute you have available and any additional{" "}
inference optimizations you employ.
Most people can't influence these factors directly, but if you're curious, and
have some control over your infra, faster hardware or{" "}
running engines at a lower saturation may give you a modest
TPM boost. And if you're down in the trenches, there's a myriad of other{" "}
inference optimizations
{" "}
that are a bit beyond the scope of this guide.
## Generate fewer tokens
Generating tokens is almost always the highest latency step when using an LLM: as a general heuristic, **cutting 50% of your output tokens may cut ~50% your latency**. The way you reduce your output size will depend on output type:
If you're generating **natural language**, simply **asking the model to be more concise** ("under 20 words" or "be very brief") may help. You can also use few shot examples and/or fine-tuning to teach the model shorter responses.
If you're generating **structured output**, try to **minimize your output syntax** where possible: shorten function names, omit named arguments, coalesce parameters, etc.
Finally, while not common, you can also use `max_tokens` or `stop_tokens` to end your generation early.
Always remember: an output token cut is a (milli)second earned!
## Use fewer input tokens
While reducing the number of input tokens does result in lower latency, this is not usually a significant factor – **cutting 50% of your prompt may only result in a 1-5% latency improvement**. Unless you're working with truly massive context sizes (documents, images), you may want to spend your efforts elsewhere.
That being said, if you _are_ working with massive contexts (or you're set on squeezing every last bit of performance _and_ you've exhausted all other options) you can use the following techniques to reduce your input tokens:
- **Fine-tuning the model**, to replace the need for lengthy instructions / examples.
- **Filtering context input**, like pruning RAG results, cleaning HTML, etc.
- **Maximize shared prompt prefix**, by putting dynamic portions (e.g. RAG results, history, etc) later in the prompt. This makes your request more [KV cache](https://medium.com/@joaolages/kv-caching-explained-276520203249)-friendly (which most LLM providers use) and means fewer input tokens are processed on each request.
Check out our docs to learn more about how [prompt
caching](https://developers.openai.com/api/docs/guides/prompt-engineering#prompt-caching) works.
## Make fewer requests
Each time you make a request you incur some round-trip latency – this can start to add up.
If you have sequential steps for the LLM to perform, instead of firing off one request per step consider **putting them in a single prompt and getting them all in a single response**. You'll avoid the additional round-trip latency, and potentially also reduce complexity of processing multiple responses.
An approach to doing this is by collecting your steps in an enumerated list in the combined prompt, and then requesting the model to return the results in named fields in a JSON. This way you can easily parse out and reference each result!
## Parallelize
Parallelization can be very powerful when performing multiple steps with an LLM.
If the steps **are _not_ strictly sequential**, you can **split them out into parallel calls**. Two shirts take just as long to dry as one.
If the steps **_are_ strictly sequential**, however, you might still be able to **leverage speculative execution**. This is particularly effective for classification steps where one outcome is more likely than the others (e.g. moderation).
1. Start step 1 & step 2 simultaneously (e.g. input moderation & story generation)
2. Verify the result of step 1
3. If result was not the expected, cancel step 2 (and retry if necessary)
If your guess for step 1 is right, then you essentially got to run it with zero added latency!
## Make your users wait less
There's a huge difference between **waiting** and **watching progress happen** – make sure your users experience the latter. Here are a few techniques:
- **Streaming**: The single most effective approach, as it cuts the _waiting_ time to a second or less. (ChatGPT would feel pretty different if you saw nothing until each response was done.)
- **Chunking**: If your output needs further processing before being shown to the user (moderation, translation) consider **processing it in chunks** instead of all at once. Do this by streaming to your backend, then sending processed chunks to your frontend.
- **Show your steps**: If you're taking multiple steps or using tools, surface this to the user. The more real progress you can show, the better.
- **Loading states**: Spinners and progress bars go a long way.
Note that while **showing your steps & having loading states** have a mostly
psychological effect, **streaming & chunking** genuinely do reduce overall
latency once you consider the app + user system: the user will finish reading a response
sooner.
## Don't default to an LLM
LLMs are extremely powerful and versatile, and are therefore sometimes used in cases where a **faster classical method** would be more appropriate. Identifying such cases may allow you to cut your latency significantly. Consider the following examples:
- **Hard-coding:** If your **output** is highly constrained, you may not need an LLM to generate it. Action confirmations, refusal messages, and requests for standard input are all great candidates to be hard-coded. (You can even use the age-old method of coming up with a few variations for each.)
- **Pre-computing:** If your **input** is constrained (e.g. category selection) you can generate multiple responses in advance, and just make sure you never show the same one to a user twice.
- **Leveraging UI:** Summarized metrics, reports, or search results are sometimes better conveyed with classical, bespoke UI components rather than LLM-generated text.
- **Traditional optimization techniques:** An LLM application is still an application; binary search, caching, hash maps, and runtime complexity are all _still_ useful in a world of LLMs.
## Example
Let's now look at a sample application, identify potential latency optimizations, and propose some solutions!
We'll be analyzing the architecture and prompts of a hypothetical customer service bot inspired by real production applications. The [architecture and prompts](#architecture-and-prompts) section sets the stage, and the [analysis and optimizations](#analysis-and-optimizations) section will walk through the latency optimization process.
You'll notice this example doesn't cover every single principle, much like
real-world use cases don't require applying every technique.
### Architecture and prompts
The following is the **initial architecture** for a hypothetical **customer service bot**. This is what we'll be making changes to.
At a high level, the diagram flow describes the following process:
1. A user sends a message as part of an ongoing conversation.
2. The last message is turned into a **self-contained query** (see examples in prompt).
3. We determine whether or not **additional (retrieved) information is required** to respond to that query.
4. **Retrieval** is performed, producing search results.
5. The assistant **reasons** about the user's query and search results, and **produces a response**.
6. The response is sent back to the user.
Below are the prompts used in each part of the diagram. While they are still only hypothetical and simplified, they are written with the same structure and wording that you would find in a production application.
Places where you see placeholders like "**[user input here]**" represent
dynamic portions, that would be replaced by actual data at runtime.
Query contextualization prompt
Re-writes user query to be a self-contained search query.
```example-chat
SYSTEM: Given the previous conversation, re-write the last user query so it contains
all necessary context.
# Example
History: [{user: "What is your return policy?"},{assistant: "..."}]
User Query: "How long does it cover?"
Response: "How long does the return policy cover?"
# Conversation
[last 3 messages of conversation]
# User Query
[last user query]
USER: [JSON-formatted input conversation here]
```
Retrieval check prompt
Determines whether a query requires performing retrieval to respond.
```example-chat
SYSTEM: Given a user query, determine whether it requires doing a realtime lookup to
respond to.
# Examples
User Query: "How can I return this item after 30 days?"
Response: "true"
User Query: "Thank you!"
Response: "false"
USER: [input user query here]
```
Assistant prompt
Fills the fields of a JSON to reason through a pre-defined set of steps to produce a final response given a user conversation and relevant retrieved information.
```example-chat
SYSTEM: You are a helpful customer service bot.
Use the result JSON to reason about each user query - use the retrieved context.
# Example
User: "My computer screen is cracked! I want it fixed now!!!"
Assistant Response:
{
"message_is_conversation_continuation": "True",
"number_of_messages_in_conversation_so_far": "1",
"user_sentiment": "Aggravated",
"query_type": "Hardware Issue",
"response_tone": "Validating and solution-oriented",
"response_requirements": "Propose options for repair or replacement.",
"user_requesting_to_talk_to_human": "False",
"enough_information_in_context": "True",
"response": "..."
}
USER: # Relevant Information
` ` `
[retrieved context]
` ` `
USER: [input user query here]
```
### Analysis and optimizations
#### Part 1: Looking at retrieval prompts
Looking at the architecture, the first thing that stands out is the **consecutive GPT-4 calls** - these hint at a potential inefficiency, and can often be replaced by a single call or parallel calls.
In this case, since the check for retrieval requires the contextualized query, let's **combine them into a single prompt** to [make fewer requests](#make-fewer-requests).
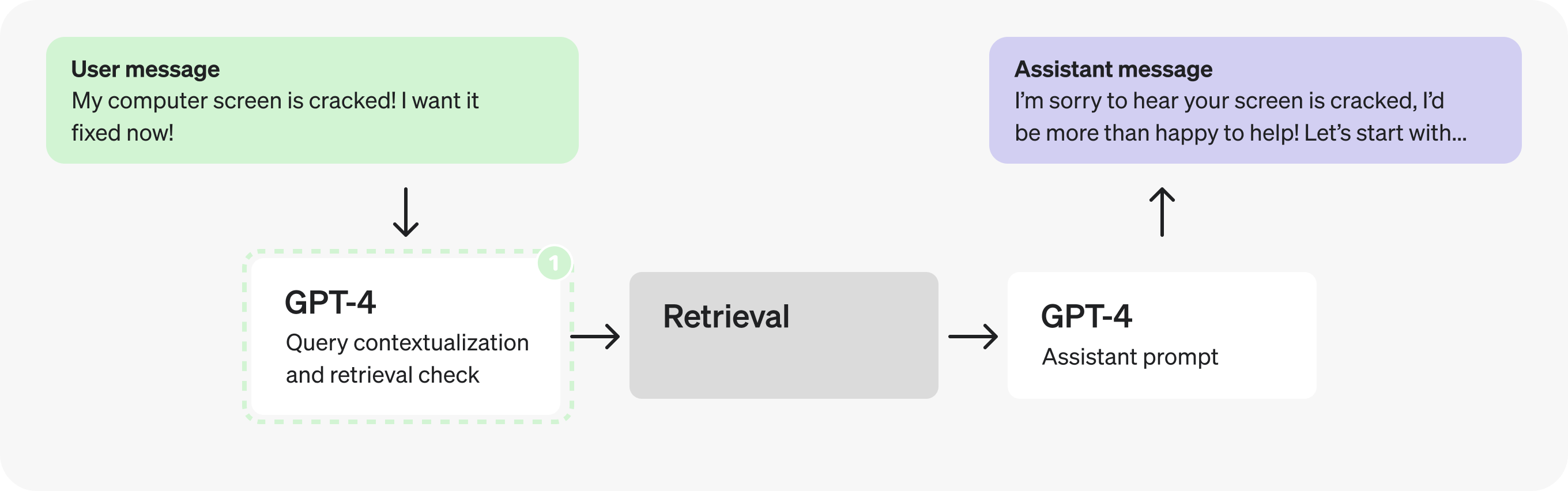
Combined query contextualization and retrieval check prompt
**What changed?** Before, we had one prompt to re-write the query and one to determine whether this requires doing a retrieval lookup. Now, this combined prompt does both. Specifically, notice the updated instruction in the first line of the prompt, and the updated output JSON:
```jsx
{
query:"[contextualized query]",
retrieval:"[true/false - whether retrieval is required]"
}
```
```example-chat
SYSTEM: Given the previous conversation, re-write the last user query so it contains
all necessary context. Then, determine whether the full request requires doing a
realtime lookup to respond to.
Respond in the following form:
{
query:"[contextualized query]",
retrieval:"[true/false - whether retrieval is required]"
}
# Examples
History: [{user: "What is your return policy?"},{assistant: "..."}]
User Query: "How long does it cover?"
Response: {query: "How long does the return policy cover?", retrieval: "true"}
History: [{user: "How can I return this item after 30 days?"},{assistant: "..."}]
User Query: "Thank you!"
Response: {query: "Thank you!", retrieval: "false"}
# Conversation
[last 3 messages of conversation]
# User Query
[last user query]
USER: [JSON-formatted input conversation here]
```
Actually, adding context and determining whether to retrieve are very straightforward and well defined tasks, so we can likely use a **smaller, fine-tuned model** instead. Switching to GPT-3.5 will let us [process tokens faster](#process-tokens-faster).
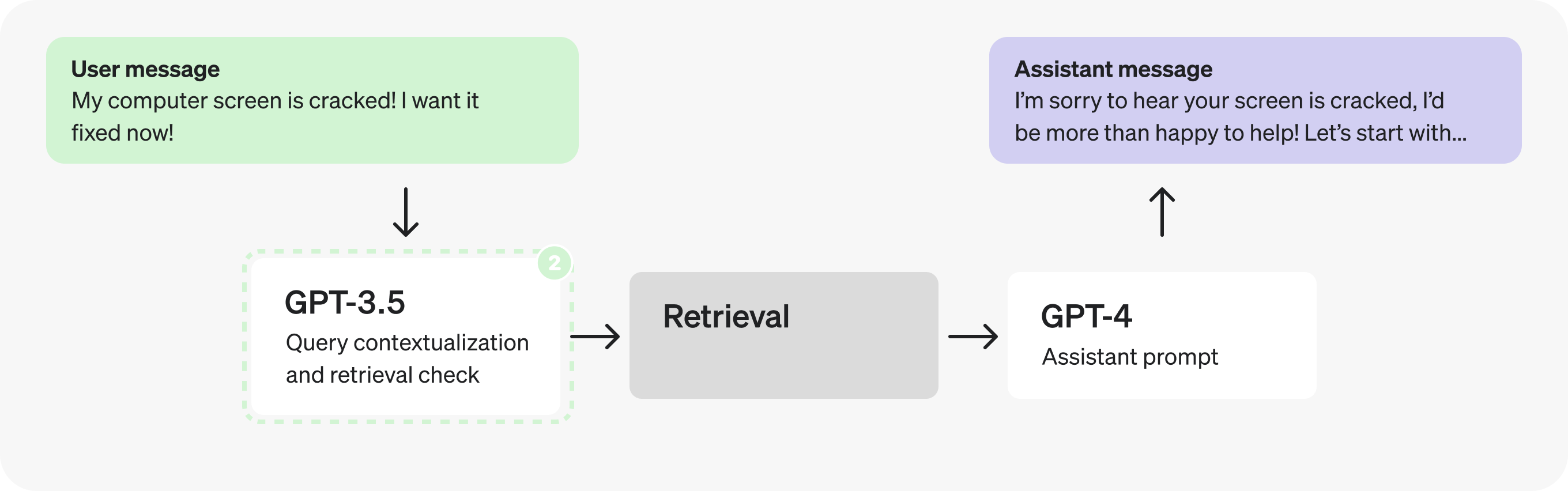
#### Part 2: Analyzing the assistant prompt
Let's now direct our attention to the Assistant prompt. There seem to be many distinct steps happening as it fills the JSON fields – this could indicate an opportunity to [parallelize](#parallelize).
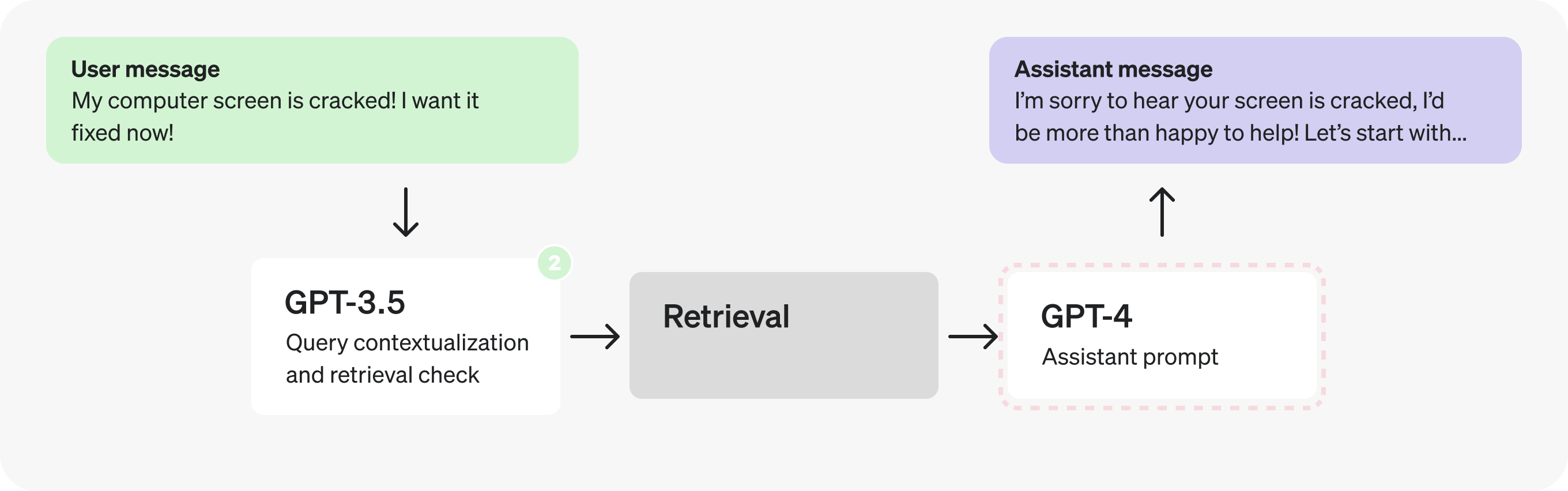
However, let's pretend we have run some tests and discovered that splitting the reasoning steps in the JSON produces worse responses, so we need to explore different solutions.
**Could we use a fine-tuned GPT-3.5 instead of GPT-4?** Maybe – but in general, open-ended responses from assistants are best left to GPT-4 so it can better handle a greater range of cases. That being said, looking at the reasoning steps themselves, they may not all require GPT-4 level reasoning to produce. The well defined, limited scope nature makes them and **good potential candidates for fine-tuning**.
```jsx
{
"message_is_conversation_continuation": "True", // <-
"number_of_messages_in_conversation_so_far": "1", // <-
"user_sentiment": "Aggravated", // <-
"query_type": "Hardware Issue", // <-
"response_tone": "Validating and solution-oriented", // <-
"response_requirements": "Propose options for repair or replacement.", // <-
"user_requesting_to_talk_to_human": "False", // <-
"enough_information_in_context": "True", // <-
"response": "..." // X -- benefits from GPT-4
}
```
This opens up the possibility of a trade-off. Do we keep this as a **single request entirely generated by GPT-4**, or **split it into two sequential requests** and use GPT-3.5 for all but the final response? We have a case of conflicting principles: the first option lets us [make fewer requests](#make-fewer-requests), but the second may let us [process tokens faster](#1-process-tokens-faster).
As with many optimization tradeoffs, the answer will depend on the details. For example:
- The proportion of tokens in the `response` vs the other fields.
- The average latency decrease from processing most fields faster.
- The average latency _increase_ from doing two requests instead of one.
The conclusion will vary by case, and the best way to make the determiation is by testing this with production examples. In this case let's pretend the tests indicated it's favorable to split the prompt in two to [process tokens faster](#process-tokens-faster).
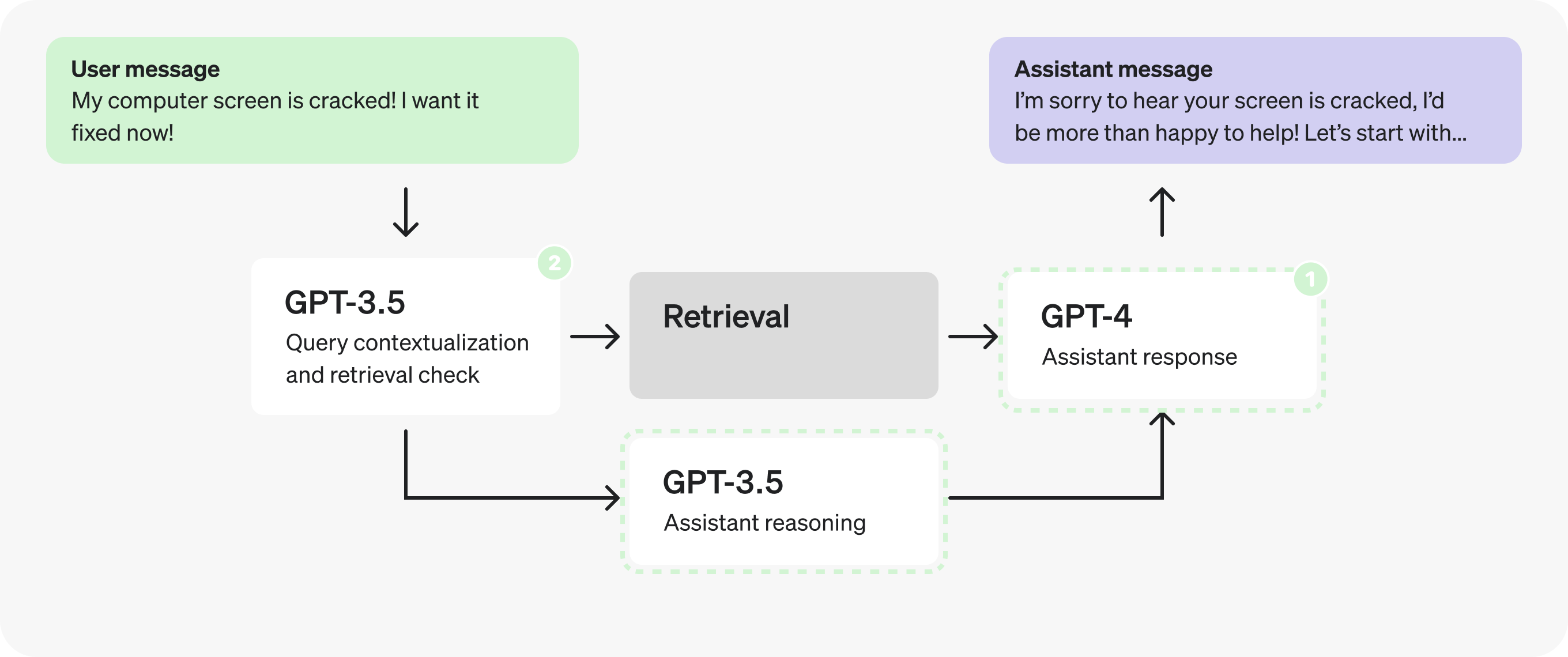
**Note:** We'll be grouping `response` and `enough_information_in_context` together in the second prompt to avoid passing the retrieved context to both new prompts.
Assistants prompt - reasoning
This prompt will be passed to GPT-3.5 and can be fine-tuned on curated examples.
**What changed?** The "enough_information_in_context" and "response" fields were removed, and the retrieval results are no longer loaded into this prompt.
```example-chat
SYSTEM: You are a helpful customer service bot.
Based on the previous conversation, respond in a JSON to determine the required
fields.
# Example
User: "My freaking computer screen is cracked!"
Assistant Response:
{
"message_is_conversation_continuation": "True",
"number_of_messages_in_conversation_so_far": "1",
"user_sentiment": "Aggravated",
"query_type": "Hardware Issue",
"response_tone": "Validating and solution-oriented",
"response_requirements": "Propose options for repair or replacement.",
"user_requesting_to_talk_to_human": "False",
}
```
Assistants prompt - response
This prompt will be processed by GPT-4 and will receive the reasoning steps determined in the prior prompt, as well as the results from retrieval.
**What changed?** All steps were removed except for "enough_information_in_context" and "response". Additionally, the JSON we were previously filling in as output will be passed in to this prompt.
```example-chat
SYSTEM: You are a helpful customer service bot.
Use the retrieved context, as well as these pre-classified fields, to respond to
the user's query.
# Reasoning Fields
` ` `
[reasoning json determined in previous GPT-3.5 call]
` ` `
# Example
User: "My freaking computer screen is cracked!"
Assistant Response:
{
"enough_information_in_context": "True",
"response": "..."
}
USER: # Relevant Information
` ` `
[retrieved context]
` ` `
```
In fact, now that the reasoning prompt does not depend on the retrieved context we can [parallelize](#parallelize) and fire it off at the same time as the retrieval prompts.
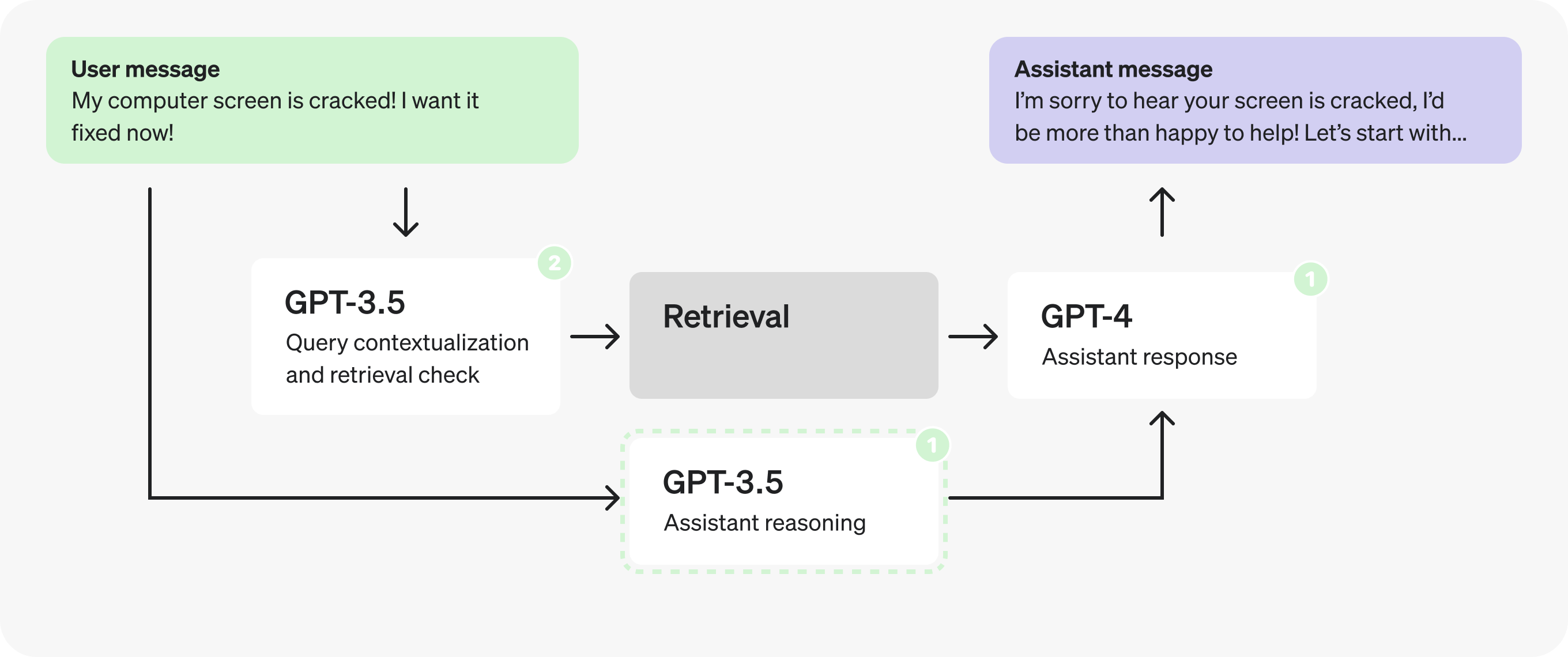
#### Part 3: Optimizing the structured output
Let's take another look at the reasoning prompt.
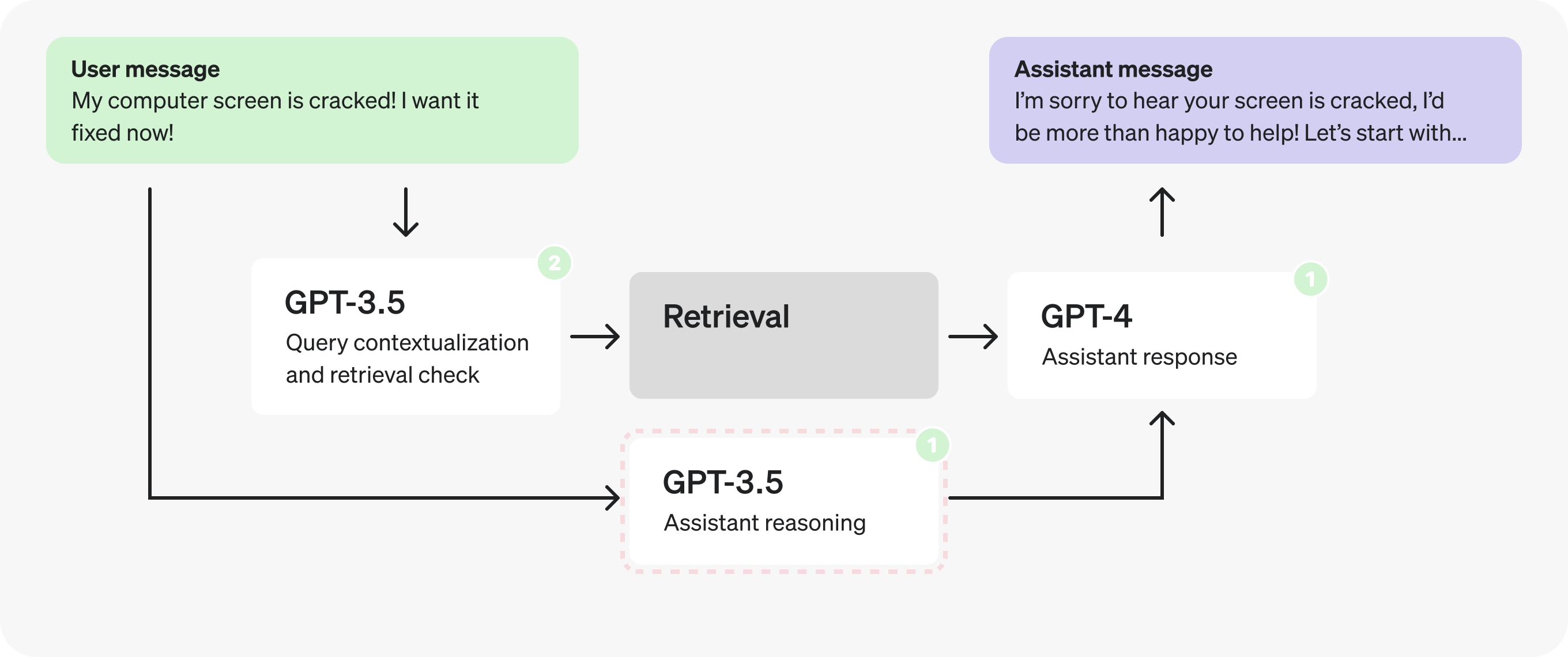
Taking a closer look at the reasoning JSON you may notice the field names themselves are quite long.
```jsx
{
"message_is_conversation_continuation": "True", // <-
"number_of_messages_in_conversation_so_far": "1", // <-
"user_sentiment": "Aggravated", // <-
"query_type": "Hardware Issue", // <-
"response_tone": "Validating and solution-oriented", // <-
"response_requirements": "Propose options for repair or replacement.", // <-
"user_requesting_to_talk_to_human": "False", // <-
}
```
By making them shorter and moving explanations to the comments we can [generate fewer tokens](#generate-fewer-tokens).
```jsx
{
"cont": "True", // whether last message is a continuation
"n_msg": "1", // number of messages in the continued conversation
"tone_in": "Aggravated", // sentiment of user query
"type": "Hardware Issue", // type of the user query
"tone_out": "Validating and solution-oriented", // desired tone for response
"reqs": "Propose options for repair or replacement.", // response requirements
"human": "False", // whether user is expressing want to talk to human
}
```

This small change removed 19 output tokens. While with GPT-3.5 this may only result in a few millisecond improvement, with GPT-4 this could shave off up to a second.

You might imagine, however, how this can have quite a significant impact for larger model outputs.
We could go further and use single characters for the JSON fields, or put everything in an array, but this may start to hurt our response quality. The best way to know, once again, is through testing.
#### Example wrap-up
Let's review the optimizations we implemented for the customer service bot example:
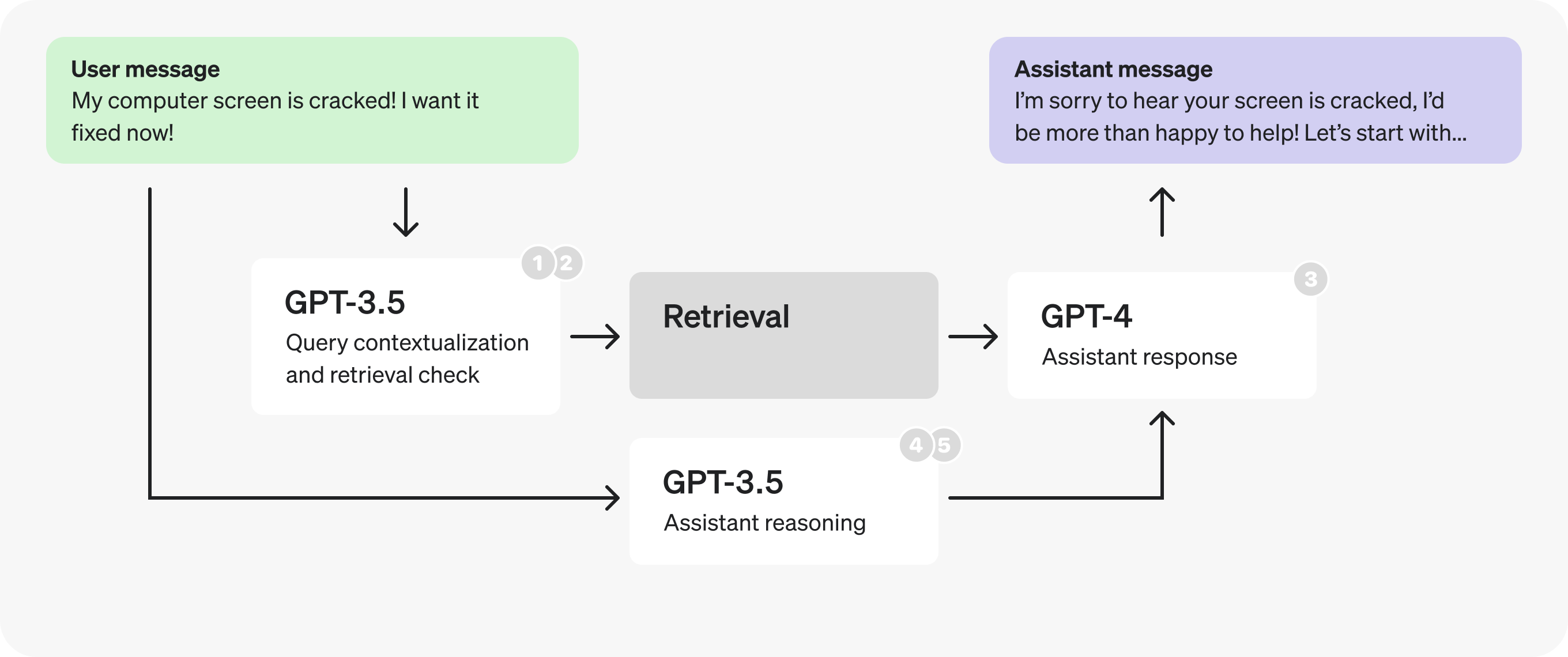
1. **Combined** query contextualization and retrieval check steps to [make fewer requests](#make-fewer-requests).
2. For the new prompt, **switched to a smaller, fine-tuned GPT-3.5** to [process tokens faster](https://developers.openai.com/api/docs/guides/process-tokens-faster).
3. Split the assistant prompt in two, **switching to a smaller, fine-tuned GPT-3.5** for the reasoning, again to [process tokens faster](#process-tokens-faster).
4. [Parallelized](#parallelize) the retrieval checks and the reasoning steps.
5. **Shortened reasoning field names** and moved comments into the prompt, to [generate fewer tokens](#generate-fewer-tokens).
---
# Local shell
The local shell tool is outdated. For new use cases, use the
[`shell`](https://developers.openai.com/api/docs/guides/tools-shell) tool with GPT-5.1 instead. [Learn
more](https://developers.openai.com/api/docs/guides/tools-shell).
Local shell is a tool that allows agents to run shell commands locally on a machine you or the user provides. It's designed to work with [Codex CLI](https://github.com/openai/codex) and [`codex-mini-latest`](https://developers.openai.com/api/docs/models/codex-mini-latest). Commands are executed inside your own runtime, **you are fully in control of which commands actually run** —the API only returns the instructions, but does not execute them on OpenAI infrastructure.
Local shell is available through the [Responses API](https://developers.openai.com/api/docs/guides/responses-vs-chat-completions) for use with [`codex-mini-latest`](https://developers.openai.com/api/docs/models/codex-mini-latest). It is not available on other models, or via the Chat Completions API.
Running arbitrary shell commands can be dangerous. Always sandbox execution
or add strict allow- / deny-lists before forwarding a command to the system
shell.
See [Codex CLI](https://github.com/openai/codex) for reference implementation.
## How it works
The local shell tool enables agents to run in a continuous loop with access to a terminal.
It sends shell commands, which your code executes on a local machine and then returns the output back to the model. This loop allows the model to complete the build-test-run loop without additional intervention by a user.
As part of your code, you'll need to implement a loop that listens for `local_shell_call` output items and executes the commands they contain. We strongly recommend sandboxing the execution of these commands to prevent any unexpected commands from being executed.
Integrating the local shell tool
These are the high-level steps you need to follow to integrate the computer use tool in your application:
1. **Send a request to the model**:
Include the `local_shell` tool as part of the available tools.
2. **Receive a response from the model**:
Check if the response has any `local_shell_call` items.
This tool call contains an action like `exec` with a command to execute.
3. **Execute the requested action**:
Execute through code the corresponding action in the computer or container environment.
4. **Return the action output**:
After executing the action, return the command output and metadata like status code to the model.
5. **Repeat**:
Send a new request with the updated state as a `local_shell_call_output`, and repeat this loop until the model stops requesting actions or you decide to stop.
## Example workflow
Below is a minimal (Python) example showing the request/response loop. For
brevity, error handling and security checks are omitted—**do not execute
untrusted commands in production without additional safeguards**.
```python
import os
import shlex
import subprocess
from openai import OpenAI
client = OpenAI()
# 1) Create the initial response request with the tool enabled
response = client.responses.create(
model="codex-mini-latest",
tools=[{"type": "local_shell"}],
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text": "List files in the current directory"},
],
}
],
)
while True:
# 2) Look for a local_shell_call in the model's output items
shell_calls = []
for item in response.output:
item_type = getattr(item, "type", None)
if item_type == "local_shell_call":
shell_calls.append(item)
elif item_type == "tool_call" and getattr(item, "tool_name", None) == "local_shell":
shell_calls.append(item)
if not shell_calls:
# No more commands — the assistant is done.
break
call = shell_calls[0]
args = getattr(call, "action", None) or getattr(call, "arguments", None)
# 3) Execute the command locally (here we just trust the command!)
# The command is already split into argv tokens.
def _get(obj, key, default=None):
if isinstance(obj, dict):
return obj.get(key, default)
return getattr(obj, key, default)
timeout_ms = _get(args, "timeout_ms")
command = _get(args, "command")
if not command:
break
if isinstance(command, str):
command = shlex.split(command)
completed = subprocess.run(
command,
cwd=_get(args, "working_directory") or os.getcwd(),
env={**os.environ, **(_get(args, "env") or {})},
capture_output=True,
text=True,
timeout=(timeout_ms / 1000) if timeout_ms else None,
)
output_item = {
"type": "local_shell_call_output",
"call_id": getattr(call, "call_id", None),
"output": completed.stdout + completed.stderr,
}
# 4) Send the output back to the model to continue the conversation
response = client.responses.create(
model="codex-mini-latest",
tools=[{"type": "local_shell"}],
previous_response_id=response.id,
input=[output_item],
)
# Print the assistant's final answer
print(response.output_text)
```
## Best practices
- **Sandbox or containerize** execution. Consider using Docker, firejail, or a
jailed user account.
- **Impose resource limits** (time, memory, network). The `timeout_ms`
provided by the model is only a hint—you should enforce your own limits.
- **Filter or scrutinize** high-risk commands (e.g. `rm`, `curl`, network
utilities).
- **Log every command and its output** for auditability and debugging.
### Error handling
If the command fails on your side (non-zero exit code, timeout, etc.) you can still send a `local_shell_call_output`; include the error message in the `output` field.
The model can choose to recover or try executing a different command. If you send malformed data (e.g. missing `call_id`) the API returns a standard `400` validation error.
---
# Manage permissions in the OpenAI platform
Role-based access control (RBAC) lets you decide who can do what across your organization and projects—both through the API and in the Dashboard. The same permissions govern both surfaces: if someone can call an endpoint (for example, `/v1/chat/completions`), they can use the equivalent Dashboard page, and missing permissions disable related UI (such as the **Upload** button in Playground). With RBAC you can:
- Group users and assign permissions at scale
- Create custom roles with the exact permissions you need
- Scope access at the organization or project level
- Enforce consistent permissions in both the Dashboard and API
## Key concepts
- **Organization**: Your top-level account. Organization roles can grant access across all projects.
- **Project**: A workspace for keys, files, and resources. Project roles grant access within only that project.
- **Groups**: Collections of users you can assign roles to. Groups can be synced from your identity provider (via SCIM) to keep membership up to date automatically.
- **Roles**: Bundles of permissions (like Models Request or Files Write). Roles can be created for the organization under **Organization settings**, or created for a specific project under that project's settings. Once created, organization or project roles can be assigned to users or groups. Users can have multiple roles, and their access is the union of those roles.
- **Permissions**: The specific actions a role allows (e.g., make request to models, read files, write files, manage keys).
### Permissions
The table below shows the available permissions, which preset roles include them, and whether they can be configured for custom roles.
| Area | What it allows | Org owner permissions | Org reader permissions | Project owner permissions | Project member permissions | Project viewer permissions | Custom role eligible |
| ---------------------- | ------------------------------------------------------------------------------------ | --------------------- | ---------------------- | ------------------------- | -------------------------- | -------------------------- | -------------------- |
| List models | List models this organization has access to | `Read` | `Read` | `Read` | `Read` | `Read` | ✓ |
| Groups | View and manage groups | `Read`, `Write` | `Read` | `Read`, `Write` | `Read`, `Write` | `Read` | |
| Roles | View and manage roles | `Read`, `Write` | `Read` | `Read`, `Write` | `Read`, `Write` | `Read` | |
| Organization Admin | Manage organization users, projects, invites, admin API keys, and rate limits | `Read`, `Write` | | | | | |
| Usage | View usage dashboard and export | `Read` | | | | | ✓ |
| External Keys | View and manage keys for Enterprise Key Management | `Read`, `Write` | | | | | |
| IP allowlist | View and manage IP allowlist | `Read`, `Write` | | | | | |
| mTLS | View and manage mutual TLS settings | `Read`, `Write` | | | | | |
| OIDC | View and manage OIDC configuration | `Read`, `Write` | | | | | |
| Model capabilities | Make requests to chat completions, audio, embeddings, and images | `Request` | `Request` | `Request` | `Request` | | ✓ |
| Assistants | Create and retrieve Assistants | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read` | ✓ |
| Threads | Create and retrieve Threads/Messages/Runs | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read` | ✓ |
| Evals | Create, retrieve, and delete Evals | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read` | ✓ |
| Fine-tuning | Create and retrieve fine tuning jobs | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read` | ✓ |
| Files | Create and retrieve files | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read` | ✓ |
| Vector Stores | Create and retrieve vector stores | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | | ✓ |
| Responses API | Create responses | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | | ✓ |
| Prompts | Create and retrieve prompts to use as context for Responses API and Realtime API | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read` | ✓ |
| Webhooks | Create and view webhooks in your project | `Read`, `Write` | `Read` | `Read`, `Write` | `Read`, `Write` | `Read` | ✓ |
| Datasets | Create and retrieve Datasets | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read` | ✓ |
| Apps | Create, manage, and submit apps for review in the Dashboard | `Read`, `Write` | | | | | ✓ |
| Project API Keys | Permission for a user to manage their own API keys | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read` | ✓ |
| Project Administration | Manage project users, service accounts, API keys, and rate limits via management API | `Read`, `Write` | | `Read`, `Write` | | | |
| Batch | Create and manage batch jobs | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read` | |
| Service Accounts | View and manage project service accounts | `Read`, `Write` | | `Read`, `Write` | | | |
| Videos | Create and retrieve videos | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | | |
| Voices | Create and retrieve voices | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read`, `Write` | `Read` | |
| Agent Builder | Create and manage agents and workflows in Agent Builder | `Read`, `Write` | `Read` | `Read`, `Write` | `Read`, `Write` | `Read` | ✓ |
## Setting up RBAC
Allow up to **30 minutes** for role changes and group sync to propagate.
1. **Create groups**
Add groups for teams (e.g., “Data Science”, “Support”). If you use an IdP, enable SCIM sync so group membership stays current.
2. **Create custom roles**
Start from least privilege. For example:
- _Model Tester_: Models Read, Model Capabilities Request, Evals
- _Model Engineer_: Model Capabilities Request, Files Read/Write, Fine-tuning
- _App Publisher_: Apps Read, Apps Write
3. **Assign roles**
- **Organization level** roles apply everywhere (all projects within the organization).
- **Project level** roles apply only in that project.
You can assign roles to **users** and **groups**. Users can hold multiple roles; access is the **union**.
4. **Verify**
Use a non-owner account to confirm expected access (API and Dashboard). Adjust roles if users can see more than they need.
Use the principle of least privilege. Start with the minimum permissions
required for a task, then add more only as needed.
## Access configuration examples
### Small team
- Give the core team an org-level role with Model Capabilities Request and Files Read/Write.
- Create a project for each app; add contractors to those projects only, with project-level roles.
### Larger org
- Sync groups from your IdP (e.g., “Research”, “Support”, “Finance”).
- Create custom roles per function and assign at the org level; or only grant project-specific roles when a project needs tighter controls.
### Contractors & vendors
- Create a “Contractors” group without org-level roles.
- Add them to specific projects with narrowly scoped project roles (for example, read-only access).
## How user access is evaluated
In the dashboard, we combine:
- roles from the **organization** (direct + via groups)
- roles from the **project** (direct + via groups)
The effective permissions are the **union** of all assigned roles.
If requesting with an API key within a project, we take the permissions assigned to the API key, and ensure that the user has some project role that grants them those permissions. For example, if requesting /v1/models, the API key must have api.model.read assigned to it and the user must have a project role with api.model.read.
## Best practices
- **Model your org in groups**: Mirror teams in your IdP and assign roles to groups, not individuals.
- **Separate duties**: reading models vs. uploading files vs. managing keys.
- **Project boundaries**: put experiments, staging, and production in separate projects.
- **Review regularly**: remove unused roles and keys; rotate sensitive keys.
- **Test as a non-owner**: validate access matches expectations before broad rollout.
---
# Managing costs
This document describes how Realtime API billing works and offers strategies for optimizing costs. Voice-agent sessions accrue input and output tokens across text, audio, and image modalities. Streaming translation and streaming transcription sessions are billed by audio duration. Prices vary per model, with prices listed on the model pages (for example, [`gpt-realtime-2`](https://developers.openai.com/api/docs/models/gpt-realtime-2), [`gpt-realtime-translate`](https://developers.openai.com/api/docs/models/gpt-realtime-translate), [`gpt-realtime-whisper`](https://developers.openai.com/api/docs/models/gpt-realtime-whisper), and [`gpt-realtime`](https://developers.openai.com/api/docs/models/gpt-realtime)).
Conversational Realtime API sessions are a series of _turns_, where the user adds input that triggers a _Response_ to produce the model output. The server maintains a _Conversation_, which is a list of _Items_ that form the input for the next turn. When a Response is returned, the output is automatically added to the Conversation.
Translation and transcription sessions use a different streaming architecture. The client streams audio continuously and receives translated audio, transcript deltas, or transcript events as the source audio arrives. These sessions don't use the normal Response lifecycle, so estimate and monitor them with their duration-based rates instead of per-Response token usage.
## Per-Response costs
Realtime API costs are accrued when a Response is created, and is charged based on the numbers of input and output tokens (except for input transcription costs, see below). There is no cost currently for network bandwidth or connections. A Response can be created manually or automatically if voice activity detection (VAD) is turned on. VAD will effectively filter out empty input audio, so empty audio doesn't count as input tokens unless the client manually adds it as conversation input.
The entire conversation is sent to the model for each Response. The output from a turn will be added as Items to the server Conversation and become the input to subsequent turns, thus turns later in the session will be more expensive.
Text token costs can be estimated using our [tokenization tools](https://platform.openai.com/tokenizer). Audio tokens in user messages are 1 token per 100 ms of audio, while audio tokens in assistant messages are 1 token per 50ms of audio. Note that token counts include special tokens aside from the content of a message which will surface as small variations in these counts, for example a user message with 10 text tokens of content may count as 12 tokens.
### Example
Here’s a simple example to illustrate token costs over a multi-turn Realtime API session.
For the first turn in the conversation we’ve added 100 tokens of instructions, a user message of 20 audio tokens (for example added by VAD based on the user speaking), for a total of 120 input tokens. Creating a Response generates an assistant output message (20 audio, 10 text tokens).
Then we create a second turn with another user audio message. What will the tokens for turn 2 look like? The Conversation at this point includes the initial instructions, first user message, the output assistant message from the first turn, plus the second user message (25 audio tokens). This turn will have 110 text and 64 audio tokens for input, plus the output tokens of another assistant output message.
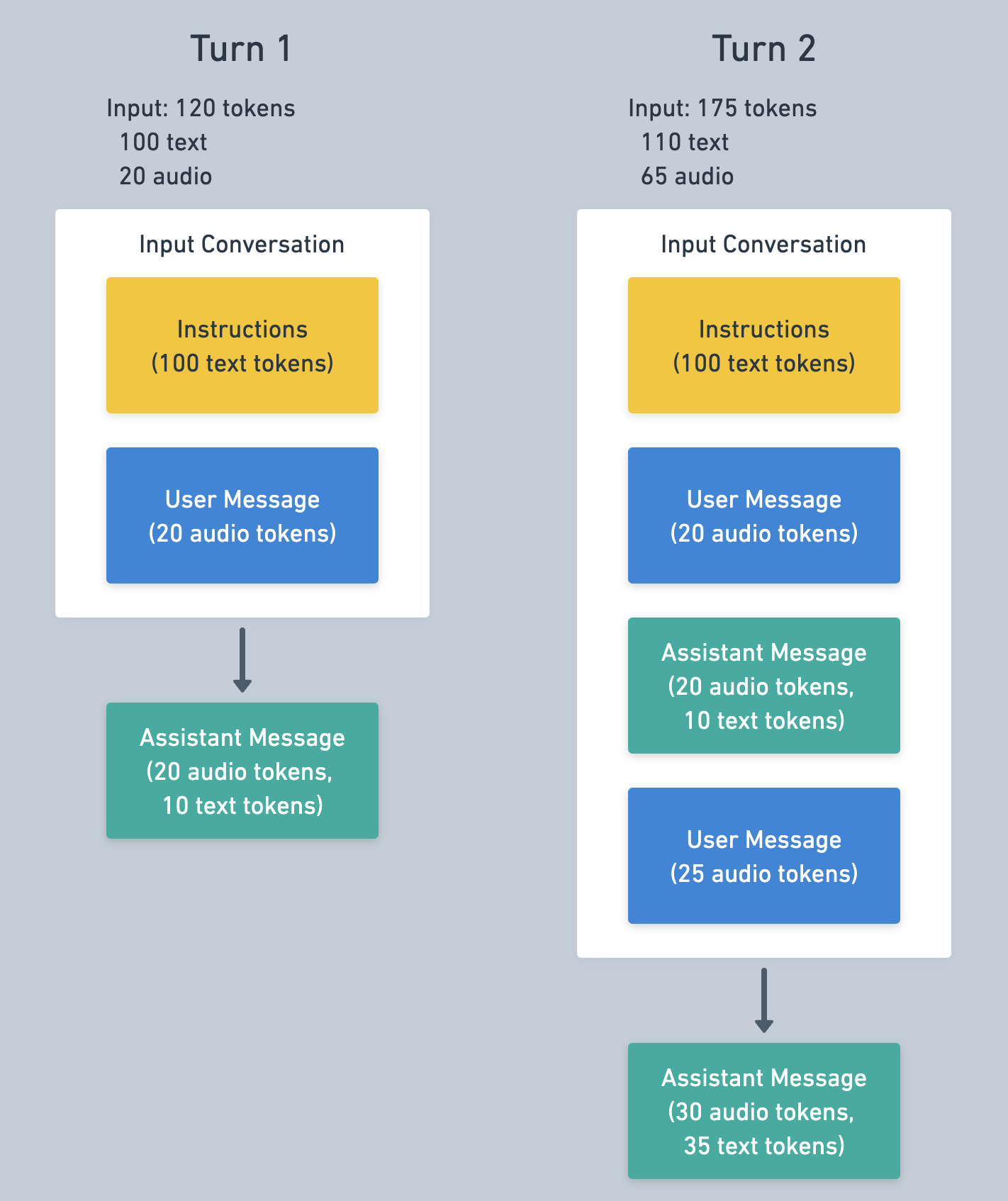
The messages from the first turn are likely to be cached for turn 2, which reduces the input cost. See below for more information on caching.
The tokens used for a Response can be read from the `response.done` event, which looks like the following.
```json
{
"type": "response.done",
"response": {
...
"usage": {
"total_tokens": 253,
"input_tokens": 132,
"output_tokens": 121,
"input_token_details": {
"text_tokens": 119,
"audio_tokens": 13,
"image_tokens": 0,
"cached_tokens": 64,
"cached_tokens_details": {
"text_tokens": 64,
"audio_tokens": 0,
"image_tokens": 0
}
},
"output_token_details": {
"text_tokens": 30,
"audio_tokens": 91
}
}
}
}
```
## Input transcription costs
Aside from conversational Responses, the Realtime API bills for input transcriptions, if enabled. Input transcription uses a different model than the speech2speech model, such as [`whisper-1`](https://developers.openai.com/api/docs/models/whisper-1) or [`gpt-4o-transcribe`](https://developers.openai.com/api/docs/models/gpt-4o-transcribe), and thus are billed from a different rate card. Transcription is performed when audio is written to the input audio buffer and then committed, either manually or by VAD.
Input transcription token counts can be read from the `conversation.item.input_audio_transcription.completed` event, as in the following example.
```json
{
"type": "conversation.item.input_audio_transcription.completed",
...
"transcript": "Hi, can you hear me?",
"usage": {
"type": "tokens",
"total_tokens": 26,
"input_tokens": 17,
"input_token_details": {
"text_tokens": 0,
"audio_tokens": 17
},
"output_tokens": 9
}
}
```
## Caching
Realtime API supports [prompt caching](https://developers.openai.com/api/docs/guides/prompt-caching), which is applied automatically and can dramatically reduce the costs of input tokens during multi-turn sessions. Caching applies when the input tokens of a Response match tokens from a previous Response, though this is best-effort and not guaranteed.
The best strategy for maximizing cache rate is keep a session’s history static. Removing or changing content in the conversation will “bust” the cache up to the point of the change — the input no longer matches as much as before. Note that instructions and tool definitions are at the beginning of a conversation, thus changing these mid-session will reduce the cache rate for subsequent turns.
## Truncation
When the number of tokens in a conversation exceeds the model's input token limit the conversation be truncated, meaning messages (starting from the oldest) will be dropped from the Response input. A 32k context model with 4,096 max output tokens can only include 28,224 tokens in the context before truncation occurs.
Clients can set a smaller token window than the model’s maximum, which is a good way to control token usage and cost. This is controlled with the `token_limits.post_instructions` configuration (if you configure truncation with a `retention_ratio` type as shown below). As the name indicates, this controls the maximum number of input tokens for a Response, except for the instruction tokens. Setting `post_instructions` to 1,000 means that items over the 1,000 input token limit won't be sent to the model for a Response.
Truncation busts the cache near the beginning of the conversation, and if truncation occurs on every turn then cache rate will be very low. To mitigate this issue clients can configure truncation to drop more messages than necessary, which will extend the headroom before another truncation is needed. This can be controlled with the `session.truncation.retention_ratio` setting. The server defaults to a value of `1.0` , meaning truncation will remove only the items necessary. A value of `0.8` means a truncation would retain 80% of the maximum, dropping an additional 20%.
If you’re attempting to reduce Realtime API cost per session (for a given model), we recommend reducing limiting the number of tokens and setting a `retention_ratio` less than 1, as in the following example. Remember that there may be a tradeoff here in terms of lower cost but lower model memory for a given turn.
```json
{
"event": "session.update",
"session": {
"truncation": {
"type": "retention_ratio",
"retention_ratio": 0.8,
"token_limits": {
"post_instructions": 8000
}
}
}
}
```
Truncation can also be completely disabled, as shown below. When disabled an error will be returned if the Conversation is too long to create a Response. This may be useful if you intend to manage the Conversation size manually.
```json
{
"event": "session.update",
"session": {
"truncation": "disabled"
}
}
```
## Other optimization strategies
### Using a mini model
The Realtime speech2speech models come in a “normal” size and a mini size, which is significantly cheaper. The tradeoff here tends to be intelligence related to instruction following and function calling, which won't be as effective in the mini model. We recommend first testing applications with the larger model, refining your application and prompt, then attempting to optimize using the mini model.
### Editing the Conversation
While truncation will occur automatically on the server, another cost management strategy is to manually edit the Conversation. A principle of the API is to allow full client control of the server-side Conversation, allowing the client to add and remove items at will.
```json
{
"type": "conversation.item.delete",
"item_id": "item_CCXLecNJVIVR2HUy3ABLj"
}
```
Clearing out old messages is a good way to reduce input token sizes and cost. This might remove important content, but a common strategy is to replace these old messages with a summary. Items can be deleted from the Conversation with a `conversation.item.delete` message as above, and can be added with a `conversation.item.create` message.
## Estimating costs
Given the complexity in Realtime API token usage it can be difficult to estimate your costs ahead of time. A good approach is to use the Realtime Playground with your intended prompts and functions, and measure the token usage over a sample session. The token usage for a session can be found under the Logs tab in the Realtime Playground next to the session id.
---
# MCP and Connectors
import {
CheckCircleFilled,
XCircle,
} from "@components/react/oai/platform/ui/Icon.react";
In addition to tools you make available to the model with [function calling](https://developers.openai.com/api/docs/guides/function-calling), you can give models new capabilities using **connectors** and **remote MCP servers**. These tools give the model the ability to connect to and control external services when needed to respond to a user's prompt. These tool calls can either be allowed automatically, or restricted with explicit approval required by you as the developer.
- **Connectors** are OpenAI-maintained MCP wrappers for popular services like Google Workspace or Dropbox, like the connectors available in [ChatGPT](https://chatgpt.com).
- **Remote MCP servers** can be any server on the public Internet that implements a remote [Model Context Protocol](https://modelcontextprotocol.io/introduction) (MCP) server.
This guide will show how to use both remote MCP servers and connectors to give the model access to new capabilities.
## Quickstart
Check out the examples below to see how remote MCP servers and connectors work through the [Responses API](https://developers.openai.com/api/docs/api-reference/responses/create). Both connectors and remote MCP servers can be used with the `mcp` built-in tool type.
Using remote MCP servers
Remote MCP servers require a server_url. Depending on the server,
you may also need an OAuth authorization parameter containing an
access token.
Using a remote MCP server in the Responses API
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5.5",
"tools": [
{
"type": "mcp",
"server_label": "dmcp",
"server_description": "A Dungeons and Dragons MCP server to assist with dice rolling.",
"server_url": "https://dmcp-server.deno.dev/sse",
"require_approval": "never"
}
],
"input": "Roll 2d4+1"
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const resp = await client.responses.create({
model: "gpt-5.5",
tools: [
{
type: "mcp",
server_label: "dmcp",
server_description: "A Dungeons and Dragons MCP server to assist with dice rolling.",
server_url: "https://dmcp-server.deno.dev/sse",
require_approval: "never",
},
],
input: "Roll 2d4+1",
});
console.log(resp.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-5.5",
tools=[
{
"type": "mcp",
"server_label": "dmcp",
"server_description": "A Dungeons and Dragons MCP server to assist with dice rolling.",
"server_url": "https://dmcp-server.deno.dev/sse",
"require_approval": "never",
},
],
input="Roll 2d4+1",
)
print(resp.output_text)
```
```csharp
using OpenAI.Responses;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5.5", apiKey: key);
ResponseCreationOptions options = new();
options.Tools.Add(ResponseTool.CreateMcpTool(
serverLabel: "dmcp",
serverUri: new Uri("https://dmcp-server.deno.dev/sse"),
toolCallApprovalPolicy: new McpToolCallApprovalPolicy(GlobalMcpToolCallApprovalPolicy.NeverRequireApproval)
));
OpenAIResponse response = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("Roll 2d4+1")
])
], options);
Console.WriteLine(response.GetOutputText());
```
It is very important that developers trust any remote MCP server they use with
the Responses API. A malicious server can exfiltrate sensitive data from
anything that enters the model's context. Carefully review the{" "}
Risks and Safety section below before using this tool.
Using connectors
Connectors require a connector_id parameter, and an OAuth access
token provided by your application in the authorization parameter.
Using connectors in the Responses API
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"tools": [
{
"type": "mcp",
"server_label": "Dropbox",
"connector_id": "connector_dropbox",
"authorization": "
",
"require_approval": "never"
}
],
"input": "Summarize the Q2 earnings report."
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const resp = await client.responses.create({
model: "gpt-5",
tools: [
{
type: "mcp",
server_label: "Dropbox",
connector_id: "connector_dropbox",
authorization: "",
require_approval: "never",
},
],
input: "Summarize the Q2 earnings report.",
});
console.log(resp.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-5",
tools=[
{
"type": "mcp",
"server_label": "Dropbox",
"connector_id": "connector_dropbox",
"authorization": "",
"require_approval": "never",
},
],
input="Summarize the Q2 earnings report.",
)
print(resp.output_text)
```
```csharp
using OpenAI.Responses;
string dropboxToken = Environment.GetEnvironmentVariable("DROPBOX_OAUTH_ACCESS_TOKEN")!;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5", apiKey: key);
ResponseCreationOptions options = new();
options.Tools.Add(ResponseTool.CreateMcpTool(
serverLabel: "Dropbox",
connectorId: McpToolConnectorId.Dropbox,
authorizationToken: dropboxToken,
toolCallApprovalPolicy: new McpToolCallApprovalPolicy(GlobalMcpToolCallApprovalPolicy.NeverRequireApproval)
));
OpenAIResponse response = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("Summarize the Q2 earnings report.")
])
], options);
Console.WriteLine(response.GetOutputText());
```
The API will return new items in the `output` array of the model response. If the model decides to use a Connector or MCP server, it will first make a request to list available tools from the server, which will create a `mcp_list_tools` output item. From the simple remote MCP server example above, it contains only one tool definition:
```json
{
"id": "mcpl_68a6102a4968819c8177b05584dd627b0679e572a900e618",
"type": "mcp_list_tools",
"server_label": "dmcp",
"tools": [
{
"annotations": null,
"description": "Given a string of text describing a dice roll...",
"input_schema": {
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"diceRollExpression": {
"type": "string"
}
},
"required": ["diceRollExpression"],
"additionalProperties": false
},
"name": "roll"
}
]
}
```
If the model decides to call one of the available tools from the MCP server, you will also find a `mcp_call` output which will show what the model sent to the MCP tool, and what the MCP tool sent back as output.
```json
{
"id": "mcp_68a6102d8948819c9b1490d36d5ffa4a0679e572a900e618",
"type": "mcp_call",
"approval_request_id": null,
"arguments": "{\"diceRollExpression\":\"2d4 + 1\"}",
"error": null,
"name": "roll",
"output": "4",
"server_label": "dmcp"
}
```
Read on in the guide below to learn more about how the MCP tool works, how to filter available tools, and how to handle tool call approval requests.
## How it works
The MCP tool (for both remote MCP servers and connectors) is available in the [Responses API](https://developers.openai.com/api/docs/api-reference/responses/create) in most recent models. Check MCP tool compatibility for your model [here](https://developers.openai.com/api/docs/models). When you're using the MCP tool, you only pay for [tokens](https://developers.openai.com/api/docs/pricing) used when importing tool definitions or making tool calls. There are no additional fees involved per tool call.
Below, we'll step through the process the API takes when calling an MCP tool.
### Step 1: Listing available tools
When you specify a remote MCP server in the `tools` parameter, the API will attempt to get a list of tools from the server. The Responses API works with remote MCP servers that support either the Streamable HTTP or the HTTP/SSE transport protocols.
If successful in retrieving the list of tools, a new `mcp_list_tools` output item will appear in the model response output. The `tools` property of this object will show the tools that were successfully imported.
```json
{
"id": "mcpl_68a6102a4968819c8177b05584dd627b0679e572a900e618",
"type": "mcp_list_tools",
"server_label": "dmcp",
"tools": [
{
"annotations": null,
"description": "Given a string of text describing a dice roll...",
"input_schema": {
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"diceRollExpression": {
"type": "string"
}
},
"required": ["diceRollExpression"],
"additionalProperties": false
},
"name": "roll"
}
]
}
```
As long as the `mcp_list_tools` item is present in the context of an API
request, the API will not fetch a list of tools from the MCP server again at
each turn in a [conversation](https://developers.openai.com/api/docs/guides/conversation-state). We
recommend you keep this item in the model's context as part of every
conversation or workflow execution to optimize for latency.
#### Filtering tools
Some MCP servers can have dozens of tools, and exposing many tools to the model can result in high cost and latency. If you're only interested in a subset of tools an MCP server exposes, you can use the `allowed_tools` parameter to only import those tools.
Constrain allowed tools
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"tools": [
{
"type": "mcp",
"server_label": "dmcp",
"server_description": "A Dungeons and Dragons MCP server to assist with dice rolling.",
"server_url": "https://dmcp-server.deno.dev/sse",
"require_approval": "never",
"allowed_tools": ["roll"]
}
],
"input": "Roll 2d4+1"
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const resp = await client.responses.create({
model: "gpt-5",
tools: [{
type: "mcp",
server_label: "dmcp",
server_description: "A Dungeons and Dragons MCP server to assist with dice rolling.",
server_url: "https://dmcp-server.deno.dev/sse",
require_approval: "never",
allowed_tools: ["roll"],
}],
input: "Roll 2d4+1",
});
console.log(resp.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-5",
tools=[{
"type": "mcp",
"server_label": "dmcp",
"server_description": "A Dungeons and Dragons MCP server to assist with dice rolling.",
"server_url": "https://dmcp-server.deno.dev/sse",
"require_approval": "never",
"allowed_tools": ["roll"],
}],
input="Roll 2d4+1",
)
print(resp.output_text)
```
```csharp
using OpenAI.Responses;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5", apiKey: key);
ResponseCreationOptions options = new();
options.Tools.Add(ResponseTool.CreateMcpTool(
serverLabel: "dmcp",
serverUri: new Uri("https://dmcp-server.deno.dev/sse"),
allowedTools: new McpToolFilter() { ToolNames = { "roll" } },
toolCallApprovalPolicy: new McpToolCallApprovalPolicy(GlobalMcpToolCallApprovalPolicy.NeverRequireApproval)
));
OpenAIResponse response = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("Roll 2d4+1")
])
], options);
Console.WriteLine(response.GetOutputText());
```
### Step 2: Calling tools
Once the model has access to these tool definitions, it may choose to call them depending on what's in the model's context. When the model decides to call an MCP tool, the API will make an request to the remote MCP server to call the tool and put its output into the model's context. This creates an `mcp_call` item which looks like this:
```json
{
"id": "mcp_68a6102d8948819c9b1490d36d5ffa4a0679e572a900e618",
"type": "mcp_call",
"approval_request_id": null,
"arguments": "{\"diceRollExpression\":\"2d4 + 1\"}",
"error": null,
"name": "roll",
"output": "4",
"server_label": "dmcp"
}
```
This item includes both the arguments the model decided to use for this tool call, and the `output` that the remote MCP server returned. All models can choose to make multiple MCP tool calls, so you may see several of these items generated in a single API request.
Failed tool calls will populate the error field of this item with MCP protocol errors, MCP tool execution errors, or general connectivity errors. The MCP errors are documented in the MCP spec [here](https://modelcontextprotocol.io/specification/2025-03-26/server/tools#error-handling).
#### Approvals
By default, OpenAI will request your approval before any data is shared with a connector or remote MCP server. Approvals help you maintain control and visibility over what data is being sent to an MCP server. We highly recommend that you carefully review (and optionally log) all data being shared with a remote MCP server. A request for an approval to make an MCP tool call creates a `mcp_approval_request` item in the Response's output that looks like this:
```json
{
"id": "mcpr_68a619e1d82c8190b50c1ccba7ad18ef0d2d23a86136d339",
"type": "mcp_approval_request",
"arguments": "{\"diceRollExpression\":\"2d4 + 1\"}",
"name": "roll",
"server_label": "dmcp"
}
```
You can then respond to this by creating a new Response object and appending an `mcp_approval_response` item to it.
Approving the use of tools in an API request
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"tools": [
{
"type": "mcp",
"server_label": "dmcp",
"server_description": "A Dungeons and Dragons MCP server to assist with dice rolling.",
"server_url": "https://dmcp-server.deno.dev/sse",
"require_approval": "always",
}
],
"previous_response_id": "resp_682d498bdefc81918b4a6aa477bfafd904ad1e533afccbfa",
"input": [{
"type": "mcp_approval_response",
"approve": true,
"approval_request_id": "mcpr_682d498e3bd4819196a0ce1664f8e77b04ad1e533afccbfa"
}]
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const resp = await client.responses.create({
model: "gpt-5",
tools: [{
type: "mcp",
server_label: "dmcp",
server_description: "A Dungeons and Dragons MCP server to assist with dice rolling.",
server_url: "https://dmcp-server.deno.dev/sse",
require_approval: "always",
}],
previous_response_id: "resp_682d498bdefc81918b4a6aa477bfafd904ad1e533afccbfa",
input: [{
type: "mcp_approval_response",
approve: true,
approval_request_id: "mcpr_682d498e3bd4819196a0ce1664f8e77b04ad1e533afccbfa"
}],
});
console.log(resp.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-5",
tools=[{
"type": "mcp",
"server_label": "dmcp",
"server_description": "A Dungeons and Dragons MCP server to assist with dice rolling.",
"server_url": "https://dmcp-server.deno.dev/sse",
"require_approval": "always",
}],
previous_response_id="resp_682d498bdefc81918b4a6aa477bfafd904ad1e533afccbfa",
input=[{
"type": "mcp_approval_response",
"approve": True,
"approval_request_id": "mcpr_682d498e3bd4819196a0ce1664f8e77b04ad1e533afccbfa"
}],
)
print(resp.output_text)
```
```csharp
using OpenAI.Responses;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5", apiKey: key);
ResponseCreationOptions options = new();
options.Tools.Add(ResponseTool.CreateMcpTool(
serverLabel: "dmcp",
serverUri: new Uri("https://dmcp-server.deno.dev/sse"),
toolCallApprovalPolicy: new McpToolCallApprovalPolicy(GlobalMcpToolCallApprovalPolicy.AlwaysRequireApproval)
));
// STEP 1: Create response that requests tool call approval
OpenAIResponse response1 = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("Roll 2d4+1")
])
], options);
McpToolCallApprovalRequestItem? approvalRequestItem = response1.OutputItems.Last() as McpToolCallApprovalRequestItem;
// STEP 2: Approve the tool call request and get final response
options.PreviousResponseId = response1.Id;
OpenAIResponse response2 = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateMcpApprovalResponseItem(approvalRequestItem!.Id, approved: true),
], options);
Console.WriteLine(response2.GetOutputText());
```
Here we're using the `previous_response_id` parameter to chain this new Response, with the previous Response that generated the approval request. But you can also pass back the [outputs from one response, as inputs into another](https://developers.openai.com/api/docs/guides/conversation-state#manually-manage-conversation-state) for maximum control over what enter's the model's context.
If and when you feel comfortable trusting a remote MCP server, you can choose to skip the approvals for reduced latency. To do this, you can set the `require_approval` parameter of the MCP tool to an object listing just the tools you'd like to skip approvals for like shown below, or set it to the value `'never'` to skip approvals for all tools in that remote MCP server.
Never require approval for some tools
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"tools": [
{
"type": "mcp",
"server_label": "deepwiki",
"server_url": "https://mcp.deepwiki.com/mcp",
"require_approval": {
"never": {
"tool_names": ["ask_question", "read_wiki_structure"]
}
}
}
],
"input": "What transport protocols does the 2025-03-26 version of the MCP spec (modelcontextprotocol/modelcontextprotocol) support?"
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const resp = await client.responses.create({
model: "gpt-5",
tools: [
{
type: "mcp",
server_label: "deepwiki",
server_url: "https://mcp.deepwiki.com/mcp",
require_approval: {
never: {
tool_names: ["ask_question", "read_wiki_structure"]
}
}
},
],
input: "What transport protocols does the 2025-03-26 version of the MCP spec (modelcontextprotocol/modelcontextprotocol) support?",
});
console.log(resp.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-5",
tools=[
{
"type": "mcp",
"server_label": "deepwiki",
"server_url": "https://mcp.deepwiki.com/mcp",
"require_approval": {
"never": {
"tool_names": ["ask_question", "read_wiki_structure"]
}
}
},
],
input="What transport protocols does the 2025-03-26 version of the MCP spec (modelcontextprotocol/modelcontextprotocol) support?",
)
print(resp.output_text)
```
```csharp
using OpenAI.Responses;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5", apiKey: key);
ResponseCreationOptions options = new();
options.Tools.Add(ResponseTool.CreateMcpTool(
serverLabel: "deepwiki",
serverUri: new Uri("https://mcp.deepwiki.com/mcp"),
allowedTools: new McpToolFilter() { ToolNames = { "ask_question", "read_wiki_structure" } },
toolCallApprovalPolicy: new McpToolCallApprovalPolicy(GlobalMcpToolCallApprovalPolicy.NeverRequireApproval)
));
OpenAIResponse response = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("What transport protocols does the 2025-03-26 version of the MCP spec (modelcontextprotocol/modelcontextprotocol) support?")
])
], options);
Console.WriteLine(response.GetOutputText());
```
## Authentication
Unlike the [example MCP server we used above](https://dash.deno.com/playground/dmcp-server), most other MCP servers require authentication. The most common scheme is an OAuth access token. Provide this token using the `authorization` field of the MCP tool:
Use Stripe MCP tool
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"input": "Create a payment link for $20",
"tools": [
{
"type": "mcp",
"server_label": "stripe",
"server_url": "https://mcp.stripe.com",
"authorization": "$STRIPE_OAUTH_ACCESS_TOKEN"
}
]
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const resp = await client.responses.create({
model: "gpt-5",
input: "Create a payment link for $20",
tools: [
{
type: "mcp",
server_label: "stripe",
server_url: "https://mcp.stripe.com",
authorization: "$STRIPE_OAUTH_ACCESS_TOKEN"
}
]
});
console.log(resp.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-5",
input="Create a payment link for $20",
tools=[
{
"type": "mcp",
"server_label": "stripe",
"server_url": "https://mcp.stripe.com",
"authorization": "$STRIPE_OAUTH_ACCESS_TOKEN"
}
]
)
print(resp.output_text)
```
```csharp
using OpenAI.Responses;
string authToken = Environment.GetEnvironmentVariable("STRIPE_OAUTH_ACCESS_TOKEN")!;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5", apiKey: key);
ResponseCreationOptions options = new();
options.Tools.Add(ResponseTool.CreateMcpTool(
serverLabel: "stripe",
serverUri: new Uri("https://mcp.stripe.com"),
authorizationToken: authToken
));
OpenAIResponse response = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("Create a payment link for $20")
])
], options);
Console.WriteLine(response.GetOutputText());
```
To prevent the leakage of sensitive tokens, the Responses API does not store the value you provide in the `authorization` field. This value will also not be visible in the Response object created. Because of this, you must send the `authorization` value in every Responses API creation request you make.
## Connectors
The Responses API has built-in support for a limited set of connectors to third-party services. These connectors let you pull in context from popular applications, like Dropbox and Gmail, to allow the model to interact with popular services.
Connectors can be used in the same way as remote MCP servers. Both let an OpenAI model access additional third-party tools in an API request. However, instead of passing a `server_url` as you would to call a remote MCP server, you pass a `connector_id` which uniquely identifies a connector available in the API.
### Available connectors
- Dropbox: `connector_dropbox`
- Gmail: `connector_gmail`
- Google Calendar: `connector_googlecalendar`
- Google Drive: `connector_googledrive`
- Microsoft Teams: `connector_microsoftteams`
- Outlook Calendar: `connector_outlookcalendar`
- Outlook Email: `connector_outlookemail`
- SharePoint: `connector_sharepoint`
We prioritized services that don't have official remote MCP servers. GitHub, for instance, has an official MCP server you can connect to by passing `https://api.githubcopilot.com/mcp/` to the `server_url` field in the MCP tool.
### Authorizing a connector
In the `authorization` field, pass in an OAuth access token. OAuth client registration and authorization must be handled separately by your application.
For testing purposes, you can use Google's [OAuth 2.0 Playground](https://developers.google.com/oauthplayground/) to generate temporary access tokens that you can use in an API request.
To use the playground to test the connectors API functionality, start by entering:
```
https://www.googleapis.com/auth/calendar.events
```
This authorization scope will enable the API to read Google Calendar events. In the UI under "Step 1: Select and authorize APIs".
After authorizing the application with your Google account, you will come to "Step 2: Exchange authorization code for tokens". This will generate an access token you can use in an API request using the Google Calendar connector:
Use the Google Calendar connector
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"tools": [
{
"type": "mcp",
"server_label": "google_calendar",
"connector_id": "connector_googlecalendar",
"authorization": "ya29.A0AS3H6...",
"require_approval": "never"
}
],
"input": "What is on my Google Calendar for today?"
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const resp = await client.responses.create({
model: "gpt-5",
tools: [
{
type: "mcp",
server_label: "google_calendar",
connector_id: "connector_googlecalendar",
authorization: "ya29.A0AS3H6...",
require_approval: "never",
},
],
input: "What's on my Google Calendar for today?",
});
console.log(resp.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-5",
tools=[
{
"type": "mcp",
"server_label": "google_calendar",
"connector_id": "connector_googlecalendar",
"authorization": "ya29.A0AS3H6...",
"require_approval": "never",
},
],
input="What's on my Google Calendar for today?",
)
print(resp.output_text)
```
```csharp
using OpenAI.Responses;
string authToken = Environment.GetEnvironmentVariable("GOOGLE_CALENDAR_OAUTH_ACCESS_TOKEN")!;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5", apiKey: key);
ResponseCreationOptions options = new();
options.Tools.Add(ResponseTool.CreateMcpTool(
serverLabel: "google_calendar",
connectorId: McpToolConnectorId.GoogleCalendar,
authorizationToken: authToken,
toolCallApprovalPolicy: new McpToolCallApprovalPolicy(GlobalMcpToolCallApprovalPolicy.NeverRequireApproval)
));
OpenAIResponse response = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("What's on my Google Calendar for today?")
])
], options);
Console.WriteLine(response.GetOutputText());
```
An MCP tool call from a Connector will look the same as an MCP tool call from a remote MCP server, using the `mcp_call` output item type. In this case, both the arguments to and the response from the Connector are JSON strings:
```json
{
"id": "mcp_68a62ae1c93c81a2b98c29340aa3ed8800e9b63986850588",
"type": "mcp_call",
"approval_request_id": null,
"arguments": "{\"time_min\":\"2025-08-20T00:00:00\",\"time_max\":\"2025-08-21T00:00:00\",\"timezone_str\":null,\"max_results\":50,\"query\":null,\"calendar_id\":null,\"next_page_token\":null}",
"error": null,
"name": "search_events",
"output": "{\"events\": [{\"id\": \"2n8ni54ani58pc3ii6soelupcs_20250820\", \"summary\": \"Home\", \"location\": null, \"start\": \"2025-08-20T00:00:00\", \"end\": \"2025-08-21T00:00:00\", \"url\": \"https://www.google.com/calendar/event?eid=Mm44bmk1NGFuaTU4cGMzaWk2c29lbHVwY3NfMjAyNTA4MjAga3doaW5uZXJ5QG9wZW5haS5jb20&ctz=America/Los_Angeles\", \"description\": \"\\n\\n\", \"transparency\": \"transparent\", \"display_url\": \"https://www.google.com/calendar/event?eid=Mm44bmk1NGFuaTU4cGMzaWk2c29lbHVwY3NfMjAyNTA4MjAga3doaW5uZXJ5QG9wZW5haS5jb20&ctz=America/Los_Angeles\", \"display_title\": \"Home\"}], \"next_page_token\": null}",
"server_label": "Google_Calendar"
}
```
### Available tools in each connector
The available tools depend on which scopes your OAuth token has available to it. Expand the tables below to see what tools you can use when connecting to each application.
Dropbox
| Tool |
Description |
Scopes |
| `search` |
Search Dropbox for files that match a query |
files.metadata.read, account_info.read |
| `fetch` |
Fetch a file by path with optional raw download |
files.content.read |
| `search_files` |
Search Dropbox files and return results |
files.metadata.read, account_info.read |
| `fetch_file` |
Retrieve a file's text or raw content |
files.content.read, account_info.read |
| `list_recent_files` |
Return the most recently modified files accessible to the user |
files.metadata.read, account_info.read |
| `get_profile` |
Retrieve the Dropbox profile of the current user |
account_info.read |
Gmail
| Tool |
Description |
Scopes |
| `get_profile` |
Return the current Gmail user's profile |
userinfo.email, userinfo.profile |
| `search_emails` |
Search Gmail for emails matching a query or label |
gmail.modify |
| `search_email_ids` |
Retrieve Gmail message IDs matching a search |
gmail.modify |
| `get_recent_emails` |
Return the most recently received Gmail messages |
gmail.modify |
| `read_email` |
Fetch a single Gmail message including its body |
gmail.modify |
| `batch_read_email` |
Read multiple Gmail messages in one call |
gmail.modify |
Google Calendar
| Tool |
Description |
Scopes |
| `get_profile` |
Return the current Calendar user's profile |
userinfo.email, userinfo.profile |
| `search` |
Search Calendar events within an optional time window |
calendar.events |
| `fetch` |
Get details for a single Calendar event |
calendar.events |
| `search_events` |
Look up Calendar events using filters |
calendar.events |
| `read_event` |
Read a Google Calendar event by ID |
calendar.events |
Google Drive
| Tool |
Description |
Scopes |
| `get_profile` |
Return the current Drive user's profile |
userinfo.email, userinfo.profile |
| `list_drives` |
List shared drives accessible to the user |
drive.readonly |
| `search` |
Search Drive files using a query |
drive.readonly |
| `recent_documents` |
Return the most recently modified documents |
drive.readonly |
| `fetch` |
Download the content of a Drive file |
drive.readonly |
Microsoft Teams
| Tool |
Description |
Scopes |
| `search` |
Search Microsoft Teams chats and channel messages |
Chat.Read, ChannelMessage.Read.All |
| `fetch` |
Fetch a Teams message by path |
Chat.Read, ChannelMessage.Read.All |
| `get_chat_members` |
List the members of a Teams chat |
Chat.Read |
| `get_profile` |
Return the authenticated Teams user's profile |
User.Read |
Outlook Calendar
| Tool |
Description |
Scopes |
| `search_events` |
Search Outlook Calendar events with date filters |
Calendars.Read |
| `fetch_event` |
Retrieve details for a single event |
Calendars.Read |
| `fetch_events_batch` |
Retrieve multiple events in one call |
Calendars.Read |
| `list_events` |
List calendar events within a date range |
Calendars.Read |
| `get_profile` |
Retrieve the current user's profile |
User.Read |
Outlook Email
| Tool |
Description |
Scopes |
| `get_profile` |
Return profile info for the Outlook account |
User.Read |
| `list_messages` |
Retrieve Outlook emails from a folder |
Mail.Read |
| `search_messages` |
Search Outlook emails with optional filters |
Mail.Read |
| `get_recent_emails` |
Return the most recently received emails |
Mail.Read |
| `fetch_message` |
Fetch a single email by ID |
Mail.Read |
| `fetch_messages_batch` |
Retrieve multiple emails in one request |
Mail.Read |
Sharepoint
| Tool |
Description |
Scopes |
| `get_site` |
Resolve a SharePoint site by hostname and path |
Sites.Read.All |
| `search` |
Search SharePoint/OneDrive documents by keyword |
Sites.Read.All, Files.Read.All |
| `list_recent_documents` |
Return recently accessed documents |
Files.Read.All |
| `fetch` |
Fetch content from a Graph file download URL |
Files.Read.All |
| `get_profile` |
Retrieve the current user's profile |
User.Read |
## Defer loading tools in an MCP server
If you are using [tool search](https://developers.openai.com/api/docs/guides/tools-tool-search), you can defer loading the functions exposed by an MCP server until the model decides it needs them. To do this, set `defer_loading: true` on the MCP server tool definition.
When you defer loading an MCP server, the model can still use the MCP server's label and description to decide when to search it, but the individual function definitions are loaded only when needed. This can help reduce overall token usage, and it is most useful for MCP servers that expose large numbers of functions.
## Risks and safety
The MCP tool permits you to connect OpenAI models to external services. This is a powerful feature that comes with some risks.
For connectors, there is a risk of potentially sending sensitive data to OpenAI, or allowing models read access to potentially sensitive data in those services.
Remote MCP servers carry those same risks, but also have not been verified by OpenAI. These servers can allow models to access, send, and receive data, and take action in these services. All MCP servers are third-party services that are subject to their own terms and conditions.
If you come across a malicious MCP server, please report it to `security@openai.com`.
Below are some best practices to consider when integrating connectors and remote MCP servers.
#### Prompt injection
[Prompt injection](https://chatgpt.com/?prompt=what%20is%20prompt%20injection?) is an important security consideration in any LLM application, and is especially true when you give the model access to MCP servers and connectors which can access sensitive data or take action. Use these tools with appropriate caution and mitigations if the prompt for the model contains user-provided content.
#### Always require approval for sensitive actions
Use the available configurations of the `require_approval` and `allowed_tools` parameters to ensure that any sensitive actions require an approval flow.
#### URLs within MCP tool calls and outputs
It can be dangerous to request URLs or embed image URLs provided by tool call outputs either from connectors or remote MCP servers. Ensure that you trust the domains and services providing those URLs before embedding or otherwise using them in your application code.
#### Connecting to trusted servers
Pick official servers hosted by the service providers themselves (e.g. we recommend connecting to the Stripe server hosted by Stripe themselves on mcp.stripe.com, instead of a Stripe MCP server hosted by a third party). Because there aren't too many official remote MCP servers today, you may be tempted to use a MCP server hosted by an organization that doesn't operate that server and simply proxies request to that service via your API. If you must do this, be extra careful in doing your due diligence on these "aggregators", and carefully review how they use your data.
#### Log and review data being shared with third party MCP servers.
Because MCP servers define their own tool definitions, they may request for data that you may not always be comfortable sharing with the host of that MCP server. Because of this, the MCP tool in the Responses API defaults to requiring approvals of each MCP tool call being made. When developing your application, review the type of data being shared with these MCP servers carefully and robustly. Once you gain confidence in your trust of this MCP server, you can skip these approvals for more performant execution.
We also recommend logging any data sent to MCP servers. If you're using the Responses API with `store=true`, these data are already logged via the API for 30 days unless Zero Data Retention is enabled for your organization. You may also want to log these data in your own systems and perform periodic reviews on this to ensure data is being shared per your expectations.
Malicious MCP servers may include hidden instructions (prompt injections) designed to make OpenAI models behave unexpectedly. While OpenAI has implemented built-in safeguards to help detect and block these threats, it's essential to carefully review inputs and outputs, and ensure connections are established only with trusted servers.
MCP servers may update tool behavior unexpectedly, potentially leading to unintended or malicious behavior.
#### Implications on Zero Data Retention and Data Residency
The MCP tool is compatible with Zero Data Retention and Data Residency, but it's important to note that MCP servers are third-party services, and data sent to an MCP server is subject to their data retention and data residency policies.
In other words, if you're an organization with Data Residency in Europe, OpenAI will limit inference and storage of Customer Content to take place in Europe up until the point communication or data is sent to the MCP server. It is your responsibility to ensure that the MCP server also adheres to any Zero Data Retention or Data Residency requirements you may have. Learn more about Zero Data Retention and Data Residency [here](https://developers.openai.com/api/docs/guides/your-data).
## Usage notes
{" "}
| API Availability |
Rate limits |
Notes |
|
[Responses](https://developers.openai.com/api/docs/api-reference/responses)
[Chat Completions](https://developers.openai.com/api/docs/api-reference/chat)
[Assistants](https://developers.openai.com/api/docs/api-reference/assistants)
|
**Tier 1**
200 RPM
**Tier 2 and 3**
1000 RPM
**Tier 4 and 5**
2000 RPM
|
[Pricing](https://developers.openai.com/api/docs/pricing#built-in-tools)
[ZDR and data residency](https://developers.openai.com/api/docs/guides/your-data)
|
---
# Migrate to the Responses API
import {
CheckCircleFilled,
XCircle,
} from "@components/react/oai/platform/ui/Icon.react";
The [Responses API](https://developers.openai.com/api/docs/api-reference/responses) is our new API primitive, an evolution of [Chat Completions](https://developers.openai.com/api/docs/api-reference/chat) which brings added simplicity and powerful agentic primitives to your integrations.
**While Chat Completions remains supported, Responses is recommended for all new projects.**
## About the Responses API
The Responses API is a unified interface for building powerful, agent-like applications. It contains:
- Built-in tools like [web search](https://developers.openai.com/api/docs/guides/tools-web-search), [file search](https://developers.openai.com/api/docs/guides/tools-file-search)
, [computer use](https://developers.openai.com/api/docs/guides/tools-computer-use), [code interpreter](https://developers.openai.com/api/docs/guides/tools-code-interpreter), and [remote MCPs](https://developers.openai.com/api/docs/guides/tools-remote-mcp).
- Seamless multi-turn interactions that allow you to pass previous responses for higher accuracy reasoning results.
- Native multimodal support for text and images.
## Responses benefits
The Responses API contains several benefits over Chat Completions:
- **Better performance**: Using reasoning models, like GPT-5, with Responses will result in better model intelligence when compared to Chat Completions. Our internal evals reveal a 3% improvement in SWE-bench with same prompt and setup.
- **Agentic by default**: The Responses API is an agentic loop, allowing the model to call multiple tools, like `web_search`, `image_generation`, `file_search`, `code_interpreter`, remote MCP servers, as well as your own custom functions, within the span of one API request.
- **Lower costs**: Results in lower costs due to improved cache utilization (40% to 80% improvement when compared to Chat Completions in internal tests).
- **Stateful context**: Use `store: true` to maintain state from turn to turn, preserving reasoning and tool context from turn-to-turn.
- **Flexible inputs**: Pass a string with input or a list of messages; use instructions for system-level guidance.
- **Encrypted reasoning**: Opt-out of statefulness while still benefiting from advanced reasoning.
- **Future-proof**: Future-proofed for upcoming models.
| Capabilities | Chat Completions API | Responses API |
| ------------------- | --------------------- | --------------------- |
| Text generation | | |
| Audio | | Coming soon |
| Vision | | |
| Structured Outputs | | |
| Function calling | | |
| Web search | | |
| File search | | |
| Computer use | | |
| Code interpreter | | |
| MCP | | |
| Image generation | | |
| Reasoning summaries | | |
### Examples
See how the Responses API compares to the Chat Completions API in specific scenarios.
#### Messages vs. Items
Both APIs make it easy to generate output from our models. The input to, and result of, a call to Chat completions is an array of _Messages_, while
the Responses API uses _Items_. An Item is a union of many types, representing the range of possibilities
of model actions. A `message` is a type of Item, as is a `function_call` or `function_call_output`. Unlike a Chat Completions Message, where
many concerns are glued together into one object, Items are distinct from one another and better represent the basic unit of model context.
Additionally, Chat Completions can return multiple parallel generations as `choices`, using the `n` param. In Responses, we've removed this param, leaving only one generation.
When you get a response back from the Responses API, the fields differ slightly.
Instead of a `message`, you receive a typed `response` object with its own `id`.
Responses are stored by default. Chat completions are stored by default for new accounts.
To disable storage when using either API, set `store: false`.
The objects you recieve back from these APIs will differ slightly. In Chat Completions, you receive an array of
`choices`, each containing a `message`. In Responses, you receive an array of Items labled `output`.
### Additional differences
- Responses are stored by default. Chat completions are stored by default for new accounts. To disable storage in either API, set `store: false`.
- [Reasoning](https://developers.openai.com/api/docs/guides/reasoning) models have a richer experience in the Responses API with [improved tool usage](https://developers.openai.com/api/docs/guides/reasoning#keeping-reasoning-items-in-context). Starting with GPT-5.4, tool calling is not supported in Chat Completions with `reasoning: none`.
- Structured Outputs API shape is different. Instead of `response_format`, use `text.format` in Responses. Learn more in the [Structured Outputs](https://developers.openai.com/api/docs/guides/structured-outputs) guide.
- The function-calling API shape is different, both for the function config on the request, and function calls sent back in the response. See the full difference in the [function calling guide](https://developers.openai.com/api/docs/guides/function-calling).
- The Responses SDK has an `output_text` helper, which the Chat Completions SDK does not have.
- In Chat Completions, conversation state must be managed manually. The Responses API has compatibility with the [Conversations API](https://developers.openai.com/api/docs/guides/docs/guides/conversation-state?api-mode=responses#using-the-conversations-api) for persistent conversations, or the ability to pass a `previous_response_id` to easily chain Responses together.
## Migrating from Chat Completions
### 1. Update generation endpoints
Start by updating your generation endpoints from `post /v1/chat/completions` to `post /v1/responses`.
If you are not using functions or multimodal inputs, then you're done! Simple message inputs are compatible from one API to the other:
Web search tool
```bash
INPUT='[
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Hello!" }
]'
curl -s https://api.openai.com/v1/chat/completions \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d "{
\\"model\\": \\"gpt-5\\",
\\"messages\\": $INPUT
}"
curl -s https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d "{
\\"model\\": \\"gpt-5\\",
\\"input\\": $INPUT
}"
```
```javascript
const context = [
{ role: 'system', content: 'You are a helpful assistant.' },
{ role: 'user', content: 'Hello!' }
];
const completion = await client.chat.completions.create({
model: 'gpt-5',
messages: messages
});
const response = await client.responses.create({
model: "gpt-5",
input: context
});
```
```python
context = [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Hello!" }
]
completion = client.chat.completions.create(
model="gpt-5",
messages=messages
)
response = client.responses.create(
model="gpt-5",
input=context
)
```
Chat Completions
<>
With Chat Completions, you need to create an array of messages that specify different roles and content for each role.
Generate text from a model
```javascript
import OpenAI from 'openai';
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const completion = await client.chat.completions.create({
model: 'gpt-5',
messages: [
{ 'role': 'system', 'content': 'You are a helpful assistant.' },
{ 'role': 'user', 'content': 'Hello!' }
]
});
console.log(completion.choices[0].message.content);
```
```python
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message.content)
```
```bash
curl https://api.openai.com/v1/chat/completions \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
}'
```
Responses
<>
With Responses, you can separate instructions and input at the top-level. The API shape is similar to Chat Completions but has cleaner semantics.
Generate text from a model
```javascript
import OpenAI from 'openai';
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const response = await client.responses.create({
model: 'gpt-5',
instructions: 'You are a helpful assistant.',
input: 'Hello!'
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
instructions="You are a helpful assistant.",
input="Hello!"
)
print(response.output_text)
```
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"instructions": "You are a helpful assistant.",
"input": "Hello!"
}'
```
### 2. Update item definitions
Chat Completions
<>
With Chat Completions, you need to create an array of messages that specify different roles and content for each role.
Generate text from a model
```javascript
import OpenAI from 'openai';
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const completion = await client.chat.completions.create({
model: 'gpt-5',
messages: [
{ 'role': 'system', 'content': 'You are a helpful assistant.' },
{ 'role': 'user', 'content': 'Hello!' }
]
});
console.log(completion.choices[0].message.content);
```
```python
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message.content)
```
```bash
curl https://api.openai.com/v1/chat/completions \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
}'
```
Responses
<>
With Responses, you can separate instructions and input at the top-level. The API shape is similar to Chat Completions but has cleaner semantics.
Generate text from a model
```javascript
import OpenAI from 'openai';
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const response = await client.responses.create({
model: 'gpt-5',
instructions: 'You are a helpful assistant.',
input: 'Hello!'
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
instructions="You are a helpful assistant.",
input="Hello!"
)
print(response.output_text)
```
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"instructions": "You are a helpful assistant.",
"input": "Hello!"
}'
```
### 3. Update multi-turn conversations
If you have multi-turn conversations in your application, update your context logic.
Chat Completions
<>
In Chat Completions, you have to store and manage context yourself.
Multi-turn conversation
```javascript
let messages = [
{ 'role': 'system', 'content': 'You are a helpful assistant.' },
{ 'role': 'user', 'content': 'What is the capital of France?' }
];
const res1 = await client.chat.completions.create({
model: 'gpt-5',
messages
});
messages = messages.concat([res1.choices[0].message]);
messages.push({ 'role': 'user', 'content': 'And its population?' });
const res2 = await client.chat.completions.create({
model: 'gpt-5',
messages
});
```
```python
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"}
]
res1 = client.chat.completions.create(model="gpt-5", messages=messages)
messages += [res1.choices[0].message]
messages += [{"role": "user", "content": "And its population?"}]
res2 = client.chat.completions.create(model="gpt-5", messages=messages)
```
Responses
<>
With responses, the pattern is similar, you can pass outputs from one response to the input of another.
Multi-turn conversation
```python
context = [
{ "role": "role", "content": "What is the capital of France?" }
]
res1 = client.responses.create(
model="gpt-5",
input=context,
)
// Append the first response’s output to context
context += res1.output
// Add the next user message
context += [
{ "role": "role", "content": "And it's population?" }
]
res2 = client.responses.create(
model="gpt-5",
input=context,
)
```
```javascript
let context = [
{ role: "role", content: "What is the capital of France?" }
];
const res1 = await client.responses.create({
model: "gpt-5",
input: context,
});
// Append the first response’s output to context
context = context.concat(res1.output);
// Add the next user message
context.push({ role: "role", content: "And its population?" });
const res2 = await client.responses.create({
model: "gpt-5",
input: context,
});
```
As a simplification, we've also built a way to simply reference inputs and outputs from a previous response by passing its id.
You can use `previous_response_id` to form chains of responses that build upon one other or create forks in a history.
Multi-turn conversation
```javascript
const res1 = await client.responses.create({
model: 'gpt-5',
input: 'What is the capital of France?',
store: true
});
const res2 = await client.responses.create({
model: 'gpt-5',
input: 'And its population?',
previous_response_id: res1.id,
store: true
});
```
```python
res1 = client.responses.create(
model="gpt-5",
input="What is the capital of France?",
store=True
)
res2 = client.responses.create(
model="gpt-5",
input="And its population?",
previous_response_id=res1.id,
store=True
)
```
### 4. Decide when to use statefulness
Some organizations—such as those with Zero Data Retention (ZDR) requirements—cannot use the Responses API in a stateful way due to compliance or data retention policies. To support these cases, OpenAI offers encrypted reasoning items, allowing you to keep your workflow stateless while still benefiting from reasoning items.
To disable statefulness, but still take advantage of reasoning:
- set `store: false` in the [store field](https://developers.openai.com/api/docs/api-reference/responses/create#responses_create-store)
- add `["reasoning.encrypted_content"]` to the [include field](https://developers.openai.com/api/docs/api-reference/responses/create#responses_create-include)
The API will then return an encrypted version of the reasoning tokens, which you can pass back in future requests just like regular reasoning items.
For ZDR organizations, OpenAI enforces store=false automatically. When a request includes encrypted_content, it is decrypted in-memory (never written to disk), used for generating the next response, and then securely discarded. Any new reasoning tokens are immediately encrypted and returned to you, ensuring no intermediate state is ever persisted.
### 5. Update function definitions
There are two minor, but notable, differences in how functions are defined between Chat Completions and Responses.
1. In Chat Completions, functions are defined using externally tagged polymorphism, whereas in Responses, they are internally-tagged.
2. In Chat Completions, functions are non-strict by default, whereas in the Responses API, functions _are_ strict by default.
The Responses API function example on the right is functionally equivalent to the Chat Completions example on the left.
#### Follow function-calling best practices
In Responses, tool calls and their outputs are two distinct types of Items that are correlated using a `call_id`. See
the [tool calling docs](https://developers.openai.com/api/docs/guides/function-calling#function-tool-example) for more detail on how function calling works in Responses.
### 6. Update Structured Outputs definition
In the Responses API, defining structured outputs have moved from `response_format` to `text.format`:
Chat Completions
Structured Outputs
```bash
curl https://api.openai.com/v1/chat/completions \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"messages": [
{
"role": "user",
"content": "Jane, 54 years old",
}
],
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "person",
"strict": true,
"schema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"minLength": 1
},
"age": {
"type": "number",
"minimum": 0,
"maximum": 130
}
},
"required": [
"name",
"age"
],
"additionalProperties": false
}
}
},
"verbosity": "medium",
"reasoning_effort": "medium"
}'
```
```python
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-5",
messages=[
{
"role": "user",
"content": "Jane, 54 years old",
}
],
response_format={
"type": "json_schema",
"json_schema": {
"name": "person",
"strict": True,
"schema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"minLength": 1
},
"age": {
"type": "number",
"minimum": 0,
"maximum": 130
}
},
"required": [
"name",
"age"
],
"additionalProperties": False
}
}
},
verbosity="medium",
reasoning_effort="medium"
)
```
```javascript
const completion = await openai.chat.completions.create({
model: "gpt-5",
messages: [
{
"role": "user",
"content": "Jane, 54 years old",
}
],
response_format: {
type: "json_schema",
json_schema: {
name: "person",
strict: true,
schema: {
type: "object",
properties: {
name: {
type: "string",
minLength: 1
},
age: {
type: "number",
minimum: 0,
maximum: 130
}
},
required: [
name,
age
],
additionalProperties: false
}
}
},
verbosity: "medium",
reasoning_effort: "medium"
});
```
Responses
Structured Outputs
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"input": "Jane, 54 years old",
"text": {
"format": {
"type": "json_schema",
"name": "person",
"strict": true,
"schema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"minLength": 1
},
"age": {
"type": "number",
"minimum": 0,
"maximum": 130
}
},
"required": [
"name",
"age"
],
"additionalProperties": false
}
}
}
}'
```
```python
response = client.responses.create(
model="gpt-5",
input="Jane, 54 years old",
text={
"format": {
"type": "json_schema",
"name": "person",
"strict": True,
"schema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"minLength": 1
},
"age": {
"type": "number",
"minimum": 0,
"maximum": 130
}
},
"required": [
"name",
"age"
],
"additionalProperties": False
}
}
}
)
```
```javascript
const response = await openai.responses.create({
model: "gpt-5",
input: "Jane, 54 years old",
text: {
format: {
type: "json_schema",
name: "person",
strict: true,
schema: {
type: "object",
properties: {
name: {
type: "string",
minLength: 1
},
age: {
type: "number",
minimum: 0,
maximum: 130
}
},
required: [
name,
age
],
additionalProperties: false
}
},
}
});
```
### 7. Upgrade to native tools
If your application has use cases that would benefit from OpenAI's native [tools](https://developers.openai.com/api/docs/guides/tools), you can update your tool calls to use OpenAI's tools out of the box.
Chat Completions
<>
With Chat Completions, you cannot use OpenAI's tools natively and have to write your own.
Web search tool
```javascript
async function web_search(query) {
const fetch = (await import('node-fetch')).default;
const res = await fetch(\`https://api.example.com/search?q=\${query}\`);
const data = await res.json();
return data.results;
}
const completion = await client.chat.completions.create({
model: 'gpt-5',
messages: [
{ role: 'system', content: 'You are a helpful assistant.' },
{ role: 'user', content: 'Who is the current president of France?' }
],
functions: [
{
name: 'web_search',
description: 'Search the web for information',
parameters: {
type: 'object',
properties: { query: { type: 'string' } },
required: ['query']
}
}
]
});
```
```python
import requests
def web_search(query):
r = requests.get(f"https://api.example.com/search?q={query}")
return r.json().get("results", [])
completion = client.chat.completions.create(
model="gpt-5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who is the current president of France?"}
],
functions=[
{
"name": "web_search",
"description": "Search the web for information",
"parameters": {
"type": "object",
"properties": {"query": {"type": "string"}},
"required": ["query"]
}
}
]
)
```
```bash
curl https://api.example.com/search \\
-G \\
--data-urlencode "q=your+search+term" \\
--data-urlencode "key=$SEARCH_API_KEY"\
```
Responses
<>
With Responses, you can simply specify the tools that you are interested in.
Web search tool
```javascript
const answer = await client.responses.create({
model: 'gpt-5.5',
input: 'Who is the current president of France?',
tools: [{ type: 'web_search' }]
});
console.log(answer.output_text);
```
```python
answer = client.responses.create(
model="gpt-5.5",
input="Who is the current president of France?",
tools=[{"type": "web_search"}]
)
print(answer.output_text)
```
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5.5",
"input": "Who is the current president of France?",
"tools": [{"type": "web_search"}]
}'
```
## Incremental migration
The Responses API is a superset of the Chat Completions API. The Chat Completions API will also continue to be supported. As such, you can incrementally adopt the Responses API if desired. You can migrate user flows who would benefit from improved reasoning models to the Responses API while keeping other flows on the Chat Completions API until you're ready for a full migration.
As a best practice, we encourage all users to migrate to the Responses API to take advantage of the latest features and improvements from OpenAI.
## Assistants API
Based on developer feedback from the [Assistants API](https://developers.openai.com/api/docs/api-reference/assistants) beta, we've incorporated key improvements into the Responses API to make it more flexible, faster, and easier to use. The Responses API represents the future direction for building agents on OpenAI.
We now have Assistant-like and Thread-like objects in the Responses API. Learn more in the [migration guide](https://developers.openai.com/api/docs/guides/assistants/migration). As of August 26th, 2025, we're deprecating the Assistants API, with a sunset date of August 26, 2026.
---
# Model optimization
import {
Report,
Code,
Tools,
} from "@components/react/oai/platform/ui/Icon.react";
import {
evalsIcon,
promptIcon,
fineTuneIcon,
} from "./model-optimization-icons";
LLM output is non-deterministic, and model behavior changes between model snapshots and families. Developers must constantly measure and tune the performance of LLM applications to ensure they're getting the best results. In this guide, we explore the techniques and OpenAI platform tools you can use to ensure high quality outputs from the model.
## Model optimization workflow
Optimizing model output requires a combination of **evals**, **prompt engineering**, and **fine-tuning**, creating a flywheel of feedback that leads to better prompts and better training data for fine-tuning. The optimization process usually goes something like this.
1. Write [evals](https://developers.openai.com/api/docs/guides/evals) that measure model output, establishing a baseline for performance and accuracy.
1. [Prompt the model](https://developers.openai.com/api/docs/guides/text) for output, providing relevant context data and instructions.
1. For some use cases, it may be desirable to [fine-tune](#fine-tune-a-model) a model for a specific task.
1. Run evals using test data that is representative of real world inputs. Measure the performance of your prompt and fine-tuned model.
1. Tweak your prompt or fine-tuning dataset based on eval feedback.
1. Repeat the loop continuously to improve your model results.
Here's an overview of the major steps, and how to do them using the OpenAI platform.
## Build evals
In the OpenAI platform, you can [build and run evals](https://developers.openai.com/api/docs/guides/evals) either via API or in the [dashboard](https://platform.openai.com/evaluations). You might even consider writing evals _before_ you start writing prompts, taking an approach akin to behavior-driven development (BDD).
Run your evals against test inputs like you expect to see in production. Using one of several available [graders](https://developers.openai.com/api/docs/guides/graders), measure the results of a prompt against your test data set.
[
Run tests on your model outputs to ensure you're getting the right results.
](https://developers.openai.com/api/docs/guides/evals)
## Write effective prompts
With evals in place, you can effectively iterate on [prompts](https://developers.openai.com/api/docs/guides/text). The prompt engineering process may be all you need in order to get great results for your use case. Different models may require different prompting techniques, but there are several best practices you can apply across the board to get better results.
- **Include relevant context** - in your instructions, include text or image content that the model will need to generate a response from outside its training data. This could include data from private databases or current, up-to-the-minute information.
- **Provide clear instructions** - your prompt should contain clear goals about what kind of output you want. GPT models like `gpt-4.1` are great at following very explicit instructions, while [reasoning models](https://developers.openai.com/api/docs/guides/reasoning) like `o4-mini` tend to do better with high level guidance on outcomes.
- **Provide example outputs** - give the model a few examples of correct output for a given prompt (a process called few-shot learning). The model can extrapolate from these examples how it should respond for other prompts.
[
Learn the basics of writing good prompts for the model.
](https://developers.openai.com/api/docs/guides/text)
## Fine-tune a model
OpenAI is winding down the fine-tuning platform. The platform is no longer
accessible to new users, but existing users of the fine-tuning platform will
be able to create training jobs for the coming months.
All fine-tuned models will remain available for inference until their base
models are [deprecated](https://developers.openai.com/api/docs/deprecations). The full timeline is
[here](https://developers.openai.com/api/docs/deprecations).
OpenAI models are already pre-trained to perform across a broad range of subjects and tasks. Fine-tuning lets you take an OpenAI base model, provide the kinds of inputs and outputs you expect in your application, and get a model that excels in the tasks you'll use it for.
Fine-tuning can be a time-consuming process, but it can also enable a model to consistently format responses in a certain way or handle novel inputs. You can use fine-tuning with [prompt engineering](https://developers.openai.com/api/docs/guides/text) to realize a few more benefits over prompting alone:
- You can provide more example inputs and outputs than could fit within the context window of a single request, enabling the model handle a wider variety of prompts.
- You can use shorter prompts with fewer examples and context data, which saves on token costs at scale and can be lower latency.
- You can train on proprietary or sensitive data without having to include it via examples in every request.
- You can train a smaller, cheaper, faster model to excel at a particular task where a larger model is not cost-effective.
Visit our [pricing page](https://openai.com/api/pricing) to learn more about how fine-tuned model training and usage are billed.
### Fine-tuning methods
These are the fine-tuning methods supported in the OpenAI platform today.
### How fine-tuning works
In the OpenAI platform, you can create fine-tuned models either in the [dashboard](https://platform.openai.com/finetune) or [with the API](https://developers.openai.com/api/docs/api-reference/fine-tuning). This is the general shape of the fine-tuning process:
1. Collect a dataset of examples to use as training data
1. Upload that dataset to OpenAI, formatted in JSONL
1. Create a fine-tuning job using one of the methods above, depending on your goals—this begins the fine-tuning training process
1. In the case of RFT, you'll also define a grader to score the model's behavior
1. Evaluate the results
Get started with [supervised fine-tuning](https://developers.openai.com/api/docs/guides/supervised-fine-tuning), [vision fine-tuning](https://developers.openai.com/api/docs/guides/vision-fine-tuning), [direct preference optimization](https://developers.openai.com/api/docs/guides/direct-preference-optimization), or [reinforcement fine-tuning](https://developers.openai.com/api/docs/guides/reinforcement-fine-tuning).
## Learn from experts
Model optimization is a complex topic, and sometimes more art than science. Check out the videos below from members of the OpenAI team on model optimization techniques.
Cost/accuracy/latency
Optimizing LLM Performance
---
# Model selection
Choosing the right model, whether GPT-4o or a smaller option like GPT-4o-mini, requires balancing **accuracy**, **latency**, and **cost**. This guide explains key principles to help you make informed decisions, along with a practical example.
## Core principles
The principles for model selection are simple:
- **Optimize for accuracy first:** Optimize for accuracy until you hit your accuracy target.
- **Optimize for cost and latency second:** Then aim to maintain accuracy with the cheapest, fastest model possible.
### 1. Focus on accuracy first
Begin by setting a clear accuracy goal for your use case, where you're clear on the accuracy that would be "good enough" for this use case to go to production. You can accomplish this through:
- **Setting a clear accuracy target:** Identify what your target accuracy statistic is going to be.
- For example, 90% of customer service calls need to be triaged correctly at the first interaction.
- **Developing an evaluation dataset:** Create a dataset that allows you to measure the model's performance against these goals.
- To extend the example above, capture 100 interaction examples where we have what the user asked for, what the LLM triaged them to, what the correct triage should be, and whether this was correct or not.
- **Using the most powerful model to optimize:** Start with the most capable model available to achieve your accuracy targets. Log all responses so we can use them for distillation of a smaller model.
- Use retrieval-augmented generation to optimize for accuracy
- Use fine-tuning to optimize for consistency and behavior
During this process, collect prompt and completion pairs for use in evaluations, few-shot learning, or fine-tuning. This practice, known as **prompt baking**, helps you produce high-quality examples for future use.
For more methods and tools here, see our [Accuracy Optimization Guide](https://developers.openai.com/api/docs/guides/optimizing-llm-accuracy).
#### Setting a realistic accuracy target
Calculate a realistic accuracy target by evaluating the financial impact of model decisions. For example, in a fake news classification scenario:
- **Correctly classified news:** If the model classifies it correctly, it saves you the cost of a human reviewing it - let's assume **$50**.
- **Incorrectly classified news:** If it falsely classifies a safe article or misses a fake news article, it may trigger a review process and possible complaint, which might cost us **$300**.
Our news classification example would need **85.8%** accuracy to cover costs, so targeting 90% or more ensures an overall return on investment. Use these calculations to set an effective accuracy target based on your specific cost structures.
### 2. Optimize cost and latency
Cost and latency are considered secondary because if the model can’t hit your accuracy target then these concerns are moot. However, once you’ve got a model that works for your use case, you can take one of two approaches:
- **Compare with a smaller model zero- or few-shot:** Swap out the model for a smaller, cheaper one and test whether it maintains accuracy at the lower cost and latency point.
- **Model distillation:** Fine-tune a smaller model using the data gathered during accuracy optimization.
Cost and latency are typically interconnected; reducing tokens and requests generally leads to faster processing.
The main strategies to consider here are:
- **Reduce requests:** Limit the number of necessary requests to complete tasks.
- **Minimize tokens:** Lower the number of input tokens and optimize for shorter model outputs.
- **Select a smaller model:** Use models that balance reduced costs and latency with maintained accuracy.
To dive deeper into these, please refer to our guide on [latency optimization](https://developers.openai.com/api/docs/guides/latency-optimization).
#### Exceptions to the rule
Clear exceptions exist for these principles. If your use case is extremely cost or latency sensitive, establish thresholds for these metrics before beginning your testing, then remove the models that exceed those from consideration. Once benchmarks are set, these guidelines will help you refine model accuracy within your constraints.
## Practical example
To demonstrate these principles, we'll develop a fake news classifier with the following target metrics:
- **Accuracy:** Achieve 90% correct classification
- **Cost:** Spend less than $5 per 1,000 articles
- **Latency:** Maintain processing time under 2 seconds per article
### Experiments
We ran three experiments to reach our goal:
1. **Zero-shot:** Used `GPT-4o` with a basic prompt for 1,000 records, but missed the accuracy target.
2. **Few-shot learning:** Included 5 few-shot examples, meeting the accuracy target but exceeding cost due to more prompt tokens.
3. **Fine-tuned model:** Fine-tuned `GPT-4o-mini` with 1,000 labeled examples, meeting all targets with similar latency and accuracy but significantly lower costs.
| ID | Method | Accuracy | Accuracy target | Cost | Cost target | Avg. latency | Latency target |
| --- | --------------------------------------- | -------- | --------------- | ------ | ----------- | ------------ | -------------- |
| 1 | gpt-4o zero-shot | 84.5% | | $1.72 | | < 1s | |
| 2 | gpt-4o few-shot (n=5) | 91.5% | ✓ | $11.92 | | < 1s | ✓ |
| 3 | gpt-4o-mini fine-tuned w/ 1000 examples | 91.5% | ✓ | $0.21 | ✓ | < 1s | ✓ |
## Conclusion
By switching from `gpt-4o` to `gpt-4o-mini` with fine-tuning, we achieved **equivalent performance for less than 2%** of the cost, using only 1,000 labeled examples.
This process is important - you often can’t jump right to fine-tuning because you don’t know whether fine-tuning is the right tool for the optimization you need, or you don’t have enough labeled examples. Use `gpt-4o` to achieve your accuracy targets, and curate a good training set - then go for a smaller, more efficient model with fine-tuning.
---
# Models and providers
Every SDK run eventually resolves a model and a transport. Most applications should keep that setup straightforward: choose models explicitly, use the standard OpenAI path by default, and reach for provider or transport overrides only when the workflow actually needs them.
## Start with explicit model selection
In production, prefer explicit model choice over whichever runtime default your SDK release happens to ship with.
- Set `model` on an agent when that specialist consistently needs a different quality, latency, or cost profile.
- Set a run-level default when one workflow should override several agents at once.
- Set `OPENAI_DEFAULT_MODEL` when you want a process-wide fallback for agents that omit `model`.
Set models per agent and per run
```typescript
import { Agent, Runner } from "@openai/agents";
const fastAgent = new Agent({
name: "Fast support agent",
instructions: "Handle routine support questions.",
model: "gpt-5.4-mini",
});
const generalAgent = new Agent({
name: "General support agent",
instructions: "Handle support questions carefully.",
});
const runner = new Runner({
model: "gpt-5.5",
});
await runner.run(fastAgent, "Summarize ticket 123.");
const result = await runner.run(
generalAgent,
"Investigate the billing issue on account 456.",
);
console.log(result.finalOutput);
```
```python
import asyncio
from agents import Agent, RunConfig, Runner
fast_agent = Agent(
name="Fast support agent",
instructions="Handle routine support questions.",
model="gpt-5.4-mini",
)
general_agent = Agent(
name="General support agent",
instructions="Handle support questions carefully.",
)
async def main() -> None:
await Runner.run(fast_agent, "Summarize ticket 123.")
result = await Runner.run(
general_agent,
"Investigate the billing issue on account 456.",
run_config=RunConfig(model="gpt-5.5"),
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
```
For most new SDK workflows, start with [`gpt-5.5`](https://developers.openai.com/api/docs/models/gpt-5.5) and move to a smaller variant only when latency or cost matters enough to justify it. Use the platform-wide [Using GPT-5.5](https://developers.openai.com/api/docs/guides/latest-model) guide for current model-selection advice.
## Choose the simplest default strategy
| If you need | Start with | Why |
| ---------------------------------------------- | ------------------------- | ------------------------------------------------------------------------------------ |
| One explicit model per specialist | Set `model` on each agent | The workflow stays readable in code and traces |
| One fallback across a whole process | `OPENAI_DEFAULT_MODEL` | Agents that omit `model` still resolve predictably |
| One workflow-level override | A run-level default | You can swap models for a script, worker, or environment without editing every agent |
| Different model sizes across the same workflow | Mix per-agent models | A fast triage agent and a slower deep specialist can coexist cleanly |
If your team cares about the exact default, don't rely on the SDK fallback. Set it yourself.
## Providers and transport
| Need | Start with |
| ------------------------------------------------------- | ----------------------------------------------------------------- |
| Standard SDK runs on OpenAI | The default OpenAI provider path |
| Many repeated Responses model round trips over a socket | Responses WebSocket transport in the SDK |
| Non-OpenAI models or a mixed-provider stack | The provider or adapter surface in the language-specific SDK docs |
Two distinctions matter:
- The Responses WebSocket transport still uses the normal text-and-tools agent loop. It's separate from the voice session path.
- Live audio sessions over WebRTC or WebSocket are for low-latency voice or image interactions. Use [Voice agents](https://developers.openai.com/api/docs/guides/voice-agents) and the [live audio API guide](https://developers.openai.com/api/docs/guides/realtime) for that path.
Exact provider configuration, provider lifecycle management, and transport helper APIs remain language-specific material. Keep those details in the SDK docs instead of duplicating them here.
## Model settings, prompts, and feature support
Model choice is only part of the runtime contract.
- Use for tuning such as reasoning effort, verbosity, and tool behavior.
- Use `prompt` when you want a stored prompt configuration to control the run instead of embedding the full system prompt in code.
- Some SDK features depend on the OpenAI Responses path rather than older compatibility surfaces, so check the SDK docs when you need advanced tool-loading or transport features.
Keep the model contract close to the agent definition when it's intrinsic to that specialist. Move it to a workflow-level default only when a group of agents should share the same runtime choice.
## Next steps
Once the runtime contract is clear, continue with the guide that matches the rest of the workflow design.
---
# Moderation
Use the [moderations](https://developers.openai.com/api/docs/api-reference/moderations) endpoint to check whether text or images are potentially harmful. If harmful content is identified, you can take corrective action, like filtering content or intervening with user accounts creating offending content. The moderation endpoint is free to use. Image files are limited to 20 MB.
You can use two models for this endpoint:
- `omni-moderation-latest`: This model and all snapshots support more categorization options and multi-modal inputs.
- `text-moderation-latest` **(Legacy)**: Older model that supports only text inputs and fewer input categorizations. The newer omni-moderation models will be the best choice for new applications.
## Quickstart
Use the tabs below to see how you can moderate text inputs or image inputs, using our [official SDKs](https://developers.openai.com/api/docs/libraries) and the [omni-moderation-latest model](https://developers.openai.com/api/docs/models#moderation):
Here's a full example output, where the input is an image from a single frame of a war movie. The model correctly predicts indicators of violence in the image, with a `violence` category score of greater than 0.8.
```json
{
"id": "modr-970d409ef3bef3b70c73d8232df86e7d",
"model": "omni-moderation-latest",
"results": [
{
"flagged": true,
"categories": {
"sexual": false,
"sexual/minors": false,
"harassment": false,
"harassment/threatening": false,
"hate": false,
"hate/threatening": false,
"illicit": false,
"illicit/violent": false,
"self-harm": false,
"self-harm/intent": false,
"self-harm/instructions": false,
"violence": true,
"violence/graphic": false
},
"category_scores": {
"sexual": 2.34135824776394e-7,
"sexual/minors": 1.6346470245419304e-7,
"harassment": 0.0011643905680426018,
"harassment/threatening": 0.0022121340080906377,
"hate": 3.1999824407395835e-7,
"hate/threatening": 2.4923252458203563e-7,
"illicit": 0.0005227032493135171,
"illicit/violent": 3.682979260160596e-7,
"self-harm": 0.0011175734280627694,
"self-harm/intent": 0.0006264858507989037,
"self-harm/instructions": 7.368592981140821e-8,
"violence": 0.8599265510337075,
"violence/graphic": 0.37701736389561064
},
"category_applied_input_types": {
"sexual": ["image"],
"sexual/minors": [],
"harassment": [],
"harassment/threatening": [],
"hate": [],
"hate/threatening": [],
"illicit": [],
"illicit/violent": [],
"self-harm": ["image"],
"self-harm/intent": ["image"],
"self-harm/instructions": ["image"],
"violence": ["image"],
"violence/graphic": ["image"]
}
}
]
}
```
The output has several categories in the JSON response, which tell you which (if any) categories of content are present in the inputs, and to what degree the model believes them to be present.
| Output category |
Description |
| `flagged` |
Set to `true` if the model classifies the content as potentially harmful,
`false` otherwise.
|
| `categories` |
Contains a dictionary of per-category violation flags. For each category,
the value is `true` if the model flags the corresponding category as
violated, `false` otherwise.
|
| `category_scores` |
Contains a dictionary of per-category scores output by the model, denoting
the model's confidence that the input violates the OpenAI's policy for the
category. The value is between 0 and 1, where higher values denote higher
confidence.
|
| `category_applied_input_types` |
This property contains information on which input types were flagged in
the response, for each category. For example, if the both the image and
text inputs to the model are flagged for "violence/graphic", the
`violence/graphic` property will be set to `["image", "text"]`. This is
only available on omni models.
|
We plan to continuously upgrade the moderation endpoint's underlying model.
Therefore, custom policies that rely on `category_scores` may need
recalibration over time.
## Content classifications
The table below describes the types of content that can be detected in the moderation API, along with which models and input types are supported for each category.
Categories marked as "Text only" do not support image inputs. If you send only
images (without accompanying text) to the `omni-moderation-latest` model, it
will return a score of 0 for these unsupported categories. Image files are
limited to 20 MB.
|
Category
|
Description
|
Models
|
Inputs
|
| `harassment` |
Content that expresses, incites, or promotes harassing language towards
any target.
|
All |
Text only |
| `harassment/threatening` |
Harassment content that also includes violence or serious harm towards any
target.
|
All |
Text only |
| `hate` |
Content that expresses, incites, or promotes hate based on race, gender,
ethnicity, religion, nationality, sexual orientation, disability status,
or caste. Hateful content aimed at non-protected groups (e.g., chess
players) is harassment.
|
All |
Text only |
| `hate/threatening` |
Hateful content that also includes violence or serious harm towards the
targeted group based on race, gender, ethnicity, religion, nationality,
sexual orientation, disability status, or caste.
|
All |
Text only |
| `illicit` |
Content that gives advice or instruction on how to commit illicit acts. A
phrase like "how to shoplift" would fit this category.
|
Omni only |
Text only |
| `illicit/violent` |
The same types of content flagged by the `illicit` category, but also
includes references to violence or procuring a weapon.
|
Omni only |
Text only |
| `self-harm` |
Content that promotes, encourages, or depicts acts of self-harm, such as
suicide, cutting, and eating disorders.
|
All |
Text and images |
| `self-harm/intent` |
Content where the speaker expresses that they are engaging or intend to
engage in acts of self-harm, such as suicide, cutting, and eating
disorders.
|
All |
Text and images |
| `self-harm/instructions` |
Content that encourages performing acts of self-harm, such as suicide,
cutting, and eating disorders, or that gives instructions or advice on how
to commit such acts.
|
All |
Text and images |
| `sexual` |
Content meant to arouse sexual excitement, such as the description of
sexual activity, or that promotes sexual services (excluding sex education
and wellness).
|
All |
Text and images |
| `sexual/minors` |
Sexual content that includes an individual who is under 18 years old.
|
All |
Text only |
| `violence` |
Content that depicts death, violence, or physical injury. |
All |
Text and images |
| `violence/graphic` |
Content that depicts death, violence, or physical injury in graphic
detail.
|
All |
Text and images |
---
# Node reference
[Agent Builder](https://platform.openai.com/agent-builder) is a visual canvas for composing agentic worfklows. Workflows are made up of nodes and connections that control the sequence and flow. Insert nodes, then configure and connect them to define the process you want your agents to follow.
Explore all available nodes below. To learn more, read the [Agent Builder guide](https://developers.openai.com/api/docs/guides/agent-builder).
### Core nodes
Get started with basic building blocks. All workflows have start and agent nodes.

#### Start
Define inputs to your workflow. For user input in a chat workflow, start nodes do two things:
- Append the user input to the conversation history
- Expose `input_as_text` to represent the text contents of this input
All chat start nodes have `input_as_text` as an input variable. You can add state variables too.
#### Agent
Define instructions, tools, and model configuration, or attach evaluations.
Keep each agent well defined in scope. In our homework helper example, we use one agent to rewrite the user's query for more specificity and relevance with the knowledge base. We use another agent to classify the query as either Q&A or fact-finding, and another agent to field each type of question.
Add model behavior instructions and user messages as you would with any other model prompt. To pipe output from a previous step, you can add it as context.
You can have as many agent nodes as you'd like.
#### Note
Leave comments and explanations about your workflow. Unlike other nodes, notes don't _do_ anything in the flow. They're just helpful commentary for you and your team.
### Tool nodes
Tool nodes let you equip your agents with tools and external services. You can retrieve data, monitor for misuse, and connect to external services.
#### File search
Retrieve data from vector stores you've created in the OpenAI platform. Search by vector store ID, and add a query for what the model should search for. You can use variables to include output from previous nodes in the workflow.
See the [file search documentation](https://developers.openai.com/api/docs/guides/tools-file-search) to set up vector stores and see supported file types.
To search outside of your hosted storage with OpenAI, use [MCP](#mcp) instead.
#### Guardrails
Set up input monitors for unwanted inputs such as personally identifiable information (PII), jailbreaks, hallucinations, and other misuse.
Guardrails are pass/fail by default, meaning they test the output from a previous node, and you define what happens next. When there's a guardrails failure, we recommend either ending the workflow or returning to the previous step with a reminder of safe use.
#### MCP
Call third-party tools and services. Connect with OpenAI connectors or third-party servers, or add your own server. MCP connections are helpful in a workflow that needs to read or search data in another application, like Gmail or Zapier.
Browse options in the Agent Builder. To learn more about MCP, see the [connectors and MCP documentation](https://developers.openai.com/api/docs/guides/tools-connectors-mcp).
### Logic nodes
Logic nodes let you write custom logic and define the control flow—for example, looping on custom conditions, or asking the user for approval before continuing an operation.
#### If/else
Add conditional logic. Use [Common Expression Language](https://cel.dev/) (CEL) to create a custom expression. Useful for defining what to do with input that's been sorted into classifications.
For example, if an agent classifies input as Q&A, route that query to the Q&A agent for a straightforward answer. If it's an open-ended query, route to an agent that finds relevant facts. Else, end the workflow.
#### While
Loop on custom conditions. Use [Common Expression Language](https://cel.dev/) (CEL) to create a custom expression. Useful for checking whether a condition is still true.
#### Human approval
Defer to end-users for approval. Useful for workflows where agents draft work that could use a human review before it goes out.
For example, picture an agent workflow that sends emails on your behalf. You'd include an agent node that outputs an email widget, then a human approval node immediately following. You can configure the human approval node to ask, "Would you like me to send this email?" and, if approved, proceeds to an MCP node that connects to Gmail.
### Data nodes
Data nodes let you define and manipulate data in your workflow. Reshape outputs or define global variables for use across your workflow.
#### Transform
Reshape outputs (e.g., object → array). Useful for enforcing types to adhere to your schema or reshaping outputs for agents to read and understand as inputs.
#### Set state
Define global variables for use across the workflow. Useful for when an agent takes input and outputs something new that you'll want to use throughout the workflow. You can define that output as a new global variable.
---
# Optimizing LLM Accuracy
### How to maximize correctness and consistent behavior when working with LLMs
Optimizing LLMs is hard.
We've worked with many developers across both start-ups and enterprises, and the reason optimization is hard consistently boils down to these reasons:
- Knowing **how to start** optimizing accuracy
- **When to use what** optimization method
- What level of accuracy is **good enough** for production
This paper gives a mental model for how to optimize LLMs for accuracy and behavior. We’ll explore methods like prompt engineering, retrieval-augmented generation (RAG) and fine-tuning. We’ll also highlight how and when to use each technique, and share a few pitfalls.
As you read through, it's important to mentally relate these principles to what accuracy means for your specific use case. This may seem obvious, but there is a difference between producing a bad copy that a human needs to fix vs. refunding a customer $1000 rather than $100. You should enter any discussion on LLM accuracy with a rough picture of how much a failure by the LLM costs you, and how much a success saves or earns you - this will be revisited at the end, where we cover how much accuracy is “good enough” for production.
## LLM optimization context
Many “how-to” guides on optimization paint it as a simple linear flow - you start with prompt engineering, then you move on to retrieval-augmented generation, then fine-tuning. However, this is often not the case - these are all levers that solve different things, and to optimize in the right direction you need to pull the right lever.
It is useful to frame LLM optimization as more of a matrix:

The typical LLM task will start in the bottom left corner with prompt engineering, where we test, learn, and evaluate to get a baseline. Once we’ve reviewed those baseline examples and assessed why they are incorrect, we can pull one of our levers:
- **Context optimization:** You need to optimize for context when 1) the model lacks contextual knowledge because it wasn’t in its training set, 2) its knowledge is out of date, or 3) it requires knowledge of proprietary information. This axis maximizes **response accuracy**.
- **LLM optimization:** You need to optimize the LLM when 1) the model is producing inconsistent results with incorrect formatting, 2) the tone or style of speech is not correct, or 3) the reasoning is not being followed consistently. This axis maximizes **consistency of behavior**.
In reality this turns into a series of optimization steps, where we evaluate, make a hypothesis on how to optimize, apply it, evaluate, and re-assess for the next step. Here’s an example of a fairly typical optimization flow:
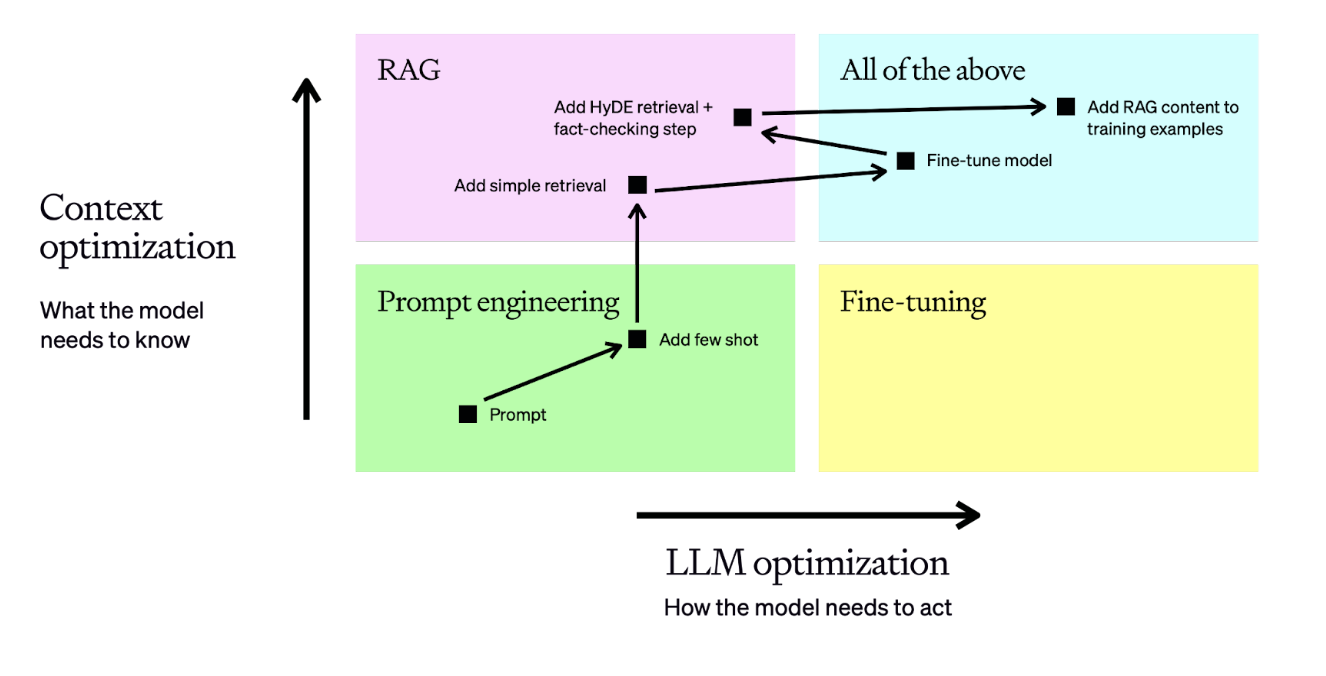
In this example, we do the following:
- Begin with a prompt, then evaluate its performance
- Add static few-shot examples, which should improve consistency of results
- Add a retrieval step so the few-shot examples are brought in dynamically based on the question - this boosts performance by ensuring relevant context for each input
- Prepare a dataset of 50+ examples and fine-tune a model to increase consistency
- Tune the retrieval and add a fact-checking step to find hallucinations to achieve higher accuracy
- Re-train the fine-tuned model on the new training examples which include our enhanced RAG inputs
This is a fairly typical optimization pipeline for a tough business problem - it helps us decide whether we need more relevant context or if we need more consistent behavior from the model. Once we make that decision, we know which lever to pull as our first step toward optimization.
Now that we have a mental model, let’s dive into the methods for taking action on all of these areas. We’ll start in the bottom-left corner with Prompt Engineering.
### Prompt engineering
Prompt engineering is typically the best place to start\*\*. It is often the only method needed for use cases like summarization, translation, and code generation where a zero-shot approach can reach production levels of accuracy and consistency.
This is because it forces you to define what accuracy means for your use case - you start at the most basic level by providing an input, so you need to be able to judge whether or not the output matches your expectations. If it is not what you want, then the reasons **why** will show you what to use to drive further optimizations.
To achieve this, you should always start with a simple prompt and an expected output in mind, and then optimize the prompt by adding **context**, **instructions**, or **examples** until it gives you what you want.
#### Optimization
To optimize your prompts, I’ll mostly lean on strategies from the [Prompt Engineering guide](https://developers.openai.com/api/docs/guides/prompt-engineering) in the OpenAI API documentation. Each strategy helps you tune Context, the LLM, or both:
| Strategy | Context optimization | LLM optimization |
| ----------------------------------------- | :------------------: | :--------------: |
| Write clear instructions | | X |
| Split complex tasks into simpler subtasks | X | X |
| Give GPTs time to "think" | | X |
| Test changes systematically | X | X |
| Provide reference text | X | |
| Use external tools | X | |
These can be a little difficult to visualize, so we’ll run through an example where we test these out with a practical example. Let’s use gpt-4-turbo to correct Icelandic sentences to see how this can work.
Prompt engineering for language corrections
The [Icelandic Errors Corpus](https://repository.clarin.is/repository/xmlui/handle/20.500.12537/105) contains combinations of an Icelandic sentence with errors, and the corrected version of that sentence. We’ll use the baseline GPT-4 model to try to solve this task, and then apply different optimization techniques to see how we can improve the model’s performance.
Given an Icelandic sentence, we want the model to return a corrected version of the sentence. We’ll use Bleu score to measure the relative quality of the translation.
| system | user | ground_truth | assistant | BLEU |
| ------------------------------------------------------------------------------------------------------------------------------------------------ | ----------------------------------------------------------- | ---------------------------------------------------------- | ---------------------------------------------------------- | ---- |
| The following sentences contain Icelandic sentences which may include errors. Please correct these errors using as few word changes as possible. | Sörvistölur eru nær hálsi og skartgripir kvenna á brjótsti. | Sörvistölur eru nær hálsi og skartgripir kvenna á brjósti. | Sörvistölur eru nær hálsi og skartgripir kvenna á brjósti. | 1.0 |
We perform a first attempt with GPT-4 with no examples, and it performs decently, getting a BLEU score of 62.
We’ll now add some few-shot examples and see whether we can teach the model the style we’re looking for by showing rather than telling.
An example looks like this:
```example-chat
SYSTEM: The following sentences contain Icelandic sentences which may include errors. Please correct these errors using as few word changes as possible.
# Examples
USER: "Stofnendurnir séu margir og eru fulltrúar hennar frá Englandi, Grikklandi, Rússlandi, Svíþjóð og fleiri löndum Evrópu."
ASSISTANT: "Hann segir að stofnendur leynireglunnar séu margir og að fulltrúar hennar séu frá Englandi, Grikklandi, Rússlandi, Svíþjóð og fleiri löndum Evrópu."
USER: "Helsta fæða bjúgorma eru hægfara lífverur sem eru á sama búsvæði og bjúgormarnir, oft smærri ormar eins og burstormar (fræðiheiti: Polychatete)."
ASSISTANT: "Helsta fæða bjúgorma eru hægfara lífverur sem eru á sama búsvæði og bjúgormarnir, oft smærri ormar eins og burstaormar (fræðiheiti: Polychatete)."
USER: "Sörvistölur eru nær hálsi og skartgripir kvenna á brjótsti."
ASSISTANT: "Sörvistölur eru nær hálsi og skartgripir kvenna á brjósti."
USER: [input user query here]
```
The overall translation quality is better, showing an improvement to a Bleu score of **70 (+8%)**. This is pretty good, and shows us that giving the model examples of the task is helping it to learn.
This tells us that it is the **behavior** of the model that we need to optimize - it already has the knowledge that it needs to solve the problem, so providing many more examples may be the optimization we need.
We’ll revisit this later in the paper to test how our more advanced optimization methods play with this use case.
We’ve seen that prompt engineering is a great place to start, and that with the right tuning methods we can push the performance pretty far.
However, the biggest issue with prompt engineering is that it often doesn’t scale - we either need dynamic context to be fed to allow the model to deal with a wider range of problems than we can deal with through adding content to the context, or we need more consistent behavior than we can achieve with few-shot examples.
Long-context models allow prompt engineering to scale further - however,
beware that models can struggle to maintain attention across very large
prompts with complex instructions, and so you should always pair long context
models with evaluation at different context sizes to ensure you don’t get
[**lost in the middle**](https://arxiv.org/abs/2307.03172). "Lost in the
middle" is a term that addresses how an LLM can't pay equal attention to all
the tokens given to it at any one time. This can result in it missing
information seemingly randomly. This doesn't mean you shouldn't use long
context, but you need to pair it with thorough evaluation. One open-source
contributor, Greg Kamradt, made a useful evaluation called [**Needle in A
Haystack (NITA)**](https://github.com/gkamradt/LLMTest_NeedleInAHaystack)
which hid a piece of information at varying depths in long-context documents
and evaluated the retrieval quality. This illustrates the problem with
long-context - it promises a much simpler retrieval process where you can dump
everything in context, but at a cost in accuracy.
So how far can you really take prompt engineering? The answer is that it depends, and the way you make your decision is through evaluations.
### Evaluation
This is why **a good prompt with an evaluation set of questions and ground truth answers** is the best output from this stage. If we have a set of 20+ questions and answers, and we have looked into the details of the failures and have a hypothesis of why they’re occurring, then we’ve got the right baseline to take on more advanced optimization methods.
Before you move on to more sophisticated optimization methods, it's also worth considering how to automate this evaluation to speed up your iterations. Some common practices we’ve seen be effective here are:
- Using approaches like [ROUGE](https://aclanthology.org/W04-1013/) or [BERTScore](https://arxiv.org/abs/1904.09675) to provide a finger-in-the-air judgment. This doesn’t correlate that closely with human reviewers, but can give a quick and effective measure of how much an iteration changed your model outputs.
- Using [GPT-4](https://arxiv.org/pdf/2303.16634.pdf) as an evaluator as outlined in the G-Eval paper, where you provide the LLM a scorecard to assess the output as objectively as possible.
If you want to dive deeper on these, check out [this cookbook](https://developers.openai.com/cookbook/examples/evaluation/how_to_eval_abstractive_summarization) which takes you through all of them in practice.
## Understanding the tools
So you’ve done prompt engineering, you’ve got an eval set, and your model is still not doing what you need it to do. The most important next step is to diagnose where it is failing, and what tool works best to improve it.
Here is a basic framework for doing so:
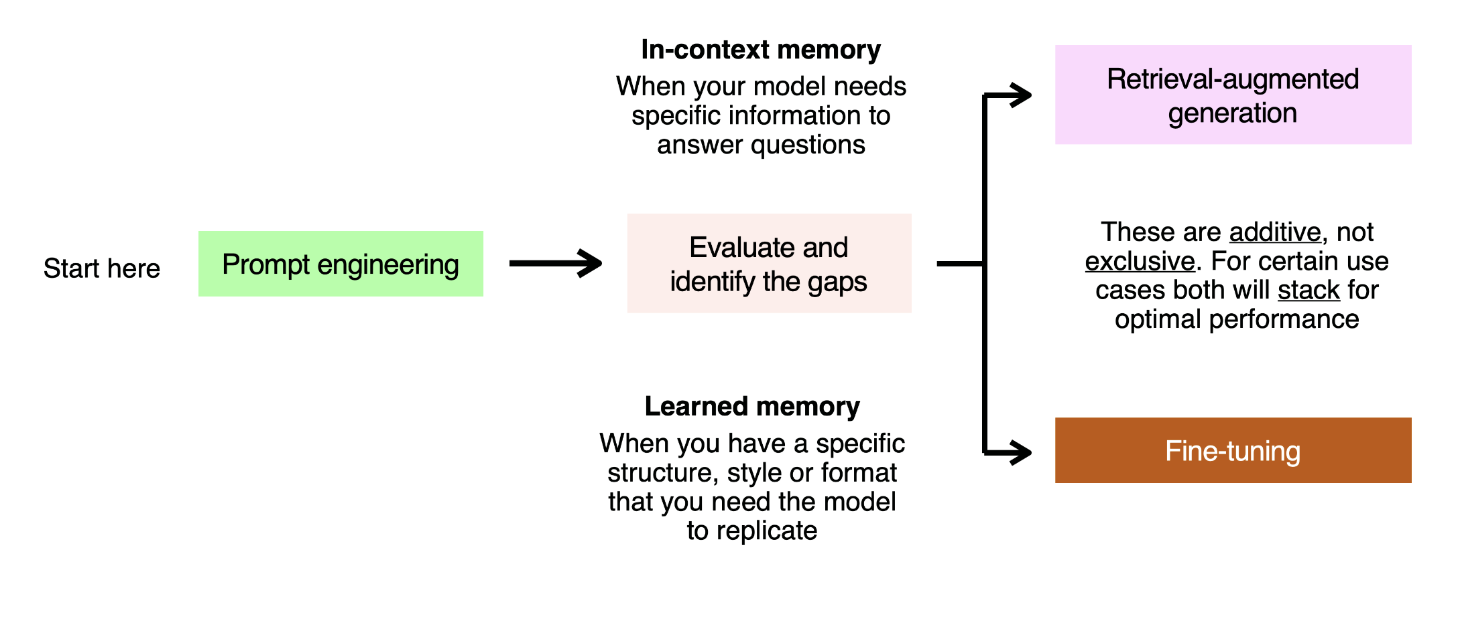
You can think of framing each failed evaluation question as an **in-context** or **learned** memory problem. As an analogy, imagine writing an exam. There are two ways you can ensure you get the right answer:
- You attend class for the last 6 months, where you see many repeated examples of how a particular concept works. This is **learned** memory - you solve this with LLMs by showing examples of the prompt and the response you expect, and the model learning from those.
- You have the textbook with you, and can look up the right information to answer the question with. This is **in-context** memory - we solve this in LLMs by stuffing relevant information into the context window, either in a static way using prompt engineering, or in an industrial way using RAG.
These two optimization methods are **additive, not exclusive** - they stack, and some use cases will require you to use them together to use optimal performance.
Let’s assume that we’re facing a short-term memory problem - for this we’ll use RAG to solve it.
### Retrieval-augmented generation (RAG)
RAG is the process of **R**etrieving content to **A**ugment your LLM’s prompt before **G**enerating an answer. It is used to give the model **access to domain-specific context** to solve a task.
RAG is an incredibly valuable tool for increasing the accuracy and consistency of an LLM - many of our largest customer deployments at OpenAI were done using only prompt engineering and RAG.
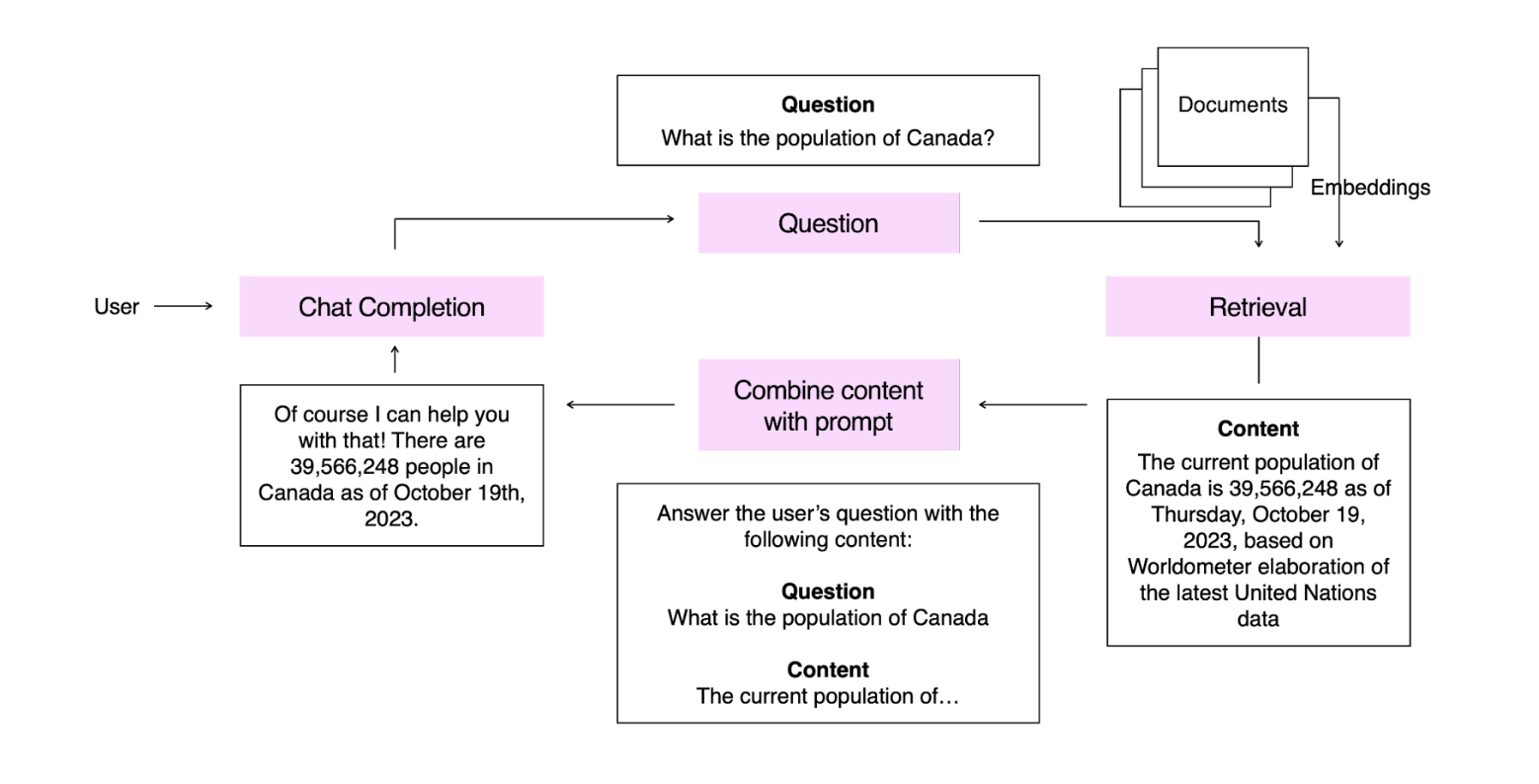
In this example we have embedded a knowledge base of statistics. When our user asks a question, we embed that question and retrieve the most relevant content from our knowledge base. This is presented to the model, which answers the question.
RAG applications introduce a new axis we need to optimize against, which is retrieval. For our RAG to work, we need to give the right context to the model, and then assess whether the model is answering correctly. I’ll frame these in a grid here to show a simple way to think about evaluation with RAG:
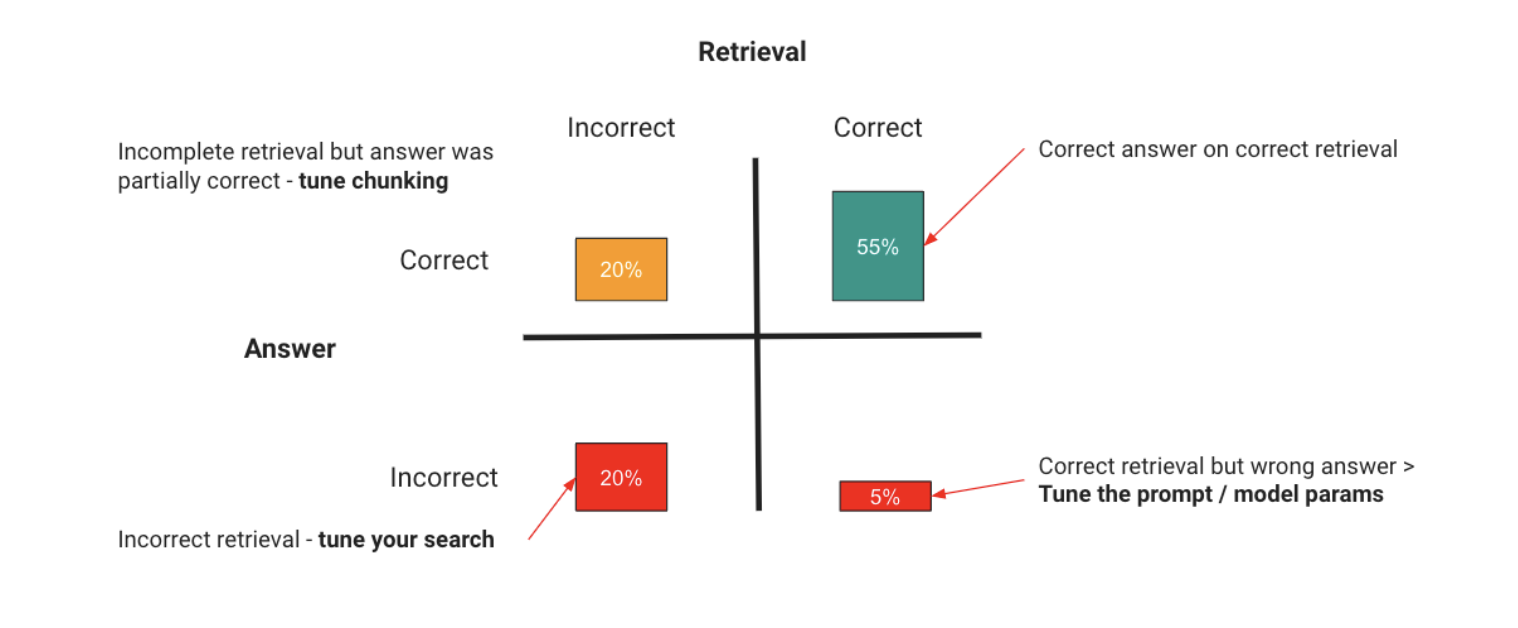
You have two areas your RAG application can break down:
| Area | Problem | Resolution |
| --------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Retrieval | You can supply the wrong context, so the model can’t possibly answer, or you can supply too much irrelevant context, which drowns out the real information and causes hallucinations. | Optimizing your retrieval, which can include:
- Tuning the search to return the right results.
- Tuning the search to include less noise.
- Providing more information in each retrieved result
These are just examples, as tuning RAG performance is an industry into itself, with libraries like LlamaIndex and LangChain giving many approaches to tuning here. |
| LLM | The model can also get the right context and do the wrong thing with it. | Prompt engineering by improving the instructions and method the model uses, and, if showing it examples increases accuracy, adding in fine-tuning |
The key thing to take away here is that the principle remains the same from our mental model at the beginning - you evaluate to find out what has gone wrong, and take an optimization step to fix it. The only difference with RAG is you now have the retrieval axis to consider.
While useful, RAG only solves our in-context learning issues - for many use cases, the issue will be ensuring the LLM can learn a task so it can perform it consistently and reliably. For this problem we turn to fine-tuning.
### Fine-tuning
To solve a learned memory problem, many developers will continue the training process of the LLM on a smaller, domain-specific dataset to optimize it for the specific task. This process is known as **fine-tuning**.
Fine-tuning is typically performed for one of two reasons:
- **To improve model accuracy on a specific task:** Training the model on task-specific data to solve a learned memory problem by showing it many examples of that task being performed correctly.
- **To improve model efficiency:** Achieve the same accuracy for less tokens or by using a smaller model.
The fine-tuning process begins by preparing a dataset of training examples - this is the most critical step, as your fine-tuning examples must exactly represent what the model will see in the real world.
Many customers use a process known as **prompt baking**, where you extensively
log your prompt inputs and outputs during a pilot. These logs can be pruned
into an effective training set with realistic examples.
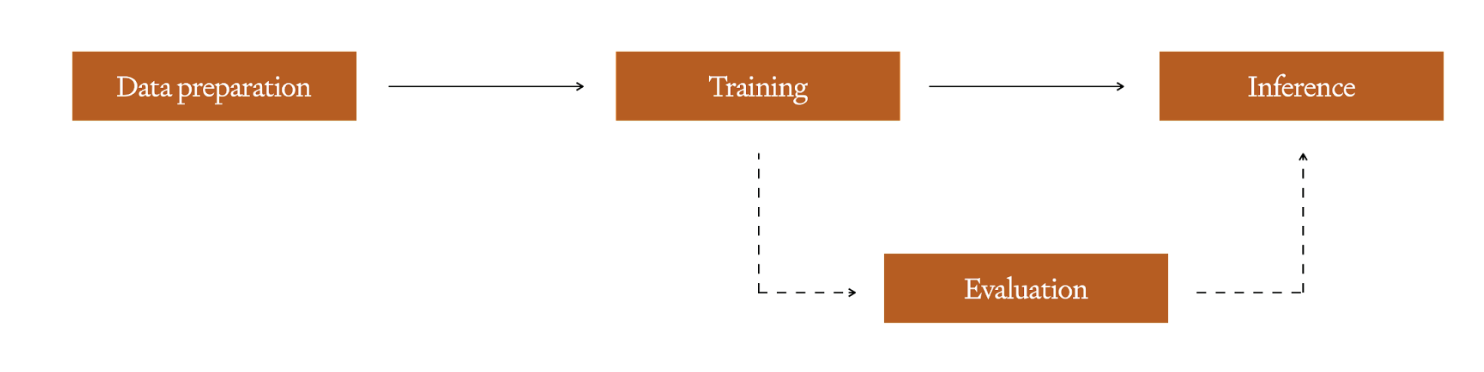
Once you have this clean set, you can train a fine-tuned model by performing a **training** run - depending on the platform or framework you’re using for training you may have hyperparameters you can tune here, similar to any other machine learning model. We always recommend maintaining a hold-out set to use for **evaluation** following training to detect overfitting. For tips on how to construct a good training set you can check out the [guidance](https://developers.openai.com/api/docs/guides/fine-tuning#analyzing-your-fine-tuned-model) in our Fine-tuning documentation. Once training is completed, the new, fine-tuned model is available for inference.
For optimizing fine-tuning we’ll focus on best practices we observe with OpenAI’s model customization offerings, but these principles should hold true with other providers and OSS offerings. The key practices to observe here are:
- **Start with prompt-engineering:** Have a solid evaluation set from prompt engineering which you can use as a baseline. This allows a low-investment approach until you’re confident in your base prompt.
- **Start small, focus on quality:** Quality of training data is more important than quantity when fine-tuning on top of a foundation model. Start with 50+ examples, evaluate, and then dial your training set size up if you haven’t yet hit your accuracy needs, and if the issues causing incorrect answers are due to consistency/behavior and not context.
- **Ensure your examples are representative:** One of the most common pitfalls we see is non-representative training data, where the examples used for fine-tuning differ subtly in formatting or form from what the LLM sees in production. For example, if you have a RAG application, fine-tune the model with RAG examples in it so it isn’t learning how to use the context zero-shot.
### All of the above
These techniques stack on top of each other - if your early evals show issues with both context and behavior, then it's likely you may end up with fine-tuning + RAG in your production solution. This is ok - these stack to balance the weaknesses of both approaches. Some of the main benefits are:
- Using fine-tuning to **minimize the tokens** used for prompt engineering, as you replace instructions and few-shot examples with many training examples to ingrain consistent behaviour in the model.
- **Teaching complex behavior** using extensive fine-tuning
- Using RAG to **inject context**, more recent content or any other specialized context required for your use cases
Using these tools to improve language translation
We’ll continue building on the Icelandic correction example we used above. We’ll test out the following approaches:
- Our original hypothesis was that this was a behavior optimization problem, so our first step will be to fine-tune a model. We’ll try both gpt-3.5-turbo and gpt-4 here.
- We’ll also try RAG - in this instance our hypothesis is that relevant examples might give additional context which could help the model solve the problem, but this is a lower confidence optimization.
#### Fine-tuning
To fine-tune for our use-case we’ll use a dataset of 1000 examples similar to our few-shot examples above:
```example-chat
# One training example
SYSTEM: The following sentences contain Icelandic sentences which may include errors. Please correct these errors using as few word changes as possible.
USER: "Hið sameinaða fyrirtæki verður einn af stærstu bílaframleiðendum í heiminum."
ASSISTANT: "Hið sameinaða fyrirtæki verður einn af stærstu bílaframleiðendum heims."
```
We use these 1000 examples to train both gpt-3.5-turbo and gpt-4 fine-tuned models, and rerun our evaluation on our validation set. This confirmed our hypothesis - we got a meaningful bump in performance with both, with even the 3.5 model outperforming few-shot gpt-4 by 8 points:
| Run | Method | Bleu Score |
| --- | ------------------------------------------- | ---------- |
| 1 | gpt-4 with zero-shot | 62 |
| 2 | gpt-4 with 3 few-shot examples | 70 |
| 3 | gpt-3.5-turbo fine-tuned with 1000 examples | 78 |
| 4 | gpt-4 fine-tuned with 1000 examples | 87 |
Great, this is starting to look like production level accuracy for our use case. However, let's test whether we can squeeze a little more performance out of our pipeline by adding some relevant RAG examples to the prompt for in-context learning.
#### RAG + Fine-tuning
Our final optimization adds 1000 examples from outside of the training and validation sets which are embedded and placed in a vector database. We then run a further test with our gpt-4 fine-tuned model, with some perhaps surprising results:
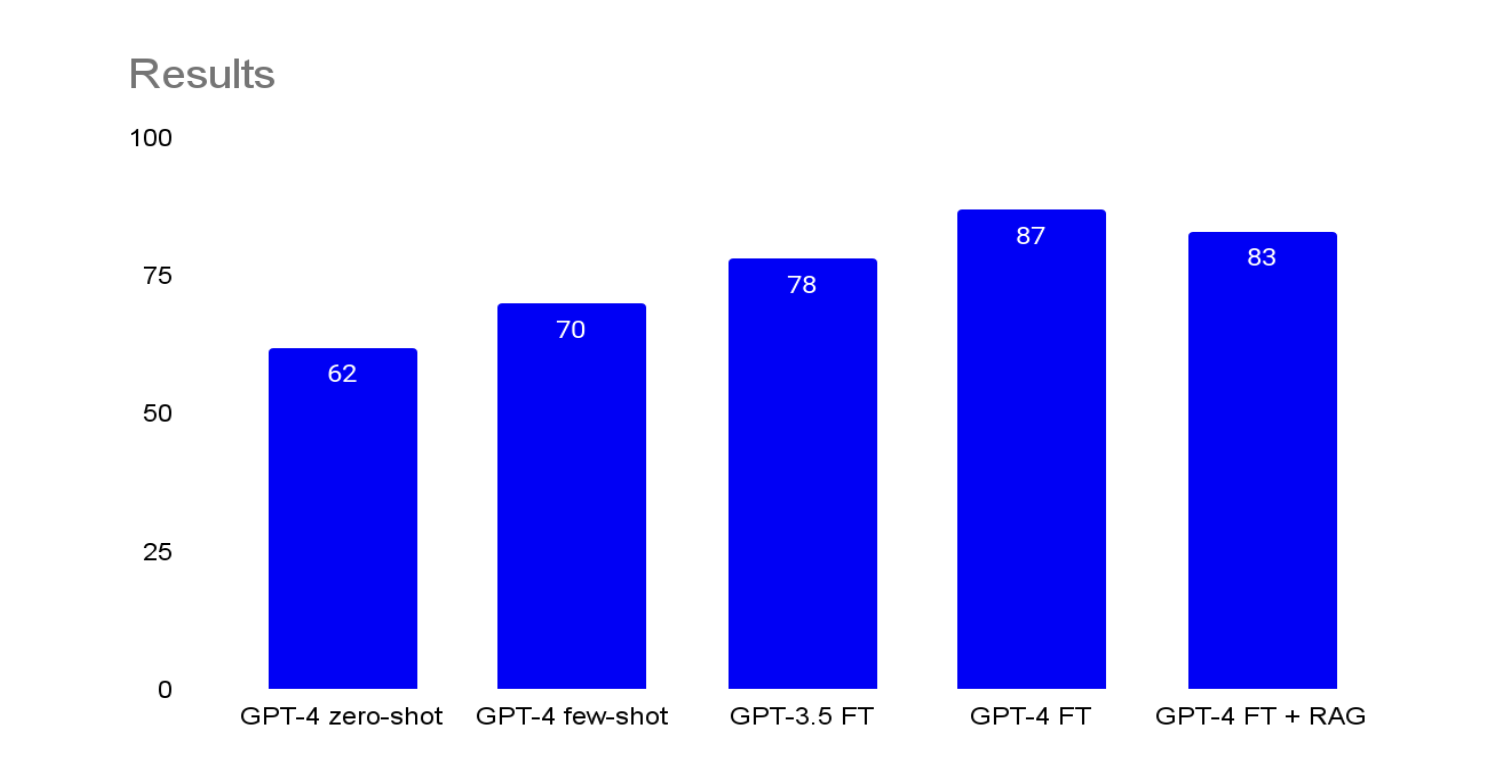
_Bleu Score per tuning method (out of 100)_
RAG actually **decreased** accuracy, dropping four points from our GPT-4 fine-tuned model to 83.
This illustrates the point that you use the right optimization tool for the right job - each offers benefits and risks that we manage with evaluations and iterative changes. The behavior we witnessed in our evals and from what we know about this question told us that this is a behavior optimization problem where additional context will not necessarily help the model. This was borne out in practice - RAG actually confounded the model by giving it extra noise when it had already learned the task effectively through fine-tuning.
We now have a model that should be close to production-ready, and if we want to optimize further we can consider a wider diversity and quantity of training examples.
Now you should have an appreciation for RAG and fine-tuning, and when each is appropriate. The last thing you should appreciate with these tools is that once you introduce them there is a trade-off here in our speed to iterate:
- For RAG you need to tune the retrieval as well as LLM behavior
- With fine-tuning you need to rerun the fine-tuning process and manage your training and validation sets when you do additional tuning.
Both of these can be time-consuming and complex processes, which can introduce regression issues as your LLM application becomes more complex. If you take away one thing from this paper, let it be to squeeze as much accuracy out of basic methods as you can before reaching for more complex RAG or fine-tuning - let your accuracy target be the objective, not jumping for RAG + FT because they are perceived as the most sophisticated.
## How much accuracy is “good enough” for production
Tuning for accuracy can be a never-ending battle with LLMs - they are unlikely to get to 99.999% accuracy using off-the-shelf methods. This section is all about deciding when is enough for accuracy - how do you get comfortable putting an LLM in production, and how do you manage the risk of the solution you put out there.
I find it helpful to think of this in both a **business** and **technical** context. I’m going to describe the high level approaches to managing both, and use a customer service help-desk use case to illustrate how we manage our risk in both cases.
### Business
For the business it can be hard to trust LLMs after the comparative certainties of rules-based or traditional machine learning systems, or indeed humans! A system where failures are open-ended and unpredictable is a difficult circle to square.
An approach I’ve seen be successful here was for a customer service use case - for this, we did the following:
First we identify the primary success and failure cases, and assign an estimated cost to them. This gives us a clear articulation of what the solution is likely to save or cost based on pilot performance.
- For example, a case getting solved by an AI where it was previously solved by a human may save $20.
- Someone getting escalated to a human when they shouldn’t might cost **$40**
- In the worst case scenario, a customer gets so frustrated with the AI they churn, costing us **$1000**. We assume this happens in 5% of cases.
| Event | Value | Number of cases | Total value |
| ----------------------- | ----- | --------------- | ----------- |
| AI success | +20 | 815 | $16,300 |
| AI failure (escalation) | -40 | 175.75 | $7,030 |
| AI failure (churn) | -1000 | 9.25 | $9,250 |
| **Result** | | | **+20** |
| **Break-even accuracy** | | | **81.5%** |
The other thing we did is to measure the empirical stats around the process which will help us measure the macro impact of the solution. Again using customer service, these could be:
- The CSAT score for purely human interactions vs. AI ones
- The decision accuracy for retrospectively reviewed cases for human vs. AI
- The time to resolution for human vs. AI
In the customer service example, this helped us make two key decisions following a few pilots to get clear data:
1. Even if our LLM solution escalated to humans more than we wanted, it still made an enormous operational cost saving over the existing solution. This meant that an accuracy of even 85% could be ok, if those 15% were primarily early escalations.
2. Where the cost of failure was very high, such as a fraud case being incorrectly resolved, we decided the human would drive and the AI would function as an assistant. In this case, the decision accuracy stat helped us make the call that we weren’t comfortable with full autonomy.
### Technical
On the technical side it is more clear - now that the business is clear on the value they expect and the cost of what can go wrong, your role is to build a solution that handles failures gracefully in a way that doesn’t disrupt the user experience.
Let’s use the customer service example one more time to illustrate this, and we’ll assume we’ve got a model that is 85% accurate in determining intent. As a technical team, here are a few ways we can minimize the impact of the incorrect 15%:
- We can prompt engineer the model to prompt the customer for more information if it isn’t confident, so our first-time accuracy may drop but we may be more accurate given 2 shots to determine intent.
- We can give the second-line assistant the option to pass back to the intent determination stage, again giving the UX a way of self-healing at the cost of some additional user latency.
- We can prompt engineer the model to hand off to a human if the intent is unclear, which costs us some operational savings in the short-term but may offset customer churn risk in the long term.
Those decisions then feed into our UX, which gets slower at the cost of higher accuracy, or more human interventions, which feed into the cost model covered in the business section above.
You now have an approach to breaking down the business and technical decisions involved in setting an accuracy target that is grounded in business reality.
## Taking this forward
This is a high level mental model for thinking about maximizing accuracy for LLMs, the tools you can use to achieve it, and the approach for deciding where enough is enough for production. You have the framework and tools you need to get to production consistently, and if you want to be inspired by what others have achieved with these methods then look no further than our customer stories, where use cases like [Morgan Stanley](https://openai.com/customer-stories/morgan-stanley) and [Klarna](https://openai.com/customer-stories/klarna) show what you can achieve by leveraging these techniques.
Best of luck, and we’re excited to see what you build with this!
---
# Orchestration and handoffs
Multi-agent workflows are useful when specialists should own different parts of the job. The first design choice is deciding who owns the final user-facing answer at each branch of the workflow.
## Choose the orchestration pattern
| Pattern | Use it when | What happens |
| --------------- | ----------------------------------------------------------------------------- | ---------------------------------------- |
| Handoffs | A specialist should take over the conversation for that branch of the work | Control moves to the specialist agent |
| Agents as tools | A manager should stay in control and call specialists as bounded capabilities | The manager keeps ownership of the reply |
## Use handoffs for delegated ownership
Handoffs are the clearest fit when a specialist should own the next response rather than merely helping behind the scenes.
Delegate with handoffs
```typescript
import { Agent, handoff } from "@openai/agents";
const billingAgent = new Agent({ name: "Billing agent" });
const refundAgent = new Agent({ name: "Refund agent" });
const triageAgent = Agent.create({
name: "Triage agent",
handoffs: [billingAgent, handoff(refundAgent)],
});
```
```python
from agents import Agent, handoff
billing_agent = Agent(name="Billing agent")
refund_agent = Agent(name="Refund agent")
triage_agent = Agent(
name="Triage agent",
handoffs=[billing_agent, handoff(refund_agent)],
)
```
Keep the routing surface legible:
- Give each specialist a narrow job.
- Keep short and concrete.
- Split only when the next branch truly needs different instructions, tools, or policy.
At the advanced end, handoffs can also carry structured metadata or filtered history. Those exact APIs stay in the SDK docs because the wiring differs by language.
## Use agents as tools for manager-style workflows
Use when the main agent should stay responsible for the final answer and call specialists as helpers.
Call a specialist as a tool
```typescript
import { Agent } from "@openai/agents";
const summarizer = new Agent({
name: "Summarizer",
instructions: "Generate a concise summary of the supplied text.",
});
const mainAgent = new Agent({
name: "Research assistant",
tools: [
summarizer.asTool({
toolName: "summarize_text",
toolDescription: "Generate a concise summary of the supplied text.",
}),
],
});
```
```python
from agents import Agent
summarizer = Agent(
name="Summarizer",
instructions="Generate a concise summary of the supplied text.",
)
main_agent = Agent(
name="Research assistant",
tools=[
summarizer.as_tool(
tool_name="summarize_text",
tool_description="Generate a concise summary of the supplied text.",
)
],
)
```
This is usually the better fit when:
- the manager should synthesize the final answer
- the specialist is doing a bounded task like summarization or classification
- you want one stable outer workflow with nested specialist calls instead of ownership transfer
## Add specialists only when the contract changes
Start with one agent whenever you can. Add specialists only when they materially improve capability isolation, policy isolation, prompt clarity, or trace legibility.
Splitting too early creates more prompts, more traces, and more approval surfaces without necessarily making the workflow better.
## Next steps
Once the ownership pattern is clear, continue with the guide that covers the adjacent runtime or state question.
---
# Predicted Outputs
**Predicted Outputs** enable you to speed up API responses from [Chat Completions](https://developers.openai.com/api/docs/api-reference/chat/create) when many of the output tokens are known ahead of time. This is most common when you are regenerating a text or code file with minor modifications. You can provide your prediction using the [`prediction` request parameter in Chat Completions](https://developers.openai.com/api/docs/api-reference/chat/create#chat-create-prediction).
Predicted Outputs are available today using the latest `gpt-4o`, `gpt-4o-mini`, `gpt-4.1`, `gpt-4.1-mini`, and `gpt-4.1-nano` models. Read on to learn how to use Predicted Outputs to reduce latency in your applications.
## Code refactoring example
Predicted Outputs are particularly useful for regenerating text documents and code files with small modifications. Let's say you want the [GPT-4o model](https://developers.openai.com/api/docs/models#gpt-4o) to refactor a piece of TypeScript code, and convert the `username` property of the `User` class to be `email` instead:
```typescript
class User {
firstName: string = "";
lastName: string = "";
username: string = "";
}
export default User;
```
Most of the file will be unchanged, except for line 4 above. If you use the current text of the code file as your prediction, you can regenerate the entire file with lower latency. These time savings add up quickly for larger files.
Below is an example of using the `prediction` parameter in our SDKs to predict that the final output of the model will be very similar to our original code file, which we use as the prediction text.
Refactor a TypeScript class with a Predicted Output
```javascript
import OpenAI from "openai";
const code = \`
class User {
firstName: string = "";
lastName: string = "";
username: string = "";
}
export default User;
\`.trim();
const openai = new OpenAI();
const refactorPrompt = \`
Replace the "username" property with an "email" property. Respond only
with code, and with no markdown formatting.
\`;
const completion = await openai.chat.completions.create({
model: "gpt-4.1",
messages: [
{
role: "user",
content: refactorPrompt
},
{
role: "user",
content: code
}
],
store: true,
prediction: {
type: "content",
content: code
}
});
// Inspect returned data
console.log(completion);
console.log(completion.choices[0].message.content);
```
```python
from openai import OpenAI
code = """
class User {
firstName: string = "";
lastName: string = "";
username: string = "";
}
export default User;
"""
refactor_prompt = """
Replace the "username" property with an "email" property. Respond only
with code, and with no markdown formatting.
"""
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4.1",
messages=[
{
"role": "user",
"content": refactor_prompt
},
{
"role": "user",
"content": code
}
],
prediction={
"type": "content",
"content": code
}
)
print(completion)
print(completion.choices[0].message.content)
```
```bash
curl https://api.openai.com/v1/chat/completions \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-4.1",
"messages": [
{
"role": "user",
"content": "Replace the username property with an email property. Respond only with code, and with no markdown formatting."
},
{
"role": "user",
"content": "$CODE_CONTENT_HERE"
}
],
"prediction": {
"type": "content",
"content": "$CODE_CONTENT_HERE"
}
}'
```
In addition to the refactored code, the model response will contain data that looks something like this:
```javascript
{
id: 'chatcmpl-xxx',
object: 'chat.completion',
created: 1730918466,
model: 'gpt-4o-2024-08-06',
choices: [ /* ...actual text response here... */],
usage: {
prompt_tokens: 81,
completion_tokens: 39,
total_tokens: 120,
prompt_tokens_details: { cached_tokens: 0, audio_tokens: 0 },
completion_tokens_details: {
reasoning_tokens: 0,
audio_tokens: 0,
accepted_prediction_tokens: 18,
rejected_prediction_tokens: 10
}
},
system_fingerprint: 'fp_159d8341cc'
}
```
Note both the `accepted_prediction_tokens` and `rejected_prediction_tokens` in the `usage` object. In this example, 18 tokens from the prediction were used to speed up the response, while 10 were rejected.
Note that any rejected tokens are still billed like other completion tokens
generated by the API, so Predicted Outputs can introduce higher costs for your
requests.
## Streaming example
The latency gains of Predicted Outputs are even greater when you use streaming for API responses. Here is an example of the same code refactoring use case, but using streaming in the OpenAI SDKs instead.
Predicted Outputs with streaming
```javascript
import OpenAI from "openai";
const code = \`
class User {
firstName: string = "";
lastName: string = "";
username: string = "";
}
export default User;
\`.trim();
const openai = new OpenAI();
const refactorPrompt = \`
Replace the "username" property with an "email" property. Respond only
with code, and with no markdown formatting.
\`;
const completion = await openai.chat.completions.create({
model: "gpt-4.1",
messages: [
{
role: "user",
content: refactorPrompt
},
{
role: "user",
content: code
}
],
store: true,
prediction: {
type: "content",
content: code
},
stream: true
});
// Inspect returned data
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0]?.delta?.content || "");
}
```
```python
from openai import OpenAI
code = """
class User {
firstName: string = "";
lastName: string = "";
username: string = "";
}
export default User;
"""
refactor_prompt = """
Replace the "username" property with an "email" property. Respond only
with code, and with no markdown formatting.
"""
client = OpenAI()
stream = client.chat.completions.create(
model="gpt-4.1",
messages=[
{
"role": "user",
"content": refactor_prompt
},
{
"role": "user",
"content": code
}
],
prediction={
"type": "content",
"content": code
},
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
```
## Position of predicted text in response
When providing prediction text, your prediction can appear anywhere within the generated response, and still provide latency reduction for the response. Let's say your predicted text is the simple [Hono](https://hono.dev/) server shown below:
```typescript
const app = new Hono();
app.get("/api", (c) => {
return c.text("Hello Hono!");
});
// You will need to build the client code first `pnpm run ui:build`
app.use(
"/*",
serveStatic({
rewriteRequestPath: (path) => `./dist${path}`,
})
);
const port = 3000;
console.log(`Server is running on port ${port}`);
serve({
fetch: app.fetch,
port,
});
```
You could prompt the model to regenerate the file with a prompt like:
```
Add a get route to this application that responds with
the text "hello world". Generate the entire application
file again with this route added, and with no other
markdown formatting.
```
The response to the prompt might look something like this:
```typescript
const app = new Hono();
app.get("/api", (c) => {
return c.text("Hello Hono!");
});
app.get("/hello", (c) => {
return c.text("hello world");
});
// You will need to build the client code first `pnpm run ui:build`
app.use(
"/*",
serveStatic({
rewriteRequestPath: (path) => `./dist${path}`,
})
);
const port = 3000;
console.log(`Server is running on port ${port}`);
serve({
fetch: app.fetch,
port,
});
```
You would still see accepted prediction tokens in the response, even though the prediction text appeared both before and after the new content added to the response:
```javascript
{
id: 'chatcmpl-xxx',
object: 'chat.completion',
created: 1731014771,
model: 'gpt-4o-2024-08-06',
choices: [ /* completion here... */],
usage: {
prompt_tokens: 203,
completion_tokens: 159,
total_tokens: 362,
prompt_tokens_details: { cached_tokens: 0, audio_tokens: 0 },
completion_tokens_details: {
reasoning_tokens: 0,
audio_tokens: 0,
accepted_prediction_tokens: 60,
rejected_prediction_tokens: 0
}
},
system_fingerprint: 'fp_9ee9e968ea'
}
```
This time, there were no rejected prediction tokens, because the entire content of the file we predicted was used in the final response. Nice! 🔥
## Limitations
When using Predicted Outputs, you should consider the following factors and limitations.
- Predicted Outputs are only supported with the GPT-4o, GPT-4o-mini, GPT-4.1, GPT-4.1-mini, and GPT-4.1-nano series of models.
- When providing a prediction, any tokens provided that are not part of the final completion are still charged at completion token rates. See the [`rejected_prediction_tokens` property of the `usage` object](https://developers.openai.com/api/docs/api-reference/chat/object#chat/object-usage) to see how many tokens are not used in the final response.
- The following [API parameters](https://developers.openai.com/api/docs/api-reference/chat/create) are not supported when using Predicted Outputs:
- `n`: values higher than 1 are not supported
- `logprobs`: not supported
- `presence_penalty`: values greater than 0 are not supported
- `frequency_penalty`: values greater than 0 are not supported
- `audio`: Predicted Outputs are not compatible with [audio inputs and outputs](https://developers.openai.com/api/docs/guides/audio)
- `modalities`: Only `text` modalities are supported
- `max_completion_tokens`: not supported
- `tools`: Function calling is not currently supported with Predicted Outputs
---
# Priority processing
Priority processing delivers significantly lower and more consistent latency compared to Standard processing while keeping pay-as-you-go flexibility.
Priority processing is ideal for high-value, user-facing applications with regular traffic where latency is paramount. Priority processing should not be used for data processing, evaluations, or other highly erratic traffic.
## Configuring Priority processing
Requests to the Responses or Completions endpoints can be configured to use Priority processing through either a request parameter, or a Project setting.
To opt-in to Priority processing at the request level, include the [`service_tier=priority`](https://platform.openai.com/docs/api-reference/responses/create#responses-create-service_tier) parameter for Completions or Responses.
Create a response with priority processing
```bash
curl https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5",
"input": "What does 'fit check for my napalm era' mean?",
"service_tier": "priority"
}'
```
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5",
input: "What does 'fit check for my napalm era' mean?",
service_tier: "priority"
});
console.log(response);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
input="What does 'fit check for my napalm era' mean?",
service_tier="priority"
)
print(response)
```
To opt in at the Project level, navigate to the Settings page, select the General tab under Project, then change the Project Service Tier to Priority. Once configured on the project, requests that don't specify a `service_tier` will default to Priority. Note that requests for the project will be gradually transitioned to Priority over time.
The `service_tier` field in the [Responses](https://platform.openai.com/docs/api-reference/responses/object#responses/object-service_tier) or [Completions](https://platform.openai.com/docs/api-reference/chat/object#chat/object-service_tier) response objects will contain which service tier was used to process the request.
## Rate limits and ramp rate
**Baseline limits**
Priority consumption is treated like Standard for rate‑limit accounting. Use your usual retry and backoff logic. For a given model, the rate limit is shared between Standard and Priority processing.
**Ramp rate limit**
If your traffic ramps too quickly, some Priority requests may be downgraded to Standard and billed at Standard rates. If the ramp rate limit is exceeded, the response will show service_tier="default". Currently, the ramp rate limit may apply if you’re sending at least 1 million TPM and >50% TPM increase within 15 minutes.
To avoid triggering the ramp rate limit, we recommend:
- Ramp gradually when changing models or snapshots
- Use feature flags to shift traffic over hours, not instantly.
- Avoid large ETL or batch jobs on Priority
## Usage considerations
- Per token costs are billed at a premium to standard - see [pricing](https://developers.openai.com/api/docs/pricing) for more information.
- Cache discounts are still applied for priority processing requests.
- Priority processing applies for multimodal / image input requests as well.
- Requests handled with priority processing can be viewed in the dashboard using the "group by service tier" option.
- See the [pricing page](https://developers.openai.com/api/docs/pricing) for which models currently support Priority processing.
- Long context, fine-tuned models and embeddings are not yet supported.
---
# Production best practices
This guide provides a comprehensive set of best practices to help you transition from prototype to production. Whether you are a seasoned machine learning engineer or a recent enthusiast, this guide should provide you with the tools you need to successfully put the platform to work in a production setting: from securing access to our API to designing a robust architecture that can handle high traffic volumes. Use this guide to help develop a plan for deploying your application as smoothly and effectively as possible.
If you want to explore best practices for going into production further, please check out our Developer Day talk:
## Setting up your organization
Once you [log in](https://platform.openai.com/login) to your OpenAI account, you can find your organization name and ID in your [organization settings](https://platform.openai.com/settings/organization/general). The organization name is the label for your organization, shown in user interfaces. The organization ID is the unique identifier for your organization which can be used in API requests.
Users who belong to multiple organizations can [pass a header](https://developers.openai.com/api/docs/api-reference/requesting-organization) to specify which organization is used for an API request. Usage from these API requests will count against the specified organization's quota. If no header is provided, the [default organization](https://platform.openai.com/settings/organization/api-keys) will be billed. You can change your default organization in your [user settings](https://platform.openai.com/settings/organization/api-keys).
You can invite new members to your organization from the [Team page](https://platform.openai.com/settings/organization/team). Members can be **readers** or **owners**.
Readers:
- Can make API requests.
- Can view basic organization information.
- Can create, update, and delete resources (like Assistants) in the organization, unless otherwise noted.
Owners:
- Have all the permissions of readers.
- Can modify billing information.
- Can manage members within the organization.
### Managing billing limits
Once you’ve entered your billing information, you will have an approved usage limit of $100 per month, which is set by OpenAI. Your quota limit will automatically increase as your usage on your platform increases and you move from one [usage tier](https://developers.openai.com/api/docs/guides/rate-limits#usage-tiers) to another. You can review your current usage limit in the [limits](https://platform.openai.com/settings/organization/limits) page in your account settings.
If you’d like to be notified when your usage exceeds a certain dollar amount, you can set a notification threshold through the [usage limits](https://platform.openai.com/settings/organization/limits) page.
### API keys
The OpenAI API uses API keys for authentication. Visit your [API keys](https://platform.openai.com/settings/organization/api-keys) page to retrieve the API key you'll use in your requests.
This is a relatively straightforward way to control access, but you must be vigilant about securing these keys. Avoid exposing the API keys in your code or in public repositories; instead, store them in a secure location. You should expose your keys to your application using environment variables or secret management service, so that you don't need to hard-code them in your codebase. Read more in our [Best practices for API key safety](https://help.openai.com/en/articles/5112595-best-practices-for-api-key-safety).
API key usage can be monitored on the [Usage page](https://platform.openai.com/usage) once tracking is enabled. If you are using an API key generated prior to Dec 20, 2023 tracking will not be enabled by default. You can enable tracking going forward on the [API key management dashboard](https://platform.openai.com/api-keys). All API keys generated past Dec 20, 2023 have tracking enabled. Any previous untracked usage will be displayed as `Untracked` in the dashboard.
### Staging projects
As you scale, you may want to create separate projects for your staging and production environments. You can create these projects in the dashboard, allowing you to isolate your development and testing work, so you don't accidentally disrupt your live application. You can also limit user access to your production project, and set custom rate and spend limits per project.
## Scaling your solution architecture
When designing your application or service for production that uses our API, it's important to consider how you will scale to meet traffic demands. There are a few key areas you will need to consider regardless of the cloud service provider of your choice:
- **Horizontal scaling**: You may want to scale your application out horizontally to accommodate requests to your application that come from multiple sources. This could involve deploying additional servers or containers to distribute the load. If you opt for this type of scaling, make sure that your architecture is designed to handle multiple nodes and that you have mechanisms in place to balance the load between them.
- **Vertical scaling**: Another option is to scale your application up vertically, meaning you can beef up the resources available to a single node. This would involve upgrading your server's capabilities to handle the additional load. If you opt for this type of scaling, make sure your application is designed to take advantage of these additional resources.
- **Caching**: By storing frequently accessed data, you can improve response times without needing to make repeated calls to our API. Your application will need to be designed to use cached data whenever possible and invalidate the cache when new information is added. There are a few different ways you could do this. For example, you could store data in a database, filesystem, or in-memory cache, depending on what makes the most sense for your application.
- **Load balancing**: Finally, consider load-balancing techniques to ensure requests are distributed evenly across your available servers. This could involve using a load balancer in front of your servers or using DNS round-robin. Balancing the load will help improve performance and reduce bottlenecks.
### Managing rate limits
When using our API, it's important to understand and plan for [rate limits](https://developers.openai.com/api/docs/guides/rate-limits).
## Improving latencies
Check out our most up-to-date guide on [latency
optimization](https://developers.openai.com/api/docs/guides/latency-optimization).
Latency is the time it takes for a request to be processed and a response to be returned. In this section, we will discuss some factors that influence the latency of our text generation models and provide suggestions on how to reduce it.
The latency of a completion request is mostly influenced by two factors: the model and the number of tokens generated. The life cycle of a completion request looks like this:
The bulk of the latency typically arises from the token generation step.
> **Intuition**: Prompt tokens add very little latency to completion calls. Time to generate completion tokens is much longer, as tokens are generated one at a time. Longer generation lengths will accumulate latency due to generation required for each token.
### Common factors affecting latency and possible mitigation techniques
Now that we have looked at the basics of latency, let’s take a look at various factors that can affect latency, broadly ordered from most impactful to least impactful.
#### Model
Our API offers different models with varying levels of complexity and generality. The most capable models, such as `gpt-5`, can generate more complex and diverse completions, but they also take longer to process your query.
Models such as `gpt-5.4-mini` and `gpt-5.4-nano` can generate faster and cheaper Responses, while `gpt-5.5` is a stronger default when you want more headroom on complex tasks. You can choose the model that best suits your use case and the trade-off between speed, cost, and quality.
#### Number of completion tokens
Requesting a large amount of generated tokens completions can lead to increased latencies:
- **Lower max tokens**: for requests with a similar token generation count, those that have a lower `max_tokens` parameter incur less latency.
- **Include stop sequences**: to prevent generating unneeded tokens, add a stop sequence. For example, you can use stop sequences to generate a list with a specific number of items. In this case, by using `11.` as a stop sequence, you can generate a list with only 10 items, since the completion will stop when `11.` is reached. [Read our help article on stop sequences](https://help.openai.com/en/articles/5072263-how-do-i-use-stop-sequences) for more context on how you can do this.
- **Generate fewer completions**: lower the values of `n` and `best_of` when possible where `n` refers to how many completions to generate for each prompt and `best_of` is used to represent the result with the highest log probability per token.
If `n` and `best_of` both equal 1 (which is the default), the number of generated tokens will be at most, equal to `max_tokens`.
If `n` (the number of completions returned) or `best_of` (the number of completions generated for consideration) are set to `> 1`, each request will create multiple outputs. Here, you can consider the number of generated tokens as `[ max_tokens * max (n, best_of) ]`
#### Streaming
Setting `stream: true` in a request makes the model start returning tokens as soon as they are available, instead of waiting for the full sequence of tokens to be generated. It does not change the time to get all the tokens, but it reduces the time for first token for an application where we want to show partial progress or are going to stop generations. This can be a better user experience and a UX improvement so it’s worth experimenting with streaming.
#### Batching
Depending on your use case, batching may help. If you are sending multiple requests to the same endpoint, you can [batch the prompts](https://developers.openai.com/api/docs/guides/rate-limits#batching-requests) to be sent in the same request. This will reduce the number of requests you need to make. The prompt parameter can hold up to 20 unique prompts. We advise you to test out this method and see if it helps. In some cases, you may end up increasing the number of generated tokens which will slow the response time.
## Managing costs
To monitor your costs, you can set a [notification threshold](https://platform.openai.com/settings/organization/limits) in your account to receive an email alert once you pass a certain usage threshold. Use the [usage tracking dashboard](https://platform.openai.com/settings/organization/usage) to monitor your token usage during the current and past billing cycles.
### Text generation
One of the challenges of moving your prototype into production is budgeting for the costs associated with running your application. OpenAI offers a [pay-as-you-go pricing model](https://openai.com/api/pricing/), with prices per 1,000 tokens (roughly equal to 750 words). To estimate your costs, you will need to project the token utilization. Consider factors such as traffic levels, the frequency with which users will interact with your application, and the amount of data you will be processing.
**One useful framework for thinking about reducing costs is to consider costs as a function of the number of tokens and the cost per token.** There are two potential avenues for reducing costs using this framework. First, you could work to reduce the cost per token by switching to smaller models for some tasks in order to reduce costs. Alternatively, you could try to reduce the number of tokens required. There are a few ways you could do this, such as by using shorter prompts, [fine-tuning](https://developers.openai.com/api/docs/guides/model-optimization) models, or caching common user queries so that they don't need to be processed repeatedly.
You can experiment with our interactive [tokenizer tool](https://platform.openai.com/tokenizer) to help you estimate costs. The API and playground also returns token counts as part of the response. Once you’ve got things working with our most capable model, you can see if the other models can produce the same results with lower latency and costs. Learn more in our [token usage help article](https://help.openai.com/en/articles/6614209-how-do-i-check-my-token-usage).
## MLOps strategy
As you move your prototype into production, you may want to consider developing an MLOps strategy. MLOps (machine learning operations) refers to the process of managing the end-to-end life cycle of your machine learning models, including any models you may be fine-tuning using our API. There are a number of areas to consider when designing your MLOps strategy. These include
- Data and model management: managing the data used to train or fine-tune your model and tracking versions and changes.
- Model monitoring: tracking your model's performance over time and detecting any potential issues or degradation.
- Model retraining: ensuring your model stays up to date with changes in data or evolving requirements and retraining or fine-tuning it as needed.
- Model deployment: automating the process of deploying your model and related artifacts into production.
Thinking through these aspects of your application will help ensure your model stays relevant and performs well over time.
## Security and compliance
As you move your prototype into production, you will need to assess and address any security and compliance requirements that may apply to your application. This will involve examining the data you are handling, understanding how our API processes data, and determining what regulations you must adhere to. Our [security practices](https://www.openai.com/security) and [trust and compliance portal](https://trust.openai.com/) provide our most comprehensive and up-to-date documentation. For reference, here is our [Privacy Policy](https://openai.com/privacy/) and [Terms of Use](https://openai.com/api/policies/terms/).
Some common areas you'll need to consider include data storage, data transmission, and data retention. You might also need to implement data privacy protections, such as encryption or anonymization where possible. In addition, you should follow best practices for secure coding, such as input sanitization and proper error handling.
### Safety best practices
When creating your application with our API, consider our [safety best practices](https://developers.openai.com/api/docs/guides/safety-best-practices) to ensure your application is safe and successful. These recommendations highlight the importance of testing the product extensively, being proactive about addressing potential issues, and limiting opportunities for misuse.
## Business considerations
As projects using AI move from prototype to production, it is important to consider how to build a great product with AI and how that ties back to your core business. We certainly don't have all the answers but a great starting place is a talk from our Developer Day where we dive into this with some of our customers:
---
# Prompt caching
Model prompts often contain repetitive content, like system prompts and common instructions. OpenAI routes API requests to servers that recently processed the same prompt, making it cheaper and faster than processing a prompt from scratch. Prompt Caching can reduce latency by up to 80% and input token costs by up to 90%. Prompt Caching works automatically on all your API requests (no code changes required) and has no additional fees associated with it. Prompt Caching is enabled for all recent [models](https://developers.openai.com/api/docs/models), gpt-4o and newer.
This guide describes how Prompt Caching works in detail, so that you can optimize your prompts for lower latency and cost.
## Structuring prompts
Cache hits are only possible for exact prefix matches within a prompt. To realize caching benefits, place static content like instructions and examples at the beginning of your prompt, and put variable content, such as user-specific information, at the end. This also applies to images and tools, which must be identical between requests.

## How it works
Caching is enabled automatically for prompts that are 1024 tokens or longer. When you make an API request, the following steps occur:
1. **Cache Routing**:
- Requests are routed to a machine based on a hash of the initial prefix of the prompt. The hash typically uses the first 256 tokens, though the exact length varies depending on the model.
- If you provide the [`prompt_cache_key`](https://developers.openai.com/api/docs/api-reference/responses/create#responses-create-prompt_cache_key) parameter, it is combined with the prefix hash, allowing you to influence routing and improve cache hit rates. This is especially beneficial when many requests share long, common prefixes.
- If requests for the same prefix and `prompt_cache_key` combination exceed a certain rate (approximately 15 requests per minute), some may overflow and get routed to additional machines, reducing cache effectiveness.
2. **Cache Lookup**: The system checks if the initial portion (prefix) of your prompt exists in the cache on the selected machine.
3. **Cache Hit**: If a matching prefix is found, the system uses the cached result. This significantly decreases latency and reduces costs.
4. **Cache Miss**: If no matching prefix is found, the system processes your full prompt, caching the prefix afterward on that machine for future requests.
## Prompt cache retention
Prompt Caching can either use in-memory or extended retention policies. When available, Extended Prompt Caching aims to retain the cache for longer, so that subsequent requests are more likely to match the cache.
Prompt cache pricing is the same for both retention policies.
To configure the prompt cache retention policy, set the `prompt_cache_retention` parameter on your `Responses.create` request (or `chat.completions.create` if using Chat Completions).
### In-memory prompt cache retention
In-memory prompt cache retention is available for all models that support Prompt Caching, except for `gpt-5.5`, `gpt-5.5-pro`, and all future models.
When using the in-memory policy, cached prefixes generally remain active for 5 to 10 minutes of inactivity, up to a maximum of one hour. In-memory cached prefixes are only held within volatile GPU memory.
### Extended prompt cache retention
Extended prompt cache retention is available for the following models:
- gpt-5.5
- gpt-5.5-pro
- gpt-5.4
- gpt-5.2
- gpt-5.1-codex-max
- gpt-5.1
- gpt-5.1-codex
- gpt-5.1-codex-mini
- gpt-5.1-chat-latest
- gpt-5
- gpt-5-codex
- gpt-4.1
Extended prompt cache retention keeps cached prefixes active for longer, up to a maximum of 24 hours. Extended Prompt Caching works by offloading the key/value tensors to GPU-local storage when memory is full, significantly increasing the storage capacity available for caching.
key/value tensors are the intermediate representation from the model's attention layers produced during prefill. Only the key/value tensors may be persisted in local storage; the original customer content, such as prompt text, is only retained in memory.
### Configure per request
If you don’t specify a retention policy, for most models the default is `in_memory`. For `gpt-5.5`, `gpt-5.5-pro`, and all future models, the default is `24h` and `in_memory` is not supported. Allowed values are `in_memory` and `24h`.
```json
{
"model": "gpt-5.5",
"input": "Your prompt goes here...",
"prompt_cache_retention": "24h"
}
```
## Requirements
Caching is available for prompts containing 1024 tokens or more.
All requests, including those with fewer than 1024 tokens, will display a `cached_tokens` field of the `usage.prompt_tokens_details` [Response object](https://developers.openai.com/api/docs/api-reference/responses/object) or [Chat object](https://developers.openai.com/api/docs/api-reference/chat/object) indicating how many of the prompt tokens were a cache hit. For requests under 1024 tokens, `cached_tokens` will be zero.
```json
"usage": {
"prompt_tokens": 2006,
"completion_tokens": 300,
"total_tokens": 2306,
"prompt_tokens_details": {
"cached_tokens": 1920
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
```
### What can be cached
- **Messages:** The complete messages array, encompassing system, user, and assistant interactions.
- **Images:** Images included in user messages, either as links or as base64-encoded data, as well as multiple images can be sent. Ensure the detail parameter is set identically, as it impacts image tokenization.
- **Tool use:** Both the messages array and the list of available `tools` can be cached, contributing to the minimum 1024 token requirement.
- **Structured outputs:** The structured output schema serves as a prefix to the system message and can be cached.
## Best practices
- Structure prompts with **static or repeated content at the beginning** and dynamic, user-specific content at the end.
- Use the **[`prompt_cache_key`](https://developers.openai.com/api/docs/api-reference/responses/create#responses-create-prompt_cache_key) parameter** consistently across requests that share common prefixes. Select a granularity that keeps each unique prefix-`prompt_cache_key` combination below 15 requests per minute to avoid cache overflow.
- **Monitor your cache performance metrics**, including cache hit rates, latency, and the proportion of tokens cached, to refine your strategy. You can monitor your cached token counts by logging the usage field results as shown above, or in the OpenAI Usage dashboard.
- **Maintain a steady stream of requests** with identical prompt prefixes to minimize cache evictions and maximize caching benefits.
## Frequently asked questions
1. **How is data privacy maintained for caches?**
Prompt caches are not shared between organizations. Only members of the same organization can access caches of identical prompts. When using Extended Prompt Caching, key/value tensors have a maximum retention period of 24 hours.
2. **Does Prompt Caching affect output token generation or the final response of the API?**
Prompt Caching does not influence the generation of output tokens or the final response provided by the API. Regardless of whether caching is used, the output generated will be identical. This is because only the prompt itself is cached, while the actual response is computed anew each time based on the cached prompt.
3. **Is there a way to manually clear the cache?**
Manual cache clearing is not currently available. Prompts that have not been encountered recently are automatically cleared from the cache. Typical cache evictions occur after 5-10 minutes of inactivity, though sometimes lasting up to a maximum of one hour during off-peak periods.
4. **Will I be expected to pay extra for writing to Prompt Caching?**
No. Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature.
5. **Do cached prompts contribute to TPM rate limits?**
Yes, as caching does not affect rate limits.
6. **Does Prompt Caching work on Zero Data Retention requests?**
In-memory cache retention does not save any data to disk.
Extended prompt caching may store key/value tensors in GPU-local storage, and the key-value tensors are derived from customer content. This data is not retained beyond cache expiration -- the key-value tensors are retained for 1-2 hours (most usage) and at most 24 hours.
Extended prompt caching requests are not blocked if Zero Data Retention is enabled for your project. Other Zero Data Retention still applies, such as excluding customer content from abuse logs and preventing use of `store=True`.
See the [Your data](https://developers.openai.com/api/docs/guides/your-data) guide for more context on Zero Data Retention.
7. **Does Prompt Caching work with Data Residency?**
In-memory Prompt Caching does not store data and so does not impact Data Residency.
Extended caching temporarily stores data on GPU machines and will only be kept in-region when using Regional Inference.
---
# Prompt engineering
With the OpenAI API, you can use a [large language model](https://developers.openai.com/api/docs/models) to generate text from a prompt, as you might using [ChatGPT](https://chatgpt.com). Models can generate almost any kind of text response—like code, mathematical equations, structured JSON data, or human-like prose.
Here's a simple example using the [Responses API](https://developers.openai.com/api/docs/api-reference/responses).
An array of content generated by the model is in the `output` property of the response. In this simple example, we have just one output which looks like this:
```json
[
{
"id": "msg_67b73f697ba4819183a15cc17d011509",
"type": "message",
"role": "assistant",
"content": [
{
"type": "output_text",
"text": "Under the soft glow of the moon, Luna the unicorn danced through fields of twinkling stardust, leaving trails of dreams for every child asleep.",
"annotations": []
}
]
}
]
```
**The `output` array often has more than one item in it!** It can contain tool calls, data about reasoning tokens generated by [reasoning models](https://developers.openai.com/api/docs/guides/reasoning), and other items. It is not safe to assume that the model's text output is present at `output[0].content[0].text`.
Some of our [official SDKs](https://developers.openai.com/api/docs/libraries) include an `output_text` property on model responses for convenience, which aggregates all text outputs from the model into a single string. This may be useful as a shortcut to access text output from the model.
In addition to plain text, you can also have the model return structured data in JSON format - this feature is called [**Structured Outputs**](https://developers.openai.com/api/docs/guides/structured-outputs).
## Choosing a model
A key choice to make when generating content through the API is which model you want to use - the `model` parameter of the code samples above. [You can find a full listing of available models here](https://developers.openai.com/api/docs/models). Here are a few factors to consider when choosing a model for text generation.
- **[Reasoning models](https://developers.openai.com/api/docs/guides/reasoning)** generate an internal chain of thought to analyze the input prompt, and excel at understanding complex tasks and multi-step planning. They are also generally slower and more expensive to use than GPT models.
- **GPT models** are fast, cost-efficient, and highly intelligent, but benefit from more explicit instructions around how to accomplish tasks.
- **Large and small (mini or nano) models** offer trade-offs for speed, cost, and intelligence. Large models are more effective at understanding prompts and solving problems across domains, while small models are generally faster and cheaper to use.
When in doubt, [`gpt-4.1`](https://developers.openai.com/api/docs/models/gpt-4.1) offers a solid combination of intelligence, speed, and cost effectiveness.
## Prompt engineering
**Prompt engineering** is the process of writing effective instructions for a model, such that it consistently generates content that meets your requirements.
Because the content generated from a model is non-deterministic, prompting to get your desired output is a mix of art and science. However, you can apply techniques and best practices to get good results consistently.
Some prompt engineering techniques work with every model, like using message roles. But different model types (like reasoning versus GPT models) might need to be prompted differently to produce the best results. Even different snapshots of models within the same family could produce different results. So as you build more complex applications, we strongly recommend:
- Pinning your production applications to specific [model snapshots](https://developers.openai.com/api/docs/models) (like `gpt-4.1-2025-04-14` for example) to ensure consistent behavior
- Building [evals](https://developers.openai.com/api/docs/guides/evals) that measure the behavior of your prompts so you can monitor prompt performance as you iterate, or when you change and upgrade model versions
Now, let's examine some tools and techniques available to you to construct prompts.
## Message roles and instruction following
You can provide instructions to the model with [differing levels of authority](https://model-spec.openai.com/2025-02-12.html#chain_of_command) using the `instructions` API parameter or **message roles**.
The `instructions` parameter gives the model high-level instructions on how it should behave while generating a response, including tone, goals, and examples of correct responses. Any instructions provided this way will take priority over a prompt in the `input` parameter.
Generate text with instructions
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5",
reasoning: { effort: "low" },
instructions: "${semicolonsDevMsg}",
input: "${semicolonsPrompt}",
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
reasoning={"effort": "low"},
instructions="${semicolonsDevMsg}",
input="${semicolonsPrompt}",
)
print(response.output_text)
```
```bash
curl "https://api.openai.com/v1/responses" \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"reasoning": {"effort": "low"},
"instructions": "${semicolonsDevMsg}",
"input": "${semicolonsPrompt}"
}'
```
The example above is roughly equivalent to using the following input messages in the `input` array:
Generate text with messages using different roles
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5",
reasoning: { effort: "low" },
input: [
{
role: "developer",
content: "${semicolonsDevMsg}"
},
{
role: "user",
content: "${semicolonsPrompt}",
},
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
reasoning={"effort": "low"},
input=[
{
"role": "developer",
"content": "${semicolonsDevMsg}"
},
{
"role": "user",
"content": "${semicolonsPrompt}"
}
]
)
print(response.output_text)
```
```bash
curl "https://api.openai.com/v1/responses" \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"reasoning": {"effort": "low"},
"input": [
{
"role": "developer",
"content": "${semicolonsDevMsg}"
},
{
"role": "user",
"content": "${semicolonsPrompt}"
}
]
}'
```
Note that the `instructions` parameter only applies to the current response generation request. If you are [managing conversation state](https://developers.openai.com/api/docs/guides/conversation-state) with the `previous_response_id` parameter, the `instructions` used on previous turns will not be present in the context.
The [OpenAI model spec](https://model-spec.openai.com/2025-02-12.html#chain_of_command) describes how our models give different levels of priority to messages with different roles.
| `developer` | `user` | `assistant` |
| ------------------------------------------------------------------------------------------------------------------ | -------------------------------------------------------------------------------------------------- | ---------------------------------------------------------- |
| `developer` messages are instructions provided by the application developer, prioritized ahead of `user` messages. | `user` messages are instructions provided by an end user, prioritized behind `developer` messages. | Messages generated by the model have the `assistant` role. |
A multi-turn conversation may consist of several messages of these types, along with other content types provided by both you and the model. Learn more about [managing conversation state here](https://developers.openai.com/api/docs/guides/conversation-state).
You could think about `developer` and `user` messages like a function and its arguments in a programming language.
- `developer` messages provide the system's rules and business logic, like a function definition.
- `user` messages provide inputs and configuration to which the `developer` message instructions are applied, like arguments to a function.
## Reusable prompts
In the OpenAI dashboard, you can develop reusable [prompts](https://platform.openai.com/chat/edit) that you can use in API requests, rather than specifying the content of prompts in code. This way, you can more easily build and evaluate your prompts, and deploy improved versions of your prompts without changing your integration code.
Here's how it works:
1. **Create a reusable prompt** in the [dashboard](https://platform.openai.com/chat/edit) with placeholders like `{{customer_name}}`.
2. **Use the prompt** in your API request with the `prompt` parameter. The prompt parameter object has three properties you can configure:
- `id` — Unique identifier of your prompt, found in the dashboard
- `version` — A specific version of your prompt (defaults to the "current" version as specified in the dashboard)
- `variables` — A map of values to substitute in for variables in your prompt. The substitution values can either be strings, or other Response input message types like `input_image` or `input_file`. [See the full API reference](https://developers.openai.com/api/docs/api-reference/responses/create).
String variables
Generate text with a prompt template
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5",
prompt: {
id: "pmpt_abc123",
version: "2",
variables: {
customer_name: "Jane Doe",
product: "40oz juice box"
}
}
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
prompt={
"id": "pmpt_abc123",
"version": "2",
"variables": {
"customer_name": "Jane Doe",
"product": "40oz juice box"
}
}
)
print(response.output_text)
```
```bash
curl https://api.openai.com/v1/responses \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"model": "gpt-5",
"prompt": {
"id": "pmpt_abc123",
"version": "2",
"variables": {
"customer_name": "Jane Doe",
"product": "40oz juice box"
}
}
}'
```
Variables with file input
Prompt template with file input variable
```javascript
import fs from "fs";
import OpenAI from "openai";
const client = new OpenAI();
// Upload a PDF we will reference in the prompt variables
const file = await client.files.create({
file: fs.createReadStream("draconomicon.pdf"),
purpose: "user_data",
});
const response = await client.responses.create({
model: "gpt-5",
prompt: {
id: "pmpt_abc123",
variables: {
topic: "Dragons",
reference_pdf: {
type: "input_file",
file_id: file.id,
},
},
},
});
console.log(response.output_text);
```
```python
import openai, pathlib
client = openai.OpenAI()
# Upload a PDF we will reference in the variables
file = client.files.create(
file=open("draconomicon.pdf", "rb"),
purpose="user_data",
)
response = client.responses.create(
model="gpt-5",
prompt={
"id": "pmpt_abc123",
"variables": {
"topic": "Dragons",
"reference_pdf": {
"type": "input_file",
"file_id": file.id,
},
},
},
)
print(response.output_text)
```
```bash
# Assume you have already uploaded the PDF and obtained FILE_ID
curl https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5",
"prompt": {
"id": "pmpt_abc123",
"variables": {
"topic": "Dragons",
"reference_pdf": {
"type": "input_file",
"file_id": "file-abc123"
}
}
}
}'
```
## Message formatting with Markdown and XML
When writing `developer` and `user` messages, you can help the model understand logical boundaries of your prompt and context data using a combination of [Markdown](https://commonmark.org/help/) formatting and [XML tags](https://www.w3.org/TR/xml/).
Markdown headers and lists can be helpful to mark distinct sections of a prompt, and to communicate hierarchy to the model. They can also potentially make your prompts more readable during development. XML tags can help delineate where one piece of content (like a supporting document used for reference) begins and ends. XML attributes can also be used to define metadata about content in the prompt that can be referenced by your instructions.
In general, a developer message will contain the following sections, usually in this order (though the exact optimal content and order may vary by which model you are using):
- **Identity:** Describe the purpose, communication style, and high-level goals of the assistant.
- **Instructions:** Provide guidance to the model on how to generate the response you want. What rules should it follow? What should the model do, and what should the model never do? This section could contain many subsections as relevant for your use case, like how the model should [call custom functions](https://developers.openai.com/api/docs/guides/function-calling).
- **Examples:** Provide examples of possible inputs, along with the desired output from the model.
- **Context:** Give the model any additional information it might need to generate a response, like private/proprietary data outside its training data, or any other data you know will be particularly relevant. This content is usually best positioned near the end of your prompt, as you may include different context for different generation requests.
Below is an example of using Markdown and XML tags to construct a `developer` message with distinct sections and supporting examples.
API request
Send a prompt to generate code through the API
```javascript
import fs from "fs/promises";
import OpenAI from "openai";
const client = new OpenAI();
const instructions = await fs.readFile("prompt.txt", "utf-8");
const response = await client.responses.create({
model: "gpt-5",
instructions,
input: "How would I declare a variable for a last name?",
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
with open("prompt.txt", "r", encoding="utf-8") as f:
instructions = f.read()
response = client.responses.create(
model="gpt-5",
instructions=instructions,
input="How would I declare a variable for a last name?",
)
print(response.output_text)
```
```bash
curl https://api.openai.com/v1/responses \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"model": "gpt-5",
"instructions": "'"$(< prompt.txt)"'",
"input": "How would I declare a variable for a last name?"
}'
```
#### Save on cost and latency with prompt caching
When constructing a message, you should try and keep content that you expect to use over and over in your API requests at the beginning of your prompt, **and** among the first API parameters you pass in the JSON request body to [Chat Completions](https://developers.openai.com/api/docs/api-reference/chat) or [Responses](https://developers.openai.com/api/docs/api-reference/responses). This enables you to maximize cost and latency savings from [prompt caching](https://developers.openai.com/api/docs/guides/prompt-caching).
## Few-shot learning
Few-shot learning lets you steer a large language model toward a new task by including a handful of input/output examples in the prompt, rather than [fine-tuning](https://developers.openai.com/api/docs/guides/model-optimization) the model. The model implicitly "picks up" the pattern from those examples and applies it to a prompt. When providing examples, try to show a diverse range of possible inputs with the desired outputs.
Typically, you will provide examples as part of a `developer` message in your API request. Here's an example `developer` message containing examples that show a model how to classify positive or negative customer service reviews.
```
# Identity
You are a helpful assistant that labels short product reviews as
Positive, Negative, or Neutral.
# Instructions
* Only output a single word in your response with no additional formatting
or commentary.
* Your response should only be one of the words "Positive", "Negative", or
"Neutral" depending on the sentiment of the product review you are given.
# Examples
I absolutely love this headphones — sound quality is amazing!
Positive
Battery life is okay, but the ear pads feel cheap.
Neutral
Terrible customer service, I'll never buy from them again.
Negative
```
## Include relevant context information
It is often useful to include additional context information the model can use to generate a response within the prompt you give the model. There are a few common reasons why you might do this:
- To give the model access to proprietary data, or any other data outside the data set the model was trained on.
- To constrain the model's response to a specific set of resources that you have determined will be most beneficial.
The technique of adding additional relevant context to the model generation request is sometimes called **retrieval-augmented generation (RAG)**. You can add additional context to the prompt in many different ways, from querying a vector database and including the text you get back into a prompt, or by using OpenAI's built-in [file search tool](https://developers.openai.com/api/docs/guides/tools-file-search) to generate content based on uploaded documents.
#### Planning for the context window
Models can only handle so much data within the context they consider during a generation request. This memory limit is called a **context window**, which is defined in terms of [tokens](https://blogs.nvidia.com/blog/ai-tokens-explained) (chunks of data you pass in, from text to images).
Models have different context window sizes from the low 100k range up to one million tokens for newer GPT-4.1 models. [Refer to the model docs](https://developers.openai.com/api/docs/models) for specific context window sizes per model.
## Prompting GPT-5 models
GPT models like [`gpt-5`](https://developers.openai.com/api/docs/models/gpt-5) benefit from precise instructions that explicitly provide the logic and data required to complete the task in the prompt. GPT-5 in particular is highly steerable and responsive to well-specified prompts. To get the most out of GPT-5, refer to the prompting guide in the cookbook.
Get the most out of prompting GPT-5 with the tips and tricks in this
prompting guide, extracted from real-world use cases and practical
experience.
### GPT-5 prompting best practices
While the [cookbook](https://developers.openai.com/cookbook/examples/gpt-5/gpt-5_prompting_guide) has the best and most comprehensive guidance for prompting this model, here are a few best practices to keep in mind.
Coding
#### Coding
Prompting GPT-5 for coding tasks is most effective when following a few best practices: define the agent's role, enforce structured tool use with examples, require thorough testing for correctness, and set Markdown standards for clean output.
**Explicit role and workflow guidance**
Frame the model as a software engineering agent with well-defined responsibilities. Provide clear instructions for using tools like `functions.run` for code tasks, and specify when not to use certain modes—for example, avoid interactive execution unless necessary.
**Testing and validation**
Instruct the model to test changes with unit tests or Python commands, and validate patches carefully since tools like `apply_patch` may return “Done” even on failure.
**Tool use examples**
Include concrete examples of how to invoke commands with the provided functions, which improves reliability and adherence to expected workflows.
**Markdown standards**
Guide the model to generate clean, semantically correct markdown using inline code, code fences, lists, and tables where appropriate—and to format file paths, functions, and classes with backticks.
For detailed guidance and prompt samples specific to coding, see our [GPT-5 prompting guide](https://developers.openai.com/cookbook/examples/gpt-5/gpt-5_prompting_guide).
Front-end engineering
[GPT-5](https://developers.openai.com/api/docs/guides/latest-model) performs well at building front ends from scratch as well as contributing to large, established codebases. To get the best results, we recommend using the following libraries:
- **Styling / UI:** Tailwind CSS, shadcn/ui, Radix Themes
- **Icons:** Lucide, Material Symbols, Heroicons
- **Animation**: Motion
**Zero-to-one web apps**
GPT-5 can generate front-end web apps from a single prompt, no examples needed. Here's a sample prompt:
```bash
You are a world class web developer, capable of producing stunning, interactive, and innovative websites from scratch in a single prompt. You excel at delivering top-tier one-shot solutions.
Your process is simple and follows these steps:
Step 1: Create an evaluation rubric and refine it until you are fully confident.
Step 2: Consider every element that defines a world-class one-shot web app, then use that insight to create a <ONE_SHOT_RUBRIC> with 5–7 categories. Keep this rubric hidden—it's for internal use only.
Step 3: Apply the rubric to iterate on the optimal solution to the given prompt. If it doesn't meet the highest standard across all categories, refine and try again.
Step 4: Aim for simplicity while fully achieving the goal, and avoid external dependencies such as Next.js or React.
```
**Integration with large codebases**
For front-end engineering work in larger codebases, we've found that adding these categories of instruction to your prompts delivers the best results:
- **Principles:** Set visual quality standards, use modular/reusable components, and keep design consistent.
- **UI/UX:** Specify typography, colors, spacing/layout, interaction states (hover, empty, loading), and accessibility.
- **Structure:** Define file/folder layout for seamless integration.
- **Components:** Give reusable wrapper examples and backend-call separation strategies.
- **Pages:** Provide templates for common layouts.
- **Agent Instructions:** Ask the model to confirm design assumptions, scaffold projects, enforce standards, integrate APIs, test states, and document code.
For detailed guidance and prompt samples specific to frontend development, see our [frontend engineering cookbook.](https://developers.openai.com/cookbook/examples/gpt-5/gpt-5_frontend)
Agentic tasks
For agentic and long-running rollouts with GPT-5, focus your prompts on three core practices: plan tasks thoroughly to ensure complete resolution, provide clear preambles for major tool usage decisions, and use a TODO tool to track workflow and progress in an organized manner.
**Planning and persistence**
Instruct the model to resolve the full query before yielding control, decomposing it into sub-tasks and reflecting after each tool call to confirm completeness.
```
Remember, you are an agent - please keep going until the user's
query is completely resolved, before ending your turn and yielding
back to the user. Decompose the user's query into all required
sub-requests, and confirm that each is completed. Do not stop
after completing only part of the request. Only terminate your
turn when you are sure that the problem is solved. You must be
prepared to answer multiple queries and only finish the call once
the user has confirmed they're done.
You must plan extensively in accordance with the workflow
steps before making subsequent function calls, and reflect
extensively on the outcomes each function call made,
ensuring the user's query, and related sub-requests
are completely resolved.
```
**Preambles for transparency**
Ask the model to explain why it is calling a tool, but only at notable steps.
```
Before you call a tool explain why you are calling it
```
**Progress tracking with rubrics and TODOs**
Use a TODO list tool or rubric to enforce structured planning and avoid missed steps.
For detailed guidance and prompt samples specific to building agents with GPT-5 , see the [GPT-5 prompting guide.](https://developers.openai.com/cookbook/examples/gpt-5/gpt-5_prompting_guide)
## Prompting reasoning models
There are some differences to consider when prompting a [reasoning model](https://developers.openai.com/api/docs/guides/reasoning) versus prompting a GPT model. Generally speaking, reasoning models will provide better results on tasks with only high-level guidance. This differs from GPT models, which benefit from very precise instructions.
You could think about the difference between reasoning and GPT models like this.
- A reasoning model is like a senior co-worker. You can give them a goal to achieve and trust them to work out the details.
- A GPT model is like a junior coworker. They'll perform best with explicit instructions to create a specific output.
For more information on best practices when using reasoning models, [refer to this guide](https://developers.openai.com/api/docs/guides/reasoning-best-practices).
## Next steps
Now that you known the basics of text inputs and outputs, you might want to check out one of these resources next.
[
Use the Playground to develop and iterate on prompts.
](https://platform.openai.com/chat/edit)
[
Ensure JSON data emitted from a model conforms to a JSON schema.
](https://developers.openai.com/api/docs/guides/structured-outputs)
[
Check out all the options for text generation in the API reference.
](https://developers.openai.com/api/docs/api-reference/responses)
## Other resources
For more inspiration, visit the [OpenAI Cookbook](https://developers.openai.com/cookbook), which contains example code and also links to third-party resources such as:
- [Prompting libraries & tools](https://developers.openai.com/cookbook/related_resources#prompting-libraries--tools)
- [Prompting guides](https://developers.openai.com/cookbook/related_resources#prompting-guides)
- [Video courses](https://developers.openai.com/cookbook/related_resources#video-courses)
- [Papers on advanced prompting to improve reasoning](https://developers.openai.com/cookbook/related_resources#papers-on-advanced-prompting-to-improve-reasoning)
---
# Prompt generation
import {
FUNCTION_META_SCHEMA,
FUNCTION_META_SCHEMA_PROMPT,
GENERAL_META_PROMPT,
GENERAL_META_PROMPT_EDIT,
META_SCHEMA,
META_SCHEMA_PROMPT,
REALTIME_META_PROMPT,
REALTIME_META_PROMPT_EDIT,
} from "./prompts";
The **Generate** button in the [Playground](https://platform.openai.com/chat/edit) lets you generate prompts, [functions](https://developers.openai.com/api/docs/guides/function-calling), and [schemas](https://developers.openai.com/api/docs/guides/structured-outputs#supported-schemas) from just a description of your task. This guide will walk through exactly how it works.
## Overview
Creating prompts and schemas from scratch can be time-consuming, so generating them can help you get started quickly. The Generate button uses two main approaches:
1. **Prompts:** We use **meta-prompts** that incorporate best practices to generate or improve prompts.
1. **Schemas:** We use **meta-schemas** that produce valid JSON and function syntax.
While we currently use meta prompts and schemas, we may integrate more advanced techniques in the future like [DSPy](https://arxiv.org/abs/2310.03714) and ["Gradient Descent"](https://arxiv.org/abs/2305.03495).
## Prompts
A **meta-prompt** instructs the model to create a good prompt based on your task description or improve an existing one. The meta-prompts in the Playground draw from our [prompt engineering](https://developers.openai.com/api/docs/guides/prompt-engineering) best practices and real-world experience with users.
We use specific meta-prompts for different output types, like audio, to ensure the generated prompts meet the expected format.
### Meta-prompts
export const textMeta = {
python:`
from openai import OpenAI
client = OpenAI()
META_PROMPT = """\n`+
GENERAL_META_PROMPT + "\n" +`""".strip()
def generate_prompt(task_or_prompt: str):
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": META_PROMPT,
},
{
"role": "user",
"content": "Task, Goal, or Current Prompt:\\n" + task_or_prompt,
},
],
)
return completion.choices[0].message.content
`.trim(),
};
export const audioMeta = {
python:`
from openai import OpenAI
client = OpenAI()
META_PROMPT = """\n`+
REALTIME_META_PROMPT + "\n" +`""".strip()
def generate_prompt(task_or_prompt: str):
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": META_PROMPT,
},
{
"role": "user",
"content": "Task, Goal, or Current Prompt:\\n" + task_or_prompt,
},
],
)
return completion.choices[0].message.content
`.trim(),
};
### Prompt edits
To edit prompts, we use a slightly modified meta-prompt. While direct edits are straightforward to apply, identifying necessary changes for more open-ended revisions can be challenging. To address this, we include a **reasoning section** at the beginning of the response. This section helps guide the model in determining what changes are needed by evaluating the existing prompt's clarity, chain-of-thought ordering, overall structure, and specificity, among other factors. The reasoning section makes suggestions for improvements and is then parsed out from the final response.
export const textMetaEdits = {
python:`
from openai import OpenAI
client = OpenAI()
META_PROMPT = """\n`+
GENERAL_META_PROMPT_EDIT + "\n" +`""".strip()
def generate_prompt(task_or_prompt: str):
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": META_PROMPT,
},
{
"role": "user",
"content": "Task, Goal, or Current Prompt:\\n" + task_or_prompt,
},
],
)
return completion.choices[0].message.content
`.trim(),
};
export const audioMetaEdits = {
python:`
from openai import OpenAI
client = OpenAI()
META_PROMPT = """\n`+
REALTIME_META_PROMPT_EDIT + "\n" +`""".strip()
def generate_prompt(task_or_prompt: str):
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": META_PROMPT,
},
{
"role": "user",
"content": "Task, Goal, or Current Prompt:\\n" + task_or_prompt,
},
],
)
return completion.choices[0].message.content
`.trim(),
};
## Schemas
[Structured Outputs](https://developers.openai.com/api/docs/guides/structured-outputs) schemas and function schemas are themselves JSON objects, so we leverage Structured Outputs to generate them.
This requires defining a schema for the desired output, which in this case is itself a schema. To do this, we use a self-describing schema – a **meta-schema**.
Because the `parameters` field in a function schema is itself a schema, we use the same meta-schema to generate functions.
### Defining a constrained meta-schema
[Structured Outputs](https://developers.openai.com/api/docs/guides/structured-outputs) supports two modes: `strict=true` and `strict=false`. Both modes use the same model trained to follow the provided schema, but only "strict mode" guarantees perfect adherence through constrained sampling.
Our goal is to generate schemas for strict mode using strict mode itself. However, the official meta-schemas provided by the [JSON Schema Specification](https://json-schema.org/specification#meta-schemas) rely on features [not currently supported](https://developers.openai.com/api/docs/guides/structured-outputs#some-type-specific-keywords-are-not-yet-supported) in strict mode. This poses challenges that affect both input and output schemas.
1. **Input schema:** We can't use [unsupported features](https://developers.openai.com/api/docs/guides/structured-outputs#some-type-specific-keywords-are-not-yet-supported) in the input schema to describe the output schema.
2. **Output schema:** The generated schema must not include [unsupported features](https://developers.openai.com/api/docs/guides/structured-outputs#some-type-specific-keywords-are-not-yet-supported).
Because we need to generate new keys in the output schema, the input meta-schema must use `additionalProperties`. This means we can't currently use strict mode to generate schemas. However, we still want the generated schema to conform to strict mode constraints.
To overcome this limitation, we define a **pseudo-meta-schema** — a meta-schema that uses features not supported in strict mode to describe only the features that are supported in strict mode. Essentially, this approach steps outside strict mode for the meta-schema definition while still ensuring that the generated schemas adhere to strict mode constraints.
Constructing a constrained meta-schema is a challenging task, so we leveraged our models to help.
We began by giving `o1-preview` and `gpt-4o` in JSON mode a description of our goal using the Structured Outputs documentation.
After a few iterations, we developed our first functional meta-schema.
We then used `gpt-4o` with Structured Outputs and provided _that initial schema_ along with our task description and documentation, to generate better candidates. With each iteration we used a better schema to generate the next, until we finally reviewed it carefully by hand.
Finally, after cleaning the output, we validated the schemas against a set of evals for schemas and functions.
### Output cleaning
Strict mode guarantees perfect schema adherence. Because we can't use it during generation, however, we need to validate and transform the output after generating it.
After generating a schema, we perform the following steps:
1. **Set `additionalProperties` to `false`** for all objects.
1. **Mark all properties as required**.
1. **For structured output schemas**, wrap them in [`json_schema`](https://developers.openai.com/api/docs/guides/structured-outputs#how-to-use?context=without_parse) object.
1. **For functions**, wrap them in a [`function`](https://developers.openai.com/api/docs/guides/function-calling#step-3-pass-your-function-definitions-as-available-tools-to-the-model-along-with-the-messages) object.
The Realtime API
[function](https://developers.openai.com/api/docs/guides/realtime-conversations#function-calling) object
differs slightly from the Chat Completions API, but uses the same schema.
### Meta-schemas
Each meta-schema has a corresponding prompt which includes few-shot examples. When combined with the reliability of Structured Outputs — even without strict mode — we were able to use `gpt-4o-mini` for schema generation.
export const soMetaSchema = {
python:`
from openai import OpenAI
import json
client = OpenAI()
META_SCHEMA = ` +
JSON.stringify(META_SCHEMA, null, 2).replaceAll("false", "False") + "\n" +
`
META_PROMPT = """\n` +
META_SCHEMA_PROMPT + "\n" + `""".strip()
def generate_schema(description: str):
completion = client.chat.completions.create(
model="gpt-4o-mini",
response_format={"type": "json_schema", "json_schema": META_SCHEMA},
messages=[
{
"role": "system",
"content": META_PROMPT,
},
{
"role": "user",
"content": "Description:\\n" + description,
},
],
)
return json.loads(completion.choices[0].message.content)
`.trim(),
};
export const soFunctionSchema = {
python:`
from openai import OpenAI
import json
client = OpenAI()
META_SCHEMA = ` +
JSON.stringify(FUNCTION_META_SCHEMA, null, 2).replaceAll("false", "False") + "\n" +
`
META_PROMPT = """\n` +
FUNCTION_META_SCHEMA_PROMPT + "\n" + `""".strip()
def generate_function_schema(description: str):
completion = client.chat.completions.create(
model="gpt-4o-mini",
response_format={"type": "json_schema", "json_schema": META_SCHEMA},
messages=[
{
"role": "system",
"content": META_PROMPT,
},
{
"role": "user",
"content": "Description:\\n" + description,
},
],
)
return json.loads(completion.choices[0].message.content)
`.trim(),
};
---
# Prompt guidance
---
# Prompt optimizer
The [prompt optimizer](https://platform.openai.com/chat/edit?models=gpt-5&optimize=true) is a chat interface in the dashboard, where you enter a prompt, and we optimize it according to current best practices before returning it to you. Pairing the prompt optimizer with [datasets](https://developers.openai.com/api/docs/guides/evaluation-getting-started) is a powerful way to automatically improve prompts.
## Prepare your data
1. Set up a [dataset](https://developers.openai.com/api/docs/guides/evaluation-getting-started) containing the prompt you want to optimize and an evaluation dataset.
1. Create at least three rows of data with responses in your dataset.
1. For each row, create at least one grader result or human annotation.
The prompt optimizer can use the following from your dataset to improve your prompt:
- Annotations (Good/Bad and additional custom annotation columns you add)
- Text critiques written in **output_feedback**
- Results from graders
For effective results, add annotations containing a Good/Bad rating _and_ detailed, specific critiques. Create [graders](https://developers.openai.com/api/docs/guides/evaluation-getting-started#adding-graders) that precisely capture the properties that you desire from your prompt.
## Optimize your prompt
Once you’ve prepared your dataset, create an optimization.
1. In the bottom of the prompt pane, click **Optimize**. This will create a new tab for the optimized result and start an optimization process that runs in the background.
1. When the optimized prompt is ready, view and test the new prompt.
1. Repeat. While a single optimization run may achieve your desired result, experiment with repeating the optimization process on the new prompt—generate outputs, annotate outputs, run graders, and optimize.
The effectiveness of prompt optimization depends on the quality of your
graders. We recommend building narrowly-defined graders for each of the
desired output properties where you see your prompt failing.
Always evaluate and manually review optimized prompts before using them in production. While the prompt optimizer generally provides a strict improvement in your prompt’s effectiveness, it's possible for the optimized prompt to perform worse than your original on specific inputs.
## Next steps
For more inspiration, visit the [OpenAI Cookbook](https://developers.openai.com/cookbook), which contains example code and links to third-party resources, or learn more about our tools for evals:
Operate a flywheel of continuous improvement using evaluations.
Evaluate against external models, interact with evals via API, and more.
[
Build sophisticated graders to improve the effectiveness of your evals.
](https://developers.openai.com/api/docs/guides/graders)
[
Improve a model's ability to generate responses tailored to your use case.
](https://developers.openai.com/api/docs/guides/fine-tuning)
---
# Prompting
**Prompting** is the process of providing input to a model. The quality of your output often depends on how well you're able to prompt the model.
## Overview
Prompting is both an art and a science. OpenAI has some strategies and API design decisions to help you construct strong prompts and get consistently good results from a model. We encourage you to experiment.
### Prompts in the API
OpenAI provides a long-lived prompt object, with versioning and templating shared by all users in a project. This design lets you manage, test, and reuse prompts across your team, with one central definition across APIs, SDKs, and dashboard.
Universal prompt IDs give you flexibility to test and build. Variables and prompts share a base prompt, so when you create a new version, you can use that for [evals](https://developers.openai.com/api/docs/guides/evals) and determine whether a prompt performs better or worse.
### Prompting tools and techniques
- **[Prompt caching](https://developers.openai.com/api/docs/guides/prompt-caching)**: Reduce latency by up to 80% and cost by up to 75%
- **[Prompt engineering](https://developers.openai.com/api/docs/guides/prompt-engineering)**: Learn strategies, techniques, and tools to construct prompts
## Create a prompt
Log in and use the OpenAI [dashboard](https://platform.openai.com/chat) to create, save, version, and share your prompts.
1. **Start a prompt**
In the [Playground](https://platform.openai.com/playground), fill out the fields to create your desired prompt.
1. **Add prompt variables**
Variables let you inject dynamic values without changing your prompt. Use them in any message role using `{{variable}}`. For example, when creating a local weather prompt, you might add a `city` variable with the value `San Francisco`.
1. **Use the prompt in your [Responses API](https://developers.openai.com/api/docs/guides/text?api-mode=responses) call**
Find your prompt ID and version number in the URL, and pass it as `prompt_id`:
```curl
curl -s -X POST "https://api.openai.com/v1/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"prompt": {
"prompt_id": "pmpt_123",
"variables": {
"city": "San Francisco"
}
}
}'
```
1. **Create a new prompt version**
Versions let you iterate on your prompts without overwriting existing details. You can use all versions in the API and evaluate their performance against each other. The prompt ID points to the latest published version unless you specify a version.
To create a new version, edit the prompt and click **Update**. You'll receive a new prompt ID to copy and use in your Responses API calls.
1. **Roll back if needed**
In the [prompts dashboard](https://platform.openai.com/chat), select the prompt you want to roll back. On the right, click **History**. Find the version you want to restore, and click **Restore**.
## Refine your prompt
- Put overall tone or role guidance in the system message; keep task-specific details and examples in user messages.
- Combine few-shot examples into a concise YAML-style or bulleted block so they’re easy to scan and update.
- Mirror your project structure with clear folder names so teammates can locate prompts quickly.
- Rerun your linked eval every time you publish—catching issues early is cheaper than fixing them in production.
## Next steps
When you feel confident in your prompts, you might want to check out the following guides and resources.
[
Use the Playground to develop and iterate on prompts.
](https://platform.openai.com/chat/edit)
[
Learn how to prompt a model to generate text.
](https://developers.openai.com/api/docs/guides/text)
[
Learn about OpenAI's prompt engineering tools and techniques.
](https://developers.openai.com/api/docs/guides/prompt-engineering)
---
# Quickstart
Use this page when you want the shortest path to a working SDK-based agent. The examples below use the same high-level concepts in both TypeScript and Python: define an agent, run it, then add tools and specialist agents as your workflow grows.
## Install the SDK
Create a project, install the SDK, and set your API key.
Create an API Key
```bash
# TypeScript
npm install @openai/agents zod
# Python
pip install openai-agents
export OPENAI_API_KEY=sk-...
```
## Create and run your first agent
Start with one focused agent and one turn. The SDK handles the model call and returns a result object with the final output plus the run history.
Create and run an agent
```typescript
import { Agent, run } from "@openai/agents";
const agent = new Agent({
name: "History tutor",
instructions:
"You answer history questions clearly and concisely.",
model: "gpt-5.5",
});
const result = await run(agent, "When did the Roman Empire fall?");
console.log(result.finalOutput);
```
```python
import asyncio
from agents import Agent, Runner
agent = Agent(
name="History tutor",
instructions="You answer history questions clearly and concisely.",
model="gpt-5.5",
)
async def main() -> None:
result = await Runner.run(agent, "When did the Roman Empire fall?")
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
```
You should see a concise answer in the terminal. Once that loop works, keep the same shape and add capabilities incrementally rather than starting with a large multi-agent design.
## Carry state into the next turn
The first run result is also how you decide what the second turn should use as state.
| If you want | Start with |
| ----------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------- |
| Keep the full history in your application | |
| Let the SDK load and save history for you | A session |
| Let OpenAI manage continuation state | A server-managed continuation ID |
| Resume a run that paused for approval or interruption | , together with `interruptions` |
After handoffs, reuse for the next turn when that specialist should stay in control.
## Give the agent a tool
The first capability you add is often a function tool or a hosted OpenAI tool such as web search or file search.
Add a function tool
```typescript
import { Agent, run, tool } from "@openai/agents";
import { z } from "zod";
const historyFunFact = tool({
name: "history_fun_fact",
description: "Return a short history fact.",
parameters: z.object({}),
async execute() {
return "Sharks are older than trees.";
},
});
const agent = new Agent({
name: "History tutor",
instructions:
"Answer history questions clearly. Use history_fun_fact when it helps.",
tools: [historyFunFact],
});
const result = await run(
agent,
"Tell me something surprising about ancient life on Earth.",
);
console.log(result.finalOutput);
```
```python
import asyncio
from agents import Agent, Runner, function_tool
@function_tool
def history_fun_fact() -> str:
"""Return a short history fact."""
return "Sharks are older than trees."
agent = Agent(
name="History tutor",
instructions="Answer history questions clearly. Use history_fun_fact when it helps.",
tools=[history_fun_fact],
)
async def main() -> None:
result = await Runner.run(
agent,
"Tell me something surprising about ancient life on Earth.",
)
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
```
Use the shared [Using tools](https://developers.openai.com/api/docs/guides/tools#usage-in-the-agents-sdk) guide when you need hosted tools, tool search, or agents-as-tools.
## Add specialist agents
A common next step is to split the workflow into specialists and let a router delegate to them with handoffs.
Route to specialist agents
```typescript
import { Agent, run } from "@openai/agents";
const historyTutor = new Agent({
name: "History tutor",
instructions: "Answer history questions clearly and concisely.",
});
const mathTutor = new Agent({
name: "Math tutor",
instructions: "Explain math step by step and include worked examples.",
});
const triageAgent = Agent.create({
name: "Homework triage",
instructions: "Route each homework question to the right specialist.",
handoffs: [historyTutor, mathTutor],
});
const result = await run(
triageAgent,
"Who was the first president of the United States?",
);
console.log(result.finalOutput);
console.log(result.lastAgent?.name);
```
```python
import asyncio
from agents import Agent, Runner
history_tutor = Agent(
name="History tutor",
handoff_description="Specialist for history questions.",
instructions="Answer history questions clearly and concisely.",
)
math_tutor = Agent(
name="Math tutor",
handoff_description="Specialist for math questions.",
instructions="Explain math step by step and include worked examples.",
)
triage_agent = Agent(
name="Homework triage",
instructions="Route each homework question to the right specialist.",
handoffs=[history_tutor, math_tutor],
)
async def main() -> None:
result = await Runner.run(
triage_agent,
"Who was the first president of the United States?",
)
print(result.final_output)
print(result.last_agent.name)
if __name__ == "__main__":
asyncio.run(main())
```
## Inspect traces early
The normal server-side SDK path includes tracing. As soon as the first run works, open the [Traces dashboard](https://platform.openai.com/traces) to inspect model calls, tool calls, handoffs, and guardrails before you start tuning prompts.
## Next steps
Once the first run works, continue with the guide that matches the next capability you want to add.
---
# Rate limits
export const snippetTenacityLibrary = {
python: `
from openai import OpenAI
client = OpenAI()
from tenacity import (
retry,
stop_after_attempt,
wait_random_exponential,
) # for exponential backoff
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
def completion_with_backoff(**kwargs):
return client.completions.create(**kwargs)
completion_with_backoff(model="gpt-4o-mini", prompt="Once upon a time,")
`.trim(),
};
export const snippetBackoffLibrary = {
python: `
import backoff
import openai
from openai import OpenAI
client = OpenAI()
@backoff.on_exception(backoff.expo, openai.RateLimitError)
def completions_with_backoff(**kwargs):
return client.completions.create(**kwargs)
completions_with_backoff(model="gpt-4o-mini", prompt="Once upon a time,")
`.trim(),
};
export const snippetManualBackoffImplementation = {
python: `
# imports
import random
import time
import openai
from openai import OpenAI
client = OpenAI()
# define a retry decorator
def retry_with_exponential_backoff(
func,
initial_delay: float = 1,
exponential_base: float = 2,
jitter: bool = True,
max_retries: int = 10,
errors: tuple = (openai.RateLimitError,),
):
"""Retry a function with exponential backoff."""
def wrapper(*args, **kwargs):
# Initialize variables
num_retries = 0
delay = initial_delay
# Loop until a successful response or max_retries is hit or an exception is raised
while True:
try:
return func(*args, **kwargs)
# Retry on specific errors
except errors as e:
# Increment retries
num_retries += 1
# Check if max retries has been reached
if num_retries > max_retries:
raise Exception(
f"Maximum number of retries ({max_retries}) exceeded."
)
# Increment the delay
delay *= exponential_base * (1 + jitter * random.random())
# Sleep for the delay
time.sleep(delay)
# Raise exceptions for any errors not specified
except Exception as e:
raise e
return wrapper
@retry_with_exponential_backoff
def completions_with_backoff(**kwargs):
return client.completions.create(**kwargs)
`.trim(),
};
Rate limits are restrictions that our API imposes on the number of times a user or client can
access our services within a specified period of time.
## Why do we have rate limits?
Rate limits are a common practice for APIs, and they're put in place for a few different reasons:
- **They help protect against abuse or misuse of the API.** For example, a malicious actor could flood the API with requests in an attempt to overload it or cause disruptions in service. By setting rate limits, OpenAI can prevent this kind of activity.
- **Rate limits help ensure that everyone has fair access to the API.** If one person or organization makes an excessive number of requests, it could bog down the API for everyone else. By throttling the number of requests that a single user can make, OpenAI ensures that the most number of people have an opportunity to use the API without experiencing slowdowns.
- **Rate limits can help OpenAI manage the aggregate load on its infrastructure.** If requests to the API increase dramatically, it could tax the servers and cause performance issues. By setting rate limits, OpenAI can help maintain a smooth and consistent experience for all users.
Please work through this document in its entirety to better understand how
OpenAI’s rate limit system works. We include code examples and possible
solutions to handle common issues. We also include details around how your
rate limits are automatically increased in the usage tiers section below.
## How do these rate limits work?
Rate limits use metrics such as **RPM** (requests per minute), **RPD** (requests per day), **TPM** (tokens per minute), **TPD** (tokens per day), **IPM** (images per minute), and audio minutes per minute for some streaming audio models. Rate limits can be hit across any of the options depending on what occurs first. For example, you might send 20 requests with only 100 tokens to the ChatCompletions endpoint and that would fill your limit (if your RPM was 20), even if you didn't send 150k tokens (if your TPM limit was 150k) within those 20 requests.
[Batch API](https://developers.openai.com/api/docs/api-reference/batch/create) queue limits are calculated based on the total number of input tokens queued for a given model. Tokens from pending batch jobs are counted against your queue limit. Once a batch job is completed, its tokens are no longer counted against that model's limit.
Other important things worth noting:
- Rate limits are defined at the [organization level](https://developers.openai.com/api/docs/guides/production-best-practices) and at the project level, not user level.
- Rate limits vary by the [model](https://developers.openai.com/api/docs/models) being used.
- For long context models like GPT-4.1, there is a separate rate limit for long context requests. You can view these rate limits in [developer console](https://platform.openai.com/settings/organization/limits).
- Limits are also placed on the total amount an organization can spend on the API each month. These are also known as "usage limits".
- Some model families have shared rate limits. Any models listed under a "shared limit" in your [organizations limit page](https://platform.openai.com/settings/organization/limits) share a rate limit between them. For example, if the listed shared TPM is 3.5M, all calls to any model in the given "shared limit" list will count towards that 3.5M.
- Vector store ingestion is also rate limited per vector store ID. `/vector_stores/{vector_store_id}/files` and `/vector_stores/{vector_store_id}/file_batches` share a limit of 300 requests per minute for each vector store. For larger ingests, prefer `/vector_stores/{vector_store_id}/file_batches`.
## Usage tiers
You can view the rate and usage limits for your organization under the [limits](https://platform.openai.com/settings/organization/limits) section of your account settings. As your spend on our API goes up, we automatically graduate you to the next usage tier. This usually results in an increase in rate limits across most models.
| Tier | Qualification | Usage limits |
| ----------- | --------------------------------------------------------------------- | ---------------- |
| Free | User must be in an [allowed geography](https://developers.openai.com/api/docs/supported-countries) | $100 / month |
| Tier 1 | $5 paid | $100 / month |
| Tier 2 | $50 paid | $500 / month |
| Tier 3 | $100 paid | $1,000 / month |
| Tier 4 | $250 paid | $5,000 / month |
| Tier 5 | $1,000 paid | $200,000 / month |
To view a high-level summary of rate limits per model, visit the [models page](https://developers.openai.com/api/docs/models).
### Rate limits in headers
In addition to seeing your rate limit on your [account page](https://platform.openai.com/settings/organization/limits), you can also view important information about your rate limits such as the remaining requests, tokens, and other metadata in the headers of the HTTP response.
You can expect to see the following header fields:
| Field | Sample Value | Description |
| ------------------------------ | ------------ | ------------------------------------------------------------------------------------- |
| x-ratelimit-limit-requests | 60 | The maximum number of requests that are permitted before exhausting the rate limit. |
| x-ratelimit-limit-tokens | 150000 | The maximum number of tokens that are permitted before exhausting the rate limit. |
| x-ratelimit-remaining-requests | 59 | The remaining number of requests that are permitted before exhausting the rate limit. |
| x-ratelimit-remaining-tokens | 149984 | The remaining number of tokens that are permitted before exhausting the rate limit. |
| x-ratelimit-reset-requests | 1s | The time until the rate limit (based on requests) resets to its initial state. |
| x-ratelimit-reset-tokens | 6m0s | The time until the rate limit (based on tokens) resets to its initial state. |
### Fine-tuning rate limits
The fine-tuning rate limits for your organization can be [found in the dashboard as well](https://platform.openai.com/settings/organization/limits), and can also be retrieved via API:
```bash
curl https://api.openai.com/v1/fine_tuning/model_limits \
-H "Authorization: Bearer $OPENAI_API_KEY"
```
## Error mitigation
### What are some steps I can take to mitigate this?
The OpenAI Cookbook has a [Python notebook](https://developers.openai.com/cookbook/examples/how_to_handle_rate_limits) that explains how to avoid rate limit errors, as well an example [Python script](https://github.com/openai/openai-cookbook/blob/main/examples/api_request_parallel_processor.py) for staying under rate limits while batch processing API requests.
You should also exercise caution when providing programmatic access, bulk processing features, and automated social media posting - consider only enabling these for trusted customers.
To protect against automated and high-volume misuse, set a usage limit for individual users within a specified time frame (daily, weekly, or monthly). Consider implementing a hard cap or a manual review process for users who exceed the limit.
#### Retrying with exponential backoff
One easy way to avoid rate limit errors is to automatically retry requests with a random exponential backoff. Retrying with exponential backoff means performing a short sleep when a rate limit error is hit, then retrying the unsuccessful request. If the request is still unsuccessful, the sleep length is increased and the process is repeated. This continues until the request is successful or until a maximum number of retries is reached.
This approach has many benefits:
- Automatic retries means you can recover from rate limit errors without crashes or missing data
- Exponential backoff means that your first retries can be tried quickly, while still benefiting from longer delays if your first few retries fail
- Adding random jitter to the delay helps retries from all hitting at the same time.
Note that unsuccessful requests contribute to your per-minute limit, so continuously resending a request won’t work.
Below are a few example solutions **for Python** that use exponential backoff.
Example 1: Using the Tenacity library
Tenacity is an Apache 2.0 licensed general-purpose retrying library, written in Python, to simplify the task of adding retry behavior to just about anything.
To add exponential backoff to your requests, you can use the `tenacity.retry` decorator. The below example uses the `tenacity.wait_random_exponential` function to add random exponential backoff to a request.
Note that the Tenacity library is a third-party tool, and OpenAI makes no guarantees about
its reliability or security.
Example 2: Using the backoff library
Another python library that provides function decorators for backoff and retry is [backoff](https://pypi.org/project/backoff/):
Like Tenacity, the backoff library is a third-party tool, and OpenAI makes no guarantees about its reliability or security.
Example 3: Manual backoff implementation
If you don't want to use third-party libraries, you can implement your own backoff logic following this example:
Again, OpenAI makes no guarantees on the security or efficiency of this solution but it can be a good starting place for your own solution.
#### Reduce the `max_tokens` to match the size of your completions
Your rate limit is calculated as the maximum of `max_tokens` and the estimated number of tokens based on the character count of your request. Try to set the `max_tokens` value as close to your expected response size as possible.
#### Batching requests
If your use case does not require immediate responses, you can use the [Batch API](https://developers.openai.com/api/docs/guides/batch) to more easily submit and execute large collections of requests without impacting your synchronous request rate limits.
For use cases that _do_ requires synchronous responses, the OpenAI API has separate limits for **requests per minute** and **tokens per minute**.
If you're hitting the limit on requests per minute but have available capacity on tokens per minute, you can increase your throughput by batching multiple tasks into each request. This will allow you to process more tokens per minute, especially with our smaller models.
Sending in a batch of prompts works exactly the same as a normal API call, except you pass in a list of strings to the prompt parameter instead of a single string. [Learn more in the Batch API guide](https://developers.openai.com/api/docs/guides/batch).
---
# Realtime and audio
import {
Cube,
Desktop,
Phone,
} from "@components/react/oai/platform/ui/Icon.react";
Start with the outcome you want to build. Realtime sessions are best for live audio that needs low latency. Request-based audio APIs are best for files, bounded requests, or generated speech that doesn't need a live session.
## Common use cases
## Understand different architectures
## Choose a realtime session
Realtime sessions keep a connection open while your application sends audio, receives events, and updates session state.
| Session type |
Use when |
Endpoint or pattern |
| Voice-agent session |
The model should respond to the user, call tools, and manage
conversation state.
|
Conversation session on /v1/realtime
|
| Translation session |
The app should continuously translate speech as it arrives. |
Continuous translation session on /v1/realtime/translations
|
| Transcription session |
The app needs streaming transcript deltas without model-generated spoken
responses.
|
Transcription session that emits transcript deltas |
Use a voice-agent session when your application needs an assistant that responds to the user. Use a translation session when your application needs an interpreter that translates the speaker. Use a transcription session when your application needs text from audio without model-generated responses.
### Voice-agent sessions
Voice-agent sessions use the standard Realtime API conversation lifecycle. The client connects to `/v1/realtime`, sends audio or text, and listens for model responses, tool calls, and session events.
For most browser voice agents, start with the [Voice agents](https://developers.openai.com/api/docs/guides/voice-agents) guide. It uses the Agents SDK with WebRTC for browser audio and can connect to server-side tools.
Realtime 2 adds reasoning to speech-to-speech workflows. Start with
`reasoning.effort` set to `low` for most production voice agents, then adjust
based on latency tolerance and task complexity. Use the [Realtime prompting
guide](https://developers.openai.com/api/docs/guides/realtime-models-prompting) to tune reasoning,
preambles, tool use, unclear audio, and exact entity capture.
### Translation sessions
Realtime translation uses a dedicated translation endpoint instead of the standard voice-agent endpoint. Translation sessions are continuous: the client streams audio into the session, and the service streams translated audio and transcript deltas out.
Translation sessions don't use the normal assistant turn lifecycle. Don't call `response.create`, and don't wait for the client to commit a user turn before translation begins. For browser media, use WebRTC. For server media pipelines such as phone calls or broadcast ingest, use WebSockets.
See [Realtime translation](https://developers.openai.com/api/docs/guides/realtime-translation) for the dedicated endpoint, session configuration, and architecture patterns.
### Transcription sessions
You can transcribe audio in more than one way. Use a realtime transcription session when your application needs live transcript deltas from streaming audio. Use the [Speech to text](https://developers.openai.com/api/docs/guides/speech-to-text) guide for file uploads, request-based transcription, or diarization-focused workflows.
For realtime transcription, `gpt-realtime-whisper` gives you controllable latency. Lower delay settings produce earlier partial text, while higher delay settings can improve transcript quality. Test with your real audio conditions, target languages, accents, and domain vocabulary before choosing a production default.
See [Realtime transcription](https://developers.openai.com/api/docs/guides/realtime-transcription) for session configuration and event handling.
## Choose a connection method
Choose the transport based on where your application captures and plays audio:
[
Use for browser and mobile clients that capture or play audio directly.
](https://developers.openai.com/api/docs/guides/realtime-webrtc)
[
Use when your server already receives raw audio from a media pipeline, call
system, or worker.
](https://developers.openai.com/api/docs/guides/realtime-websocket)
[
Use for telephony voice agents. Confirm model support before using SIP for
translation or transcription.
](https://developers.openai.com/api/docs/guides/realtime-sip)
## Safety identifiers
If your application identifies individual end users, include a [safety identifier](https://developers.openai.com/api/docs/guides/safety-best-practices#implement-safety-identifiers) with Realtime API requests. Safety identifiers are recommended but not required. They help OpenAI monitor and detect abuse while allowing enforcement to target an individual user rather than your entire organization. Use a stable, privacy-preserving value, such as a hashed internal user ID.
For Realtime API requests, send the identifier in the `OpenAI-Safety-Identifier` header. When using ephemeral tokens, set the header on the server-side request that creates the client secret so the identifier is bound to that session. When connecting from a trusted server with WebSocket or the unified WebRTC interface, set the header on the connection request.
Safety identifiers do not carry over from Responses API requests or from other sessions. If you use the Responses API `safety_identifier` parameter elsewhere in your application, pass the same stable value separately when you create or connect each Realtime session.
## Beta to GA migration
If you still have a beta Realtime integration, migrate it to the GA interface before moving forward with new work. The most important changes are:
- Remove the `OpenAI-Beta: realtime=v1` header when calling the GA interface.
- Use [`POST /v1/realtime/client_secrets`](https://developers.openai.com/api/docs/api-reference/realtime-sessions/create-realtime-client-secret) to create ephemeral credentials for browser or mobile clients.
- Use `/v1/realtime/calls` when establishing WebRTC sessions.
- Update session and event shapes for the GA interface. In particular, set `session.type`, move output audio configuration under `session.audio.output`, and use the newer response event names like `response.output_text.delta`, `response.output_audio.delta`, and `response.output_audio_transcript.delta`.
- If you are moving a speech-to-speech app forward, start from the [Voice agents](https://developers.openai.com/api/docs/guides/voice-agents) guide. If you are moving a transcription workflow forward, use [Realtime transcription](https://developers.openai.com/api/docs/guides/realtime-transcription).
See the [Realtime client events reference](https://developers.openai.com/api/docs/api-reference/realtime_client_events), [Realtime sessions reference](https://developers.openai.com/api/docs/api-reference/realtime-sessions), and [Voice agents](https://developers.openai.com/api/docs/guides/voice-agents) guide for the current GA flow.
## Related guides
- [Realtime prompting guide](https://developers.openai.com/api/docs/guides/realtime-models-prompting): Prompt and tune Realtime voice models.
- [Managing conversations](https://developers.openai.com/api/docs/guides/realtime-conversations): Work with the Realtime session lifecycle.
- [Realtime translation](https://developers.openai.com/api/docs/guides/realtime-translation): Translate live speech with a dedicated translation session.
- [Realtime transcription](https://developers.openai.com/api/docs/guides/realtime-transcription): Stream live transcript deltas from audio.
- [Realtime with tools](https://developers.openai.com/api/docs/guides/realtime-mcp): Connect function tools, MCP servers, and connectors to a Realtime session.
- [Webhooks and server-side controls](https://developers.openai.com/api/docs/guides/realtime-server-controls): Control Realtime sessions from your server.
- [Managing costs](https://developers.openai.com/api/docs/guides/realtime-costs): Track and optimize Realtime API usage.
Use [Audio and speech](https://developers.openai.com/api/docs/guides/audio) for the core concepts behind
audio input, audio output, streaming, latency, transcripts, and speech
generation. Use this overview when you are ready to choose an implementation
path.
---
# Realtime API with SIP
[SIP](https://en.wikipedia.org/wiki/Session_Initiation_Protocol) is a
protocol used to make phone calls over the internet. With SIP and the
Realtime API you can direct incoming phone calls to the API.
## Overview
If you want to connect a phone number to the Realtime API,
use a SIP trunking provider (e.g., Twilio). This is a service that converts your phone call
to IP traffic. After you purchase a phone number from your SIP trunking
provider, follow the instructions below.
Start by creating a [webhook](https://developers.openai.com/api/docs/guides/webhooks) for incoming calls, through your **platform.openai.com** [settings](https://platform.openai.com/settings) > Project > **Webhooks**.
Then, point your SIP trunk at the OpenAI SIP endpoint, using the project ID
for which you configured the webhook, e.g., `sip:$PROJECT_ID@sip.api.openai.com;transport=tls`.
To find your `$PROJECT_ID`, visit [settings](https://platform.openai.com/settings) > Project > **General**. That page will display the project ID, which
will have a `proj_` prefix.
When OpenAI receives SIP traffic associated with your project,
your webhook will be fired. The event fired will be a
[`realtime.call.incoming`](https://developers.openai.com/api/docs/api-reference/webhook-events/realtime/call/incoming) event,
like the example below:
```
POST https://my_website.com/webhook_endpoint
user-agent: OpenAI/1.0 (+https://platform.openai.com/docs/webhooks)
content-type: application/json
webhook-id: wh_685342e6c53c8190a1be43f081506c52 # unique id for idempotency
webhook-timestamp: 1750287078 # timestamp of delivery attempt
webhook-signature: v1,K5oZfzN95Z9UVu1EsfQmfVNQhnkZ2pj9o9NDN/H/pI4= # signature to verify authenticity from OpenAI
{
"object": "event",
"id": "evt_685343a1381c819085d44c354e1b330e",
"type": "realtime.call.incoming",
"created_at": 1750287018, // Unix timestamp
"data": {
"call_id": "some_unique_id",
"sip_headers": [
{ "name": "From", "value": "sip:+142555512112@sip.example.com" },
{ "name": "To", "value": "sip:+18005551212@sip.example.com" },
{ "name": "Call-ID", "value": "03782086-4ce9-44bf-8b0d-4e303d2cc590"}
]
}
}
```
From this webhook, you can accept or reject the call, using the `call_id` value from the webhook.
When accepting the call, you'll provide the needed configuration
(instructions, voice, etc) for the Realtime API session.
Once established, you can set up a WebSocket and monitor the session as usual. The APIs to
accept, reject, monitor, refer, and hangup the call are documented below.
## Accept the call
Use the [Accept call endpoint](https://developers.openai.com/api/docs/api-reference/realtime-calls/accept-call) to
approve the inbound call and configure the realtime session that will answer it.
Send the same parameters you would send in a
[`create client secret`](https://developers.openai.com/api/docs/api-reference/realtime-sessions/create-realtime-client-secret)
request, i.e., ensure the realtime model, voice, tools, or instructions are set before bridging the
call to the model.
```bash
curl -X POST "https://api.openai.com/v1/realtime/calls/$CALL_ID/accept" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"type": "realtime",
"model": "gpt-realtime",
"instructions": "You are Alex, a friendly concierge for Example Corp."
}'
```
The request path must include the `call_id` from the
[`realtime.call.incoming`](https://developers.openai.com/api/docs/api-reference/webhook-events/realtime/call/incoming)
webhook, and every request requires the `Authorization` header shown above. The
endpoint returns `200 OK` once the SIP leg is ringing and the realtime session
is being established.
## Reject the call
Use the [Reject call endpoint](https://developers.openai.com/api/docs/api-reference/realtime-calls/reject-call) to
decline an invite when you do not want to handle the incoming call, (e.g., from
an unsupported country code.) Supply the `call_id` path parameter
and an optional SIP `status_code` (e.g., `486` to indicate "busy") in the JSON
body to control the response sent back to the carrier.
```bash
curl -X POST "https://api.openai.com/v1/realtime/calls/$CALL_ID/reject" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{"status_code": 486}'
```
If no status code is supplied the API uses `603 Decline` by default. A
successful request responds with `200 OK` after OpenAI delivers the SIP
response.
## Monitor call events
After you accept a call, open a WebSocket connection to the same session to
stream events and issue realtime commands. Note that when connecting to an existing
call using the `call_id` parameter, the `model` argument is not used (as it has already been configured
via the `accept` endpoint).
### WebSocket request
`GET wss://api.openai.com/v1/realtime?call_id={call_id}`
### Query parameters
| Parameter | Type | Description |
| --------- | ------ | ----------------------------------------------------- |
| `call_id` | string | Identifier from the `realtime.call.incoming` webhook. |
### Headers
- `Authorization: Bearer YOUR_API_KEY`
The WebSocket behaves exactly like any other Realtime API connection. Send
[`response.create`](https://developers.openai.com/api/docs/api-reference/realtime_client_events/response/create),
and other client events to control the call, and listen for server events to
track progress. See [Webhooks and server-side controls](https://developers.openai.com/api/docs/guides/realtime-server-controls)
for more information.
```javascript
const callId = "rtc_u1_9c6574da8b8a41a18da9308f4ad974ce";
const ws = new WebSocket(`wss://api.openai.com/v1/realtime?call_id=${callId}`, {
headers: {
Authorization: `Bearer ${process.env.OPENAI_API_KEY}`,
},
});
ws.on("open", () => {
ws.send(
JSON.stringify({
type: "response.create",
})
);
});
```
## Redirect the call
Transfer an active call using the
[Refer call endpoint](https://developers.openai.com/api/docs/api-reference/realtime-calls/refer-call). Provide the
`call_id` as well as the `target_uri` that should be placed in the SIP `Refer-To`
header (for example `tel:+14155550123` or `sip:agent@example.com`).
```bash
curl -X POST "https://api.openai.com/v1/realtime/calls/$CALL_ID/refer" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{"target_uri": "tel:+14155550123"}'
```
OpenAI returns `200 OK` once the REFER is relayed to your SIP provider. The
downstream system handles the rest of the call flow for the caller.
## Hang up the call
End the session with the [Hang up endpoint](https://developers.openai.com/api/docs/api-reference/realtime-calls/hangup-call)
when your application should disconnect the caller. This endpoint can be used to
terminate both SIP and WebRTC realtime sessions.
```bash
curl -X POST "https://api.openai.com/v1/realtime/calls/$CALL_ID/hangup" \
-H "Authorization: Bearer $OPENAI_API_KEY"
```
The API responds with `200 OK` when it starts tearing down the call.
## Dedicated SIP IP ranges
If you need to allowlist OpenAI SIP traffic. `sip.api.openai.com` does GeoIP routing, you
will be connected to the closest region.
- `13.79.45.80/28` for `northeurope`
- `23.98.140.64/28` for `southcentralus`
- `40.67.149.176/28` for `eastus2`
- `40.83.204.240/28` for `westus`
## Python example
The following is an example of a `realtime.call.incoming` handler. It accepts the call and then logs all the events from
the Realtime API.
Python
Python
```python
from flask import Flask, request, Response, jsonify, make_response
from openai import OpenAI, InvalidWebhookSignatureError
import asyncio
import json
import os
import requests
import time
import threading
import websockets
app = Flask(__name__)
client = OpenAI(
webhook_secret=os.environ["OPENAI_WEBHOOK_SECRET"]
)
AUTH_HEADER = {
"Authorization": "Bearer " + os.getenv("OPENAI_API_KEY")
}
call_accept = {
"type": "realtime",
"instructions": "You are a support agent.",
"model": "gpt-realtime-2",
}
response_create = {
"type": "response.create",
"response": {
"instructions": (
"Say to the user 'Thank you for calling, how can I help you'"
)
},
}
async def websocket_task(call_id):
try:
async with websockets.connect(
"wss://api.openai.com/v1/realtime?call_id=" + call_id,
additional_headers=AUTH_HEADER,
) as websocket:
await websocket.send(json.dumps(response_create))
while True:
response = await websocket.recv()
print(f"Received from WebSocket: {response}")
except Exception as e:
print(f"WebSocket error: {e}")
@app.route("/", methods=["POST"])
def webhook():
try:
event = client.webhooks.unwrap(request.data, request.headers)
if event.type == "realtime.call.incoming":
requests.post(
"https://api.openai.com/v1/realtime/calls/"
+ event.data.call_id
+ "/accept",
headers={**AUTH_HEADER, "Content-Type": "application/json"},
json=call_accept,
)
threading.Thread(
target=lambda: asyncio.run(
websocket_task(event.data.call_id)
),
daemon=True,
).start()
return Response(status=200)
except InvalidWebhookSignatureError as e:
print("Invalid signature", e)
return Response("Invalid signature", status=400)
if __name__ == "__main__":
app.run(port=8000)
```
## Next steps
Now that you've connected over SIP, use the left navigation or click into these pages to start building your realtime application.
- [Realtime prompting guide](https://developers.openai.com/api/docs/guides/realtime-models-prompting)
- [Managing conversations](https://developers.openai.com/api/docs/guides/realtime-conversations)
- [Webhooks and server-side controls](https://developers.openai.com/api/docs/guides/realtime-server-controls)
- [Managing costs](https://developers.openai.com/api/docs/guides/realtime-costs)
- [Realtime transcription](https://developers.openai.com/api/docs/guides/realtime-transcription)
### Additional Resources
- [JavaScript demo](https://hello-realtime.val.run/)
- [Connect the Realtime SIP Connector to Twilio Elastic SIP Trunking](https://www.twilio.com/en-us/blog/developers/tutorials/product/openai-realtime-api-elastic-sip-trunking)
---
# Realtime API with WebRTC
[WebRTC](https://webrtc.org/) is a powerful set of standard interfaces for building real-time applications. The OpenAI Realtime API supports connecting to realtime models through a WebRTC peer connection.
For browser-based speech-to-speech voice applications, we recommend starting with [Voice agents](https://developers.openai.com/api/docs/guides/voice-agents), which covers the Agents SDK's higher-level helpers and APIs for managing Realtime sessions. The WebRTC interface is powerful and flexible, but lower level than the Agents SDK.
When connecting to a Realtime model from the client (like a web browser or
mobile device), we recommend using WebRTC rather than WebSockets for more
consistent performance.
For more guidance on building user interfaces on top of WebRTC, [refer to the docs on MDN](https://developer.mozilla.org/en-US/docs/Web/API/WebRTC_API).
## Overview
The Realtime API supports two mechanisms for connecting to the Realtime API from the browser, either using ephemeral API keys ([generated via the OpenAI REST API](https://developers.openai.com/api/docs/api-reference/realtime-sessions)), or via the new unified interface. Generally, using the unified interface is simpler, but puts your application server in the critical path for session initialization.
### Connecting using the unified interface
The process for initializing a WebRTC connection using the unified interface is as follows (assuming a web browser client):
1. The browser makes a request to a developer-controlled server using the SDP data from its WebRTC peer connection.
2. The server combines that SDP with its session configuration in a multipart form and sends that to the OpenAI Realtime API, authenticating it with its [standard API key](https://platform.openai.com/settings/organization/api-keys).
#### Creating a session via the unified interface
To create a realtime API session via the unified interface, you will need to build a small server-side application (or integrate with an existing one) to make an request to `/v1/realtime/calls`. You will use a [standard API key](https://platform.openai.com/settings/organization/api-keys) to authenticate this request on your backend server.
Below is an example of a simple Node.js [express](https://expressjs.com/) server which creates a realtime API session:
```javascript
const app = express();
// Parse raw SDP payloads posted from the browser
app.use(express.text({ type: ["application/sdp", "text/plain"] }));
const sessionConfig = JSON.stringify({
type: "realtime",
model: "gpt-realtime",
audio: { output: { voice: "marin" } },
});
// An endpoint which creates a Realtime API session.
app.post("/session", async (req, res) => {
const fd = new FormData();
fd.set("sdp", req.body);
fd.set("session", sessionConfig);
try {
const r = await fetch("https://api.openai.com/v1/realtime/calls", {
method: "POST",
headers: {
Authorization: `Bearer ${process.env.OPENAI_API_KEY}`,
"OpenAI-Safety-Identifier": "hashed-user-id",
},
body: fd,
});
// Send back the SDP we received from the OpenAI REST API
const sdp = await r.text();
res.send(sdp);
} catch (error) {
console.error("Token generation error:", error);
res.status(500).json({ error: "Failed to generate token" });
}
});
app.listen(3000);
```
If your application assigns a [safety identifier](https://developers.openai.com/api/docs/guides/safety-best-practices#implement-safety-identifiers)
for each end user, include it as the `OpenAI-Safety-Identifier` header in this
server-side request. Use a stable, privacy-preserving value, such as a hashed
internal user ID. The header should be set by your trusted backend, not by the
browser.
#### Connecting to the server
In the browser, you can use standard WebRTC APIs to connect to the Realtime API via your application server. The client directly POSTs its SDP data to your server.
```javascript
// Create a peer connection
const pc = new RTCPeerConnection();
// Set up to play remote audio from the model
audioElement.current = document.createElement("audio");
audioElement.current.autoplay = true;
pc.ontrack = (e) => (audioElement.current.srcObject = e.streams[0]);
// Add local audio track for microphone input in the browser
const ms = await navigator.mediaDevices.getUserMedia({
audio: true,
});
pc.addTrack(ms.getTracks()[0]);
// Set up data channel for sending and receiving events
const dc = pc.createDataChannel("oai-events");
// Start the session using the Session Description Protocol (SDP)
const offer = await pc.createOffer();
await pc.setLocalDescription(offer);
const sdpResponse = await fetch("/session", {
method: "POST",
body: offer.sdp,
headers: {
"Content-Type": "application/sdp",
},
});
const answer = {
type: "answer",
sdp: await sdpResponse.text(),
};
await pc.setRemoteDescription(answer);
```
### Connecting using an ephemeral token
The process for initializing a WebRTC connection using an ephemeral API key is as follows (assuming a web browser client):
1. The browser makes a request to a developer-controlled server to mint an ephemeral API key.
1. The developer's server uses a [standard API key](https://platform.openai.com/settings/organization/api-keys) to request an ephemeral key from the [OpenAI REST API](https://developers.openai.com/api/docs/api-reference/realtime-sessions), and returns that new key to the browser.
1. The browser uses the ephemeral key to authenticate a session directly with the OpenAI Realtime API as a [WebRTC peer connection](https://developer.mozilla.org/en-US/docs/Web/API/RTCPeerConnection).
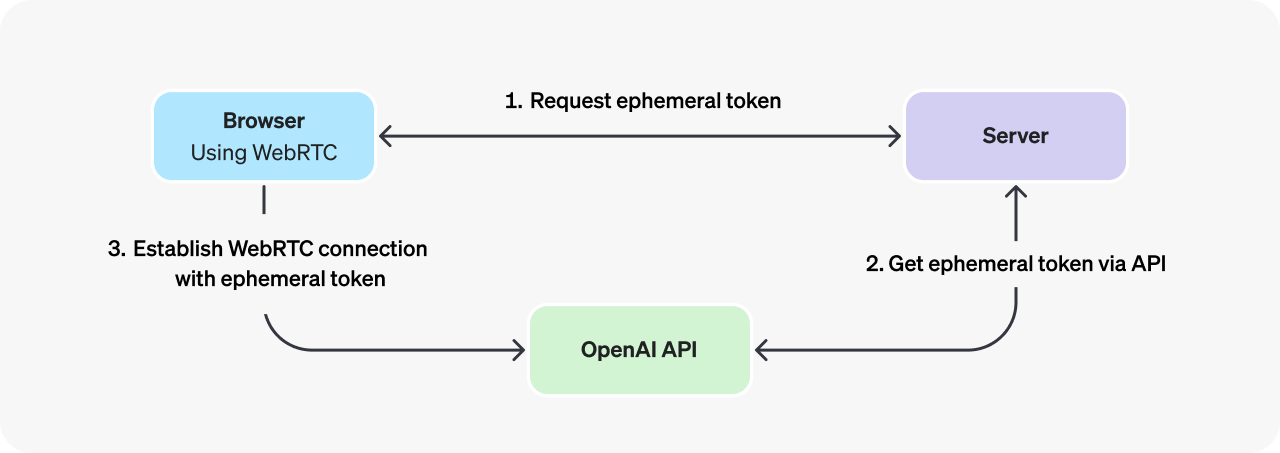
#### Creating an ephemeral token
To create an ephemeral token to use on the client-side, you will need to build a small server-side application (or integrate with an existing one) to make an [OpenAI REST API](https://developers.openai.com/api/docs/api-reference/realtime-sessions) request for an ephemeral key. You will use a [standard API key](https://platform.openai.com/settings/organization/api-keys) to authenticate this request on your backend server.
Below is an example of a simple Node.js [express](https://expressjs.com/) server which mints an ephemeral API key using the REST API:
```javascript
const app = express();
const sessionConfig = JSON.stringify({
session: {
type: "realtime",
model: "gpt-realtime",
audio: {
output: {
voice: "marin",
},
},
},
});
// An endpoint which would work with the client code above - it returns
// the contents of a REST API request to this protected endpoint
app.get("/token", async (req, res) => {
try {
const response = await fetch(
"https://api.openai.com/v1/realtime/client_secrets",
{
method: "POST",
headers: {
Authorization: `Bearer ${apiKey}`,
"Content-Type": "application/json",
"OpenAI-Safety-Identifier": "hashed-user-id",
},
body: sessionConfig,
}
);
const data = await response.json();
res.json(data);
} catch (error) {
console.error("Token generation error:", error);
res.status(500).json({ error: "Failed to generate token" });
}
});
app.listen(3000);
```
You can create a server endpoint like this one on any platform that can send and receive HTTP requests. Just ensure that **you only use standard OpenAI API keys on the server, not in the browser.**
When using ephemeral tokens, set `OpenAI-Safety-Identifier` on the server-side
request that creates the client secret. The Realtime API binds the identifier to
the resulting ephemeral token, so the browser does not need to send the safety
identifier when it later connects with that token.
#### Connecting to the server
In the browser, you can use standard WebRTC APIs to connect to the Realtime API with an ephemeral token. The client first fetches a token from your server endpoint, and then POSTs its SDP data (with the ephemeral token) to the Realtime API.
```javascript
// Get a session token for OpenAI Realtime API
const tokenResponse = await fetch("/token");
const data = await tokenResponse.json();
const EPHEMERAL_KEY = data.value;
// Create a peer connection
const pc = new RTCPeerConnection();
// Set up to play remote audio from the model
audioElement.current = document.createElement("audio");
audioElement.current.autoplay = true;
pc.ontrack = (e) => (audioElement.current.srcObject = e.streams[0]);
// Add local audio track for microphone input in the browser
const ms = await navigator.mediaDevices.getUserMedia({
audio: true,
});
pc.addTrack(ms.getTracks()[0]);
// Set up data channel for sending and receiving events
const dc = pc.createDataChannel("oai-events");
// Start the session using the Session Description Protocol (SDP)
const offer = await pc.createOffer();
await pc.setLocalDescription(offer);
const sdpResponse = await fetch("https://api.openai.com/v1/realtime/calls", {
method: "POST",
body: offer.sdp,
headers: {
Authorization: `Bearer ${EPHEMERAL_KEY}`,
"Content-Type": "application/sdp",
},
});
const answer = {
type: "answer",
sdp: await sdpResponse.text(),
};
await pc.setRemoteDescription(answer);
```
## Sending and receiving events
Realtime API sessions are managed using a combination of [client-sent events](https://developers.openai.com/api/docs/api-reference/realtime_client_events/session) emitted by you as the developer, and [server-sent events](https://developers.openai.com/api/docs/api-reference/realtime_server_events/error) created by the Realtime API to indicate session lifecycle events.
When connecting to a Realtime model via WebRTC, you don't have to handle audio events from the model in the same granular way you must with [WebSockets](https://developers.openai.com/api/docs/guides/realtime-websocket). The WebRTC peer connection object, if configured as above, will do all that work for you.
To send and receive other client and server events, you can use the WebRTC peer connection's [data channel](https://developer.mozilla.org/en-US/docs/Web/API/WebRTC_API/Using_data_channels).
```javascript
// This is the data channel set up in the browser code above...
const dc = pc.createDataChannel("oai-events");
// Listen for server events
dc.addEventListener("message", (e) => {
const event = JSON.parse(e.data);
console.log(event);
});
// Send client events
const event = {
type: "conversation.item.create",
item: {
type: "message",
role: "user",
content: [
{
type: "input_text",
text: "hello there!",
},
],
},
};
dc.send(JSON.stringify(event));
```
To learn more about managing Realtime conversations, refer to the [Realtime conversations guide](https://developers.openai.com/api/docs/guides/realtime-conversations).
Check out the WebRTC Realtime API in this light weight example app.
---
# Realtime API with WebSocket
[WebSockets](https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API) are a broadly supported API for realtime data transfer, and a great choice for connecting to the OpenAI Realtime API in server-to-server applications. For browser and mobile clients, we recommend connecting via [WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc).
In a server-to-server integration with Realtime, your backend system will connect via WebSocket directly to the Realtime API. You can use a [standard API key](https://platform.openai.com/settings/organization/api-keys) to authenticate this connection, since the token will only be available on your secure backend server.

## Connect via WebSocket
Below are several examples of connecting via WebSocket to the Realtime API. In addition to using the WebSocket URL below, you will also need to pass an authentication header using your OpenAI API key. If your application assigns [safety identifiers](https://developers.openai.com/api/docs/guides/safety-best-practices#implement-safety-identifiers), pass the stable, privacy-preserving identifier for the end user in the `OpenAI-Safety-Identifier` header.
It is possible to use WebSocket in browsers with an ephemeral API token as shown in the [WebRTC connection guide](https://developers.openai.com/api/docs/guides/realtime-webrtc), but if you are connecting from a client like a browser or mobile app, WebRTC will be a more robust solution in most cases.
ws module (Node.js)
Connect using the ws module (Node.js)
```javascript
import WebSocket from "ws";
const url = "wss://api.openai.com/v1/realtime?model=gpt-realtime-2";
const ws = new WebSocket(url, {
headers: {
Authorization: "Bearer " + process.env.OPENAI_API_KEY,
"OpenAI-Safety-Identifier": "hashed-user-id",
},
});
ws.on("open", function open() {
console.log("Connected to server.");
});
ws.on("message", function incoming(message) {
console.log(JSON.parse(message.toString()));
});
```
websocket-client (Python)
Connect with websocket-client (Python)
```python
# example requires websocket-client library:
# pip install websocket-client
import os
import json
import websocket
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
url = "wss://api.openai.com/v1/realtime?model=gpt-realtime-2"
headers = [
"Authorization: Bearer " + OPENAI_API_KEY,
"OpenAI-Safety-Identifier: hashed-user-id",
]
def on_open(ws):
print("Connected to server.")
def on_message(ws, message):
data = json.loads(message)
print("Received event:", json.dumps(data, indent=2))
ws = websocket.WebSocketApp(
url,
header=headers,
on_open=on_open,
on_message=on_message,
)
ws.run_forever()
```
WebSocket (browsers)
Connect with standard WebSocket (browsers)
```javascript
/*
Note that in client-side environments like web browsers, we recommend
using WebRTC instead. It is possible, however, to use the standard
WebSocket interface in browser-like environments like Deno and
Cloudflare Workers.
*/
const ws = new WebSocket(
"wss://api.openai.com/v1/realtime?model=gpt-realtime-2",
[
"realtime",
// Auth
"openai-insecure-api-key." + OPENAI_API_KEY,
// Optional
"openai-organization." + OPENAI_ORG_ID,
"openai-project." + OPENAI_PROJECT_ID,
]
);
ws.on("open", function open() {
console.log("Connected to server.");
});
ws.on("message", function incoming(message) {
console.log(message.data);
});
```
## Sending and receiving events
Realtime API sessions are managed using a combination of [client-sent events](https://developers.openai.com/api/docs/api-reference/realtime_client_events/session) emitted by you as the developer, and [server-sent events](https://developers.openai.com/api/docs/api-reference/realtime_server_events/error) created by the Realtime API to indicate session lifecycle events.
Over a WebSocket, you will both send and receive JSON-serialized events as strings of text, as in this Node.js example below (the same principles apply for other WebSocket libraries):
```javascript
const url = "wss://api.openai.com/v1/realtime?model=gpt-realtime";
const ws = new WebSocket(url, {
headers: {
Authorization: "Bearer " + process.env.OPENAI_API_KEY,
"OpenAI-Safety-Identifier": "hashed-user-id",
},
});
ws.on("open", function open() {
console.log("Connected to server.");
// Send client events over the WebSocket once connected
ws.send(
JSON.stringify({
type: "session.update",
session: {
type: "realtime",
instructions: "Be extra nice today!",
},
})
);
});
// Listen for and parse server events
ws.on("message", function incoming(message) {
console.log(JSON.parse(message.toString()));
});
```
The WebSocket interface is perhaps the lowest-level interface available to interact with a Realtime model, where you will be responsible for both sending and processing Base64-encoded audio chunks over the socket connection.
To learn how to send and receive audio over Websockets, refer to the [Realtime conversations guide](https://developers.openai.com/api/docs/guides/realtime-conversations#handling-audio-with-websockets).
---
# Realtime conversations
Once you have connected to the Realtime API through either [WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc) or [WebSocket](https://developers.openai.com/api/docs/guides/realtime-websocket), you can call a Realtime model (such as [gpt-realtime-2](https://developers.openai.com/api/docs/models/gpt-realtime-2)) to have speech-to-speech conversations. Doing so will require you to **send client events** to initiate actions, and **listen for server events** to respond to actions taken by the Realtime API.
This guide will walk through the event flows required to use model capabilities like audio and text generation, image input, and function calling, and how to think about the state of a Realtime Session.
If you do not need to have a conversation with the model, meaning you don't
expect any response, you can use the Realtime API in [transcription
mode](https://developers.openai.com/api/docs/guides/realtime-transcription).
## Realtime speech-to-speech sessions
A Realtime Session is a stateful interaction between the model and a connected client. The key components of the session are:
- The **Session** object, which controls the parameters of the interaction, like the model being used, the voice used to generate output, and other configuration.
- A **Conversation**, which represents user input Items and model output Items generated during the current session.
- **Responses**, which are model-generated audio or text Items that are added to the Conversation.
**Input audio buffer and WebSockets**
If you are using WebRTC, much of the media handling required to send and receive audio from the model is assisted by WebRTC APIs.
If you are using WebSockets for audio, you will need to manually interact with the **input audio buffer** by sending audio to the server, sent with JSON events with base64-encoded audio.
All these components together make up a Realtime Session. You will use client events to update the state of the session, and listen for server events to react to state changes within the session.
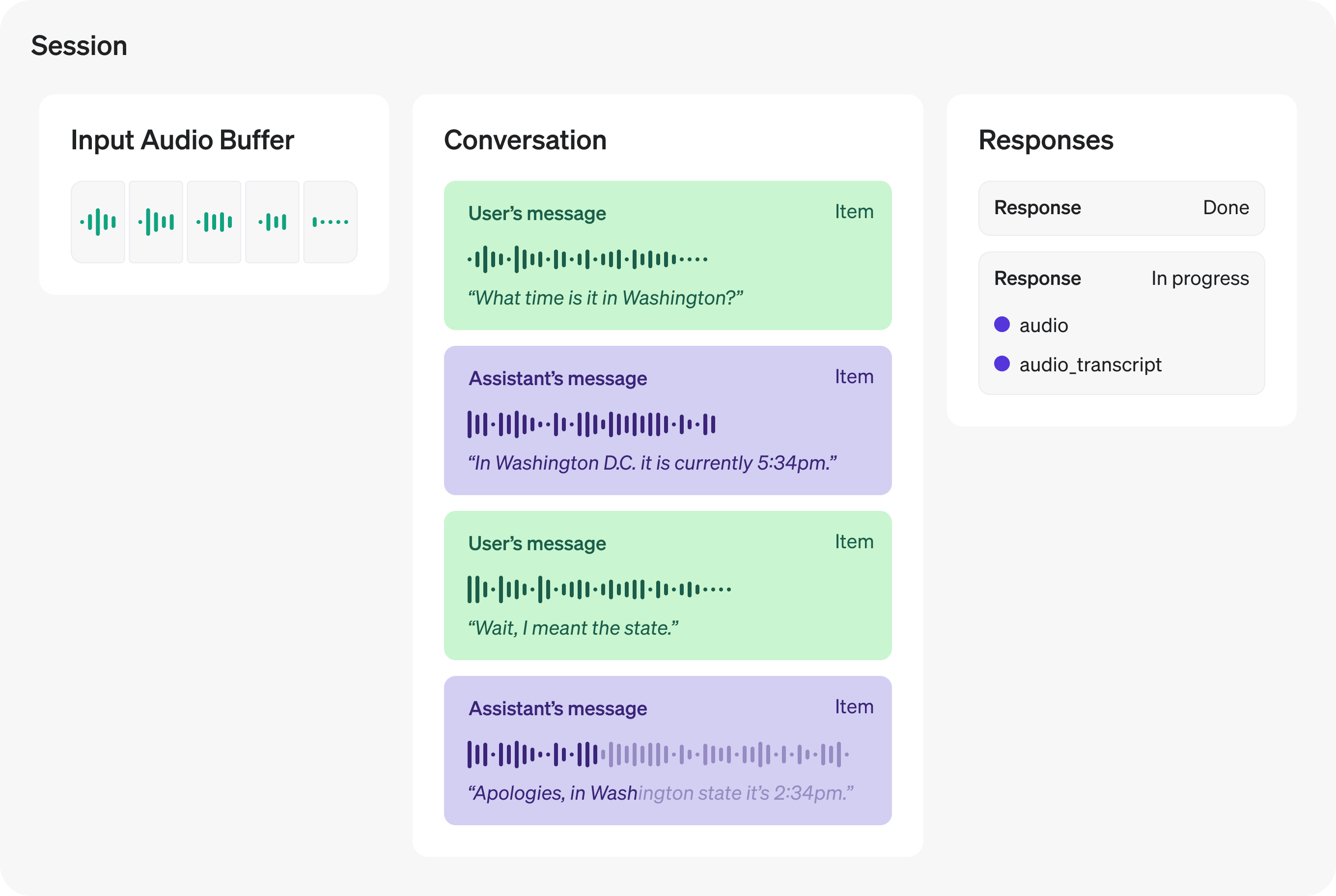
## Session lifecycle events
After initiating a session via either [WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc) or [WebSockets](https://developers.openai.com/api/docs/guides/realtime-websockets), the server will send a [`session.created`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/session/created) event indicating the session is ready. On the client, you can update the current session configuration with the [`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update) event. Most session properties can be updated at any time, except for the `voice` the model uses for audio output, after the model has responded with audio once during the session. The maximum duration of a Realtime session is **60 minutes**.
The following example shows updating the session with a `session.update` client event. See the [WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc#sending-and-receiving-events) or [WebSocket](https://developers.openai.com/api/docs/guides/realtime-websocket#sending-and-receiving-events) guide for more on sending client events over these channels.
Update the system instructions used by the model in this session
```javascript
const event = {
type: "session.update",
session: {
type: "realtime",
model: "gpt-realtime-2",
// Lock the output to audio (set to ["text"] if you want text without audio)
output_modalities: ["audio"],
audio: {
input: {
format: {
type: "audio/pcm",
rate: 24000,
},
turn_detection: {
type: "semantic_vad"
}
},
output: {
format: {
type: "audio/pcm",
},
voice: "marin",
}
},
// Use a server-stored prompt by ID. Optionally pin a version and pass variables.
prompt: {
id: "pmpt_123", // your stored prompt ID
version: "89", // optional: pin a specific version
variables: {
city: "Paris" // example variable used by your prompt
}
},
// You can still set direct session fields; these override prompt fields if they overlap:
instructions: "Speak clearly and briefly. Confirm understanding before taking actions."
},
};
// WebRTC data channel and WebSocket both have .send()
dataChannel.send(JSON.stringify(event));
```
```python
event = {
"type": "session.update",
session: {
type: "realtime",
model: "gpt-realtime-2",
# Lock the output to audio (add "text" if you also want text)
output_modalities: ["audio"],
audio: {
input: {
format: {
type: "audio/pcm",
rate: 24000,
},
turn_detection: {
type: "semantic_vad"
}
},
output: {
format: {
type: "audio/pcmu",
},
voice: "marin",
}
},
# Use a server-stored prompt by ID. Optionally pin a version and pass variables.
prompt: {
id: "pmpt_123", // your stored prompt ID
version: "89", // optional: pin a specific version
variables: {
city: "Paris" // example variable used by your prompt
}
},
# You can still set direct session fields; these override prompt fields if they overlap:
instructions: "Speak clearly and briefly. Confirm understanding before taking actions."
}
}
ws.send(json.dumps(event))
```
When the session has been updated, the server will emit a [`session.updated`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/session/updated) event with the new state of the session.
| Related client events |
Related server events |
|
[`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update)
|
[`session.created`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/session/created)
[`session.updated`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/session/updated)
|
## Text inputs and outputs
To generate text with a Realtime model, you can add text inputs to the current conversation, ask the model to generate a response, and listen for server-sent events indicating the progress of the model's response. In order to generate text, the [session must be configured](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update) with the `text` modality (this is true by default).
Create a new text conversation item using the [`conversation.item.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/conversation/item/create) client event. This is similar to sending a [user message (prompt) in Chat Completions](https://developers.openai.com/api/docs/guides/text-generation) in the REST API.
Create a conversation item with user input
```javascript
const event = {
type: "conversation.item.create",
item: {
type: "message",
role: "user",
content: [
{
type: "input_text",
text: "What Prince album sold the most copies?",
}
]
},
};
// WebRTC data channel and WebSocket both have .send()
dataChannel.send(JSON.stringify(event));
```
```python
event = {
"type": "conversation.item.create",
"item": {
"type": "message",
"role": "user",
"content": [
{
"type": "input_text",
"text": "What Prince album sold the most copies?",
}
]
}
}
ws.send(json.dumps(event))
```
After adding the user message to the conversation, send the [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create) event to initiate a response from the model. If both audio and text are enabled for the current session, the model will respond with both audio and text content. If you'd like to generate text only, you can specify that when sending the `response.create` client event, as shown below.
Generate a text-only response
```javascript
const event = {
type: "response.create",
response: {
output_modalities: [ "text" ]
},
};
// WebRTC data channel and WebSocket both have .send()
dataChannel.send(JSON.stringify(event));
```
```python
event = {
"type": "response.create",
"response": {
"output_modalities": [ "text" ]
}
}
ws.send(json.dumps(event))
```
When the response is completely finished, the server will emit the [`response.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/done) event. This event will contain the full text generated by the model, as shown below.
Listen for response.done to see the final results
```javascript
function handleEvent(e) {
const serverEvent = JSON.parse(e.data);
if (serverEvent.type === "response.done") {
console.log(serverEvent.response.output[0]);
}
}
// Listen for server messages (WebRTC)
dataChannel.addEventListener("message", handleEvent);
// Listen for server messages (WebSocket)
// ws.on("message", handleEvent);
```
```python
def on_message(ws, message):
server_event = json.loads(message)
if server_event.type == "response.done":
print(server_event.response.output[0])
```
While the model response is being generated, the server will emit a number of lifecycle events during the process. You can listen for these events, such as [`response.output_text.delta`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_text/delta), to provide realtime feedback to users as the response is generated. A full listing of the events emitted by there server are found below under **related server events**. They are provided in the rough order of when they are emitted, along with relevant client-side events for text generation.
| Related client events |
Related server events |
|
[`conversation.item.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/conversation/item/create)
[`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create)
|
[`conversation.item.added`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/conversation/item/added)
[`conversation.item.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/conversation/item/done)
[`response.created`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/created)
[`response.output_item.added`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_item/added)
[`response.content_part.added`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/content_part/added)
[`response.output_text.delta`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_text/delta)
[`response.output_text.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_text/done)
[`response.content_part.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/content_part/done)
[`response.output_item.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_item/done)
[`response.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/done)
[`rate_limits.updated`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/rate_limits/updated)
|
## Audio inputs and outputs
One of the most powerful features of the Realtime API is voice-to-voice interaction with the model, without an intermediate text-to-speech or speech-to-text step. This enables lower latency for voice interfaces, and gives the model more data to work with around the tone and inflection of voice input.
### Voice options
Realtime sessions can be configured to use one of several built‑in voices when producing audio output. You can set the `voice` on session creation (or on a `response.create`) to control how the model sounds. Current voice options are `alloy`, `ash`, `ballad`, `coral`, `echo`, `sage`, `shimmer`, `verse`, `marin`, and `cedar`. Once the model has emitted audio in a session, the `voice` cannot be modified for that session. For best quality, we recommend using `marin` or `cedar`.
### Handling audio with WebRTC
If you are connecting to the Realtime API using WebRTC, the Realtime API is acting as a [peer connection](https://developer.mozilla.org/en-US/docs/Web/API/RTCPeerConnection) to your client. Audio output from the model is delivered to your client as a [remote media stream](hhttps://developer.mozilla.org/en-US/docs/Web/API/MediaStream). Audio input to the model is collected using audio devices ([`getUserMedia`](https://developer.mozilla.org/en-US/docs/Web/API/MediaDevices/getUserMedia)), and media streams are added as tracks to to the peer connection.
The example code from the [WebRTC connection guide](https://developers.openai.com/api/docs/guides/realtime-webrtc) shows a basic example of configuring both local and remote audio using browser APIs:
```javascript
// Create a peer connection
const pc = new RTCPeerConnection();
// Set up to play remote audio from the model
const audioEl = document.createElement("audio");
audioEl.autoplay = true;
pc.ontrack = (e) => (audioEl.srcObject = e.streams[0]);
// Add local audio track for microphone input in the browser
const ms = await navigator.mediaDevices.getUserMedia({
audio: true,
});
pc.addTrack(ms.getTracks()[0]);
```
The snippet above enables simple interaction with the Realtime API, but there's much more that can be done. For more examples of different kinds of user interfaces, check out the [WebRTC samples](https://github.com/webrtc/samples) repository. Live demos of these samples can also be [found here](https://webrtc.github.io/samples/).
Using [media captures and streams](https://developer.mozilla.org/en-US/docs/Web/API/Media_Capture_and_Streams_API) in the browser enables you to do things like mute and unmute microphones, select which device to collect input from, and more.
### Client and server events for audio in WebRTC
By default, WebRTC clients don't need to send any client events to the Realtime API before sending audio inputs. Once a local audio track is added to the peer connection, your users can just start talking!
However, WebRTC clients still receive a number of server-sent lifecycle events as audio is moving back and forth between client and server over the peer connection. Examples include:
- When input is sent over the local media track, you will receive [`input_audio_buffer.speech_started`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/input_audio_buffer/speech_started) events from the server.
- When local audio input stops, you'll receive the [`input_audio_buffer.speech_stopped`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/input_audio_buffer/speech_started) event.
- You'll receive [delta events for the in-progress audio transcript](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_audio_transcript/delta).
- You'll receive a [`response.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/done) event when the model has transcribed and completed sending a response.
Manipulating WebRTC APIs for media streams may give you all the control you need. However, it may occasionally be necessary to use lower-level interfaces for audio input and output. Refer to the WebSockets section below for more information and a listing of events required for granular audio input handling.
### Handling audio with WebSockets
When sending and receiving audio over a WebSocket, you will have a bit more work to do in order to send media from the client, and receive media from the server. Below, you'll find a table describing the flow of events during a WebSocket session that are necessary to send and receive audio over the WebSocket.
The events below are given in lifecycle order, though some events (like the `delta` events) may happen concurrently.
| Lifecycle stage |
Client events |
Server events |
| Session initialization |
[`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update)
|
[`session.created`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/session/created)
[`session.updated`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/session/updated)
|
| User audio input |
[`conversation.item.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/conversation/item/create)
(send whole audio message)
[`input_audio_buffer.append`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/input_audio_buffer/append)
(stream audio in chunks)
[`input_audio_buffer.commit`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/input_audio_buffer/commit)
(used when VAD is disabled)
[`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create)
(used when VAD is disabled)
|
[`input_audio_buffer.speech_started`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/input_audio_buffer/speech_started)
[`input_audio_buffer.speech_stopped`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/input_audio_buffer/speech_stopped)
[`input_audio_buffer.committed`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/input_audio_buffer/committed)
|
| Server audio output |
[`input_audio_buffer.clear`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/input_audio_buffer/clear)
(used when VAD is disabled)
|
[`conversation.item.added`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/conversation/item/added)
[`conversation.item.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/conversation/item/done)
[`response.created`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/created)
[`response.output_item.created`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_item/created)
[`response.content_part.added`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/content_part/added)
[`response.output_audio.delta`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_audio/delta)
[`response.output_audio.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_audio/done)
[`response.output_audio_transcript.delta`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_audio_transcript/delta)
[`response.output_audio_transcript.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_audio_transcript/done)
[`response.output_text.delta`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_text/delta)
[`response.output_text.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_text/done)
[`response.content_part.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/content_part/done)
[`response.output_item.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_item/done)
[`response.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/done)
[`rate_limits.updated`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/rate_limits/updated)
|
### Streaming audio input to the server
To stream audio input to the server, you can use the [`input_audio_buffer.append`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/input_audio_buffer/append) client event. This event requires you to send chunks of **Base64-encoded audio bytes** to the Realtime API over the socket. Each chunk cannot exceed 15 MB in size.
The format of the input chunks can be configured either for the entire session, or per response.
- Session: `session.input_audio_format` in [`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update)
- Response: `response.input_audio_format` in [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create)
Append audio input bytes to the conversation
```javascript
import fs from 'fs';
import decodeAudio from 'audio-decode';
// Converts Float32Array of audio data to PCM16 ArrayBuffer
function floatTo16BitPCM(float32Array) {
const buffer = new ArrayBuffer(float32Array.length * 2);
const view = new DataView(buffer);
let offset = 0;
for (let i = 0; i < float32Array.length; i++, offset += 2) {
let s = Math.max(-1, Math.min(1, float32Array[i]));
view.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7fff, true);
}
return buffer;
}
// Converts a Float32Array to base64-encoded PCM16 data
base64EncodeAudio(float32Array) {
const arrayBuffer = floatTo16BitPCM(float32Array);
let binary = '';
let bytes = new Uint8Array(arrayBuffer);
const chunkSize = 0x8000; // 32KB chunk size
for (let i = 0; i < bytes.length; i += chunkSize) {
let chunk = bytes.subarray(i, i + chunkSize);
binary += String.fromCharCode.apply(null, chunk);
}
return btoa(binary);
}
// Fills the audio buffer with the contents of three files,
// then asks the model to generate a response.
const files = [
'./path/to/sample1.wav',
'./path/to/sample2.wav',
'./path/to/sample3.wav'
];
for (const filename of files) {
const audioFile = fs.readFileSync(filename);
const audioBuffer = await decodeAudio(audioFile);
const channelData = audioBuffer.getChannelData(0);
const base64Chunk = base64EncodeAudio(channelData);
ws.send(JSON.stringify({
type: 'input_audio_buffer.append',
audio: base64Chunk
}));
});
ws.send(JSON.stringify({type: 'input_audio_buffer.commit'}));
ws.send(JSON.stringify({type: 'response.create'}));
```
```python
import base64
import json
import struct
import soundfile as sf
from websocket import create_connection
# ... create websocket-client named ws ...
def float_to_16bit_pcm(float32_array):
clipped = [max(-1.0, min(1.0, x)) for x in float32_array]
pcm16 = b''.join(struct.pack(' 1 else data
base64_chunk = base64_encode_audio(channel_data)
# Send the client event
event = {
"type": "input_audio_buffer.append",
"audio": base64_chunk
}
ws.send(json.dumps(event))
```
### Send full audio messages
It is also possible to create conversation messages that are full audio recordings. Use the [`conversation.item.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/conversation/item/create) client event to create messages with `input_audio` content.
Create full audio input conversation items
```javascript
const fullAudio = "";
const event = {
type: "conversation.item.create",
item: {
type: "message",
role: "user",
content: [
{
type: "input_audio",
audio: fullAudio,
},
],
},
};
// WebRTC data channel and WebSocket both have .send()
dataChannel.send(JSON.stringify(event));
```
```python
fullAudio = ""
event = {
"type": "conversation.item.create",
"item": {
"type": "message",
"role": "user",
"content": [
{
"type": "input_audio",
"audio": fullAudio,
}
],
},
}
ws.send(json.dumps(event))
```
### Working with audio output from a WebSocket
**To play output audio back on a client device like a web browser, we recommend using WebRTC rather than WebSockets**. WebRTC will be more robust sending media to client devices over uncertain network conditions.
But to work with audio output in server-to-server applications using a WebSocket, you will need to listen for [`response.output_audio.delta`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_audio/delta) events containing the Base64-encoded chunks of audio data from the model. You will either need to buffer these chunks and write them out to a file, or maybe immediately stream them to another source like [a phone call with Twilio](https://www.twilio.com/en-us/blog/twilio-openai-realtime-api-launch-integration).
Note that the [`response.output_audio.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_audio/done) and [`response.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/done) events won't actually contain audio data in them - just audio content transcriptions. To get the actual bytes, you'll need to listen for the [`response.output_audio.delta`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_audio/delta) events.
The format of the output chunks can be configured either for the entire session, or per response.
- Session: `session.audio.output.format` in [`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update)
- Response: `response.audio.output.format` in [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create)
Listen for response.output_audio.delta events
```javascript
function handleEvent(e) {
const serverEvent = JSON.parse(e.data);
if (serverEvent.type === "response.audio.delta") {
// Access Base64-encoded audio chunks
// console.log(serverEvent.delta);
}
}
// Listen for server messages (WebSocket)
ws.on("message", handleEvent);
```
```python
def on_message(ws, message):
server_event = json.loads(message)
if server_event.type == "response.audio.delta":
# Access Base64-encoded audio chunks:
# print(server_event.delta)
```
## Image inputs
`gpt-realtime-2` and `gpt-realtime` also support image input. You can attach an image as a content part in a user message, and the model can incorporate what’s in the image when it responds.
Add an image to the conversation
```javascript
const base64Image = "";
const event = {
type: "conversation.item.create",
item: {
type: "message",
role: "user",
content: [
{
type: "input_image",
image_url: \`data:image/{format};base64,\${base64Image}\`,
},
],
},
};
// WebRTC data channel and WebSocket both have .send()
dataChannel.send(JSON.stringify(event));
```
## Voice activity detection
By default, Realtime sessions have **voice activity detection (VAD)** enabled, which means the API will determine when the user has started or stopped speaking and respond automatically.
Read more about how to configure VAD in our [voice activity detection](https://developers.openai.com/api/docs/guides/realtime-vad) guide.
### Disable VAD
VAD can be disabled by setting `turn_detection` to `null` with the [`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update) client event. This can be useful for interfaces where you would like to take granular control over audio input, like [push to talk](https://en.wikipedia.org/wiki/Push-to-talk) interfaces.
When VAD is disabled, the client will have to manually emit some additional client events to trigger audio responses:
- Manually send [`input_audio_buffer.commit`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/input_audio_buffer/commit), which will create a new user input item for the conversation.
- Manually send [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create) to trigger an audio response from the model.
- Send [`input_audio_buffer.clear`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/input_audio_buffer/clear) before beginning a new user input.
### Keep VAD, but disable automatic responses
If you would like to keep VAD mode enabled, but would just like to retain the ability to manually decide when a response is generated, you can set `turn_detection.interrupt_response` and `turn_detection.create_response` to `false` with the [`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update) client event. This will retain all the behavior of VAD but not automatically create new Responses. Clients can trigger these manually with a [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create) event.
This can be useful for moderation or input validation or RAG patterns, where you're comfortable trading a bit more latency in the interaction for control over inputs.
## Create responses outside the default conversation
By default, all responses generated during a session are added to the session's conversation state (the "default conversation"). However, you may want to generate model responses outside the context of the session's default conversation, or have multiple responses generated concurrently. You might also want to have more granular control over which conversation items are considered while the model generates a response (e.g. only the last N number of turns).
Generating "out-of-band" responses which are not added to the default conversation state is possible by setting the `response.conversation` field to the string `none` when creating a response with the [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create) client event.
When creating an out-of-band response, you will probably also want some way to identify which server-sent events pertain to this response. You can provide `metadata` for your model response that will help you identify which response is being generated for this client-sent event.
Create an out-of-band model response
```javascript
const prompt = \`
Analyze the conversation so far. If it is related to support, output
"support". If it is related to sales, output "sales".
\`;
const event = {
type: "response.create",
response: {
// Setting to "none" indicates the response is out of band
// and will not be added to the default conversation
conversation: "none",
// Set metadata to help identify responses sent back from the model
metadata: { topic: "classification" },
// Set any other available response fields
output_modalities: [ "text" ],
instructions: prompt,
},
};
// WebRTC data channel and WebSocket both have .send()
dataChannel.send(JSON.stringify(event));
```
```python
prompt = """
Analyze the conversation so far. If it is related to support, output
"support". If it is related to sales, output "sales".
"""
event = {
"type": "response.create",
"response": {
# Setting to "none" indicates the response is out of band,
# and will not be added to the default conversation
"conversation": "none",
# Set metadata to help identify responses sent back from the model
"metadata": { "topic": "classification" },
# Set any other available response fields
"output_modalities": [ "text" ],
"instructions": prompt,
},
}
ws.send(json.dumps(event))
```
Now, when you listen for the [`response.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/done) server event, you can identify the result of your out-of-band response.
Create an out-of-band model response
```javascript
function handleEvent(e) {
const serverEvent = JSON.parse(e.data);
if (
serverEvent.type === "response.done" &&
serverEvent.response.metadata?.topic === "classification"
) {
// this server event pertained to our OOB model response
console.log(serverEvent.response.output[0]);
}
}
// Listen for server messages (WebRTC)
dataChannel.addEventListener("message", handleEvent);
// Listen for server messages (WebSocket)
// ws.on("message", handleEvent);
```
```python
def on_message(ws, message):
server_event = json.loads(message)
topic = ""
# See if metadata is present
try:
topic = server_event.response.metadata.topic
except AttributeError:
print("topic not set")
if server_event.type == "response.done" and topic == "classification":
# this server event pertained to our OOB model response
print(server_event.response.output[0])
```
### Create a custom context for responses
You can also construct a custom context that the model will use to generate a response, outside the default/current conversation. This can be done using the `input` array on a [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create) client event. You can use new inputs, or reference existing input items in the conversation by ID.
Listen for out-of-band model response with custom context
```javascript
const event = {
type: "response.create",
response: {
conversation: "none",
metadata: { topic: "pizza" },
output_modalities: [ "text" ],
// Create a custom input array for this request with whatever context
// is appropriate
input: [
// potentially include existing conversation items:
{
type: "item_reference",
id: "some_conversation_item_id"
},
{
type: "message",
role: "user",
content: [
{
type: "input_text",
text: "Is it okay to put pineapple on pizza?",
},
],
},
],
},
};
// WebRTC data channel and WebSocket both have .send()
dataChannel.send(JSON.stringify(event));
```
```python
event = {
"type": "response.create",
"response": {
"conversation": "none",
"metadata": { "topic": "pizza" },
"output_modalities": [ "text" ],
# Create a custom input array for this request with whatever
# context is appropriate
"input": [
# potentially include existing conversation items:
{
"type": "item_reference",
"id": "some_conversation_item_id"
},
# include new content as well
{
"type": "message",
"role": "user",
"content": [
{
"type": "input_text",
"text": "Is it okay to put pineapple on pizza?",
}
],
}
],
},
}
ws.send(json.dumps(event))
```
### Create responses with no context
You can also insert responses into the default conversation, ignoring all other instructions and context. Do this by setting `input` to an empty array.
Insert no-context model responses into the default conversation
```javascript
const prompt = \`
Say exactly the following:
I'm a little teapot, short and stout!
This is my handle, this is my spout!
\`;
const event = {
type: "response.create",
response: {
// An empty input array removes existing context
input: [],
instructions: prompt,
},
};
// WebRTC data channel and WebSocket both have .send()
dataChannel.send(JSON.stringify(event));
```
```python
prompt = """
Say exactly the following:
I'm a little teapot, short and stout!
This is my handle, this is my spout!
"""
event = {
"type": "response.create",
"response": {
# An empty input array removes all prior context
"input": [],
"instructions": prompt,
},
}
ws.send(json.dumps(event))
```
## Function calling
The Realtime models also support **function calling**, which enables you to execute custom code to extend the capabilities of the model. Here's how it works at a high level:
1. When [updating the session](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update) or [creating a response](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create), you can specify a list of available functions for the model to call.
1. If when processing input, the model determines it should make a function call, it will add items to the conversation representing arguments to a function call.
1. When the client detects conversation items that contain function call arguments, it will execute custom code using those arguments
1. When the custom code has been executed, the client will create new conversation items that contain the output of the function call, and ask the model to respond.
Let's see how this would work in practice by adding a callable function that will provide today's horoscope to users of the model. We'll show the shape of the client event objects that need to be sent, and what the server will emit in turn.
### Configure callable functions
First, we must give the model a selection of functions it can call based on user input. Available functions can be configured either at the session level, or the individual response level.
- Session: `session.tools` property in [`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update)
- Response: `response.tools` property in [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create)
Here's an example client event payload for a `session.update` that configures a horoscope generation function, that takes a single argument (the astrological sign for which the horoscope should be generated):
[`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update)
```json
{
"type": "session.update",
"session": {
"tools": [
{
"type": "function",
"name": "generate_horoscope",
"description": "Give today's horoscope for an astrological sign.",
"parameters": {
"type": "object",
"properties": {
"sign": {
"type": "string",
"description": "The sign for the horoscope.",
"enum": [
"Aries",
"Taurus",
"Gemini",
"Cancer",
"Leo",
"Virgo",
"Libra",
"Scorpio",
"Sagittarius",
"Capricorn",
"Aquarius",
"Pisces"
]
}
},
"required": ["sign"]
}
}
],
"tool_choice": "auto"
}
}
```
The `description` fields for the function and the parameters help the model choose whether or not to call the function, and what data to include in each parameter. If the model receives input that indicates the user wants their horoscope, it will call this function with a `sign` parameter.
### Detect when the model wants to call a function
Based on inputs to the model, the model may decide to call a function in order to generate the best response. Let's say our application adds the following conversation item with a [`conversation.item.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/conversation/item/create) event and then creates a response:
```json
{
"type": "conversation.item.create",
"item": {
"type": "message",
"role": "user",
"content": [
{
"type": "input_text",
"text": "What is my horoscope? I am an aquarius."
}
]
}
}
```
Followed by a [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create) client event to generate a response:
```json
{
"type": "response.create"
}
```
Instead of immediately returning a text or audio response, the model will instead generate a response that contains the arguments that should be passed to a function in the developer's application. You can listen for realtime updates to function call arguments using the [`response.function_call_arguments.delta`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/function_call_arguments/delta) server event, but `response.done` will also have the complete data we need to call our function.
[`response.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/done)
```json
{
"type": "response.done",
"event_id": "event_AeqLA8iR6FK20L4XZs2P6",
"response": {
"object": "realtime.response",
"id": "resp_AeqL8XwMUOri9OhcQJIu9",
"status": "completed",
"status_details": null,
"output": [
{
"object": "realtime.item",
"id": "item_AeqL8gmRWDn9bIsUM2T35",
"type": "function_call",
"status": "completed",
"name": "generate_horoscope",
"call_id": "call_sHlR7iaFwQ2YQOqm",
"arguments": "{\"sign\":\"Aquarius\"}"
}
],
...
}
}
```
In the JSON emitted by the server, we can detect that the model wants to call a custom function:
| Property | Function calling purpose |
| ------------------------------ | -------------------------------------------------------------------------------------------------------------------------- |
| `response.output[0].type` | When set to `function_call`, indicates this response contains arguments for a named function call. |
| `response.output[0].name` | The name of the configured function to call, in this case `generate_horoscope` |
| `response.output[0].arguments` | A JSON string containing arguments to the function. In our case, `"{\"sign\":\"Aquarius\"}"`. |
| `response.output[0].call_id` | A system-generated ID for this function call - **you will need this ID to pass a function call result back to the model**. |
Given this information, we can execute code in our application to generate the horoscope, and then provide that information back to the model so it can generate a response.
### Provide the results of a function call to the model
Upon receiving a response from the model with arguments to a function call, your application can execute code that satisfies the function call. This could be anything you want, like talking to external APIs or accessing databases.
Once you are ready to give the model the results of your custom code, you can create a new conversation item containing the result via the [`conversation.item.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/conversation/item/create) client event.
```json
{
"type": "conversation.item.create",
"item": {
"type": "function_call_output",
"call_id": "call_sHlR7iaFwQ2YQOqm",
"output": "{\"horoscope\": \"You will soon meet a new friend.\"}"
}
}
```
- The conversation item type is `function_call_output`
- `item.call_id` is the same ID we got back in the `response.done` event above
- `item.output` is a JSON string containing the results of our function call
Once we have added the conversation item containing our function call results, we again emit the [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create) event from the client. This will trigger a model response using the data from the function call.
```json
{
"type": "response.create"
}
```
## Error handling
The [`error`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/error) event is emitted by the server whenever an error condition is encountered on the server during the session. Occasionally, these errors can be traced to a client event that was emitted by your application.
Unlike HTTP requests and responses, where a response is implicitly tied to a request from the client, we need to use an `event_id` property on client events to know when one of them has triggered an error condition on the server. This technique is shown in the code below, where the client attempts to emit an unsupported event type.
```javascript
const event = {
event_id: "my_awesome_event",
type: "scooby.dooby.doo",
};
dataChannel.send(JSON.stringify(event));
```
This unsuccessful event sent from the client will emit an error event like the following:
```json
{
"type": "invalid_request_error",
"code": "invalid_value",
"message": "Invalid value: 'scooby.dooby.doo' ...",
"param": "type",
"event_id": "my_awesome_event"
}
```
## Interruption and Truncation
In many voice applications the user can interrupt the model while it's speaking. Realtime API handles interruptions when VAD is enabled, in that it detects user speech, cancels the ongoing response, and starts a new one. However in this scenario you will want the model to know where it was interrupted, so it can continue the conversation naturally (for example if the user says "what was that last thing?"). We call this **truncating** the model's last response, i.e. removing the unplayed portion of the model's last response from the conversation.
In WebRTC and SIP connections the server manages a buffer of output audio, and thus knows how much audio has been played at a given moment. The server will automatically truncate unplayed audio when there's a user interruption.
With a WebSocket connection the client manages audio playback, and thus must stop playback and handle truncation. Here's how this procedure works:
1. The client monitors for new `input_audio_buffer.speech_started` events from the server, which indicate the user has started speaking. The server will automatically cancel any in-progress model response and a `response.cancelled` event will be emitted.
1. When the client detects this event, it should immediately stop playback of any audio currently being played from the model. It should note how much of the last audio response was played before the interruption.
1. The client should send a [`conversation.item.truncate`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/conversation/item/truncate) event to remove the unplayed portion of the model's last response from the conversation.
Here's an example:
```json
{
"type": "conversation.item.truncate",
"item_id": "item_1234", # this is the item ID of the model's last response
"content_index": 0,
"audio_end_ms": 1500 # truncate audio after 1.5 seconds
}
```
What about truncating the transcript as well? The realtime model doesn't have enough information to precisely align transcript and audio, and thus `conversation.item.truncate` will cut the audio at a given place and remove the text transcript for the unplayed portion. This solves the problem of removing unplayed audio but doesn't provide a truncated transcript.
## Push-to-talk
Realtime API defaults to using voice activity detection (VAD), which means model responses will be triggered with audio input. You can also do a push-to-talk interaction by disabling VAD and using an application-level gate to control when audio input is sent to the model, for example holding the space-bar down to capture audio, then triggering a response when it's released. For some apps this works surprisingly well -- it gives the users control over interactions, avoids VAD failures, and it feels snappy because we're not waiting for a VAD timeout.
Implementing push-to-talk looks a bit different on WebSockets and WebRTC. In a Realtime API WebSocket connection all events are sent in the same channel and with the same ordering, while a WebRTC connection has separate channels for audio and control events.
### WebSockets
To implement push-to-talk with a WebSocket connection, you'll want the client to stop audio playback, handle interruptions, and kick off a new response. Here's a more detailed procedure:
1. Turn VAD off by setting `"turn_detection": null` in a [`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update) event.
1. On push down, start recording audio on the client.
1. If there is an in-progress response from the model, cancel it by sending a [`response.cancel`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/cancel) event.
1. If there is is ongoing output playback from the model, stop playback immediately and send an `conversation.item.truncate` event to remove any unplayed audio from the conversation.
1. On up, send an [`input_audio_buffer.append`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/input_audio_buffer/append) message with the audio to place new audio into the input buffer.
1. Send an [`input_audio_buffer.commit`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/input_audio_buffer/commit) event, this will commit the audio written to the input buffer and kick off input transcription (if enabled).
1. Then trigger a response with a [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create) event.
### WebRTC and SIP
Implementing push-to-talk with WebRTC is similar but the input audio buffer must be explicitly cleared. Here's a procedure:
1. Turn VAD off by setting `"turn_detection": null` in a [`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update) event.
1. On push down, send an [`input_audio_buffer.clear`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/input_audio_buffer/clear) event to clear any previous audio input.
1. If there is an in-progress response from the model, cancel it by sending a [`response.cancel`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/cancel) event.
1. If there is is ongoing output playback from the model, send an [`output_audio_buffer.clear`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/output_audio_buffer/clear) event to clear out the unplayed audio, this truncates the conversation as well.
1. On up, send an [`input_audio_buffer.commit`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/input_audio_buffer/commit) event, this will commit the audio written to the input buffer and kick off input transcription (if enabled).
1. Then trigger a response with a [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create) event.
---
# Realtime transcription
import {
Bolt,
Cube,
Desktop,
Phone,
} from "@components/react/oai/platform/ui/Icon.react";
Use realtime transcription when your application needs live speech-to-text without a spoken assistant response. Realtime transcription sessions stream transcript deltas as audio arrives, so users can see text before the full utterance is complete.
For the lowest-latency streaming transcription path, use [`gpt-realtime-whisper`](https://developers.openai.com/api/docs/models/gpt-realtime-whisper). For offline files or workflows that don't need streaming deltas, use the standard speech-to-text models in the Audio API.
## Choose a transcription model
| Model |
Best for |
Notes |
|
gpt-realtime-whisper
|
Live audio, transcript deltas, tunable latency. |
Natively streaming and designed for realtime sessions. |
|
gpt-4o-transcribe
|
Higher-accuracy speech-to-text where streaming isn't required. |
Use for file and request-response transcription workflows. |
|
gpt-4o-mini-transcribe
|
Lower-cost transcription. |
Use when cost matters more than top accuracy. |
|
whisper-1
|
Existing Whisper integrations. |
Not natively streaming in the same way as{" "}
gpt-realtime-whisper.
|
`gpt-realtime-whisper` is an alternative for live transcription, not a blanket replacement for every transcription model. Test it against your audio, languages, vocabulary, and latency requirements before switching production traffic.
## Create a transcription session
Realtime transcription uses a session with `type: "transcription"`. You can connect with [WebSocket](https://developers.openai.com/api/docs/guides/realtime-websocket) for server-side audio pipelines or [WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc) for browser audio.
```json
{
"type": "session.update",
"session": {
"type": "transcription",
"audio": {
"input": {
"format": {
"type": "audio/pcm",
"rate": 24000
},
"transcription": {
"model": "gpt-realtime-whisper",
"language": "en"
},
"turn_detection": {
"type": "server_vad",
"threshold": 0.5,
"prefix_padding_ms": 300,
"silence_duration_ms": 500
}
}
}
}
}
```
### Session fields
- `type`: Set to `transcription` for transcription-only sessions.
- `audio.input.format`: Input encoding for audio appended to the buffer. Use 24 kHz mono PCM when sending `audio/pcm`.
- `audio.input.transcription.model`: Use `gpt-realtime-whisper` for streaming transcription.
- `audio.input.transcription.language`: Optional language hint such as `en`.
- `audio.input.turn_detection`: Optional voice activity detection. Set it to `null` if you want to commit audio manually.
## Stream audio
Send audio chunks with `input_audio_buffer.append`:
```javascript
ws.send(
JSON.stringify({
type: "input_audio_buffer.append",
audio: base64Pcm16,
})
);
```
If you disable turn detection, commit the buffer when you want transcription to begin:
```javascript
ws.send(
JSON.stringify({
type: "input_audio_buffer.commit",
})
);
```
With server VAD enabled, the session commits audio automatically when it detects a turn boundary.
## Handle transcript events
Listen for incremental transcript deltas and completion events:
```javascript
ws.on("message", (data) => {
const event = JSON.parse(data);
if (event.type === "conversation.item.input_audio_transcription.delta") {
process.stdout.write(event.delta);
}
if (event.type === "conversation.item.input_audio_transcription.completed") {
console.log("\nFinal transcript:", event.transcript);
}
});
```
A delta event contains newly available transcript text:
```json
{
"type": "conversation.item.input_audio_transcription.delta",
"item_id": "item_003",
"content_index": 0,
"delta": "Hello,"
}
```
A completion event contains the final transcript for the committed item:
```json
{
"type": "conversation.item.input_audio_transcription.completed",
"item_id": "item_003",
"content_index": 0,
"transcript": "Hello, how are you?"
}
```
Ordering between completion events from different speech turns isn't guaranteed. Use `item_id` to match transcription events to committed input items.
## Tune latency and accuracy
Streaming transcription trades latency for transcript quality. Lower delay settings can produce earlier partial text. Higher delay settings give the model more audio context before emitting text and can improve word error rate.
Start by testing a few delay targets against your real audio. Useful evaluation points are:
- 0.4 seconds for the most latency-sensitive interactions;
- 0.8 to 1.2 seconds for balanced live captions;
- 1.5 to 2.0 seconds when accuracy matters more than immediate display;
- 3.0 seconds for workflows that can tolerate more delay.
Don't choose a setting from synthetic audio alone. Test with representative microphones, telephony audio, accents, background noise, code-switching, domain vocabulary, and long sessions.
## Guide vocabulary and domain terms
If your application depends on exact domain vocabulary, include a language hint and test whether your model and endpoint support prompt or keyword steering before relying on it. Where supported, use short keyword lists rather than long instructions.
Example keyword style:
```text
Keywords: metoprolol, atorvastatin, A1C, systolic, diastolic
```
For production, treat keyword steering as an aid rather than a guarantee. Continue to evaluate names, numbers, dates, medication names, product names, artist names, and other high-value entities manually.
## Handle confidence, timestamps, and diarization
Only request optional fields that your selected model and endpoint support. If your application needs confidence scoring, timestamps, or diarization, verify support before launch and add fallbacks for fields that aren't available.
When log probabilities are available, request them with `include`:
```json
{
"type": "session.update",
"session": {
"type": "transcription",
"audio": {
"input": {
"transcription": {
"model": "gpt-realtime-whisper"
}
}
},
"include": ["item.input_audio_transcription.logprobs"]
}
}
```
## Production checklist
- Pick a target latency and accuracy threshold before tuning.
- Test against real production audio, not only clean samples.
- Test each target language.
- Include numbers, dates, currency, email addresses, product names, and domain terms in your eval set.
- Track empty, truncated, and delayed transcripts apart from word error rate.
- Decide how your UI should revise partial text when later deltas correct earlier text.
- Use `item_id` to order and reconcile final transcripts.
- Keep a fallback path for unsupported timestamps, diarization, or confidence fields.
## Related guides
Compare voice-agent, translation, and transcription sessions.
Translate live speech with a dedicated translation session.
Stream raw audio through a server-side media pipeline.
Configure turn detection for live audio streams.
---
# Realtime translation
import {
Bolt,
Cube,
Desktop,
Phone,
} from "@components/react/oai/platform/ui/Icon.react";
Realtime translation lets you stream source audio into a dedicated translation session and receive translated audio plus transcript deltas while the speaker is still talking. Use it for live interpretation, multilingual calls, broadcasts, meetings, lessons, and video rooms.
Use [`gpt-realtime-translate`](https://developers.openai.com/api/docs/models/gpt-realtime-translate) when your application should translate what a human says. If you need an assistant that answers questions, calls tools, and manages a conversation, use [`gpt-realtime-2`](https://developers.openai.com/api/docs/models/gpt-realtime-2) with a standard Realtime session instead.
## How translation sessions differ
Realtime translation sessions use a different architecture from voice-agent sessions:
| Voice-agent session | Translation session |
| ------------------------------------------- | ------------------------------------------------ |
| Connects to `/v1/realtime`. | Connects to `/v1/realtime/translations`. |
| The model acts as an assistant. | The model acts as an interpreter. |
| Uses a conversation and response lifecycle. | Streams continuously from incoming audio. |
| May call tools and produce assistant turns. | Produces translated audio and transcript deltas. |
| You can call `response.create`. | You don't call `response.create`. |
Translation starts from the audio stream itself. Keep appending audio, including silence between phrases, and handle output events as they arrive.
## Choose a transport
Use WebRTC when the browser captures or plays audio. WebRTC sends source audio as a media track and receives translated speech as a remote audio track, so you don't need to manually resample or play PCM chunks.
Use WebSockets when your server already receives raw audio, such as Twilio Media Streams, SIP media, broadcast ingest, or a media worker. With WebSockets, send base64-encoded 24 kHz PCM16 audio and play returned audio deltas yourself.
## Create a browser WebRTC session
For browser apps, create a short-lived client secret on your server. Don't expose your standard API key in the browser.
In the browser, capture audio, create a peer connection, and post the SDP offer to the translation calls endpoint:
## Create a WebSocket session
Connect to the dedicated translation endpoint and select the model in the URL:
Install the `ws` package for Node.js or the `websocket-client` package for Python before running this example.
Connect to a translation session
```javascript
import WebSocket from "ws";
const ws = new WebSocket(
"wss://api.openai.com/v1/realtime/translations?model=gpt-realtime-translate",
{
headers: {
Authorization: \`Bearer \${process.env.OPENAI_API_KEY}\`,
"OpenAI-Safety-Identifier": "hashed-user-id",
},
}
);
```
```python
import os
import websocket
ws = websocket.WebSocket()
ws.connect(
"wss://api.openai.com/v1/realtime/translations?model=gpt-realtime-translate",
header=[
f"Authorization: Bearer {os.environ['OPENAI_API_KEY']}",
"OpenAI-Safety-Identifier: hashed-user-id",
],
)
```
Configure the target language after the socket opens:
Configure the target language
```javascript
ws.on("open", () => {
ws.send(
JSON.stringify({
type: "session.update",
session: {
audio: {
output: {
language: "es",
},
},
},
})
);
});
```
```python
import json
ws.send(
json.dumps(
{
"type": "session.update",
"session": {
"audio": {
"output": {
"language": "es",
},
},
},
}
)
)
```
Then append audio continuously:
Append source audio
```javascript
ws.send(
JSON.stringify({
type: "session.input_audio_buffer.append",
audio: base64Pcm16,
})
);
```
```python
ws.send(
json.dumps(
{
"type": "session.input_audio_buffer.append",
"audio": base64_pcm16,
}
)
)
```
Listen for translated audio and transcripts:
Listen for translated audio and transcripts
```javascript
ws.on("message", (data) => {
const event = JSON.parse(data);
if (event.type === "session.output_audio.delta") {
playPcm16(event.delta);
}
if (event.type === "session.output_transcript.delta") {
process.stdout.write(event.delta);
}
if (event.type === "session.input_transcript.delta") {
updateSourceTranscript(event.delta);
}
});
```
```python
while True:
event = json.loads(ws.recv())
if event["type"] == "session.output_audio.delta":
play_pcm16(event["delta"])
if event["type"] == "session.output_transcript.delta":
print(event["delta"], end="", flush=True)
if event["type"] == "session.input_transcript.delta":
update_source_transcript(event["delta"])
```
## Build listen-along translation
Use listen-along translation when one source speaker or stream needs translated audio for an audience. Examples include livestreams, conference talks, webinars, earnings calls, lectures, and videos.
The typical architecture is:
```text
source audio -> translation session -> translated audio + subtitles
```
Create one translation session for each target language. If the same English source needs Spanish and French output, create one English-to-Spanish session and one English-to-French session.
For browser listen-along apps, capture tab audio with `getDisplayMedia()`, send it over WebRTC, and play the remote translated audio track. For production broadcasts, run translation in a server media worker and publish translated audio tracks or captions to listeners.
## Build conversational translation
Use conversational translation when two or more participants speak across languages. Examples include support calls, sales calls, tutoring, and video rooms.
Keep participant audio tracks separate. Mixing speakers into one stream makes speaker identity, speaker captions, and overlapping speech more difficult to handle.
For a two-person call, create one translation session per direction:
```text
Caller A audio -> translate into Caller B language -> play to Caller B
Caller B audio -> translate into Caller A language -> play to Caller A
```
For group rooms, session count depends on active speakers and target languages:
```text
translation sessions ~= active source speaker tracks x distinct target languages
```
For small rooms, each listener can create browser-side translation sidecars for the remote speakers they want translated. For larger rooms, use a server-side participant or media worker that subscribes to each source speaker once, creates one translation session per target language, and republishes translated tracks.
## Test quality and latency
Test translation with real audio and bilingual review. Automated metrics can help, but they won't catch every error users notice.
Test:
- language-pair quality;
- names, numbers, dates, currency, and phone numbers;
- domain-specific terminology;
- code-switching and mixed-language conversation;
- accents, fast speech, and overlapping speech;
- first translated audio latency;
- end-of-utterance latency;
- subtitle timing;
- voice consistency;
- reconnect behavior.
If your use case depends on exact names or domain terms, build a golden set before launch and review failures manually.
## Production checklist
- Choose WebRTC for browser media and WebSockets for server media.
- Use the dedicated `/v1/realtime/translations` endpoint.
- Stream audio continuously, including silence between phrases.
- Keep speaker tracks separate for conversational translation.
- Use one session per output language.
- Render both source and target transcripts when useful.
- Expose controls for original audio, translated audio, subtitles, mute, and volume.
- Surface reconnecting, delayed, and unavailable states.
- Track latency apart from translation quality.
## Related guides
Compare voice-agent, translation, and transcription sessions.
Connect browser media to a realtime session.
Stream raw audio through a server-side media pipeline.
Stream transcript deltas from live audio.
---
# Realtime with tools
You can attach tools to a Realtime session so the model can look up data, take actions, or call services during a live conversation. Tool configuration uses the same event surface whether your client is using a [WebRTC data channel](https://developers.openai.com/api/docs/guides/realtime-webrtc) or a [WebSocket](https://developers.openai.com/api/docs/guides/realtime-websocket).
Use function tools when your application should execute the tool and return the result. Use MCP tools or built-in connectors when the Realtime API should connect to a remote tool server for you.
## Choose a tool type
| Tool type | Use when | Who executes it |
| ------------------------- | ------------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------- |
| `function` | Your application owns the business logic, approval checks, or private system access. | Your client or server receives a function call and returns `function_call_output`. |
| `mcp` with `server_url` | You want the model to call tools exposed by a remote MCP server. | The Realtime API calls the remote MCP server. |
| `mcp` with `connector_id` | You want to use a built-in connector such as Google Calendar. | The Realtime API calls the connector with the authorization you provide. |
Add tools in **one of two places**:
- At the **session level** with `session.tools` in [`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update), if you want the tool available for the full session.
- At the **response level** with `response.tools` in [`response.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/response/create), if you only need the tool for one turn.
## Configure a function tool
Function tools are the right default when the tool should run in your application. The model emits function call arguments, your code executes the action, and your code sends the result back with a `function_call_output` item.
Configure a function tool with session.update
```javascript
const event = {
type: "session.update",
session: {
type: "realtime",
model: "gpt-realtime-2",
tools: [
{
type: "function",
name: "lookup_order",
description: "Look up an order by its order number.",
parameters: {
type: "object",
properties: {
order_number: {
type: "string",
description: "The customer-facing order number.",
},
},
required: ["order_number"],
},
},
],
tool_choice: "auto",
},
};
ws.send(JSON.stringify(event));
```
```python
event = {
"type": "session.update",
"session": {
"type": "realtime",
"model": "gpt-realtime-2",
"tools": [
{
"type": "function",
"name": "lookup_order",
"description": "Look up an order by its order number.",
"parameters": {
"type": "object",
"properties": {
"order_number": {
"type": "string",
"description": "The customer-facing order number.",
}
},
"required": ["order_number"],
},
}
],
"tool_choice": "auto",
},
}
ws.send(json.dumps(event))
```
When the model calls the function, listen for the function call item, run your application logic, then send the output back:
Send function call output
```javascript
const event = {
type: "conversation.item.create",
item: {
type: "function_call_output",
call_id: functionCall.call_id,
output: JSON.stringify({
status: "shipped",
delivery_date: "2026-05-09",
}),
},
};
ws.send(JSON.stringify(event));
ws.send(JSON.stringify({ type: "response.create" }));
```
```python
event = {
"type": "conversation.item.create",
"item": {
"type": "function_call_output",
"call_id": function_call["call_id"],
"output": json.dumps(
{
"status": "shipped",
"delivery_date": "2026-05-09",
}
),
},
}
ws.send(json.dumps(event))
ws.send(json.dumps({"type": "response.create"}))
```
For a full event-by-event walkthrough of function calling, see [Managing conversations](https://developers.openai.com/api/docs/guides/realtime-conversations#function-calling).
## Configure an MCP tool
MCP tools are useful when the tool already exists behind a remote MCP server, or when you want to use an OpenAI-managed connector. Unlike function tools, MCP tools are executed by the Realtime API itself.
In Realtime, the MCP tool shape is:
- `type: "mcp"`
- `server_label`
- One of `server_url` or `connector_id`
- Optional `authorization` and `headers`
- Optional `allowed_tools`
- Optional `require_approval`
- Optional `server_description`
This example makes a docs MCP server available for the full session:
Configure an MCP tool with session.update
```javascript
const event = {
type: "session.update",
session: {
type: "realtime",
model: "gpt-realtime-2",
output_modalities: ["text"],
tools: [
{
type: "mcp",
server_label: "openai_docs",
server_url: "https://developers.openai.com/mcp",
allowed_tools: ["search_openai_docs", "fetch_openai_doc"],
require_approval: "never",
},
],
},
};
ws.send(JSON.stringify(event));
```
```python
event = {
"type": "session.update",
"session": {
"type": "realtime",
"model": "gpt-realtime-2",
"output_modalities": ["text"],
"tools": [
{
"type": "mcp",
"server_label": "openai_docs",
"server_url": "https://developers.openai.com/mcp",
"allowed_tools": ["search_openai_docs", "fetch_openai_doc"],
"require_approval": "never",
}
],
},
}
ws.send(json.dumps(event))
```
Built-in connectors use the same MCP tool shape, but pass `connector_id`
instead of `server_url`. For example, Google Calendar uses
`connector_googlecalendar`. In Realtime, use these built-in connectors for read
actions, such as searching or reading events or emails. Pass the user's OAuth
access token in `authorization`, and narrow the tool surface with
`allowed_tools` when possible:
Configure a Google Calendar connector
```javascript
const event = {
type: "session.update",
session: {
type: "realtime",
model: "gpt-realtime-2",
output_modalities: ["text"],
tools: [
{
type: "mcp",
server_label: "google_calendar",
connector_id: "connector_googlecalendar",
authorization: "",
allowed_tools: ["search_events", "read_event"],
require_approval: "never",
},
],
},
};
ws.send(JSON.stringify(event));
```
```python
event = {
"type": "session.update",
"session": {
"type": "realtime",
"model": "gpt-realtime-2",
"output_modalities": ["text"],
"tools": [
{
"type": "mcp",
"server_label": "google_calendar",
"connector_id": "connector_googlecalendar",
"authorization": "",
"allowed_tools": ["search_events", "read_event"],
"require_approval": "never",
}
],
},
}
ws.send(json.dumps(event))
```
Remote MCP servers{" "}
don't automatically receive the full conversation context,
but they can see any data the model sends in a tool call.
Keep the tool surface narrow with allowed_tools,
and require approval for any action you would not auto-run.
## Realtime MCP flow
Unlike Realtime `function` tools, remote MCP tools are **executed by the Realtime API itself**. **Your client doesn't run the remote tool** and return a `function_call_output`. Instead, your client configures access, listens for MCP lifecycle events, and optionally sends an approval response if the server asks for one.
A typical flow looks like this:
1. You send `session.update` or `response.create` with a `tools` entry whose `type` is `mcp`.
1. The server begins importing tools and emits `mcp_list_tools.in_progress`.
1. While listing is still in progress, the model can't call a tool that hasn't loaded yet. If you want to wait before starting a turn that depends on those tools, listen for [`mcp_list_tools.completed`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/mcp_list_tools/completed). The [`conversation.item.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/conversation/item/done) event whose `item.type` is `mcp_list_tools` shows which tool names were actually imported. If import fails, you will receive [`mcp_list_tools.failed`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/mcp_list_tools/failed).
1. The user speaks or sends text, and a response is created, either by your client or automatically by the session configuration.
1. If the model chooses an MCP tool, you will see `response.mcp_call_arguments.delta` and `response.mcp_call_arguments.done`.
1. **If approval is required**, the server adds a conversation item whose `item.type` is `mcp_approval_request`. Your client must answer it with an `mcp_approval_response` item.
1. Once the tool runs, you will see `response.mcp_call.in_progress`. On success, you will later receive a [`response.output_item.done`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/output_item/done) event whose `item.type` is `mcp_call`; on failure, you will receive [`response.mcp_call.failed`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/mcp_call/failed). The assistant message item and `response.done` complete the turn.
This event handler covers the main checkpoints:
Listen for MCP events during a Realtime session
```javascript
function parseRealtimeEvent(rawMessage) {
if (typeof rawMessage === "string") {
return JSON.parse(rawMessage);
}
if (typeof rawMessage?.data === "string") {
return JSON.parse(rawMessage.data);
}
return JSON.parse(rawMessage.toString());
}
function getOutputText(item) {
if (item.type !== "message") return "";
return (item.content ?? [])
.filter((part) => part.type === "output_text")
.map((part) => part.text)
.join("");
}
ws.on("message", (rawMessage) => {
const event = parseRealtimeEvent(rawMessage);
switch (event.type) {
case "mcp_list_tools.in_progress":
console.log("Listing MCP tools for item:", event.item_id);
break;
case "mcp_list_tools.completed":
console.log("MCP tool listing complete for item:", event.item_id);
break;
case "mcp_list_tools.failed":
console.error("MCP tool listing failed for item:", event.item_id);
break;
case "conversation.item.done":
if (event.item.type === "mcp_list_tools") {
const names = event.item.tools.map((tool) => tool.name).join(", ");
console.log(\`MCP tools ready on \${event.item.server_label}: \${names}\`);
}
if (event.item.type === "mcp_approval_request") {
console.log("Approval required for:", event.item.name, event.item.arguments);
}
break;
case "response.mcp_call_arguments.done":
console.log("Final MCP call arguments:", event.arguments);
break;
case "response.mcp_call.in_progress":
console.log("Running MCP tool for item:", event.item_id);
break;
case "response.mcp_call.failed":
console.error("MCP tool call failed for item:", event.item_id);
break;
case "response.output_item.done":
if (event.item.type === "mcp_call") {
console.log(
\`MCP output from \${event.item.server_label}.\${event.item.name}:\`,
event.item.output
);
}
if (event.item.type === "message") {
console.log("Assistant:", getOutputText(event.item));
}
break;
case "response.done":
console.log("Realtime turn complete.");
break;
}
});
```
```python
def on_message(ws, message):
event = json.loads(message)
event_type = event["type"]
if event_type == "mcp_list_tools.in_progress":
print("Listing MCP tools for item:", event["item_id"])
return
if event_type == "mcp_list_tools.completed":
print("MCP tool listing complete for item:", event["item_id"])
return
if event_type == "mcp_list_tools.failed":
print("MCP tool listing failed for item:", event["item_id"])
return
if event_type == "conversation.item.done":
item = event["item"]
if item["type"] == "mcp_list_tools":
names = ", ".join(tool["name"] for tool in item["tools"])
print(f"MCP tools ready on {item['server_label']}: {names}")
return
if item["type"] == "mcp_approval_request":
print("Approval required for:", item["name"], item["arguments"])
return
if event_type == "response.mcp_call_arguments.done":
print("Final MCP call arguments:", event["arguments"])
return
if event_type == "response.mcp_call.in_progress":
print("Running MCP tool for item:", event["item_id"])
return
if event_type == "response.mcp_call.failed":
print("MCP tool call failed for item:", event["item_id"])
return
if event_type == "response.output_item.done":
item = event["item"]
if item["type"] == "mcp_call":
print(
f"MCP output from {item['server_label']}.{item['name']}:",
item.get("output"),
)
return
if item["type"] == "message":
text_parts = [
part["text"]
for part in item.get("content", [])
if part["type"] == "output_text"
]
print("Assistant:", "".join(text_parts))
return
if event_type == "response.done":
print("Realtime turn complete.")
```
## Common failures
- [`mcp_list_tools.failed`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/mcp_list_tools/failed): the Realtime API couldn't import tools from the remote server or connector. Check `server_url` or `connector_id`, authentication, server connectivity, and any `allowed_tools` names you specified.
- [`response.mcp_call.failed`](https://developers.openai.com/api/docs/api-reference/realtime-server-events/response/mcp_call/failed): the model selected a tool, but the tool call didn't complete. Inspect the event payload and the later `mcp_call` item for MCP protocol, execution, or transport errors.
- `mcp_approval_request` with no matching `mcp_approval_response`: the tool call can't continue until your client explicitly approves or rejects it.
- A turn starts while `mcp_list_tools.in_progress` is still active: only tools that have already finished loading are eligible for that turn.
- A response uses `tool_choice: "required"` but no tools are currently available: the model has nothing eligible to call. Wait for `mcp_list_tools.completed`, confirm that at least one tool was imported, or use a different `tool_choice` for turns that don't require a tool.
- MCP tool definition validation fails before import starts: common causes are a duplicate `server_label` in the same `tools` array, setting both `server_url` and `connector_id`, omitting both of them on the initial session creation request, using an invalid `connector_id`, or sending both `authorization` and `headers.Authorization`. For connectors, don't send `headers.Authorization` at all.
## Approve or reject MCP tool calls
If a tool requires approval, the Realtime API inserts an `mcp_approval_request` item into the conversation. **To continue**, send a new [`conversation.item.create`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/conversation/item/create) event whose `item.type` is `mcp_approval_response`.
Approve an MCP request
```javascript
function approveMcpRequest(approvalRequestId) {
const event = {
type: "conversation.item.create",
item: {
id: \`mcp_approval_\${approvalRequestId}\`,
type: "mcp_approval_response",
approval_request_id: approvalRequestId,
approve: true,
},
};
ws.send(JSON.stringify(event));
}
```
```python
def approve_mcp_request(ws, approval_request_id):
event = {
"type": "conversation.item.create",
"item": {
"id": f"mcp_approval_{approval_request_id}",
"type": "mcp_approval_response",
"approval_request_id": approval_request_id,
"approve": True,
},
}
ws.send(json.dumps(event))
```
If you reject the request, set `approve` to `false` and optionally include a `reason`.
## Use MCP for one response only
If MCP should **only be available for a single turn**, attach the same MCP tool object to `response.tools` instead of `session.tools`:
Add MCP tools on one response
```javascript
const event = {
type: "response.create",
response: {
output_modalities: ["text"],
input: [
{
type: "message",
role: "user",
content: [
{
type: "input_text",
text: "Which transport should I use for browser clients in the Realtime API?",
},
],
},
],
tools: [
{
type: "mcp",
server_label: "openai_docs",
server_url: "https://developers.openai.com/mcp",
allowed_tools: ["search_openai_docs", "fetch_openai_doc"],
require_approval: "never",
},
],
},
};
ws.send(JSON.stringify(event));
```
```python
event = {
"type": "response.create",
"response": {
"output_modalities": ["text"],
"input": [
{
"type": "message",
"role": "user",
"content": [
{
"type": "input_text",
"text": "Which transport should I use for browser clients in the Realtime API?",
}
],
}
],
"tools": [
{
"type": "mcp",
"server_label": "openai_docs",
"server_url": "https://developers.openai.com/mcp",
"allowed_tools": ["search_openai_docs", "fetch_openai_doc"],
"require_approval": "never",
}
],
},
}
ws.send(json.dumps(event))
```
This is useful when only one response needs external context, or when different turns should use different MCP servers.
## Reuse a previously defined server label
`server_label` is the stable handle for a tool definition in the current
Realtime session. After you define a server or connector once with
`server_label` plus `server_url` or `connector_id`, later `session.update` or
`response.create` events can reference only that same `server_label`, and the
Realtime API will reuse the earlier definition instead of requiring you to send
the full tool object again.
Reuse a previously defined connector
```javascript
const event = {
type: "response.create",
response: {
output_modalities: ["text"],
input: [
{
type: "message",
role: "user",
content: [
{
type: "input_text",
text: "Check my schedule for this afternoon.",
},
],
},
],
// Reuses the google_calendar connector defined earlier in this session.
tools: [
{
type: "mcp",
server_label: "google_calendar",
},
],
},
};
ws.send(JSON.stringify(event));
```
```python
event = {
"type": "response.create",
"response": {
"output_modalities": ["text"],
"input": [
{
"type": "message",
"role": "user",
"content": [
{
"type": "input_text",
"text": "Check my schedule for this afternoon.",
}
],
}
],
# Reuses the google_calendar connector defined earlier in this session.
"tools": [
{
"type": "mcp",
"server_label": "google_calendar",
}
],
},
}
ws.send(json.dumps(event))
```
This reuse is session-scoped. If you start a new Realtime session, send the
full MCP definition again so the server can import its tool list.
---
# Reasoning best practices
OpenAI offers two types of models: [reasoning models](https://developers.openai.com/api/docs/models#o4-mini) (o3 and o4-mini, for example) and [GPT models](https://developers.openai.com/api/docs/models#gpt-4.1) (like GPT-4.1). These model families behave differently.
This guide covers:
1. The difference between our reasoning and non-reasoning GPT models
1. When to use our reasoning models
1. How to prompt reasoning models effectively
Read more about [reasoning models](https://developers.openai.com/api/docs/guides/reasoning) and how they work.
## Reasoning models vs. GPT models
Compared to GPT models, our o-series models excel at different tasks and require different prompts. One model family isn't better than the other—they're just different.
We trained our o-series models (“the planners”) to think longer and harder about complex tasks, making them effective at strategizing, planning solutions to complex problems, and making decisions based on large volumes of ambiguous information. These models can also execute tasks with high accuracy and precision, making them ideal for domains that would otherwise require a human expert—like math, science, engineering, financial services, and legal services.
On the other hand, our lower-latency, more cost-efficient GPT models (“the workhorses”) are designed for straightforward execution. An application might use o-series models to plan out the strategy to solve a problem, and use GPT models to execute specific tasks, particularly when speed and cost are more important than perfect accuracy.
### How to choose
What's most important for your use case?
- **Speed and cost** → GPT models are faster and tend to cost less
- **Executing well defined tasks** → GPT models handle explicitly defined tasks well
- **Accuracy and reliability** → o-series models are reliable decision makers
- **Complex problem-solving** → o-series models work through ambiguity and complexity
If speed and cost are the most important factors when completing your tasks _and_ your use case is made up of straightforward, well defined tasks, then our GPT models are the best fit for you. However, if accuracy and reliability are the most important factors _and_ you have a very complex, multistep problem to solve, our o-series models are likely right for you.
Most AI workflows will use a combination of both models—o-series for agentic planning and decision-making, GPT series for task execution.
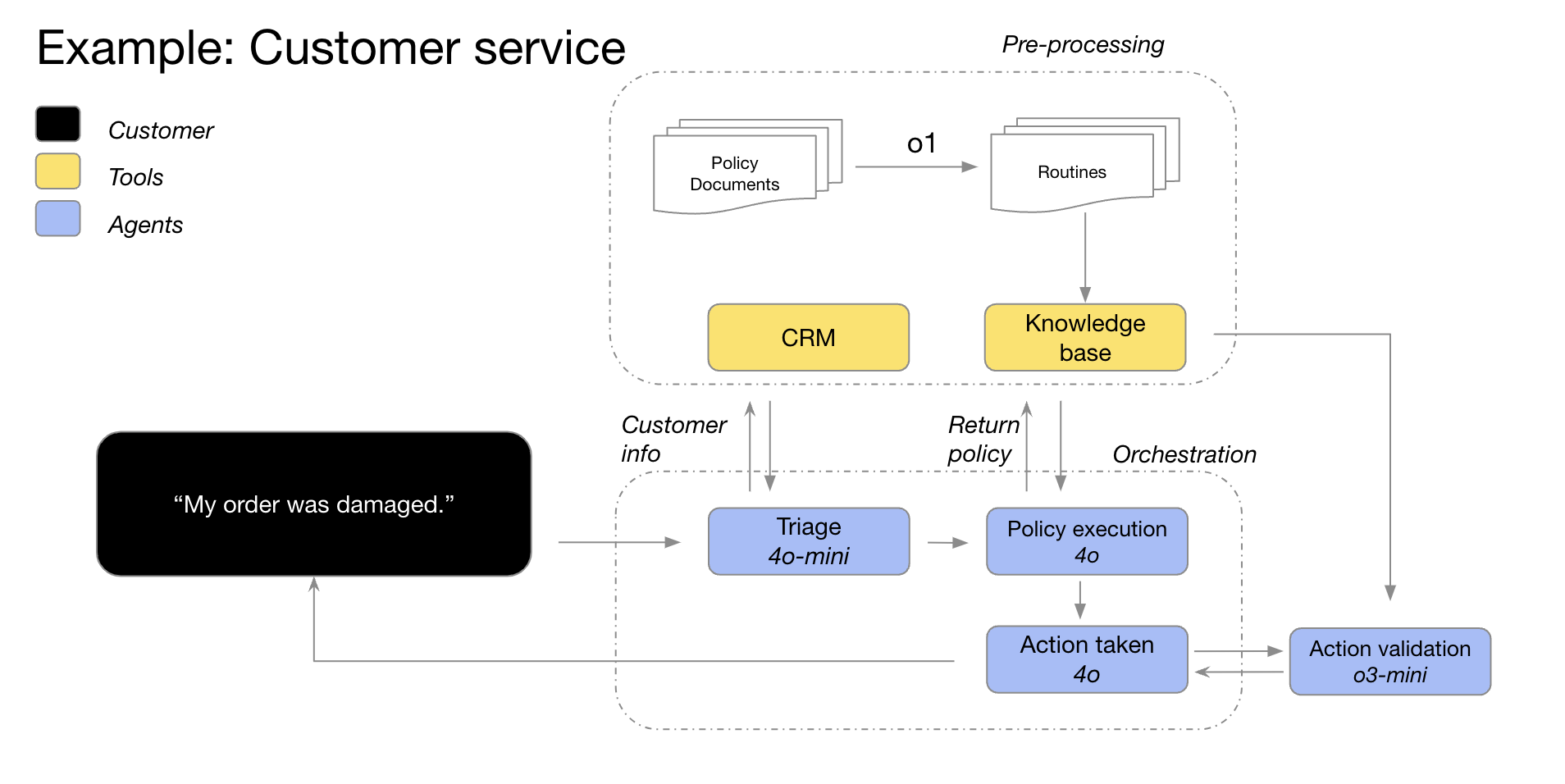
_Our GPT-4o and GPT-4o mini models triage order details with customer information, identify the order issues and the return policy, and then feed all of these data points into o3-mini to make the final decision about the viability of the return based on policy._
## When to use our reasoning models
Here are a few patterns of successful usage that we’ve observed from customers and internally at OpenAI. This isn't a comprehensive review of all possible use cases but, rather, some practical guidance for testing our o-series models.
[Ready to use a reasoning model? Skip to the quickstart →](https://developers.openai.com/api/docs/guides/reasoning)
### 1. Navigating ambiguous tasks
Reasoning models are particularly good at taking limited information or disparate pieces of information and with a simple prompt, understanding the user’s intent and handling any gaps in the instructions. In fact, reasoning models will often ask clarifying questions before making uneducated guesses or attempting to fill information gaps.
> “o1’s reasoning capabilities enable our multi-agent platform Matrix to produce exhaustive, well-formatted, and detailed responses when processing complex documents. For example, o1 enabled Matrix to easily identify baskets available under the restricted payments capacity in a credit agreement, with a basic prompt. No former models are as performant. o1 yielded stronger results on 52% of complex prompts on dense Credit Agreements compared to other models.”
>
> —[Hebbia](https://www.hebbia.com/), AI knowledge platform company for legal and finance
### 2. Finding a needle in a haystack
When you’re passing large amounts of unstructured information, reasoning models are great at understanding and pulling out only the most relevant information to answer a question.
> "To analyze a company's acquisition, o1 reviewed dozens of company documents—like contracts and leases—to find any tricky conditions that might affect the deal. The model was tasked with flagging key terms and in doing so, identified a crucial "change of control" provision in the footnotes: if the company was sold, it would have to pay off a $75 million loan immediately. o1's extreme attention to detail enables our AI agents to support finance professionals by identifying mission-critical information."
>
> —[Endex](https://endex.ai/), AI financial intelligence platform
### 3. Finding relationships and nuance across a large dataset
We’ve found that reasoning models are particularly good at reasoning over complex documents that have hundreds of pages of dense, unstructured information—things like legal contracts, financial statements, and insurance claims. The models are particularly strong at drawing parallels between documents and making decisions based on unspoken truths represented in the data.
> “Tax research requires synthesizing multiple documents to produce a final, cogent answer. We swapped GPT-4o for o1 and found that o1 was much better at reasoning over the interplay between documents to reach logical conclusions that were not evident in any one single document. As a result, we saw a 4x improvement in end-to-end performance by switching to o1—incredible.”
>
> —[Blue J](https://www.bluej.com/), AI platform for tax research
Reasoning models are also skilled at reasoning over nuanced policies and rules, and applying them to the task at hand in order to reach a reasonable conclusion.
> "In financial analyses, analysts often tackle complex scenarios around shareholder equity and need to understand the relevant legal intricacies. We tested about 10 models from different providers with a challenging but common question: how does a fundraise affect existing shareholders, especially when they exercise their anti-dilution privileges? This required reasoning through pre- and post-money valuations and dealing with circular dilution loops—something top financial analysts would spend 20-30 minutes to figure out. We found that o1 and o3-mini can do this flawlessly! The models even produced a clear calculation table showing the impact on a $100k shareholder."
>
> –[BlueFlame AI](https://www.blueflame.ai/), AI platform for investment management
### 4. Multistep agentic planning
Reasoning models are critical to agentic planning and strategy development. We’ve seen success when a reasoning model is used as “the planner,” producing a detailed, multistep solution to a problem and then selecting and assigning the right GPT model (“the doer”) for each step, based on whether high intelligence or low latency is most important.
> “We use o1 as the planner in our agent infrastructure, letting it orchestrate other models in the workflow to complete a multistep task. We find o1 is really good at selecting data types and breaking down big questions into smaller chunks, enabling other models to focus on execution.”
>
> —[Argon AI](https://argon-ai.com/), AI knowledge platform for the pharmaceutical industry
> “o1 powers many of our agentic workflows at Lindy, our AI assistant for work. The model uses function calling to pull information from your calendar or email and then can automatically help you schedule meetings, send emails, and manage other parts of your day-to-day tasks. We switched all of our agentic steps that used to cause issues to o1 and observing our agents becoming basically flawless overnight!”
>
> —[Lindy.AI](http://Lindy.AI), AI assistant for work
### 5. Visual reasoning
As of today, o1 is the only reasoning model that supports vision capabilities. What sets it apart from GPT-4o is that o1 can grasp even the most challenging visuals, like charts and tables with ambiguous structure or photos with poor image quality.
> “We automate risk and compliance reviews for millions of products online, including luxury jewelry dupes, endangered species, and controlled substances. GPT-4o reached 50% accuracy on our hardest image classification tasks. o1 achieved an impressive 88% accuracy without any modifications to our pipeline.”
>
> —[SafetyKit](https://www.safetykit.com/), AI-powered risk and compliance platform
From our own internal testing, we’ve seen that o1 can identify fixtures and materials from highly detailed architectural drawings to generate a comprehensive bill of materials. One of the most surprising things we observed was that o1 can draw parallels across different images by taking a legend on one page of the architectural drawings and correctly applying it across another page without explicit instructions. Below you can see that, for the 4x4 PT wood posts, o1 recognized that "PT" stands for pressure treated based on the legend.
### 6. Reviewing, debugging, and improving code quality
Reasoning models are particularly effective at reviewing and improving large amounts of code, often running code reviews in the background given the models’ higher latency.
> “We deliver automated AI Code Reviews on platforms like GitHub and GitLab. While code review process is not inherently latency-sensitive, it does require understanding the code diffs across multiple files. This is where o1 really shines—it's able to reliably detect minor changes to a codebase that could be missed by a human reviewer. We were able to increase product conversion rates by 3x after switching to o-series models.”
>
> —[CodeRabbit](https://www.coderabbit.ai/), AI code review startup
While GPT-4o and GPT-4o mini may be better designed for writing code with their lower latency, we’ve also seen o3-mini spike on code production for use cases that are slightly less latency-sensitive.
> “o3-mini consistently produces high-quality, conclusive code, and very frequently arrives at the correct solution when the problem is well-defined, even for very challenging coding tasks. While other models may only be useful for small-scale, quick code iterations, o3-mini excels at planning and executing complex software design systems.”
>
> —[Windsurf](https://codeium.com/), collaborative agentic AI-powered IDE, built by Codeium
### 7. Evaluation and benchmarking for other model responses
We’ve also seen reasoning models do well in benchmarking and evaluating other model responses. Data validation is important for ensuring dataset quality and reliability, especially in sensitive fields like healthcare. Traditional validation methods use predefined rules and patterns, but advanced models like o1 and o3-mini can understand context and reason about data for a more flexible and intelligent approach to validation.
> "Many customers use LLM-as-a-judge as part of their eval process in Braintrust. For example, a healthcare company might summarize patient questions using a workhorse model like gpt-4o, then assess the summary quality with o1. One Braintrust customer saw the F1 score of a judge go from 0.12 with 4o to 0.74 with o1! In these use cases, they’ve found o1’s reasoning to be a game-changer in finding nuanced differences in completions, for the hardest and most complex grading tasks."
>
> —[Braintrust](https://www.braintrust.dev/), AI evals platform
## How to prompt reasoning models effectively
These models perform best with straightforward prompts. Some prompt engineering techniques, like instructing the model to "think step by step," may not enhance performance (and can sometimes hinder it). See best practices below, or [get started with prompt examples](https://developers.openai.com/api/docs/guides/reasoning/advice-on-prompting#prompt-examples).
- **Developer messages are the new system messages**: Starting with `o1-2024-12-17`, reasoning models support developer messages rather than system messages, to align with the chain of command behavior described in the [model spec](https://cdn.openai.com/spec/model-spec-2024-05-08.html#follow-the-chain-of-command).
- **Keep prompts simple and direct**: The models excel at understanding and responding to brief, clear instructions.
- **Avoid chain-of-thought prompts**: Since these models perform reasoning internally, prompting them to "think step by step" or "explain your reasoning" is unnecessary.
- **Use delimiters for clarity**: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
- **Try zero shot first, then few shot if needed**: Reasoning models often don't need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
- **Provide specific guidelines**: If there are ways you explicitly want to constrain the model's response (like "propose a solution with a budget under $500"), explicitly outline those constraints in the prompt.
- **Be very specific about your end goal**: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
- **Markdown formatting**: Starting with `o1-2024-12-17`, reasoning models in the API will avoid generating responses with markdown formatting. To signal to the model when you do want markdown formatting in the response, include the string `Formatting re-enabled` on the first line of your developer message.
## How to keep costs low and accuracy high
With the introduction of `o3` and `o4-mini` models, persisted reasoning items in the Responses API are treated differently. Previously (for `o1`, `o3-mini`, `o1-mini` and `o1-preview`), reasoning items were always ignored in follow‑up API requests, even if they were included in the input items of the requests. With `o3` and `o4-mini`, some reasoning items adjacent to function calls are included in the model’s context to help improve model performance while using the least amount of reasoning tokens.
For the best results with this change, we recommend using the [Responses API](https://developers.openai.com/api/docs/api-reference/responses) with the `store` parameter set to `true`, and passing in all reasoning items from previous requests (either using `previous_response_id`, or by taking all the output items from an older request and passing them in as input items for a new one). OpenAI will automatically include any relevant reasoning items in the model's context and ignore any irrelevant ones. In more advanced use‑cases where you’d like to manage what goes into the model's context more precisely, we recommend that you at least include all reasoning items between the latest function call and the previous user message. Doing this will ensure that the model doesn’t have to restart its reasoning when you respond to a function call, resulting in better function‑calling performance and lower overall token usage.
If you’re using the Chat Completions API, reasoning items are never included in the context of the model. This is because Chat Completions is a stateless API. This will result in slightly degraded model performance and greater reasoning token usage in complex agentic cases involving many function calls. In instances where complex multiple function calling is not involved, there should be no degradation in performance regardless of the API being used.
## Other resources
For more inspiration, visit the [OpenAI Cookbook](https://developers.openai.com/cookbook), which contains example code and links to third-party resources, or learn more about our models and reasoning capabilities:
- [Meet the models](https://developers.openai.com/api/docs/models)
- [Reasoning guide](https://developers.openai.com/api/docs/guides/reasoning)
- [How to use reasoning for validation](https://developers.openai.com/cookbook/examples/o1/using_reasoning_for_data_validation)
- [Video course: Reasoning with o1](https://www.deeplearning.ai/short-courses/reasoning-with-o1/)
- [Papers on advanced prompting to improve reasoning](https://developers.openai.com/cookbook/related_resources#papers-on-advanced-prompting-to-improve-reasoning)
---
# Reasoning models
import {
Question,
Storage,
} from "@components/react/oai/platform/ui/Icon.react";
**Reasoning models** like [GPT-5.5](https://developers.openai.com/api/docs/models/gpt-5.5) use internal reasoning tokens before producing a response. This helps the model plan, use tools effectively, inspect alternatives, recover from ambiguity, and solve harder multi-step tasks. Reasoning models work especially well for complex problem solving, coding, scientific reasoning, and multi-step agentic workflows. They're also the best models for [Codex CLI](https://github.com/openai/codex), our lightweight coding agent.
Start with `gpt-5.5` for most reasoning workloads. If you need the highest-intelligence API option for more challenging problems that can tolerate more latency, use [`gpt-5.5-pro`](https://developers.openai.com/api/docs/models/gpt-5.5-pro). For lower cost, consider `gpt-5.4` and for lower cost and latency, consider `gpt-5.4-mini`.
**Reasoning models work better with the [Responses
API](https://developers.openai.com/api/docs/guides/migrate-to-responses)**. While the Chat Completions API
is still supported, you'll get improved model intelligence and performance by
using Responses.
## Get started with reasoning
Call the [Responses API](https://developers.openai.com/api/docs/api-reference/responses/create) and specify your reasoning model and reasoning effort:
Using a reasoning model in the Responses API
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = \`
Write a bash script that takes a matrix represented as a string with
format '[1,2],[3,4],[5,6]' and prints the transpose in the same format.
\`;
const response = await openai.responses.create({
model: "gpt-5.5",
reasoning: { effort: "low" },
input: [
{
role: "user",
content: prompt,
},
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
prompt = """
Write a bash script that takes a matrix represented as a string with
format '[1,2],[3,4],[5,6]' and prints the transpose in the same format.
"""
response = client.responses.create(
model="gpt-5.5",
reasoning={"effort": "low"},
input=[
{
"role": "user",
"content": prompt
}
]
)
print(response.output_text)
```
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5.5",
"reasoning": {"effort": "low"},
"input": [
{
"role": "user",
"content": "Write a bash script that takes a matrix represented as a string with format \\"[1,2],[3,4],[5,6]\\" and prints the transpose in the same format."
}
]
}'
```
## Reasoning effort
The `reasoning.effort` parameter guides the model on how much to think when performing a task.
Supported values are model-dependent and can include `none`, `minimal`, `low`, `medium`, `high`, and `xhigh`. Lower effort favors speed and lower token usage, while at higher effort the model thinks more completely to provide higher quality responses. The models also reason adaptively across reasoning efforts, using fewer tokens for simpler tasks and thinking harder for complex tasks.
Defaults are also model-dependent rather than universal. `gpt-5.5` defaults to `medium` reasoning effort. This is the best starting point for `gpt-5.5`’s full balance of quality, reliability and performance.
| Effort | Best for... |
| -------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `none` | Latency-critical tasks that do not benefit from any reasoning or multi-chained tool calls. For latency-sensitive use cases with `gpt-5.5`, we recommend trying `low` to begin with and then moving to `none` if required.
Common use cases include voice, fast information retrieval, and classification. |
| `low` | Efficient reasoning with a modest latency increase. Ideal for use cases requiring tool-use, planning, search, or multi-step decision making, while optimizing for speed and cost.
Common use cases include data analysis, drafting, execution-oriented coding, and customer support / chat assistant workflows. |
| `medium` | When quality and reliability matter, and the task involves planning, complex reasoning, and judgement. Default configuration for most workloads, and a well-balanced point on the pareto curve of latency, performance and cost.
Common use cases include agentic coding, research, working with spreadsheets & slides, and delegating long-horizon work. |
| `high` | Hard reasoning, complex debugging, deep planning, and high-value tasks where quality and intelligence matters more than latency. Recommended for complex workflows and agentic tasks.
Common use cases include agentic coding, long-horizon research, and knowledge work. Depending on the complexity of the task, evaluate both `medium` and `high`. |
| `xhigh` | Deep research, asynchronous workflows and agentic tasks that require very long rollouts. Only use when your evals show a clear benefit that justifies the extra latency and cost.
Common use cases include security and code review, enterprise productivity, deeper research tasks, and challenging coding workflows. |
For faster time to first visible token in latency-sensitive applications, ask the model to generate a short preamble before continuing with deeper reasoning.
Some models support only a subset of these values, so check the relevant [model page](https://developers.openai.com/api/docs/models) before choosing a setting.
## How reasoning works
Reasoning models introduce **reasoning tokens** in addition to input and output tokens. The models use these reasoning tokens to "think," breaking down the prompt and considering multiple approaches to generating a response. Our reasoning models like gpt-5.5 and gpt-5.4 support interleaved thinking, where the model is able to generate visible output tokens before and in between thinking, and is able to think in between tool calls.
Here is an example of a multi-step conversation between a user and an assistant. Input and output tokens from each step are carried over, while reasoning tokens are discarded.
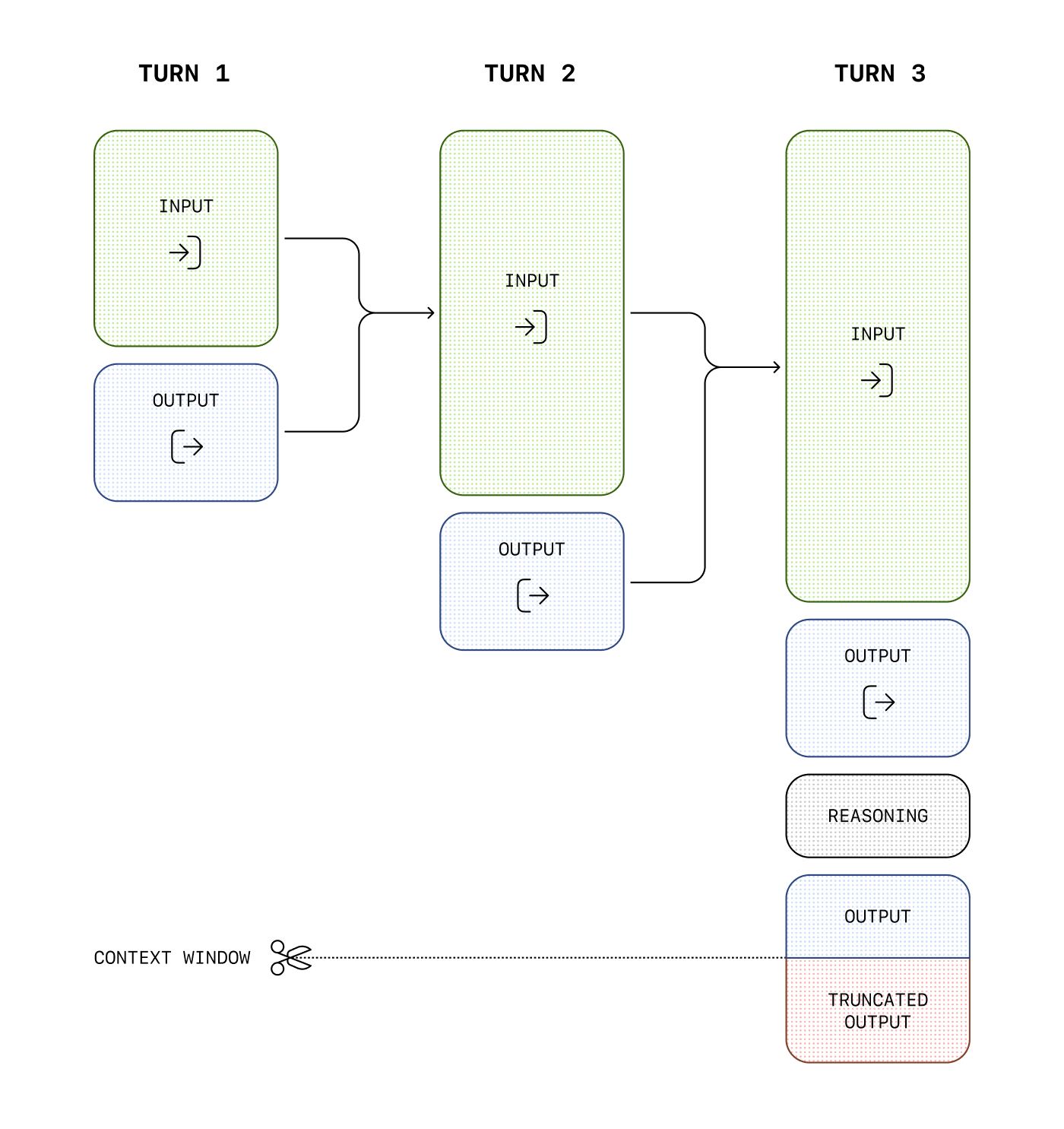
While reasoning tokens are not visible via the API, they still occupy space in
the model's context window and are billed as [output
tokens](https://openai.com/api/pricing).
### Managing the context window
It's important to ensure there's enough space in the context window for reasoning tokens when creating responses. Depending on the problem's complexity, the models may generate anywhere from a few hundred to tens of thousands of reasoning tokens. The exact number of reasoning tokens used is visible in the [usage object of the response object](https://developers.openai.com/api/docs/api-reference/responses/object), under `output_tokens_details`:
```json
{
"usage": {
"input_tokens": 75,
"input_tokens_details": {
"cached_tokens": 0
},
"output_tokens": 1186,
"output_tokens_details": {
"reasoning_tokens": 1024
},
"total_tokens": 1261
}
}
```
Context window lengths are found on the [model reference page](https://developers.openai.com/api/docs/models), and will differ across model snapshots.
### Controlling costs
To manage costs with reasoning models, you can limit the total number of tokens the
model generates (including both reasoning and final output tokens) by using the
[`max_output_tokens`](https://developers.openai.com/api/docs/api-reference/responses/create#responses-create-max_output_tokens)
parameter.
### Allocating space for reasoning
If the generated tokens reach the context window limit or the `max_output_tokens` value you've set, you'll receive a response with a `status` of `incomplete` and `incomplete_details` with `reason` set to `max_output_tokens`. This might occur before any visible output tokens are produced, meaning you could incur costs for input and reasoning tokens without receiving a visible response.
To prevent this, ensure there's sufficient space in the context window or adjust the `max_output_tokens` value to a higher number. OpenAI recommends reserving at least 25,000 tokens for reasoning and outputs when you start experimenting with these models. As you become familiar with the number of reasoning tokens your prompts require, you can adjust this buffer accordingly.
Handling incomplete responses
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = \`
Write a bash script that takes a matrix represented as a string with
format '[1,2],[3,4],[5,6]' and prints the transpose in the same format.
\`;
const response = await openai.responses.create({
model: "gpt-5.5",
reasoning: { effort: "medium" },
input: [
{
role: "user",
content: prompt,
},
],
max_output_tokens: 300,
});
if (
response.status === "incomplete" &&
response.incomplete_details.reason === "max_output_tokens"
) {
console.log("Ran out of tokens");
if (response.output_text?.length > 0) {
console.log("Partial output:", response.output_text);
} else {
console.log("Ran out of tokens during reasoning");
}
}
```
```python
from openai import OpenAI
client = OpenAI()
prompt = """
Write a bash script that takes a matrix represented as a string with
format '[1,2],[3,4],[5,6]' and prints the transpose in the same format.
"""
response = client.responses.create(
model="gpt-5.5",
reasoning={"effort": "medium"},
input=[
{
"role": "user",
"content": prompt
}
],
max_output_tokens=300,
)
if response.status == "incomplete" and response.incomplete_details.reason == "max_output_tokens":
print("Ran out of tokens")
if response.output_text:
print("Partial output:", response.output_text)
else:
print("Ran out of tokens during reasoning")
```
### Keeping reasoning items in context
When doing [function calling](https://developers.openai.com/api/docs/guides/function-calling) with a reasoning model in the [Responses API](https://developers.openai.com/api/docs/api-reference/responses), we highly recommend you pass back any reasoning items returned with the last function call (in addition to the output of your function). If the model calls multiple functions consecutively, you should pass back all reasoning items, function call items, and function call output items, since the last `user` message. This allows the model to continue its reasoning process to produce better results in the most token-efficient manner.
The simplest way to do this is to pass in all reasoning items from a previous response into the next one. Our systems will smartly ignore any reasoning items that aren't relevant to your functions, and only retain those in context that are relevant. You can pass reasoning items from previous responses either using the `previous_response_id` parameter, or by manually passing in all the [output](https://developers.openai.com/api/docs/api-reference/responses/object#responses/object-output) items from a past response into the [input](https://developers.openai.com/api/docs/api-reference/responses/create#responses-create-input) of a new one.
For advanced use cases where you might be truncating and optimizing parts of the context window before passing them on to the next response, just ensure all items between the last user message and your function call output are passed into the next response untouched. This will ensure that the model has all the context it needs.
Check out [this guide](https://developers.openai.com/api/docs/guides/conversation-state) to learn more about manual context management.
### Encrypted reasoning items
When using the Responses API in a stateless mode (either with `store` set to `false`, or when an organization is enrolled in zero data retention), you must still retain reasoning items across conversation turns using the techniques described above. But in order to have reasoning items that can be sent with subsequent API requests, each of your API requests must have `reasoning.encrypted_content` in the `include` parameter of API requests, like so:
```bash
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5.5",
"reasoning": {"effort": "medium"},
"input": "What is the weather like today?",
"tools": [ ... function config here ... ],
"include": [ "reasoning.encrypted_content" ]
}'
```
Any reasoning items in the `output` array will now have an `encrypted_content` property, which will contain encrypted reasoning tokens that can be passed along with future conversation turns.
## Reasoning summaries
While we don't expose the raw reasoning tokens emitted by the model, you can view a summary of the model's reasoning using the `summary` parameter. See our [model documentation](https://developers.openai.com/api/docs/models) to check which reasoning models support summaries.
Different models support different reasoning summary settings. For example, our computer use model supports the `concise` summarizer, while o4-mini supports `detailed`. To access the most detailed summarizer available for a model, set the value of this parameter to `auto`. `auto` will be equivalent to `detailed` for most reasoning models today, but there may be more granular settings in the future.
Reasoning summary output is part of the `summary` array in the `reasoning` [output item](https://developers.openai.com/api/docs/api-reference/responses/object#responses/object-output). This output will not be included unless you explicitly opt in to including reasoning summaries.
The example below shows how to make an API request that includes a reasoning summary.
Include a reasoning summary with the API response
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5.5",
input: "What is the capital of France?",
reasoning: {
effort: "low",
summary: "auto",
},
});
console.log(response.output);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
input="What is the capital of France?",
reasoning={
"effort": "low",
"summary": "auto"
}
)
print(response.output)
```
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5.5",
"input": "What is the capital of France?",
"reasoning": {
"effort": "low",
"summary": "auto"
}
}'
```
This API request will return an output array with both an assistant message and a summary of the model's reasoning in generating that response.
```json
[
{
"id": "rs_6876cf02e0bc8192b74af0fb64b715ff06fa2fcced15a5ac",
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "**Answering a simple question**\n\nI\u2019m looking at a straightforward question: the capital of France is Paris. It\u2019s a well-known fact, and I want to keep it brief and to the point. Paris is known for its history, art, and culture, so it might be nice to add just a hint of that charm. But mostly, I\u2019ll aim to focus on delivering a clear and direct answer, ensuring the user gets what they\u2019re looking for without any extra fluff."
}
]
},
{
"id": "msg_6876cf054f58819284ecc1058131305506fa2fcced15a5ac",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"logprobs": [],
"text": "The capital of France is Paris."
}
],
"role": "assistant"
}
]
```
Before using summarizers with our latest reasoning models, you may need to
complete [organization
verification](https://help.openai.com/en/articles/10910291-api-organization-verification)
to ensure safe deployment. Get started with verification on the [platform
settings page](https://platform.openai.com/settings/organization/general).
## `phase` parameter
For long-running or tool-heavy flows with GPT-5.5 and GPT-5.4 in the Responses API, use the assistant message `phase` field to avoid early stopping and other misbehavior.
`phase` is optional at the API level, but OpenAI recommends using it. Use `phase: "commentary"` for intermediate assistant updates, such as preambles before tool calls, and `phase: "final_answer"` for the completed answer. Don't add `phase` to user messages.
Using `previous_response_id` is usually the simplest path because prior assistant state is preserved. If you replay assistant history manually, preserve each original `phase` value.
Missing or dropped `phase` can cause preambles to be treated as final answers in those workflows. For model-specific prompt guidance, see [Prompting GPT-5.5](https://developers.openai.com/api/docs/guides/prompt-guidance?model=gpt-5.5#phase-parameter).
### Round-trip assistant phase values
## Advice on prompting
There are some differences to consider when prompting a reasoning model. Reasoning-capable GPT-5 models usually work best when you give them a clear goal, strong constraints, and an explicit output contract without prescribing every intermediate step.
- Give the model the task, constraints, and desired output format.
- Treat `reasoning.effort` as a tuning knob, not the primary way to recover quality.
- For agentic or research-heavy workflows, define what counts as done and how the model should verify its work.
For more information on best practices when using reasoning models, [refer to this guide](https://developers.openai.com/api/docs/guides/reasoning-best-practices).
### Prompt examples
## Use case examples
Some examples of using reasoning models for real-world use cases can be found in [the cookbook](https://developers.openai.com/cookbook).
Evaluate a synthetic medical data set for discrepancies.
Use help center articles to generate actions that an agent could perform.
---
# Reinforcement fine-tuning
Reinforcement fine-tuning (RFT) adapts an OpenAI reasoning model with a feedback signal you define. Like [supervised fine-tuning](https://developers.openai.com/api/docs/guides/supervised-fine-tuning), it tailors the model to your task. The difference is that instead of training on fixed “correct” answers, it relies on a programmable grader that scores every candidate response. The training algorithm then shifts the model’s weights, so high-scoring outputs become more likely and low-scoring ones fade.
OpenAI is winding down the fine-tuning platform. The platform is no longer
accessible to new users, but existing users of the fine-tuning platform will
be able to create training jobs for the coming months.
All fine-tuned models will remain available for inference until their base
models are [deprecated](https://developers.openai.com/api/docs/deprecations). The full timeline is
[here](https://developers.openai.com/api/docs/deprecations).
| How it works |
Best for |
Use with |
|
Generate a response for a prompt, provide an expert grade for the result, and reinforce the model's chain-of-thought for higher-scored responses.
Requires expert graders to agree on the ideal output from the model.
|
- Complex domain-specific tasks that require advanced reasoning
- Medical diagnoses based on history and diagnostic guidelines
- Determining relevant passages from legal case law
|
`o4-mini-2025-04-16`
**Reasoning models only**.
|
This optimization lets you align the model with nuanced objectives like style, safety, or domain accuracy—with many [practical use cases](https://developers.openai.com/api/docs/guides/rft-use-cases) emerging. Run RFT in five steps:
1. Implement a [grader](https://developers.openai.com/api/docs/guides/graders) that assigns a numeric reward to each model response.
1. Upload your prompt dataset and designate a validation split.
1. Start the fine-tune job.
1. Monitor and [evaluate](https://developers.openai.com/api/docs/guides/evals) checkpoints; revise data or grader if needed.
1. Deploy the resulting model through the standard API.
During training, the platform cycles through the dataset, samples several responses per prompt, scores them with the grader, and applies policy-gradient updates based on those rewards. The loop continues until we hit the end of your training data or you stop the job at a chosen checkpoint, producing a model optimized for the metric that matters to you.
When should I use reinforcement fine-tuning?
It's useful to understand the strengths and weaknesses of reinforcement fine-tuning to identify opportunities and to avoid wasted effort.
- **RFT works best with unambiguous tasks**. Check whether qualified human experts agree on the answers. If conscientious experts working independently (with access only to the same instructions and information as the model) do not converge on the same answers, the task may be too ambiguous and may benefit from revision or reframing.
- **Your task must be compatible with the grading options**. Review [grading options in the API](https://developers.openai.com/api/docs/api-reference/graders) first and verify it's possible to grade your task with them.
- **Your eval results must be variable enough to improve**. Run [evals](https://developers.openai.com/api/docs/guides/evals) before using RFT. If your eval scores between minimum and maximum possible scores, you'll have enough data to work with to reinforce positive answers. If the model you want to fine-tune scores at either the absolute minimum or absolute maximum score, RFT won't be useful to you.
- **Your model must have some success at the desired task**. Reinforcement fine-tuning makes gradual changes, sampling many answers and choosing the best ones. If a model has a 0% success rate at a given task, you cannot bootstrap to higher performance levels through RFT.
- **Your task should be guess-proof**. If the model can get a higher reward from a lucky guess, the training signal is too noisy, as the model can get the right answer with an incorrect reasoning process. Reframe your task to make guessing more difficult—for example, by expanding classes into subclasses or revising a multiple choice problem to take open-ended answers.
See common use cases, specific implementations, and grader examples in the [reinforcement fine-tuning use case guide](https://developers.openai.com/api/docs/guides/rft-use-cases).
What is reinforcement learning?
Reinforcement learning is a branch of machine learning in which a model learns by acting, receiving feedback, and readjusting itself to maximise future feedback. Instead of memorising one “right” answer per example, the model explores many possible answers, observes a numeric reward for each, and gradually shifts its behaviour so the high-reward answers become more likely and the low-reward ones disappear. Over repeated rounds, the model converges on a policy—a rule for choosing outputs—that best satisfies the reward signal you define.
In reinforcement fine-tuning (RFT), that reward signal comes from a custom grader that you define for your task. For every prompt in your dataset, the platform samples multiple candidate answers, runs your grader to score them, and applies a policy-gradient update that nudges the model toward answers with higher scores. This cycle—sample, grade, update—continues across the dataset (and successive epochs) until the model reliably optimizes for your grader’s understanding of quality. The grader encodes whatever you care about—accuracy, style, safety, or any metric—so the resulting fine-tuned model reflects those priorities and you don't have to manage reinforcement learning infrastructure.
Reinforcement fine-tuning is supported on o-series reasoning models only, and
currently only for [o4-mini](https://developers.openai.com/api/docs/models/o4-mini).
## Example: LLM-powered security review
To demonstrate reinforcement fine-tuning below, we'll fine-tune an [o4-mini](https://developers.openai.com/api/docs/models/o4-mini) model to provide expert answers about a fictional company's security posture, based on an internal company policy document. We want the model to return a JSON object that conforms to a specific schema with [Structured Outputs](https://developers.openai.com/api/docs/guides/structured-outputs).
Example input question:
```
Do you have a dedicated security team?
```
Using the internal policy document, we want the model to respond with JSON that has two keys:
- `compliant`: A string `yes`, `no`, or `needs review`, indicating whether the company's policy covers the question.
- `explanation`: A string of text that briefly explains, based on the policy document, why the question is covered in the policy or why it's not covered.
Example desired output from the model:
```json
{
"compliant": "yes",
"explanation": "A dedicated security team follows strict protocols for handling incidents."
}
```
Let's fine-tune a model with RFT to perform well at this task.
## Define a grader
To perform RFT, define a [grader](https://developers.openai.com/api/docs/guides/graders) to score the model's output during training, indicating the quality of its response. RFT uses the same set of graders as [evals](https://developers.openai.com/api/docs/guides/evals), which you may already be familiar with.
In this example, we define [multiple graders](https://developers.openai.com/api/docs/api-reference/graders/multi) to examine the properties of the JSON returned by our fine-tuned model:
- The [`string_check`](https://developers.openai.com/api/docs/api-reference/graders/string-check) grader to ensure the proper `compliant` property has been set
- The [`score_model`](https://developers.openai.com/api/docs/api-reference/graders/score-model) grader to provide a score between zero and one for the explanation text, using another evaluator model
We weight the output of each property equally in the `calculate_output` expression.
Below is the JSON payload data we'll use for this grader in API requests. In both graders, we use `{{ }}` template syntax to refer to the relevant properties of both the `item` (the row of test data being used for evaluation) and `sample` (the model output generated during the training run).
## Prepare your dataset
To create an RFT fine-tune, you'll need both a training and test dataset. Both the training and test datasets will share the same [JSONL format](https://jsonlines.org/). Each line in the JSONL data file will contain a `messages` array, along with any additional fields required to grade the output from the model. The full specification for RFT dataset [can be found here](https://developers.openai.com/api/docs/api-reference/fine-tuning/reinforcement-input).
In our case, in addition to the `messages` array, each line in our JSONL file also needs `compliant` and `explanation` properties, which we can use as reference values to test the fine-tuned model's Structured Output.
A single line in our training and test datasets looks like this as indented JSON:
```json
{
"messages": [
{
"role": "user",
"content": "Do you have a dedicated security team?"
}
],
"compliant": "yes",
"explanation": "A dedicated security team follows strict protocols for handling incidents."
}
```
Below, find some JSONL data you can use for both training and testing when you create your fine-tune job. Note that these datasets are for illustration purposes only—in your real test data, strive for diverse and representative inputs for your application.
**Training set**
```
{"messages":[{"role":"user","content":"Do you have a dedicated security team?"}],"compliant":"yes","explanation":"A dedicated security team follows strict protocols for handling incidents."}
{"messages":[{"role":"user","content":"Have you undergone third-party security audits or penetration testing in the last 12 months?"}],"compliant":"needs review","explanation":"The policy does not explicitly mention undergoing third-party security audits or penetration testing. It only mentions SOC 2 and GDPR compliance."}
{"messages":[{"role":"user","content":"Is your software SOC 2, ISO 27001, or similarly certified?"}],"compliant":"yes","explanation":"The policy explicitly mentions SOC 2 compliance."}
```
**Test set**
```
{"messages":[{"role":"user","content":"Will our data be encrypted at rest?"}],"compliant":"yes","explanation":"Copernicus utilizes cloud-based storage with strong encryption (AES-256) and strict access controls."}
{"messages":[{"role":"user","content":"Will data transmitted to/from your services be encrypted in transit?"}],"compliant":"needs review","explanation":"The policy does not explicitly mention encryption of data in transit. It focuses on encryption in cloud storage."}
{"messages":[{"role":"user","content":"Do you enforce multi-factor authentication (MFA) internally?"}],"compliant":"yes","explanation":"The policy explicitly mentions role-based authentication with multi-factor security."}
```
How much training data is needed?
Start small—between several dozen and a few hundred examples—to determine the usefulness of RFT before investing in a large dataset. For product safety reasons, the training set must first pass through an automated screening process. Large datasets take longer to process. This screening process begins when you start a fine-tuning job with a file, not upon initial file upload. Once a file has successfully completed screening, you can use it repeatedly without delay.
Dozens of examples can be meaningful as long as they're high quality. After screening, more data is better, as long as it remains high quality. With larger datasets, you can use a higher batch size, which tends to improve training stability.
Your training file can contain a maximum of 50,000 examples. Test datasets can contain a maximum of 1,000 examples. Test datasets also go through automated screening.
### Upload your files
The process for uploading RFT training and test data files is the same as [supervised fine-tuning](https://developers.openai.com/api/docs/guides/supervised-fine-tuning). Upload your training data to OpenAI either through the [API](https://developers.openai.com/api/docs/api-reference/files/create) or [using our UI](https://platform.openai.com/storage). Files must be uploaded with a purpose of `fine-tune` in order to be used with fine-tuning.
**You need file IDs for both your test and training data files** to create a fine-tune job.
## Create a fine-tune job
Create a fine-tune job using either the [API](https://developers.openai.com/api/docs/api-reference/fine-tuning) or [fine-tuning dashboard](https://platform.openai.com/finetune). To do this, you need:
- File IDs for both your training and test datasets
- The grader configuration we created earlier
- The model ID you want to use as a base for fine-tuning (we'll use `o4-mini-2025-04-16`)
- If you're fine-tuning a model that will return JSON data as a structured output, you need the JSON schema for the returned object as well (see below)
- Optionally, any hyperparameters you want to configure for the fine-tune
- To qualify for [data sharing inference pricing](https://developers.openai.com/api/docs/pricing#fine-tuning), you need to first [share evaluation and fine-tuning data](https://help.openai.com/en/articles/10306912-sharing-feedback-evaluation-and-fine-tuning-data-and-api-inputs-and-outputs-with-openai#h_c93188c569) with OpenAI before creating the job
### Structured Outputs JSON schema
If you're fine-tuning a model to return [Structured Outputs](https://developers.openai.com/api/docs/guides/structured-outputs), provide the JSON schema being used to format the output. See a valid JSON schema for our security interview use case:
```json
{
"type": "json_schema",
"json_schema": {
"name": "security_assistant",
"strict": true,
"schema": {
"type": "object",
"properties": {
"compliant": { "type": "string" },
"explanation": { "type": "string" }
},
"required": ["compliant", "explanation"],
"additionalProperties": false
}
}
}
```
Generating a JSON schema from a Pydantic model
To simplify JSON schema generation, start from a Pydantic BaseModel class:
1. Define your class
1. Use `to_strict_json_schema` from the OpenAI library to generate a valid schema
1. Wrap the schema in a dictionary with `type` and `name` keys, and set `strict` to true
1. Take the resulting object and supply it as the `response_format` in your RFT job
```python
from openai.lib._pydantic import to_strict_json_schema
from pydantic import BaseModel
class MyCustomClass(BaseModel):
name: str
age: int
# Note: Do not use MyCustomClass.model_json_schema() in place of
# to_strict_json_schema as it is not equivalent
schema = to_strict_json_schema(MyCustomClass)
response_format = dict(
type="json_schema",
json_schema=dict(
name=MyCustomClass.__name__,
strict=True,
schema=schema
)
)
```
### Create a job with the API
Configuring a job with the API has a lot of moving parts, so many users prefer to configure them in the [fine-tuning dashboard UI](https://platform.openai.com/finetune). However, here's a complete API request to kick off a fine-tune job with all the configuration we've set up in this guide so far:
```bash
curl https://api.openai.com/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"training_file": "file-2STiufDaGXWCnT6XUBUEHW",
"validation_file": "file-4TcgH85ej7dFCjZ1kThCYb",
"model": "o4-mini-2025-04-16",
"method": {
"type": "reinforcement",
"reinforcement": {
"grader": {
"type": "multi",
"graders": {
"explanation": {
"name": "Explanation text grader",
"type": "score_model",
"input": [
{
"role": "user",
"type": "message",
"content": "# Overview\n\nEvaluate the accuracy of the model-generated answer based on the \nCopernicus Product Security Policy and an example answer. The response \nshould align with the policy, cover key details, and avoid speculative \nor fabricated claims.\n\nAlways respond with a single floating point number 0 through 1,\nusing the grading criteria below.\n\n## Grading Criteria:\n- **1.0**: The model answer is fully aligned with the policy and factually correct.\n- **0.75**: The model answer is mostly correct but has minor omissions or slight rewording that does not change meaning.\n- **0.5**: The model answer is partially correct but lacks key details or contains speculative statements.\n- **0.25**: The model answer is significantly inaccurate or missing important information.\n- **0.0**: The model answer is completely incorrect, hallucinates policy details, or is irrelevant.\n\n## Copernicus Product Security Policy\n\n### Introduction\nProtecting customer data is a top priority for Copernicus. Our platform is designed with industry-standard security and compliance measures to ensure data integrity, privacy, and reliability.\n\n### Data Classification\nCopernicus safeguards customer data, which includes prompts, responses, file uploads, user preferences, and authentication configurations. Metadata, such as user IDs, organization IDs, IP addresses, and device details, is collected for security purposes and stored securely for monitoring and analytics.\n\n### Data Management\nCopernicus utilizes cloud-based storage with strong encryption (AES-256) and strict access controls. Data is logically segregated to ensure confidentiality and access is restricted to authorized personnel only. Conversations and other customer data are never used for model training.\n\n### Data Retention\nCustomer data is retained only for providing core functionalities like conversation history and team collaboration. Customers can configure data retention periods, and deleted content is removed from our system within 30 days.\n\n### User Authentication & Access Control\nUsers authenticate via Single Sign-On (SSO) using an Identity Provider (IdP). Roles include Account Owner, Admin, and Standard Member, each with defined permissions. User provisioning can be automated through SCIM integration.\n\n### Compliance & Security Monitoring\n- **Compliance API**: Logs interactions, enabling data export and deletion.\n- **Audit Logging**: Ensures transparency for security audits.\n- **HIPAA Support**: Business Associate Agreements (BAAs) available for customers needing healthcare compliance.\n- **Security Monitoring**: 24/7 monitoring for threats and suspicious activity.\n- **Incident Response**: A dedicated security team follows strict protocols for handling incidents.\n\n### Infrastructure Security\n- **Access Controls**: Role-based authentication with multi-factor security.\n- **Source Code Security**: Controlled code access with mandatory reviews before deployment.\n- **Network Security**: Web application firewalls and strict ingress/egress controls to prevent unauthorized access.\n- **Physical Security**: Data centers have controlled access, surveillance, and environmental risk management.\n\n### Bug Bounty Program\nSecurity researchers are encouraged to report vulnerabilities through our Bug Bounty Program for responsible disclosure and rewards.\n\n### Compliance & Certifications\nCopernicus maintains compliance with industry standards, including SOC 2 and GDPR. Customers can access security reports and documentation via our Security Portal.\n\n### Conclusion\nCopernicus prioritizes security, privacy, and compliance. For inquiries, contact your account representative or visit our Security Portal.\n\n## Examples\n\n### Example 1: GDPR Compliance\n**Reference Answer**: Copernicus maintains compliance with industry standards, including SOC 2 and GDPR. Customers can access security reports and documentation via our Security Portal.\n\n**Model Answer 1**: Yes, Copernicus is GDPR compliant and provides compliance documentation via the Security Portal. \n**Score: 1.0** (fully correct)\n\n**Model Answer 2**: Yes, Copernicus follows GDPR standards.\n**Score: 0.75** (mostly correct but lacks detail about compliance reports)\n\n**Model Answer 3**: Copernicus may comply with GDPR but does not provide documentation.\n**Score: 0.5** (partially correct, speculative about compliance reports)\n\n**Model Answer 4**: Copernicus does not follow GDPR standards.\n**Score: 0.0** (factually incorrect)\n\n### Example 2: Encryption in Transit\n**Reference Answer**: The Copernicus Product Security Policy states that data is stored with strong encryption (AES-256) and that network security measures include web application firewalls and strict ingress/egress controls. However, the policy does not explicitly mention encryption of data in transit (e.g., TLS encryption). A review is needed to confirm whether data transmission is encrypted.\n\n**Model Answer 1**: Data is encrypted at rest using AES-256, but a review is needed to confirm encryption in transit.\n**Score: 1.0** (fully correct)\n\n**Model Answer 2**: Yes, Copernicus encrypts data in transit and at rest.\n**Score: 0.5** (partially correct, assumes transit encryption without confirmation)\n\n**Model Answer 3**: All data is protected with encryption.\n**Score: 0.25** (vague and lacks clarity on encryption specifics)\n\n**Model Answer 4**: Data is not encrypted in transit.\n**Score: 0.0** (factually incorrect)\n\nReference Answer: {{item.explanation}}\nModel Answer: {{sample.output_json.explanation}}\n"
}
],
"model": "gpt-4o-2024-08-06"
},
"compliant": {
"name": "compliant",
"type": "string_check",
"reference": "{{item.compliant}}",
"operation": "eq",
"input": "{{sample.output_json.compliant}}"
}
},
"calculate_output": "0.5 * compliant + 0.5 * explanation"
},
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "security_assistant",
"strict": true,
"schema": {
"type": "object",
"properties": {
"compliant": {
"type": "string"
},
"explanation": {
"type": "string"
}
},
"required": [
"compliant",
"explanation"
],
"additionalProperties": false
}
}
},
"hyperparameters": {
"reasoning_effort": "medium"
}
}
}
}'
```
This request returns a [fine-tuning job object](https://developers.openai.com/api/docs/api-reference/fine-tuning/object), which includes a job `id`. Use this ID to monitor the progress of your job and retrieve the fine-tuned model when the job is complete.
To qualify for [data sharing inference pricing](https://developers.openai.com/api/docs/pricing#fine-tuning), make sure to [share evaluation and fine-tuning data](https://help.openai.com/en/articles/10306912-sharing-feedback-evaluation-and-fine-tuning-data-and-api-inputs-and-outputs-with-openai#h_c93188c569) with OpenAI before creating the job. You can verify the job was marked as shared by confirming `shared_with_openai` is set to `true`.
### Monitoring your fine-tune job
Fine-tuning jobs take some time to complete, and RFT jobs tend to take longer than SFT or DPO jobs. To monitor the progress of your fine-tune job, use the [fine-tuning dashboard](https://platform.openai.com/finetune) or the [API](https://developers.openai.com/api/docs/api-reference/fine-tuning).
#### Reward metrics
For reinforcement fine-tuning jobs, the primary metrics are the per-step **reward** metrics. These metrics indicate how well your model is performing on the training data. They're calculated by the graders you defined in your job configuration. These are two separate top-level reward metrics:
- `train_reward_mean`: The average reward across the samples taken from all datapoints in the current step. Because the specific datapoints in a batch change with each step, `train_reward_mean` values across different steps are not directly comparable and the specific values can fluctuate drastically from step to step.
- `valid_reward_mean`: The average reward across the samples taken from all datapoints in the validation set, which is a more stable metric.
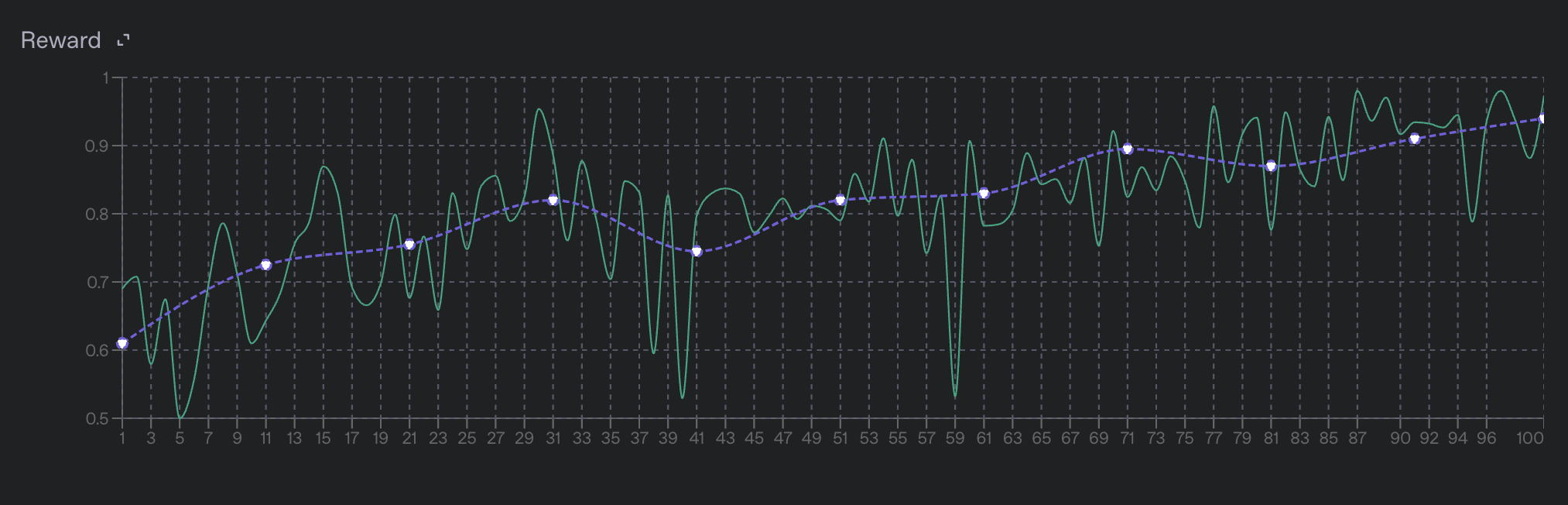
Find a full description of all training metrics in the [training metrics](#training-metrics) section.
#### Pausing and resuming jobs
To evaluate the current state of the model when your job is only partially finished, **pause** the job to stop the training process and produce a checkpoint at the current step. You can use this checkpoint to evaluate the model on a held-out test set. If the results look good, **resume** the job to continue training from that checkpoint. Learn more in [pausing and resuming jobs](#pausing-and-resuming-jobs).
#### Evals integration
Reinforcement fine-tuning jobs are integrated with our [evals product](https://developers.openai.com/api/docs/guides/evals). When you make a reinforcement fine-tuning job, a new eval is automatically created and associated with the job. As validation steps are performed, we combine the input prompts, model samples, and grader outputs to make a new [eval run](https://developers.openai.com/api/docs/guides/evals#creating-an-eval-run) for that step.
Learn more about the evals integration in the [appendix](#evals-integration-details) section below.
## Evaluate the results
By the time your fine-tuning job finishes, you should have a decent idea of how well the model is performing based on the mean reward value on the validation set. However, it's possible that the model has either _overfit_ to the training data or has learned to [reward hack](https://en.wikipedia.org/wiki/Reward_hacking) your grader, which allows it to produce high scores without actually being correct. Before deploying your model, inspect its behavior on a representative set of prompts to ensure it behaves how you expect.
Understanding the model's behavior can be done quickly by inspecting the evals associated with the fine-tuning job. Specifically, pay close attention to the run made for the final training step to see the end model's behavior. You can also use the evals product to compare the final run to earlier runs and see how the model's behavior has changed over the course of training.
### Try using your fine-tuned model
Evaluate your newly optimized model by using it! When the fine-tuned model finishes training, use its ID in either the [Responses](https://developers.openai.com/api/docs/api-reference/responses) or [Chat Completions](https://developers.openai.com/api/docs/api-reference/chat) API, just as you would an OpenAI base model.
Use your model in the Playground
Use your model with an API call
### Use checkpoints if needed
Checkpoints are models you can use that are created before the final step of the training process. For RFT, OpenAI creates a full model checkpoint at each validation step and keeps the three with the highest `valid_reward_mean` scores. Checkpoints are useful for evaluating the model at different points in the training process and comparing performance at different steps.
Find checkpoints in the dashboard
Query the API for checkpoints
## Safety checks
Before launching in production, review and follow the following safety information.
How we assess for safety
Once a fine-tuning job is completed, we assess the resulting model’s behavior across 13 distinct safety categories. Each category represents a critical area where AI outputs could potentially cause harm if not properly controlled.
| Name | Description |
| :--------------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| advice | Advice or guidance that violates our policies. |
| harassment/threatening | Harassment content that also includes violence or serious harm towards any target. |
| hate | Content that expresses, incites, or promotes hate based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. Hateful content aimed at non-protected groups (e.g., chess players) is harassment. |
| hate/threatening | Hateful content that also includes violence or serious harm towards the targeted group based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. |
| highly-sensitive | Highly sensitive data that violates our policies. |
| illicit | Content that gives advice or instruction on how to commit illicit acts. A phrase like "how to shoplift" would fit this category. |
| propaganda | Praise or assistance for ideology that violates our policies. |
| self-harm/instructions | Content that encourages performing acts of self-harm, such as suicide, cutting, and eating disorders, or that gives instructions or advice on how to commit such acts. |
| self-harm/intent | Content where the speaker expresses that they are engaging or intend to engage in acts of self-harm, such as suicide, cutting, and eating disorders. |
| sensitive | Sensitive data that violates our policies. |
| sexual/minors | Sexual content that includes an individual who is under 18 years old. |
| sexual | Content meant to arouse sexual excitement, such as the description of sexual activity, or that promotes sexual services (excluding sex education and wellness). |
| violence | Content that depicts death, violence, or physical injury. |
Each category has a predefined pass threshold; if too many evaluated examples in a given category fail, OpenAI blocks the fine-tuned model from deployment. If your fine-tuned model does not pass the safety checks, OpenAI sends a message in the fine-tuning job explaining which categories don't meet the required thresholds. You can view the results in the moderation checks section of the fine-tuning job.
How to pass safety checks
In addition to reviewing any failed safety checks in the fine-tuning job object, you can retrieve details about which categories failed by querying the [fine-tuning API events endpoint](https://developers.openai.com/api/docs/api-reference/fine-tuning/list-events). Look for events of type `moderation_checks` for details about category results and enforcement. This information can help you narrow down which categories to target for retraining and improvement. The [model spec](https://cdn.openai.com/spec/model-spec-2024-05-08.html#overview) has rules and examples that can help identify areas for additional training data.
While these evaluations cover a broad range of safety categories, conduct your own evaluations of the fine-tuned model to ensure it's appropriate for your use case.
## Next steps
Now that you know the basics of reinforcement fine-tuning, explore other fine-tuning methods.
[
Fine-tune a model by providing correct outputs for sample inputs.
](https://developers.openai.com/api/docs/guides/supervised-fine-tuning)
[
Learn to fine-tune for computer vision with image inputs.
](https://developers.openai.com/api/docs/guides/vision-fine-tuning)
[
Fine-tune a model using direct preference optimization (DPO).
](https://developers.openai.com/api/docs/guides/direct-preference-optimization)
## Appendix
### Training metrics
Reinforcement fine-tuning jobs publish per-step training metrics as [fine-tuning events](https://developers.openai.com/api/docs/api-reference/fine-tuning/event-object). Pull these metrics through the [API](https://developers.openai.com/api/docs/api-reference/fine-tuning/list-events) or view them as graphs and charts in the [fine-tuning dashboard](https://platform.openai.com/finetune).
Learn more about training metrics below.
Full example training metrics
Below is an example metric event from a real reinforcement fine-tuning job. The various fields in this payload will be discussed in the following sections.
```json
{
"object": "fine_tuning.job.event",
"id": "ftevent-Iq5LuNLDsac1C3vzshRBuBIy",
"created_at": 1746679539,
"level": "info",
"message": "Step 10/20 , train mean reward=0.42, full validation mean reward=0.68, full validation mean parse error=0.00",
"data": {
"step": 10,
"usage": {
"graders": [
{
"name": "basic_model_grader",
"type": "score_model",
"model": "gpt-4o-2024-08-06",
"train_prompt_tokens_mean": 241.0,
"valid_prompt_tokens_mean": 241.0,
"train_prompt_tokens_count": 120741.0,
"valid_prompt_tokens_count": 4820.0,
"train_completion_tokens_mean": 138.52694610778443,
"valid_completion_tokens_mean": 140.5,
"train_completion_tokens_count": 69402.0,
"valid_completion_tokens_count": 2810.0
}
],
"samples": {
"train_reasoning_tokens_mean": 3330.017964071856,
"valid_reasoning_tokens_mean": 1948.9,
"train_reasoning_tokens_count": 1668339.0,
"valid_reasoning_tokens_count": 38978.0
}
},
"errors": {
"graders": [
{
"name": "basic_model_grader",
"type": "score_model",
"train_other_error_mean": 0.0,
"valid_other_error_mean": 0.0,
"train_other_error_count": 0.0,
"valid_other_error_count": 0.0,
"train_sample_parse_error_mean": 0.0,
"valid_sample_parse_error_mean": 0.0,
"train_sample_parse_error_count": 0.0,
"valid_sample_parse_error_count": 0.0,
"train_invalid_variable_error_mean": 0.0,
"valid_invalid_variable_error_mean": 0.0,
"train_invalid_variable_error_count": 0.0,
"valid_invalid_variable_error_count": 0.0
}
]
},
"scores": {
"graders": [
{
"name": "basic_model_grader",
"type": "score_model",
"train_reward_mean": 0.4471057884231537,
"valid_reward_mean": 0.675
}
],
"train_reward_mean": 0.4215686274509804,
"valid_reward_mean": 0.675
},
"timing": {
"step": {
"eval": 101.69386267662048,
"sampling": 226.82190561294556,
"training": 402.43121099472046,
"full_iteration": 731.5038568973541
},
"graders": [
{
"name": "basic_model_grader",
"type": "score_model",
"train_execution_latency_mean": 2.6894934929297594,
"valid_execution_latency_mean": 4.141402995586395
}
]
},
"total_steps": 20,
"train_mean_reward": 0.4215686274509804,
"reasoning_tokens_mean": 3330.017964071856,
"completion_tokens_mean": 3376.0019607843137,
"full_valid_mean_reward": 0.675,
"mean_unresponsive_rewards": 0.0,
"model_graders_token_usage": {
"gpt-4o-2024-08-06": {
"eval_cached_tokens": 0,
"eval_prompt_tokens": 4820,
"train_cached_tokens": 0,
"train_prompt_tokens": 120741,
"eval_completion_tokens": 2810,
"train_completion_tokens": 69402
}
},
"full_valid_mean_parse_error": 0.0,
"valid_reasoning_tokens_mean": 1948.9
},
"type": "metrics"
},
```
Score metrics
The top-level metrics to watch are `train_reward_mean` and `valid_reward_mean`, which indicate the average reward assigned by your graders across all samples in the training and validation datasets, respectively.
Additionally, if you use a [multi-grader](https://developers.openai.com/api/docs/api-reference/graders/multi) configuration, per-grader train and validation reward metrics will be published as well. These metrics are included under the `event.data.scores` object in the fine-tuning events object, with one entry per grader. The per-grader metrics are useful for understanding how the model is performing on each individual grader, and can help you identify if the model is overfitting to one grader or another.
From the fine-tuning dashboard, the individual grader metrics will be displayed in their own graph below the overall `train_reward_mean` and `valid_reward_mean` metrics.
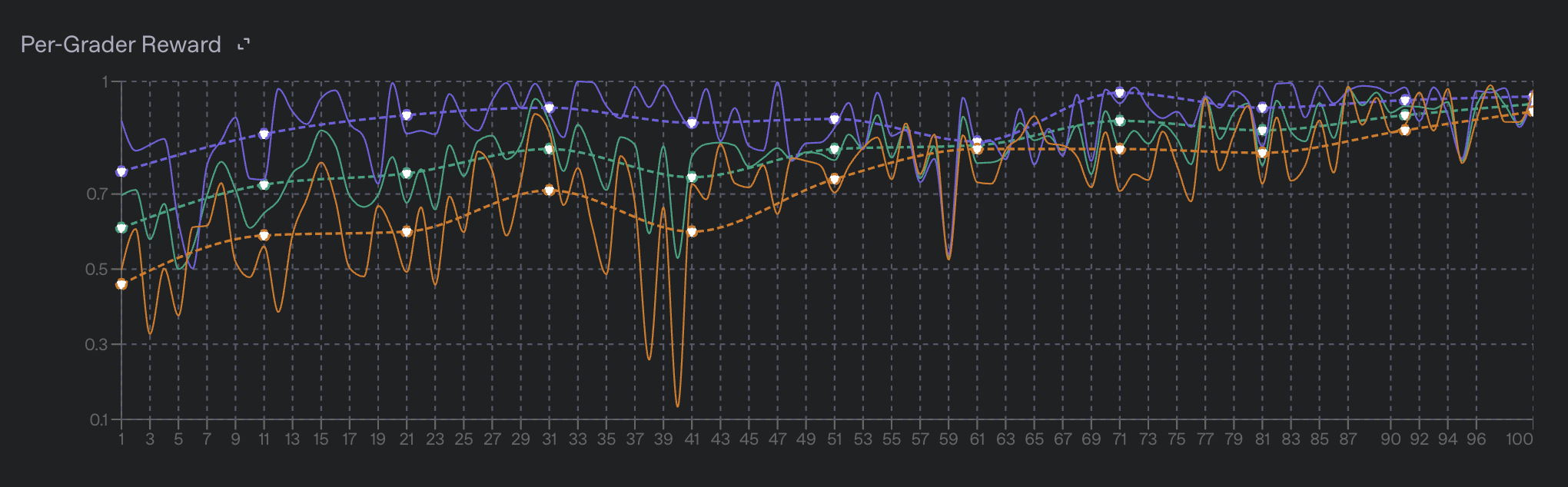
Usage metrics
An important characteristic of a reasoning model is the number of reasoning tokens it uses before responding to a prompt. Often, during training, the model will drastically change the average number of reasoning tokens it uses to respond to a prompt. This is a sign that the model is changing its behavior in response to the reward signal. The model may learn to use fewer reasoning tokens to achieve the same reward, or it may learn to use more reasoning tokens to achieve a higher reward.
You can monitor the `train_reasoning_tokens_mean` and `valid_reasoning_tokens_mean` metrics to see how the model is changing its behavior over time. These metrics are the average number of reasoning tokens used by the model to respond to a prompt in the training and validation datasets, respectively. You can also view the mean reasoning token count in the fine-tuning dashboard under the "Reasoning Tokens" chart.
If you are using [model graders](https://developers.openai.com/api/docs/guides/graders#model-graders), you will likely want to monitor the token usage of these graders. Per-grader token usage statistics are available under the `event.data.usage.graders` object, and are broken down into:
- `train_prompt_tokens_mean`
- `train_prompt_tokens_count`
- `train_completion_tokens_mean`
- `train_completion_tokens_count`.
The `_mean` metrics represent the average number of tokens used by the grader to process all prompts in the current step, while the `_count` metrics represent the total number of tokens used by the grader across all samples in the current step. The per-step token usage is also displayed on the fine-tuning dashboard under the "Grading Token Usage" chart.
Timing metrics
We include various metrics that help you understand how long each step of the training process is taking and how different parts of the training process are contributing to the per-step timing.
These metrics are available under the `event.data.timing` object, and are broken down into `step` and `graders` fields.
The `step` field contains the following metrics:
- `sampling`: The time taken to sample the model outputs (rollouts) for the current step.
- `training`: The time taken to train the model (backpropagation) for the current step.
- `eval`: The time taken to evaluate the model on the full validation set.
- `full_iteration`: The total time taken for the current step, including the above 3 metrics plus any additional overhead.
The step timing metrics are also displayed on the fine-tuning dashboard under the "Per Step Duration" chart.
The `graders` field contains timing information that details the time taken to execute each grader for the current step. Each grader will have its own timing under the `train_execution_latency_mean` and `valid_execution_latency_mean` metrics, which represent the average time taken to execute the grader on the training and validation datasets, respectively.
Graders are executed in parallel with a concurrency limit, so it is not always clear how individual grader latency adds up to the total time taken for grading. However, it is generally true that graders which take longer to execute individually will cause a job to execute more slowly. This means that slower model graders will cause the job to take longer to complete, and more expensive python code will do the same. The fastest graders generally are `string_check` and `text_similarity` as those are executed local to the training loop.
### Evals integration details
Reinforcement fine-tuning jobs are directly integrated with our [evals product](https://developers.openai.com/api/docs/guides/evals). When you make a reinforcement fine-tuning job, a new eval is automatically created and associated with the job.
As validation steps are performed, the input prompts, model samples, grader outputs, and more metadata will be combined to make a new [eval run](https://developers.openai.com/api/docs/guides/evals#creating-an-eval-run) for that step. At the end of the job, you will have one run for each validation step. This allows you to compare the performance of the model at different steps, and to see how the model's behavior has changed over the course of training.
You can find the eval associated with your fine-tuning job by viewing your job on the fine-tuning dashboard, or by finding the `eval_id` field on the [fine-tuning job object](https://developers.openai.com/api/docs/api-reference/fine-tuning/object).
The evals product is useful for inspecting the outputs of the model on specific datapoints, to get an understanding for how the model is behaving in different scenarios. It can help you figure out which slice of your dataset the model is performing poorly on which can help you identify areas for improvement in your training data.
The evals product can also help you find areas of improvement for your graders by finding areas where the grader is either overly lenient or overly harsh on the model outputs.
### Pausing and resuming jobs
You can pause a fine-tuning job at any time by using the [fine-tuning jobs API](https://developers.openai.com/api/docs/api-reference/fine-tuning/pause). Calling the pause API will tell the training process to create a new model snapshot, stop training, and put the job into a "Paused" state. The model snapshot will go through a normal safety screening process after which it will be available for you to use throughout the OpenAI platform as a normal fine-tuned model.
If you wish to continue the training process for a paused job, you can do so by using the [fine-tuning jobs API](https://developers.openai.com/api/docs/api-reference/fine-tuning/resume). This will resume the training process from the last checkpoint created when the job was paused and will continue training until the job is either completed or paused again.
### Grading with Tools
If you are training your model to [perform tool calls](https://developers.openai.com/api/docs/guides/function-calling), you will need to:
1. Provide the set of tools available for your model to call on each datapoint in the RFT training dataset. More info here in the [dataset API reference](https://developers.openai.com/api/docs/api-reference/fine-tuning/reinforcement-input).
2. Configure your grader to assign rewards based on the contents of the tool calls made by the model. Information on grading tools calls can be found [here in the grading docs](https://developers.openai.com/api/docs/guides/graders/#sample-namespace)
### Billing details
Reinforcement fine-tuning jobs are billed based on the amount of time spent training, as well as the number of tokens used by the model during training. We only bill for time spent in the core training loop, not for time spent preparing the training data, validating datasets, waiting in queues, running safety evals, or other overhead.
Details on exactly how we bill for reinforcement fine-tuning jobs can be found in this [help center article](https://help.openai.com/en/articles/11323177-billing-guide-for-the-reinforcement-fine-tuning-api).
### Training errors
Reinforcement fine-tuning is a complex process with many moving parts, and there are many places where things can go wrong. We publish various error metrics to help you understand what is going wrong in your job, and how to fix it. In general, we try to avoid failing a job entirely unless a very serious error occurs. When errors do occur, they often happen during the grading step. Errors during grading often happen either to the model outputting a sample that the grader doesn't know how to handle, the grader failing to execute properly due to some sort of system error, or due to a bug in the grading logic itself.
The error metrics are available under the `event.data.errors` object, and are aggregated into counts and rates rolled up per-grader. We also display rates and counts of errors on the fine-tuning dashboard.
Grader errors
#### Generic grading errors
The grader errors are broken down into the following categories, and they exist in both `train_` (for training data) and `valid_` (for validation data) versions:
- `sample_parse_error_mean`: The average number of samples that failed to parse correctly. This often happens when the model fails to output valid JSON or adhere to a provided response format correctly. A small percentage of these errors, especially early in the training process, is normal. If you see a large number of these errors, it is likely that the response format of the model is not configured correctly or that your graders are misconfigured and looking for incorrect fields.
- `invalid_variable_error_mean`: These errors occur when you attempt to reference a variable via a template that cannot be found either in the current datapoint or in the current model sample. This can happen if the model fails to provide output in the correct response format, or if your grader is misconfigured.
- `other_error_mean`: This is a catch-all for any other errors that occur during grading. These errors are often caused by bugs in the grading logic itself, or by system errors that occur during grading.
#### Python grading errors
- `python_grader_server_error_mean`: These errors occur when our system for executing python graders in a remote sandbox experiences system errors. This normally happens due to reasons outside of your control, like networking failures or system outages. If you see a large number of these errors, it is likely that there is a system issue that is causing the errors. You can check the [OpenAI status page](https://status.openai.com/) for more information on any ongoing issues.
- `python_grader_runtime_error_mean`: These errors occur when the python grader itself fails to execute properly. This can happen for a variety of reasons, including bugs in the grading logic, or if the grader is trying to access a variable that doesn't exist in the current context. If you see a large number of these errors, it is likely that there is a bug in your grading logic that needs to be fixed. If a large enough number of these errors occur, the job will fail and we will show you a sampling of tracebacks from the failed graders.
#### Model grading errors
- `model_grader_server_error_mean`: These errors occur when we fail to sample from a model grader. This can happen for a variety of reasons, but generally means that either the model grader was misconfigured, that you are attempting to use a model that is not available to your organization, or that there is a system issue that is happening at OpenAI.
---
# Reinforcement fine-tuning use cases
[Reinforcement fine-tuning](https://developers.openai.com/api/docs/guides/reinforcement-fine-tuning) (RFT) provides a way to improve your model's performance at specific tasks. The task must be clear and have verifiable answers.
OpenAI is winding down the fine-tuning platform. The platform is no longer
accessible to new users, but existing users of the fine-tuning platform will
be able to create training jobs for the coming months.
All fine-tuned models will remain available for inference until their base
models are [deprecated](https://developers.openai.com/api/docs/deprecations). The full timeline is
[here](https://developers.openai.com/api/docs/deprecations).
## When to use reinforcement fine-tuning
Agentic workflows are designed to make decisions that are both correct and verifiable. RFT can help by providing explicit rubrics and using code‑based or LLM‑based graders to measure functional success, factual accuracy, or policy compliance.
Across early users, three clear use cases have emerged:
1. **Turn instructions into working code**: Convert open-ended prompts into structured code, configs, or templates that must pass deterministic tests.
1. **Pull facts into a clean format**: Extract verifiable facts and summaries from messy, unstructured text and return JSON-structured or other schema-based outputs.
1. **Apply complex rules correctly**: Make fine-grained label or policy decisions when the information provided is nuanced, large in quantity, hierarchical, or high-stakes.
[Ready to use reinforcement fine-tuning? Skip to the guide →](https://developers.openai.com/api/docs/guides/reinforcement-fine-tuning)
### 1. Turn instructions into working code
In this use case, models reason over hidden domain constraints to produce structured outputs like code, queries, or infrastructure templates. Outputs must satisfy multiple correctness conditions, and success is usually deterministically graded: the artifact either compiles, passes tests, or meets an explicit schema.
#### Wiring verification IPs for semiconductor design
#### Production-ready API snippets that compile and pass AST checks
#### Correct handling of conflicts and dupes in a schedule manager
### 2. Pull facts into a clean format
These tasks typically involve subtle distinctions that demand clear classification guidelines. Successful framing requires explicit and hierarchical labeling schemes defined through consensus by domain experts. Without consistent agreement, grading signals become noisy, weakening RFT effectiveness.
#### Assigning ICD-10 medical codes
#### Extracting excerpts to support legal claims
### 3. Apply complex rules correctly
This use case involves pulling verifiable facts or entities from unstructured inputs into clearly defined schemas (e.g., JSON objects, condition codes, medical codes, legal citations, or financial metrics).
Successful extraction tasks typically benefit from precise, continuous grading methodologies—like span-level F1 scores, fuzzy text-matching metrics, or numeric accuracy checks—to evaluate how accurately the extracted information aligns with ground truth. Define explicit success criteria and detailed rubrics. Then, the model can achieve reliable, repeatable improvements.
#### Expert-level reasoning in tax analysis
#### Enforcement of nuanced content moderation policies
#### Legal document reviews, comparisons, and summaries
## Evals are the foundation
**Before implementing RFT, we strongly recommended creating and running an eval for the task you intend to fine-tune on**. If the model you intend to fine-tune scores at either the absolute minimum or absolute maximum possible score, then RFT won’t be useful to you.
RFT works by reinforcing better answers to provided prompts. If we can’t distinguish the quality of different answers (i.e., if they all receive the minimum or maximum possible score), then there's no training signal to learn from. However, if your eval scores somewhere in the range between the minimum and maximum possible scores, there's enough data to work with.
An effective eval reveals opportunities where human experts consistently agree but current frontier models struggle, presenting a valuable gap for RFT to close. [Get started with evals](https://developers.openai.com/api/docs/guides/evals).
## How to get better results from RFT
To see improvements in your fine-tuned model, there are two main places to revisit and refine: making sure your task is well defined, and making your grading scheme more robust.
### Reframe or clarify your task
Good tasks give the model a fair chance to learn and let you quantify improvements.
- **Start with a task the model can already solve occasionally**. RFT works by sampling many answers, keeping what looks best, and nudging the model toward those answers. If the model never gets the answer correct today, it cannot improve.
- **Make sure each answer can be graded**. A grader must read an answer and produce a score without a person in the loop. We support multiple [grader types](https://developers.openai.com/api/docs/guides/graders), including custom Python graders and LLM judges. If you can't write code to judge the answer with an available grader, RFT is not the right tool.
- **Remove doubt about the “right” answer**. If two careful people often disagree on the solution, the task is too fuzzy. Rewrite the prompt, add context, or split the task into clearer parts until domain experts agree.
- **Limit lucky guesses**. If the task is multiple choice with one obvious best pick, the model can win by chance. Add more classes, ask for short open‑ended text, or tweak the format so guessing is costly.
### Strengthen your grader
Clear, robust grading schemes are essential for RFT.
- **Produce a smooth score, not a pass/fail stamp**. A score that shifts gradually as answers improve provides a better training signal.
- **Guard against reward hacking**. This happens when the model finds a shortcut that earns high scores without real skill.
- **Avoid skewed data**. Datasets in which one label shows up most of the time invite the model to guess that label. Balance the set or up‑weight rare cases so the model must think.
- **Use an LLM judge when code falls short**. For rich, open‑ended answers, have a [separate OpenAI model grade](https://developers.openai.com/api/docs/guides/graders#model-graders) your fine-tuned model's answers. Make sure you:
- **Evaluate the judge**: Run multiple candidate responses and correct answers through your LLM judge to ensure the grade returned is stable and aligned with preference.
- **Provide few-shot examples**. Include great, fair, and poor answers in the prompt to improve the grader's effectiveness.
Learn more about [grader types](https://developers.openai.com/api/docs/guides/graders).
## Other resources
For more inspiration, visit the [OpenAI Cookbook](https://developers.openai.com/cookbook), which contains example code and links to third-party resources, or learn more about our models and reasoning capabilities:
- [Meet the models](https://developers.openai.com/api/docs/models)
- [Reinforcement fine-tuning guide](https://developers.openai.com/api/docs/guides/reinforcement-fine-tuning)
- [Graders](https://developers.openai.com/api/docs/guides/graders)
- [Model optimization overview](https://developers.openai.com/api/docs/guides/model-optimization)
---
# Results and state
When you run an agent, the result is more than just the final answer. It's also the handoff boundary, the next-turn continuation surface, and the resumable snapshot when a run pauses for review.
## Choose the result surface you need
Most applications only need a small set of result properties:
| If you need | Use |
| ---------------------------------------------------- | ----------------------------------------------------------------------------------- |
| The final answer to show the user | |
| Local replay-ready history | |
| The specialist that should usually own the next turn | |
| OpenAI-managed response chaining | |
| Pending approvals and a resumable snapshot | `interruptions` plus |
Those are the guide-level surfaces to learn first. Richer run items, raw model responses, and detailed diagnostics still belong in the SDK docs and reference material.
## What to carry into the next turn
Use the result in a way that matches your continuation strategy:
- If your application owns full local history, reuse .
- If you are using a session, keep passing the same session and let the SDK load and persist history for you.
- If you are using server-managed continuation, pass only the new user input and reuse the stored ID instead of replaying the full transcript.
- After handoffs, reuse when that specialist should stay in control for the next turn.
## Interrupted runs return state, not a final answer
Approval flows are the main case where a result is intentionally incomplete.
- can
stay empty because the run hasn't actually finished.
- `interruptions` tells you which pending tool calls need a decision.
- is the saved
snapshot you pass back into the runtime after approving or rejecting those
items.
That same state surface is what you serialize when a review might happen later rather than in the same request.
## Richer item and diagnostics surfaces
The SDK also exposes richer run items and diagnostics for applications that need more than the high-level surfaces above. That includes item-level tool and handoff records, raw model responses, guardrail results, and usage details.
Those are useful for audits, custom interfaces, and deep debugging, but they don't need to be the first thing most developers learn on this site.
## Next steps
Once you know which result surfaces matter, continue with the guide that explains how those surfaces get produced or inspected.
---
# Retrieval
The **Retrieval API** allows you to perform [**semantic search**](#semantic-search) over your data, which is a technique that surfaces semantically similar results — even when they match few or no keywords. Retrieval is useful on its own, but is especially powerful when combined with our models to synthesize responses.
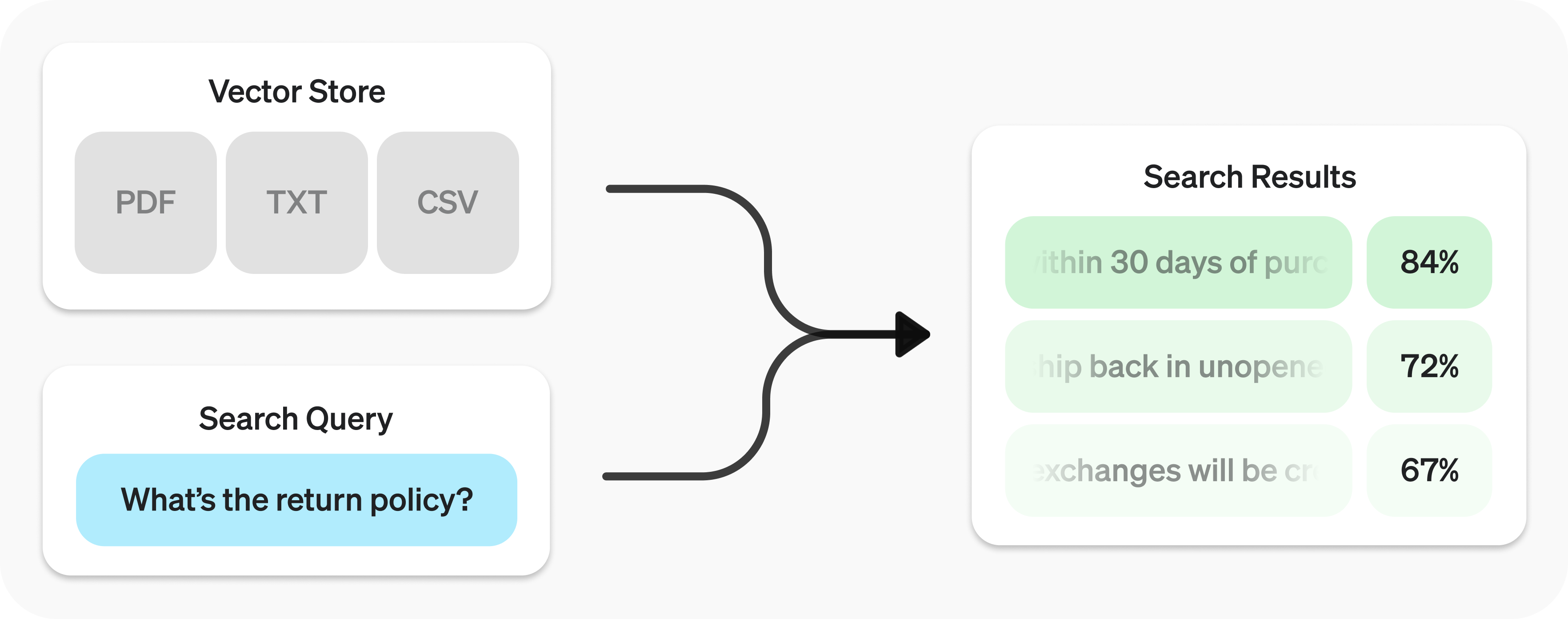
The Retrieval API is powered by [**vector stores**](#vector-stores), which serve as indices for your data. This guide will cover how to perform semantic search, and go into the details of vector stores.
## Quickstart
**Create vector store** and upload files.
**Send search query** to get relevant results.
To learn how to use the results with our models, check out the [synthesizing
responses](#synthesizing-responses) section.
## Semantic search
**Semantic search** is a technique that leverages [vector embeddings](https://developers.openai.com/api/docs/guides/embeddings) to surface semantically relevant results. Importantly, this includes results with few or no shared keywords, which classical search techniques might miss.
For example, let's look at potential results for `"When did we go to the moon?"`:
| Text | Keyword Similarity | Semantic Similarity |
| ------------------------------------------------- | ------------------ | ------------------- |
| The first lunar landing occurred in July of 1969. | 0% | 65% |
| The first man on the moon was Neil Armstrong. | 27% | 43% |
| When I ate the moon cake, it was delicious. | 40% | 28% |
_([Jaccard](https://en.wikipedia.org/wiki/Jaccard_index) used for keyword, [cosine](https://en.wikipedia.org/wiki/Cosine_similarity) with `text-embedding-3-small` used for semantic.)_
Notice how the most relevant result contains none of the words in the search query. This flexibility makes semantic search a very powerful technique for querying knowledge bases of any size.
Semantic search is powered by [vector stores](#vector-stores), which we cover in detail later in the guide. This section will focus on the mechanics of semantic search.
### Performing semantic search
You can query a vector store using the `search` function and specifying a `query` in natural language. This will return a list of results, each with the relevant chunks, similarity scores, and file of origin.
A response will contain 10 results maximum by default, but you can set up to 50 using the `max_num_results` param.
### Query rewriting
Certain query styles yield better results, so we've provided a setting to automatically rewrite your queries for optimal performance. Enable this feature by setting `rewrite_query=true` when performing a `search`.
The rewritten query will be available in the result's `search_query` field.
| **Original** | **Rewritten** |
| --------------------------------------------------------------------- | ------------------------------------------ |
| I'd like to know the height of the main office building. | primary office building height |
| What are the safety regulations for transporting hazardous materials? | safety regulations for hazardous materials |
| How do I file a complaint about a service issue? | service complaint filing process |
### Attribute filtering
Attribute filtering helps narrow down results by applying criteria, such as restricting searches to a specific date range. You can define and combine criteria in `attribute_filter` to target files based on their attributes before performing semantic search.
Use **comparison filters** to compare a specific `key` in a file's `attributes` with a given `value`, and **compound filters** to combine multiple filters using `and` and `or`.
Below are some example filters.
### Ranking
If you find that your file search results are not sufficiently relevant, you can adjust the `ranking_options` to improve the quality of responses. This includes specifying a `ranker`, such as `auto` or `default-2024-08-21`, and setting a `score_threshold` between 0.0 and 1.0. A higher `score_threshold` will limit the results to more relevant chunks, though it may exclude some potentially useful ones. When `ranking_options.hybrid_search` is provided you can also tune `hybrid_search.embedding_weight` (`rrf_embedding_weight`) and `hybrid_search.text_weight` (`rrf_text_weight`) to control how reciprocal rank fusion balances semantic embedding matches vs. sparse keyword matches. Increase the former to emphasize semantic similarity, increase the latter to emphasize textual overlap, and ensure at least one of the weights is greater than zero.
## Vector stores
Vector stores are the containers that power semantic search for the Retrieval API and the [file search](https://developers.openai.com/api/docs/guides/tools-file-search) tool. When you add a file to a vector store it will be automatically chunked, embedded, and indexed.
Vector stores contain `vector_store_file` objects, which are backed by a `file` object.
| Object type
| Description |
| -------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `file` | Represents content uploaded through the [Files API](https://developers.openai.com/api/docs/api-reference/files). Often used with vector stores, but also for fine-tuning and other use cases. |
| `vector_store` | Container for searchable files. |
| `vector_store.file` | Wrapper type specifically representing a `file` that has been chunked and embedded, and has been associated with a `vector_store`.
Contains `attributes` map used for filtering. |
### Pricing
You will be charged based on the total storage used across all your vector stores, determined by the size of parsed chunks and their corresponding embeddings.
| Storage | Cost |
| ------------------------------ | ------------ |
| Up to 1 GB (across all stores) | Free |
| Beyond 1 GB | $0.10/GB/day |
See [expiration policies](#expiration-policies) for options to minimize costs.
### Vector store operations
### Vector store file operations
Some operations, like `create` for `vector_store.file`, are asynchronous and may take time to complete — use our helper functions, like `create_and_poll` to block until it is. Otherwise, you may check the status. Removing files from a vector store is eventually consistent, and search results may still include content from a removed file for a short period.
Adding files is rate limited per vector store ID. Requests to [`/vector_stores/{vector_store_id}/files`](https://developers.openai.com/api/docs/api-reference/vector-stores/createFile) and [`/vector_stores/{vector_store_id}/file_batches`](https://developers.openai.com/api/docs/api-reference/vector-stores/createBatch) share a per-vector-store limit of 300 requests per minute.
### Batch operations
When creating a batch you can either provide `file_ids` with optional `attributes` and/or `chunking_strategy`, or use the `files` array to pass objects that include a `file_id` plus optional `attributes` and `chunking_strategy` for each file. The two options are mutually exclusive so that you can cleanly control whether every file shares the same settings or you need per-file overrides.
For higher-throughput ingestion into a single vector store, we recommend batch creation whenever possible. Batches can include up to 500 files in one request, which usually reduces contention and improves end-to-end latency versus sending many single-file create requests.
### Attributes
Each `vector_store.file` can have associated `attributes`, a dictionary of values that can be referenced when performing [semantic search](#semantic-search) with [attribute filtering](#attribute-filtering). The dictionary can have at most 16 keys, with a limit of 256 characters each.
### Expiration policies
You can set an expiration policy on `vector_store` objects with `expires_after`. Once a vector store expires, all associated `vector_store.file` objects will be deleted and you'll no longer be charged for them.
### Limits
The maximum file size is 512 MB. Each file should contain no more than 5,000,000 tokens per file (computed automatically when you attach a file).
### Chunking
By default, `max_chunk_size_tokens` is set to `800` and `chunk_overlap_tokens` is set to `400`, meaning every file is indexed by being split up into 800-token chunks, with 400-token overlap between consecutive chunks.
You can adjust this by setting [`chunking_strategy`](https://developers.openai.com/api/docs/api-reference/vector-stores-files/createFile#vector-stores-files-createfile-chunking_strategy) when adding files to the vector store. There are certain limitations to `chunking_strategy`:
- `max_chunk_size_tokens` must be between 100 and 4096 inclusive.
- `chunk_overlap_tokens` must be non-negative and should not exceed `max_chunk_size_tokens / 2`.
Supported file types
_For `text/` MIME types, the encoding must be one of `utf-8`, `utf-16`, or `ascii`._
{/* Keep this table in sync with RETRIEVAL_SUPPORTED_EXTENSIONS in the agentapi service */}
| File format | MIME type |
| ----------- | --------------------------------------------------------------------------- |
| `.c` | `text/x-c` |
| `.cpp` | `text/x-c++` |
| `.cs` | `text/x-csharp` |
| `.css` | `text/css` |
| `.doc` | `application/msword` |
| `.docx` | `application/vnd.openxmlformats-officedocument.wordprocessingml.document` |
| `.go` | `text/x-golang` |
| `.html` | `text/html` |
| `.java` | `text/x-java` |
| `.js` | `text/javascript` |
| `.json` | `application/json` |
| `.md` | `text/markdown` |
| `.pdf` | `application/pdf` |
| `.php` | `text/x-php` |
| `.pptx` | `application/vnd.openxmlformats-officedocument.presentationml.presentation` |
| `.py` | `text/x-python` |
| `.py` | `text/x-script.python` |
| `.rb` | `text/x-ruby` |
| `.sh` | `application/x-sh` |
| `.tex` | `text/x-tex` |
| `.ts` | `application/typescript` |
| `.txt` | `text/plain` |
## Synthesizing responses
After performing a query you may want to synthesize a response based on the results. You can leverage our models to do so, by supplying the results and original query, to get back a grounded response.
This uses a sample `format_results` function, which could be implemented like
so:
---
# Running agents
Defining an agent is only the setup step. The runtime questions are what a single run does, how the next turn continues, and how the workflow behaves when it pauses for approvals or tool work.
## The agent loop
One SDK run is one application-level turn. The runner keeps looping until it reaches a real stopping point:
1. Call the current agent's model with the prepared input.
2. Inspect the model output.
3. If the model produced tool calls, execute them and continue.
4. If the model handed off to another specialist, switch agents and continue.
5. If the model produced a final answer with no more tool work, return a result.
That loop is the core concept behind the SDK. Tools, handoffs, approvals, and streaming all build on top of it rather than replacing it.
## Choose one conversation strategy
There are four common ways to carry state into the next turn:
| Strategy | Where state lives | Best for | What you pass on the next turn |
| ------------------------------------------------------------------------------------------------------------------ | ------------------------- | ---------------------------------------------------------------------- | ---------------------------------------------- |
| | Your application | Small chat loops and maximum control | The replay-ready history |
| `session` | Your storage plus the SDK | Persistent chat state, resumable runs, and storage you control | The same session |
| `conversationId` | OpenAI Conversations API | Shared server-managed state across workers or services | The same conversation ID and only the new turn |
| | OpenAI Responses API | The lightest server-managed continuation from one response to the next | The last response ID and only the new turn |
In most applications, pick one strategy per conversation. Mixing local replay with server-managed state can duplicate context unless you are deliberately reconciling both layers.
Persist multi-turn state with sessions
```typescript
import { Agent, MemorySession, run } from "@openai/agents";
const agent = new Agent({
name: "Tour guide",
instructions: "Answer with compact travel facts.",
});
const session = new MemorySession();
const firstTurn = await run(
agent,
"What city is the Golden Gate Bridge in?",
{ session },
);
console.log(firstTurn.finalOutput);
const secondTurn = await run(agent, "What state is it in?", { session });
console.log(secondTurn.finalOutput);
```
```python
import asyncio
from agents import Agent, Runner, SQLiteSession
agent = Agent(
name="Tour guide",
instructions="Answer with compact travel facts.",
)
session = SQLiteSession("conversation_123")
async def main() -> None:
first_turn = await Runner.run(
agent,
"What city is the Golden Gate Bridge in?",
session=session,
)
print(first_turn.final_output)
second_turn = await Runner.run(
agent,
"What state is it in?",
session=session,
)
print(second_turn.final_output)
if __name__ == "__main__":
asyncio.run(main())
```
Sessions are the best default when you want durable memory, resumable approval flows, or storage that your application controls.
Continue with server-managed state
```typescript
import { Agent, run } from "@openai/agents";
import OpenAI from "openai";
const agent = new Agent({
name: "Assistant",
instructions: "Reply very concisely.",
});
const client = new OpenAI();
const { id: conversationId } = await client.conversations.create({});
const first = await run(agent, "What city is the Golden Gate Bridge in?", {
conversationId,
});
console.log(first.finalOutput);
const second = await run(agent, "What state is it in?", {
conversationId,
});
console.log(second.finalOutput);
```
```python
import asyncio
from agents import Agent, Runner
agent = Agent(
name="Assistant",
instructions="Reply very concisely.",
)
async def main() -> None:
first = await Runner.run(
agent,
"What city is the Golden Gate Bridge in?",
)
print(first.final_output)
second = await Runner.run(
agent,
"What state is it in?",
previous_response_id=first.last_response_id,
)
print(second.final_output)
if __name__ == "__main__":
asyncio.run(main())
```
Use `conversationId` when multiple systems should share one named conversation. Use when you want the cheapest response-to-response continuation option.
## Stream runs incrementally
Streaming uses the same agent loop and the same state strategies. The only difference is that you consume events while the run is still happening.
Stream a run as text arrives
```typescript
import { Agent, run } from "@openai/agents";
const agent = new Agent({
name: "Planet guide",
instructions: "Answer with short facts.",
});
const stream = await run(agent, "Give me three short facts about Saturn.", {
stream: true,
});
for await (const event of stream) {
if (
event.type === "raw_model_stream_event" &&
event.data.type === "response.output_text.delta"
) {
process.stdout.write(event.data.delta);
}
}
await stream.completed;
console.log("\\nFinal:", stream.finalOutput);
```
```python
import asyncio
from openai.types.responses import ResponseTextDeltaEvent
from agents import Agent, Runner
agent = Agent(
name="Planet guide",
instructions="Answer with short facts.",
)
async def main() -> None:
stream = Runner.run_streamed(
agent,
"Give me three short facts about Saturn.",
)
async for event in stream.stream_events():
if (
event.type == "raw_response_event"
and isinstance(event.data, ResponseTextDeltaEvent)
):
print(event.data.delta, end="", flush=True)
print(f"\\nFinal: {stream.final_output}")
if __name__ == "__main__":
asyncio.run(main())
```
Three practical rules matter:
- Wait for the stream to finish before treating the run as settled.
- If the run pauses for approval, resolve `interruptions` and resume from `state` rather than starting a fresh user turn.
- If you cancel a stream mid-turn, resume the unfinished turn from `state` if you want the same turn to continue later.
## Handle pauses and failures deliberately
Two broad classes of non-happy-path outcomes matter:
- **Runtime or validation failures** such as max-turn limits, guardrail exceptions, or tool errors.
- **Expected pauses** such as human approval requests, where the run is intentionally interrupted and should later resume from the same state.
Treat approvals as paused runs, not as new turns. That distinction keeps turn counts, history, and server-managed continuation IDs consistent.
## Next steps
Once the runtime loop is clear, move to the guide that matches the next workflow boundary you need to design.
---
# Safety best practices
export const snippetExampleProvidingUserIdentifier = {
python: `
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "This is a test"}
],
max_tokens=5,
safety_identifier="user_123456"
)
`.trim(),
curl: `
curl https://api.openai.com/v1/chat/completions \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-4o-mini",
"messages": [
{"role": "user", "content": "This is a test"}
],
"max_tokens": 5,
"safety_identifier": "user123456"
}'
`.trim(),
};
### Use our free Moderation API
OpenAI's [Moderation API](https://developers.openai.com/api/docs/guides/moderation) is free-to-use and can help reduce the frequency of unsafe content in your completions. Alternatively, you may wish to develop your own content filtration system tailored to your use case.
### Adversarial testing
We recommend “red-teaming” your application to ensure it's robust to adversarial input. Test your product over a wide range of inputs and user behaviors, both a representative set and those reflective of someone trying to ‘break' your application. Does it wander off topic? Can someone easily redirect the feature via prompt injections, e.g. “ignore the previous instructions and do this instead”?
### Human in the loop (HITL)
Wherever possible, we recommend having a human review outputs before they are used in practice. This is especially critical in high-stakes domains, and for code generation. Humans should be aware of the limitations of the system, and have access to any information needed to verify the outputs (for example, if the application summarizes notes, a human should have easy access to the original notes to refer back).
### Prompt engineering
“Prompt engineering” can help constrain the topic and tone of output text. This reduces the chance of producing undesired content, even if a user tries to produce it. Providing additional context to the model (such as by giving a few high-quality examples of desired behavior prior to the new input) can make it easier to steer model outputs in desired directions.
### “Know your customer” (KYC)
Users should generally need to register and log-in to access your service. Linking this service to an existing account, such as a Gmail, LinkedIn, or Facebook log-in, may help, though may not be appropriate for all use-cases. Requiring a credit card or ID card reduces risk further.
### Constrain user input and limit output tokens
Limiting the amount of text a user can input into the prompt helps avoid prompt injection. Limiting the number of output tokens helps reduce the chance of misuse.
Narrowing the ranges of inputs or outputs, especially drawn from trusted sources, reduces the extent of misuse possible within an application.
Allowing user inputs through validated dropdown fields (e.g., a list of movies on Wikipedia) can be more secure than allowing open-ended text inputs.
Returning outputs from a validated set of materials on the backend, where possible, can be safer than returning novel generated content (for instance, routing a customer query to the best-matching existing customer support article, rather than attempting to answer the query from-scratch).
### Allow users to report issues
Users should generally have an easily-available method for reporting improper functionality or other concerns about application behavior (listed email address, ticket submission method, etc). This method should be monitored by a human and responded to as appropriate.
### Understand and communicate limitations
From hallucinating inaccurate information, to offensive outputs, to bias, and much more, language models may not be suitable for every use case without significant modifications. Consider whether the model is fit for your purpose, and evaluate the performance of the API on a wide range of potential inputs in order to identify cases where the API's performance might drop. Consider your customer base and the range of inputs that they will be using, and ensure their expectations are calibrated appropriately.
**Safety and security are very important to us at OpenAI**.
If you notice any safety or security issues while developing with the API or anything else related to OpenAI, please submit it through our [Coordinated Vulnerability Disclosure Program](https://openai.com/security/disclosure/).
### Implement safety identifiers
Sending safety identifiers in your requests can be a useful tool to help OpenAI monitor and detect abuse. This allows OpenAI to provide your team with more actionable feedback in the event that we detect any policy violations in your application.
A safety identifier should be a string that uniquely identifies each user. Hash the username or email address in order to avoid sending us any identifying information. If you offer a preview of your product to non-logged in users, you can send a session ID instead.
Safety identifiers are recommended for products where individual users interact
with a model, but they are not required. Include safety identifiers in your API
requests with the `safety_identifier` parameter:
For Realtime API requests, provide the same stable, privacy-preserving identifier
with the `OpenAI-Safety-Identifier` header. When you create an ephemeral Realtime
client secret, include the header on the server-side request that creates the
secret so the identifier is bound to that session. For direct WebSocket or WebRTC
connection requests made from a trusted backend, include the header on the
connection request.
Safety identifiers do not carry over between APIs or sessions. If your
application already sends `safety_identifier` with Responses API requests, pass
the same stable value separately when you create or connect each Realtime
session.
---
# Safety checks
export const snippetExampleProvidingUserIdentifier = {
python: `
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[
{"role": "user", "content": "This is a test"}
],
safety_identifier="user_123456"
)
`.trim(),
curl: `
curl https://api.openai.com/v1/chat/completions \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5.4-mini",
"messages": [
{"role": "user", "content": "This is a test"}
],
"safety_identifier": "user_123456"
}'
`.trim(),
};
export const snippetExampleProvidingUserIdentifierResponses = {
python: `
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.4-mini",
input="This is a test",
safety_identifier="user_123456",
)
`.trim(),
curl: `
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5.4-mini",
"input": "This is a test",
"safety_identifier": "user_123456"
}'
`.trim(),
};
export const snippetExampleProvidingUserIdentifierRealtime = {
curl: `
curl https://api.openai.com/v1/realtime/client_secrets \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "OpenAI-Safety-Identifier: user_123456" \\
-d '{
"session": {
"type": "realtime",
"model": "gpt-realtime-2"
}
}'
`.trim(),
};
We run several types of evaluations on our models and how they're being used. This guide covers how we test for safety and what you can do to avoid violations.
## Safety classifiers for GPT-5 and forward
With the introduction of [GPT-5](https://developers.openai.com/api/docs/models/gpt-5), we added some checks to find and halt hazardous information from being accessed. It's likely some users will eventually try to use your application for things outside of OpenAI’s policies, especially in applications with a wide range of use cases.
### The safety classifier process
1. We classify requests to GPT-5 into risk thresholds.
1. If your org hits high thresholds repeatedly, OpenAI returns an error and sends a warning email.
1. If the requests continue past the stated time threshold (usually seven days), we stop your org's access to GPT-5. Requests will no longer work.
### How to avoid errors, latency, and bans
If your org engages in suspicious activity that violates our safety policies, we may return an error, limit model access, or even block your account. The following safety measures help us identify where high-risk requests are coming from and block individual end users, rather than blocking your entire org.
- [Implement safety identifiers](https://developers.openai.com/api/docs/guides/safety-best-practices#implement-safety-identifiers) for products where individual users interact with a model. Safety identifiers are recommended but not required.
- If your use case depends on accessing a less restricted version of our services in order to engage in beneficial applications across the life sciences, read about our [special access program](https://help.openai.com/en/articles/11826767-life-science-research-special-access-program) to see if you meet criteria.
You likely don't need to provide a safety identifier if access to your product
is tightly controlled (for example, enterprise customers) or in cases where
users don't directly provide prompts, or are limited to use in narrow areas.
### Implementing safety identifiers for individual users
The `safety_identifier` parameter is available in both the [Responses API](https://developers.openai.com/api/docs/api-reference/responses/create) and older [Chat Completions API](https://developers.openai.com/api/docs/api-reference/chat/create). The Realtime API supports the same concept through the `OpenAI-Safety-Identifier` header. To use safety identifiers, provide a stable ID for your end user on each request. Hash user email or internal user IDs to avoid passing any personal information.
Safety identifiers do not carry over between APIs or sessions. If your application already sends `safety_identifier` with Responses API requests, pass the same stable value separately when you create or connect each Realtime session.
### Potential consequences
If OpenAI monitoring systems identify potential abuse, we may take different levels of action:
- **Delayed streaming responses**
- As an initial, lower-consequence intervention for a user potentially violating policies, OpenAI may delay streaming responses while running additional checks before returning the full response to that user.
- If the check passes, streaming begins. If the check fails, the request stops—no tokens show up, and the streamed response does not begin.
- For a better end user experience, consider adding a loading spinner for cases where streaming is delayed.
- **Blocked model access for individual users**
- In a high confidence policy violation, the associated `safety_identifier` is completely blocked from OpenAI model access.
- The safety identifier receives an `identifier blocked` error on all future GPT-5 requests for the same identifier. OpenAI cannot currently unblock an individual identifier.
For these blocks to be effective, ensure you have controls in place to prevent blocked users from simply opening a new account. As a reminder, repeated policy violations from your organization can lead to losing access for your entire organization.
### Why we're doing this
The specific enforcement criteria may change based on evolving real-world usage or new model releases. Currently, OpenAI may restrict or block access for safety identifiers with risky or suspicious biology or chemical activity. See the [blog post](https://openai.com/index/preparing-for-future-ai-capabilities-in-biology/) for more information about how we’re approaching higher AI capabilities in biology.
## Other types of safety checks
To help ensure safety in your use of the OpenAI API and tools, we run safety checks on our own models, including all fine-tuned models, and on the computer use tool.
Learn more:
- [Model evaluations hub](https://openai.com/safety/evaluations-hub)
- [Cyber Safety](https://developers.openai.com/codex/concepts/cyber-safety)
- [Fine-tuning safety](https://developers.openai.com/api/docs/guides/supervised-fine-tuning#safety-checks)
- [Safety checks in computer use](https://developers.openai.com/api/docs/guides/tools-computer-use#acknowledge-safety-checks)
---
# Safety in building agents
As you build and deploy agents with [Agent Builder](https://developers.openai.com/api/docs/guides/agent-builder), it's important to understand the risks. Learn about risk types and how to mitigate them when building multi-agent workflows.
## Types of risk
Certain agent workflow patterns are more vulnerable to risk. In chat workflows, two important considerations are protecting user input and being careful about MCP tool calling.
### Prompt injections
**Prompt injections** are a common and dangerous type of attack. A prompt injection happens when untrusted text or data enters an AI system, and malicious contents in that text or data attempt to override instructions to the AI. The end goals of prompt injections vary but can include exfiltrating private data via downstream tool calls, taking misaligned actions, or otherwise changing model behavior in an unintended way. For example, a prompt might trick a data lookup agent into sending raw customer records instead of the intended summary. See an example in context in the [Codex internet access docs](https://developers.openai.com/codex/cloud/internet-access/).
### Private data leakage
**Private data leakage**, when an agent accidentally shares private data, is also a risk to guard against. It's possible for a model to leak private data in a way that's not intended, without an attacker behind it. For example, a model may send more data to an MCP than the user expected or intended. While guardrails provide better control to limit the information included in context, you don't have full control over what the model chooses to share with connected MCPs.
Use the following guidance to reduce the attack surface and mitigate these risks. However, _even with these mitigations_, agents won’t be perfect and can still make mistakes or be tricked; as a result, it's important to understand these risks and use caution in what access you give agents and how you apply agents.
## Don't use untrusted variables in developer messages
Because developer messages take precedence over user and assistant messages, injecting untrusted input directly into developer messages gives attackers the highest degree of control. Pass untrusted inputs through user messages to limit their influence. This is especially important for workflows where user inputs are passed to sensitive tools or privileged contexts.
## Use structured outputs to constrain data flow
Prompt injections often rely on the model freely generating unexpected text or commands that propagate downstream. By defining structured outputs between nodes (e.g., enums, fixed schemas, required field names), you eliminate freeform channels that attackers can exploit to smuggle instructions or data.
## Steer the agent with clear guidance and examples
Agent workflows may do something you don't want due to hallucination, misunderstanding, ambiguous user input, etc. For example, an agent may offer a refund it's not supposed to or delete information it shouldn't. The best way to mitigate this risk is to strengthen your prompts with good documentation of your desired policies and clear examples. Anticipate unintended scenarios and provide examples so the agent knows what to do in these cases.
## Use GPT-5 or GPT-5-mini
These models are more disciplined about following developer instructions and exhibit stronger robustness against jailbreaks and indirect prompt injections. Configure these models at the agent node level for a more resilient default posture, especially for higher-risk workflows.
## Keep tool approvals on
When using MCP tools, always enable tool approvals so end users can review and confirm every operation, including reads and writes. In Agent Builder, use the [human approval](https://developers.openai.com/api/docs/guides/node-reference#human-approval) node.
## Use guardrails for user inputs
Sanitize incoming inputs using built-in [guardrails](https://developers.openai.com/api/docs/guides/node-reference#guardrails) to redact personally identifiable information (PII) and detect jailbreak attempts. While the guardrails nodes in Agent Builder alone are not foolproof, they're an effective first wave of protection.
## Run trace graders and evals
If you understand what models are doing, you can better catch and prevent mistakes. Use [evals](https://developers.openai.com/api/docs/guides/evaluation-getting-started) to evaluate and improve performance. Trace grading provides scores and annotations to specific parts of an agent's trace—such as decisions, tool calls, or reasoning steps—to assess where the agent performed well or made mistakes.
## Combine techniques
By combining these techniques and hardening critical steps, you can significantly reduce risks of prompt injection, malicious tool use, or unexpected agent behavior.
Design workflows so untrusted data never directly drives agent behavior. Extract only specific structured fields (e.g., enums or validated JSON) from external inputs to limit injection risk from flowing between nodes. Use guardrails, tool confirmations, and variables passed via user messages to validate inputs.
Risk rises when agents process arbitrary text that influences tool calls. Structured outputs and isolation greatly reduce, _but don’t fully remove_, this risk.
---
# Sandbox Agents
A sandbox gives an agent an isolated, Unix-like execution environment with a
filesystem, shell, installed packages, mounted data, exposed ports, snapshots,
and controlled access to external systems.
Agent workflows get brittle when the model needs that kind of workspace but
only receives prompt context. Large document sets, generated artifacts,
commands, previews, and resumable work all need an environment the agent can
inspect and change.
Sandbox agents are available in the TypeScript and Python Agents SDKs. They
are in beta, so API details, defaults, and supported capabilities may change.
Use sandboxes when the agent needs to manipulate files, run commands, mount a
data room, produce artifacts, expose a service, or continue stateful work
later.
The key split is the boundary between the harness and compute. The harness is
the control plane around the model: it owns the agent loop, model calls, tool
routing, handoffs, approvals, tracing, recovery, and run state. Compute is the
sandbox execution plane where model-directed work reads and writes files, runs
commands, installs dependencies, uses mounted storage, exposes ports, and
snapshots state.
Keeping those boundaries separate lets your application keep sensitive control
plane work in trusted infrastructure while the sandbox stays focused on
provider-specific execution. The sandbox can run code against files with narrow
credentials and mounts; the harness can keep auth, billing, audit logs, human
review, and recovery state outside any one container.
Running the harness inside the sandbox can be convenient for prototypes,
but it puts orchestration and model-directed execution in the same compute
boundary.
The harness can run in your infrastructure while the sandbox handles
provider-specific, stateful execution.
## When to use a sandbox
Use a sandbox when the agent's answer depends on work done in a sandbox
workspace, not just reasoning over prompt context.
Common pain points include:
- The task needs a directory of documents, not a single prompt.
- The agent should write files that your application can inspect later.
- The agent needs commands, packages, or scripts to complete the work.
- The workflow produces artifacts such as Markdown, CSV, JSONL, screenshots, or generated websites.
- A service, notebook, or report preview needs to run on an exposed port.
- Work pauses for human review and then resumes in the same workspace.
If your workflow only needs a short model response and no persistent workspace,
call the [Responses API](https://developers.openai.com/api/reference/responses/overview) directly or use the
basic Agents SDK runtime without a sandbox.
If shell access is only one occasional tool, start with the hosted shell tool in
[Using tools](https://developers.openai.com/api/docs/guides/tools#usage-in-the-agents-sdk). Use sandbox
agents when workspace isolation, sandbox provider choice, or resumable
filesystem state is part of the product design.
## What sandboxes add
`SandboxAgent` is still an `Agent`. It keeps the usual agent surface, including
`instructions`, `prompt`, `tools`, `handoffs`, MCP servers, model settings,
structured output, guardrails, and hooks. What changes is the execution boundary:
the runner prepares the agent against a live sandbox session that owns files,
commands, ports, and provider-specific isolation.
| Piece | What it owns | Design question |
| ------------------ | ---------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- |
| `SandboxAgent` | The agent definition plus sandbox defaults | What should this agent do, and which sandbox defaults travel with it? |
| `Manifest` | The fresh-session workspace contract | What files, directories, repos, mounts, environment, users, or groups start out in the workspace? |
| Capabilities | Sandbox-native behavior attached to the agent | Which sandbox tools, instructions, or runtime behavior does this agent need? |
| Sandbox client | The provider integration | Where should the live workspace run: Unix-local, Docker, or a hosted provider? |
| Sandbox session | The live execution environment | Where do commands run, files change, ports open, and provider state live? |
| Sandbox run config | Per-run sandbox session source, client options, and fresh inputs | Should this run inject, resume, or create the sandbox session? |
| Saved state | `RunState`, serialized session state, and snapshots | How should later runs reconnect to work or seed a new workspace? |
Sandbox-specific defaults belong on `SandboxAgent`. Per-run sandbox-session
choices belong in the run's sandbox configuration.
Sandbox agents also don't change what a turn means. A turn is still a model
step, not a single shell command or sandbox action. Some work may stay inside
the sandbox execution layer. The agent runtime consumes another turn only when
it needs another model response after sandbox work has happened.
## Create the workspace
`Manifest` describes the desired starting contents and layout for a fresh
sandbox workspace. Use it for the files, repos, input artifacts, helper files,
mounts, output directories, and environment setup the agent should see.
Treat the manifest as a fresh-session contract, not the full source of truth for
every live sandbox. The effective workspace for a run can instead come from a
reused live sandbox session, serialized sandbox session state, or a snapshot
chosen at run time.
Manifest entry paths are workspace-relative. They can't be absolute paths or
escape the workspace with `..`, which keeps the workspace contract portable
across local, Docker, and hosted clients.
| Manifest input | Use it for |
| ------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------- |
| `File`, `Dir` | Small synthetic inputs, helper files, or output directories. |
| Local file or directory | Host files or directories to materialize into the sandbox. |
| Git repo | A repository to fetch into the workspace. |
| `S3Mount`, `GCSMount`, `R2Mount`, `AzureBlobMount`, `BoxMount`, `S3FilesMount` | External storage to make available inside the sandbox. |
| `environment` | Environment variables the sandbox needs when it starts. |
| `users` and `groups` | Sandbox-local OS accounts and groups for providers that support account provisioning. |
Good manifest design means:
- Put repos, input artifacts, and output directories in the manifest.
- Put longer task specs and repo-local instructions in workspace files such as `repo/task.md` or `AGENTS.md`.
- Use relative workspace paths in instructions, for example `repo/task.md` or `output/report.md`.
- Keep mounted storage scoped to the inputs the agent should read or write.
- Treat mount entries as ephemeral workspace entries: snapshot and persistence flows skip mounted remote storage instead of copying it into saved workspace contents.
### Mount files and storage
Useful data often already lives somewhere else. Instead of pasting large
documents into context, mount them into the sandbox and let the agent work with
files.
Examples:
- Mount a due-diligence data room and ask the agent to produce a cited summary.
- Mount a support export and ask the agent to cluster issues into a report.
- Mount generated artifacts so another system can review them.
Provider integrations expose their own mount helpers, credential handling, and
persistence behavior. Keep the application contract the same: mount only the
inputs the agent should use, tell the agent where to read and write, and check
generated artifacts before using them.
### Handle secrets and credentials
Treat sandbox credentials as runtime configuration, not prompt content. The
agent may need access to credentials for package managers, storage mounts, or
provider APIs, but those credentials shouldn't appear in user prompts,
agent instructions, task files, committed manifests, or generated artifacts.
Use these rules:
- Prefer provider-native secret systems for hosted sandbox providers.
- Keep cloud storage credentials scoped to the mount or provider option that needs them.
- Use `Manifest.environment` for values the sandbox process needs at startup, and mark sensitive or generated entries as ephemeral when you want to rebuild them instead of persisting them.
- Avoid saving secrets, generated mount config, local tokens, or files that shouldn't survive the run.
- Review artifacts before moving them out of the sandbox, especially when the agent can read private documents or mounted storage.
The SDK supports manifest environment values and provider-specific mount
credentials. General secret-store integration is provider-specific, so keep this
page focused on the contract: your runtime or sandbox provider should inject
credentials instead of teaching them to the model as instructions.
## Give the agent capabilities
Capabilities attach sandbox-native behavior to a `SandboxAgent`. They can shape
the workspace before a run starts, append sandbox-specific instructions, expose
tools that bind to the live sandbox session, and adjust model behavior or input
handling for that agent.
| Capability | Add it when | Notes |
| --------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------------------------------ |
| `Shell` | The agent needs shell access. | Adds command execution and, when supported by the sandbox client, interactive input. |
| `Filesystem` | The agent needs to edit files or inspect local images. | Adds `apply_patch` and `view_image`; patch paths are workspace-root-relative. |
| `Skills` | You want skill discovery and materialization in the sandbox. | Prefer this over manually mounting `.agents` or `.agents/skills`. |
| [`Memory`](#persist-memory-across-runs) | Follow-on runs should read or generate memory artifacts. | Requires `Shell`; live memory updates also require `Filesystem`. |
| `Compaction` | Long-running flows need context trimming. | Adjusts model behavior and input handling after compaction items. |
By default, a `SandboxAgent` includes filesystem, shell, and compaction
capabilities. If you pass a `capabilities` list, it replaces the default list,
so include any default capabilities the agent still needs.
Prefer built-in capabilities when they fit. Write a custom capability only when
you need a sandbox-specific tool or instruction surface that the built-ins don't
cover.
### Load skills
Some tasks need repeatable instructions, scripts, references, or assets before
the agent starts. Use the `Skills` capability so the agent can discover that
working context during the run.
Load skills
```typescript
import {
Capabilities,
SandboxAgent,
gitRepo,
skills,
} from "@openai/agents/sandbox";
const agent = new SandboxAgent({
name: "Tax prep assistant",
instructions: "Use the mounted skill before preparing the return.",
capabilities: [
...Capabilities.default(),
skills({
from: gitRepo({
repo: "owner/tax-prep-skills",
ref: "main",
}),
}),
],
});
```
```python
from agents.sandbox import SandboxAgent
from agents.sandbox.capabilities import Capabilities, Skills
from agents.sandbox.entries import GitRepo
agent = SandboxAgent(
name="Tax prep assistant",
instructions="Use the mounted skill before preparing the return.",
capabilities=Capabilities.default() + [
Skills(from_=GitRepo(repo="owner/tax-prep-skills", ref="main")),
],
)
```
Choose the skill source based on how you want it materialized:
- Use a lazy local directory source for larger local skill directories when you want the model to discover the index first and load only what it needs.
- Use a local directory source for a small local bundle to stage up front.
- Use a Git repo source when the skills bundle has its own release cadence or many sandboxes use it.
### Expose previews and ports
Sometimes the artifact isn't a file; it's a running process. Use an exposed
port when the agent creates a local app, notebook, report server, browser
preview, or other service that you need to inspect outside the sandbox.
Port setup is provider-specific, but the product contract is the same: the
agent starts the service inside the sandbox, the sandbox client exposes the
port, and your application shares or inspects the resulting preview URL.
## Run a sandbox agent
The shortest useful sandbox loop is:
1. Build a `Manifest` that describes the workspace.
2. Create a `SandboxAgent` with the capabilities the model needs.
3. Choose a sandbox client for the environment where work should run.
4. Run the agent with the per-run sandbox configuration.
5. Inspect, copy, resume, or snapshot the artifacts that matter to your application.
Start with Unix-local for local development on macOS or Linux. It gives you the
smallest local loop because the runner can create a temporary workspace from the
agent's default manifest and clean it up after the run.
Run a Unix-local sandbox agent
```typescript
import { run } from "@openai/agents";
import {
Manifest,
SandboxAgent,
file,
shell,
} from "@openai/agents/sandbox";
import { UnixLocalSandboxClient } from "@openai/agents/sandbox/local";
const manifest = new Manifest({
entries: {
"account_brief.md": file({
content:
"# Northwind Health\\n\\n" +
"- Segment: Mid-market healthcare analytics provider.\\n" +
"- Renewal date: 2026-04-15.\\n",
}),
"implementation_risks.md": file({
content:
"# Delivery risks\\n\\n" +
"- Security questionnaire is not complete.\\n" +
"- Procurement requires final legal language by April 1.\\n",
}),
},
});
const agent = new SandboxAgent({
name: "Renewal Packet Analyst",
model: "gpt-5.5",
instructions:
"Review the workspace before answering. Keep the response concise, " +
"business-focused, and cite the file names that support each conclusion.",
defaultManifest: manifest,
capabilities: [shell()],
});
const result = await run(
agent,
"Summarize the renewal blockers and recommend the next two actions.",
{
sandbox: {
client: new UnixLocalSandboxClient(),
},
},
);
console.log(result.finalOutput);
```
```python
import asyncio
from agents import Runner
from agents.run import RunConfig
from agents.sandbox import Manifest, SandboxAgent, SandboxRunConfig
from agents.sandbox.capabilities import Shell
from agents.sandbox.entries import File
from agents.sandbox.sandboxes.unix_local import UnixLocalSandboxClient
manifest = Manifest(
entries={
"account_brief.md": File(
content=(
b"# Northwind Health\\n\\n"
b"- Segment: Mid-market healthcare analytics provider.\\n"
b"- Renewal date: 2026-04-15.\\n"
)
),
"implementation_risks.md": File(
content=(
b"# Delivery risks\\n\\n"
b"- Security questionnaire is not complete.\\n"
b"- Procurement requires final legal language by April 1.\\n"
)
),
}
)
agent = SandboxAgent(
name="Renewal Packet Analyst",
model="gpt-5.5",
instructions=(
"Review the workspace before answering. Keep the response concise, "
"business-focused, and cite the file names that support each conclusion."
),
default_manifest=manifest,
capabilities=[Shell()],
)
async def main():
result = await Runner.run(
agent,
"Summarize the renewal blockers and recommend the next two actions.",
run_config=RunConfig(
sandbox=SandboxRunConfig(client=UnixLocalSandboxClient()),
workflow_name="Unix-local sandbox review",
),
)
print(result.final_output)
asyncio.run(main())
```
For complete local examples, see the TypeScript [sandbox agent quickstart][sdk-js-example-basic] and Python [`unix_local_runner.py`][sdk-example-unix-local-runner].
### Switch providers
The provider is part of the run configuration, not the agent definition. Keep
the `SandboxAgent`, manifest, and capabilities stable, then swap the sandbox
client and provider options for the environment you want.
This example uses Docker for local container isolation. Hosted providers follow
the same pattern with their own client classes and options.
Switch to Docker
```typescript
import { run } from "@openai/agents";
import { SandboxAgent } from "@openai/agents/sandbox";
import { DockerSandboxClient } from "@openai/agents/sandbox/local";
const agent = new SandboxAgent({
name: "Workspace reviewer",
model: "gpt-5.5",
instructions: "Inspect the sandbox workspace before answering.",
});
const result = await run(agent, "Inspect the workspace.", {
sandbox: {
client: new DockerSandboxClient({
image: "node:22-bookworm-slim",
}),
},
});
console.log(result.finalOutput);
```
```python
from docker import from_env as docker_from_env
from agents import Runner
from agents.run import RunConfig
from agents.sandbox import SandboxRunConfig
from agents.sandbox.config import DEFAULT_PYTHON_SANDBOX_IMAGE
from agents.sandbox.sandboxes.docker import DockerSandboxClient, DockerSandboxClientOptions
docker_run_config = RunConfig(
sandbox=SandboxRunConfig(
client=DockerSandboxClient(docker_from_env()),
options=DockerSandboxClientOptions(image=DEFAULT_PYTHON_SANDBOX_IMAGE),
),
workflow_name="Docker sandbox review",
)
result = await Runner.run(
agent,
"Summarize the renewal blockers and recommend the next two actions.",
run_config=docker_run_config,
)
```
For runnable examples, see the TypeScript [sandbox clients guide][sdk-js-sandbox-clients] and [basic example][sdk-js-example-basic], plus Python [`basic.py`][sdk-example-basic] for provider selection, [`docker_runner.py`][sdk-example-docker-runner] for Docker, and [`main.py`][sdk-example-dataroom-qa] for a data-room flow in the SDK repository.
### Advanced patterns
Once the basic loop works, sandboxes become useful for workflows where the
agent needs a sandbox workspace instead of more prompt context. These
examples are workflow patterns, not separate APIs: the same harness can route, pause,
resume, and trace the workflow while each sandbox keeps execution close to the
files, tools, and ports it needs.
| Example | Description |
| ------------------------------------------------------ | ------------------------------------------------------------- |
| [Data room Q&A][sdk-example-dataroom-qa] | Answer questions over a mounted data room. |
| [Data room table extraction][sdk-example-dataroom] | Extract a table from a mounted data room. |
| [Repository code review][sdk-example-repo-code-review] | Clone a repo, inspect it, and produce code review artifacts. |
| [Vision website clone][sdk-example-vision-clone] | Clone a website using the Vision API and screenshot feedback. |
| [Sandbox resume][sdk-example-sandbox-resume] | Resume work in a pre-existing sandbox. |
## Resume or seed future work
Useful agent work often outlives one request. A user reviews an artifact, a
step needs approval, or the next step depends on a later event.
Keep three state concepts separate:
| State surface | Restores | Use when |
| ------------- | ----------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------ |
| `RunState` | Harness-side state such as model items, tool state, approvals, and active agent position. | The runner should carry the workflow forward across pauses. |
| Session state | A serialized sandbox session that a client can reconnect to. | Your app or job system stores provider session state directly. |
| `snapshot` | Saved workspace contents used to seed a fresh sandbox session. | A new run should start from saved files and artifacts, not an empty workspace. |
In practice, the runner resolves the sandbox session in this order:
1. If you pass a live sandbox session, the runner reuses that session directly.
2. Otherwise, if the run is resuming from `RunState`, the runner resumes from the stored sandbox session state.
3. Otherwise, if you pass explicit serialized sandbox state, the runner resumes from that state.
4. Otherwise, the runner creates a fresh sandbox session. For that fresh session, it uses the per-run manifest when provided, or the agent's default manifest if not.
The sandbox resume example serializes the stopped session state, resumes it
through the same client, and then passes the resumed session back into the next
run:
Serialize and resume sandbox state
```typescript
import { run } from "@openai/agents";
import { Manifest, SandboxAgent } from "@openai/agents/sandbox";
import { UnixLocalSandboxClient } from "@openai/agents/sandbox/local";
const manifest = new Manifest();
const client = new UnixLocalSandboxClient({
snapshot: { type: "local", baseDir: "/tmp/my-sandbox-snapshots" },
});
const agent = new SandboxAgent({
name: "Workspace builder",
model: "gpt-5.5",
instructions: "Inspect the sandbox workspace before answering.",
});
const session = await client.create({ manifest });
let conversation: any[] = [];
let frozenSessionState;
try {
const firstResult = await run(agent, "Build the first version of the app.", {
maxTurns: 20,
sandbox: { session },
});
conversation = firstResult.history;
frozenSessionState = await client.serializeSessionState?.(session.state);
} finally {
await session.close?.();
}
if (!frozenSessionState || !client.deserializeSessionState || !client.resume) {
throw new Error("Sandbox client does not support session resume.");
}
const resumedSession = await client.resume(
await client.deserializeSessionState(frozenSessionState),
);
try {
conversation.push({
role: "user",
content: "Continue from the existing workspace and add tests.",
});
await run(agent, conversation, {
maxTurns: 20,
sandbox: { session: resumedSession },
});
} finally {
await resumedSession.close?.();
}
```
```python
async with session:
first_result = await Runner.run(
agent,
"Build the first version of the app.",
max_turns=20,
run_config=RunConfig(
sandbox=SandboxRunConfig(session=session),
workflow_name="Sandbox resume example",
),
)
conversation = first_result.to_input_list()
frozen_session_state = client.deserialize_session_state(
client.serialize_session_state(session.state)
)
conversation.append(
{
"role": "user",
"content": "Continue from the existing workspace and add tests.",
}
)
resumed_session = await client.resume(frozen_session_state)
try:
async with resumed_session:
second_result = await Runner.run(
agent,
conversation,
max_turns=20,
run_config=RunConfig(
sandbox=SandboxRunConfig(session=resumed_session),
workflow_name="Sandbox resume example",
),
)
finally:
await client.delete(resumed_session)
```
Fresh-session inputs such as `manifest` and `snapshot` only apply when the
runner creates a new sandbox session. If you inject a live `session`, capability
processing can add compatible non-mount entries, but it can't change root,
environment, users, or groups; remove existing entries; replace entry types; or
add or change mount entries on the already-running sandbox.
This split lets the harness resume the agent loop while the sandbox provider
restores or recreates the workspace. Current sample code for these paths lives
in the TypeScript [resume session state example][sdk-js-example-resume] and
Python [`main.py`][sdk-example-sandbox-resume] and
[`sandbox_agent_with_remote_snapshot.py`][sdk-example-remote-snapshot].
## Persist memory across runs
Sandbox memory lets future sandbox-agent runs learn from prior runs. It's
separate from SDK-managed conversational `Session` memory: sessions preserve
message history, while sandbox memory distills useful lessons from prior
workspace runs into files the agent can read later.
Use memory when the agent should carry forward user preferences, corrections,
project-specific lessons, or task summaries without replaying every previous
turn. Resume and snapshots preserve workspace state; memory preserves reusable
guidance about work that happened in the workspace.
Enable sandbox memory
```typescript
import {
Manifest,
SandboxAgent,
filesystem,
memory,
shell,
} from "@openai/agents/sandbox";
const manifest = new Manifest();
const agent = new SandboxAgent({
name: "Memory-enabled reviewer",
instructions:
"Inspect the workspace and retain useful lessons for follow-up runs.",
defaultManifest: manifest,
capabilities: [memory(), filesystem(), shell()],
});
```
```python
from agents.sandbox.capabilities import Filesystem, Memory, Shell
agent = SandboxAgent(
name="Memory-enabled reviewer",
instructions="Inspect the workspace and retain useful lessons for follow-up runs.",
default_manifest=manifest,
capabilities=[Memory(), Filesystem(), Shell()],
)
```
Memory enables both reads and generation by default. Memory reads require shell
access so the agent can search and open memory files. By default, live memory
updates also require filesystem access, so the agent can repair stale memory or
update memory when the user asks.
Memory reads use progressive disclosure. The SDK injects `memory_summary.md` at
the start of a run, the agent searches `MEMORY.md` when prior work looks
relevant, and it opens rollout summaries only when it needs more detail.
| Memory mode | Use it when |
| -------------------- | ----------------------------------------------------------------------- |
| Default read/write | The agent should read existing memory and generate new memory. |
| Read-only memory | The agent should read memory but not generate new memory after the run. |
| Generate-only memory | The run should generate memory without using existing memory. |
| Read config | You need to disable live updates. |
| Generate config | You need to tune generation, such as the extra prompt. |
| Layout config | Agents need isolated memory layouts in the same sandbox workspace. |
By default, memory artifacts live in the sandbox workspace:
```text
workspace/
sessions/
.jsonl
memories/
memory_summary.md
MEMORY.md
raw_memories.md
phase_two_selection.json
raw_memories/
.md
rollout_summaries/
_.md
skills/
```
The runtime appends run segments during the sandbox session. When the session
closes, memory generation first extracts conversation summaries and raw
memories, then consolidates those raw memories into `MEMORY.md` and
`memory_summary.md`. To reuse memory in a later run, preserve the configured
memory directories by keeping the same live sandbox session, resuming from
session state, starting from a snapshot, or mounting persistent storage such as
S3.
For multi-turn sandbox chats, use a stable SDK session together with the same
live sandbox session. Memory groups runs by the explicit conversation ID, then
the SDK session ID, then the run group ID, and finally a generated per-run ID.
The sandbox session ID identifies the live workspace; it's not the memory
conversation ID.
For runnable examples, see the TypeScript [memory guide][sdk-js-sandbox-memory],
plus Python [`memory.py`][sdk-example-memory] for a local snapshot flow,
[`memory_s3.py`][sdk-example-memory-s3] for S3-backed memory storage, and
[`memory_multi_agent_multiturn.py`][sdk-example-memory-multi-agent] for separate
memory layouts across agents.
## Compose sandbox agents
Sandbox agents compose with the rest of the SDK.
Use a handoff when a non-sandbox intake agent should delegate only the
workspace-heavy part of a workflow to a sandbox agent. The top-level run
continues, but the sandbox agent becomes the active agent for the next turn.
Use agents as tools when an outer orchestrator should call one or more sandbox
agents as nested tools. Each sandbox tool-agent can have its own sandbox run
configuration, sandbox client, manifest, and provider options.
For examples, see [`handoffs.py`][sdk-example-handoffs] and
[`sandbox_agents_as_tools.py`][sdk-example-agents-as-tools].
## Sandbox providers
Start with Unix-local for fast local iteration or Docker when you want local
container isolation. Move to a hosted provider when the task needs managed
execution, provider-specific isolation, scaling, previews, storage mounts,
snapshots, or credentials that should live outside your application server.
Use provider docs for provider-specific setup, credentials, isolation, storage,
previews, and persistence behavior.
| Provider | SDK client | Documentation and examples |
| ---------- | ------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Blaxel | `BlaxelSandboxClient` | Sandbox overview |
| Cloudflare | `CloudflareSandboxClient` | Sandbox documentation
OpenAI Agents tutorial
Sandbox Bridge examples |
| Daytona | `DaytonaSandboxClient` | Sandbox documentation
OpenAI Agents SDK guide |
| Docker | `DockerSandboxClient` | Docker documentation
TypeScript Docker SDK example
Python Docker SDK example |
| E2B | `E2BSandboxClient` | Sandbox documentation
OpenAI Agents SDK guide
Launch blog |
| Modal | `ModalSandboxClient` | Sandbox guide
Integration blog
Example repo
Modal extension reference |
| Runloop | `RunloopSandboxClient` | Devbox overview
Tunnels |
| Unix-local | `UnixLocalSandboxClient` | TypeScript local SDK example
Python local SDK example |
| Vercel | `VercelSandboxClient` | Sandbox documentation
OpenAI Agents SDK guide
FastAPI template
Sample app |
[sdk-example-agents-as-tools]: https://github.com/openai/openai-agents-python/blob/main/examples/sandbox/sandbox_agents_as_tools.py
[sdk-example-basic]: https://github.com/openai/openai-agents-python/blob/main/examples/sandbox/basic.py
[sdk-example-dataroom]: https://github.com/openai/openai-agents-python/tree/main/examples/sandbox/tutorials/dataroom_metric_extract
[sdk-example-dataroom-qa]: https://github.com/openai/openai-agents-python/tree/main/examples/sandbox/tutorials/dataroom_qa
[sdk-example-docker-runner]: https://github.com/openai/openai-agents-python/blob/main/examples/sandbox/docker/docker_runner.py
[sdk-example-handoffs]: https://github.com/openai/openai-agents-python/blob/main/examples/sandbox/handoffs.py
[sdk-example-memory]: https://github.com/openai/openai-agents-python/blob/main/examples/sandbox/memory.py
[sdk-example-memory-multi-agent]: https://github.com/openai/openai-agents-python/blob/main/examples/sandbox/memory_multi_agent_multiturn.py
[sdk-example-memory-s3]: https://github.com/openai/openai-agents-python/blob/main/examples/sandbox/memory_s3.py
[sdk-example-remote-snapshot]: https://github.com/openai/openai-agents-python/blob/main/examples/sandbox/sandbox_agent_with_remote_snapshot.py
[sdk-example-repo-code-review]: https://github.com/openai/openai-agents-python/tree/main/examples/sandbox/tutorials/repo_code_review
[sdk-example-sandbox-resume]: https://github.com/openai/openai-agents-python/tree/main/examples/sandbox/tutorials/sandbox_resume
[sdk-example-unix-local-runner]: https://github.com/openai/openai-agents-python/blob/main/examples/sandbox/unix_local_runner.py
[sdk-example-vision-clone]: https://github.com/openai/openai-agents-python/tree/main/examples/sandbox/tutorials/vision_website_clone
[sdk-js-example-basic]: https://github.com/openai/openai-agents-js/blob/main/examples/docs/sandbox-agents/basic.ts
[sdk-js-example-resume]: https://github.com/openai/openai-agents-js/blob/main/examples/docs/sandbox-agents/resume-session-state.ts
[sdk-js-sandbox-clients]: https://openai.github.io/openai-agents-js/guides/sandbox-agents/clients
[sdk-js-sandbox-memory]: https://openai.github.io/openai-agents-js/guides/sandbox-agents/memory
---
# Shell
The shell tool gives models the ability to work inside a complete terminal environment. We support shell for local execution and for hosted execution through the Responses API.
The shell tool lets models run commands through either:
- Hosted shell containers managed by OpenAI.
- [A local shell runtime](#local-shell-mode) that you host and execute yourself.
Shell is available through the [Responses API](https://developers.openai.com/api/docs/guides/responses-vs-chat-completions). It's not available via the Chat Completions API.
Running arbitrary shell commands can be dangerous. Always sandbox execution,
apply allowlists or denylists where possible, and log tool activity for
auditing.
## Hosted shell quickstart
Hosted shell is a native and streamlined option for tasks that need richer, deterministic processing, from running calculations to working with multimedia.
Use `container_auto` when you want OpenAI to provision and manage a container for the request.
Shell tool with container_auto
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5.5",
tools: [{ type: "shell", environment: { type: "container_auto" } }],
input: [
{
type: "message",
role: "user",
content: [
{
type: "input_text",
text: "Execute: ls -lah /mnt/data && python --version && node --version",
},
],
},
],
tool_choice: "auto",
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
tools=[{"type": "shell", "environment": {"type": "container_auto"}}],
input=[
{
"type": "message",
"role": "user",
"content": [
{
"type": "input_text",
"text": "Execute: ls -lah /mnt/data && python --version && node --version",
}
],
}
],
tool_choice="auto",
)
print(response.output_text)
```
## Hosted runtime details
- Runtime is currently based on `Debian 12` and may change over time.
- Default working directory is `/mnt/data`.
- `/mnt/data` is always present and is the supported path for user-downloadable artifacts.
- Hosted shell doesn't support interactive TTY sessions.
- Hosted shell commands don't run with `sudo`.
- You can run services inside the container when your workflow needs them.
Current preinstalled languages include:
- Python `3.11`
- Node.js `22.16`
- Java `17.0`
- PHP `8.2`
- Ruby `3.1`
- Go `1.23`
## Reuse a container across requests
If you need a long-running environment for iterative workflows, create a container and then reference it in subsequent Responses API calls.
### 1. Create a container
Create a reusable container
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const container = await client.containers.create({
name: "analysis-container",
memory_limit: "1g",
expires_after: { anchor: "last_active_at", minutes: 20 },
});
console.log(container.id);
```
```python
from openai import OpenAI
client = OpenAI()
container = client.containers.create(
name="analysis-container",
memory_limit="1g",
expires_after={"anchor": "last_active_at", "minutes": 20},
)
print(container.id)
```
### 2. Reference the container in Responses
Use shell with container_reference
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5.5",
tools: [
{
type: "shell",
environment: {
type: "container_reference",
container_id: "cntr_08f3d96c87a585390069118b594f7481a088b16cda7d9415fe",
},
},
],
input: "List files in the container and show disk usage.",
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
tools=[
{
"type": "shell",
"environment": {
"type": "container_reference",
"container_id": "cntr_08f3d96c87a585390069118b594f7481a088b16cda7d9415fe",
},
}
],
input="List files in the container and show disk usage.",
)
print(response.output_text)
```
## Attach skills
Skills are reusable, versioned bundles that you can mount in hosted shell environments. This defines the available skills, and at shell execution time the model decides whether to invoke them.
Use the [Skills guide](https://developers.openai.com/api/docs/guides/tools-skills) for upload and versioning details.
Create a container with attached skills
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const container = await client.containers.create({
name: "skill-container",
skills: [
{ type: "skill_reference", skill_id: "skill_4db6f1a2c9e73508b41f9da06e2c7b5f" },
{ type: "skill_reference", skill_id: "openai-spreadsheets", version: "latest" },
],
});
console.log(container.id);
```
```python
from openai import OpenAI
client = OpenAI()
container = client.containers.create(
name="skill-container",
skills=[
{"type": "skill_reference", "skill_id": "skill_4db6f1a2c9e73508b41f9da06e2c7b5f"},
{"type": "skill_reference", "skill_id": "openai-spreadsheets", "version": "latest"},
],
)
print(container.id)
```
## Network access
Hosted containers don't have outbound network access by default.
To enable it:
1. An admin must configure your org allow list in the dashboard.
2. You must explicitly set `network_policy` on the container environment in your request.
Shell tool with network allowlist
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5.5",
tool_choice: "required",
tools: [
{
type: "shell",
environment: {
type: "container_auto",
network_policy: {
type: "allowlist",
allowed_domains: ["pypi.org", "files.pythonhosted.org", "github.com"],
},
},
},
],
input: [
{
role: "user",
content:
"In the container, pip install httpx beautifulsoup4, fetch release pages, and write /mnt/data/release_digest.md.",
},
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
tool_choice="required",
tools=[
{
"type": "shell",
"environment": {
"type": "container_auto",
"network_policy": {
"type": "allowlist",
"allowed_domains": ["pypi.org", "files.pythonhosted.org", "github.com"],
},
},
}
],
input=[
{
"role": "user",
"content": "In the container, pip install httpx beautifulsoup4, fetch release pages, and write /mnt/data/release_digest.md.",
}
],
)
print(response.output_text)
```
Allowlisting domains introduces security risks such as prompt
injection-driven data exfiltration. Only allowlist domains you trust and that
attackers cannot use to receive exfiltrated data. Carefully review the [Risks
and safety](#risks-and-safety) section below before using this tool.
## Network policy precedence
When multiple controls are present:
- Your org allow list defines the full set of `allowed_domains`.
- Request-level `network_policy` further restricts access.
- Requests fail if `allowed_domains` includes domains outside your org allow list.
## Data retention and container lifecycle
Hosted containers used by Hosted Shell and Code Interpreter may write temporary application state to the container filesystem (backed by ephemeral block storage) while the container is active. Container data is deleted when the container expires or is explicitly deleted.
For more details on data controls, see [ZDR and data residency](https://developers.openai.com/api/docs/guides/your-data).
### Download artifacts
Hosted shell can produce downloadable files. Use the same container/files APIs as code interpreter to retrieve artifacts written under `/mnt/data`.
### Additional data controls
If you want to keep content and files ephemeral within the hosted lifecycle, you can inline files in the request and mount inline skills in the container.
Use inline files and inline skills
```javascript
import fs from "fs";
import OpenAI from "openai";
const client = new OpenAI();
const inlineZip = fs.readFileSync("csv_insights.zip").toString("base64");
const reportCsv = fs.readFileSync("report.csv").toString("base64");
const container = await client.containers.create({
name: "inline-skill-container",
skills: [
{
type: "inline",
name: "csv-insights",
description: "Summarize CSV files and produce a markdown report.",
source: {
type: "base64",
media_type: "application/zip",
data: inlineZip,
},
},
],
});
const response = await client.responses.create({
model: "gpt-5.5",
tools: [
{
type: "shell",
environment: {
type: "container_reference",
container_id: container.id,
},
},
],
input: [
{
role: "user",
content: [
{
type: "input_file",
filename: "report.csv",
file_data: \`data:text/csv;base64,\${reportCsv}\`,
},
{
type: "input_text",
text: "Use the csv-insights skill to summarize report.csv.",
},
],
},
],
});
console.log(response.output_text);
```
```python
import base64
from openai import OpenAI
client = OpenAI()
with open("csv_insights.zip", "rb") as f:
inline_zip = base64.b64encode(f.read()).decode("utf-8")
with open("report.csv", "rb") as f:
base64_string = base64.b64encode(f.read()).decode("utf-8")
container = client.containers.create(
name="inline-skill-container",
skills=[
{
"type": "inline",
"name": "csv-insights",
"description": "Summarize CSV files and produce a markdown report.",
"source": {
"type": "base64",
"media_type": "application/zip",
"data": inline_zip,
},
}
],
)
response = client.responses.create(
model="gpt-5.5",
tools=[
{
"type": "shell",
"environment": {
"type": "container_reference",
"container_id": container.id,
},
}
],
input=[
{
"role": "user",
"content": [
{
"type": "input_file",
"filename": "report.csv",
"file_data": f"data:text/csv;base64,{base64_string}",
},
{
"type": "input_text",
"text": "Use the csv-insights skill to summarize report.csv.",
},
],
}
],
)
print(response.output_text)
```
For follow-up requests, pass the same `container_id` with `container_reference`. The mounted skills and existing container files remain available while the container is active.
### Proactively delete a container
You can explicitly delete the container when the work is done instead of waiting for inactivity expiration.
Delete a container
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const deleted = await client.containers.delete("container_id");
console.log(deleted);
```
```python
from openai import OpenAI
client = OpenAI()
deleted = client.containers.delete("container_id")
print(deleted)
```
## Domain secrets
Use `domain_secrets` when a domain in your `allowed_domains` list requires private authorization headers, such as `Authorization: Bearer `.
Each secret entry includes:
- Target domain
- Friendly secret name
- Secret value
At runtime:
- The model and runtime see placeholder names (for example, `$API_KEY`) instead of raw credentials.
- The auth-translation sidecar applies raw secret values only for approved destinations.
- Raw secret values don't persist on API servers and don't appear in model-visible context.
This lets the assistant call protected services while reducing leakage risk.
Shell tool with domain_secrets
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5.5",
input: [
{
role: "user",
content:
"Use curl to call https://httpbin.org/headers with header Authorization: Bearer $API_KEY. Tell me what you see in the final text response.",
},
],
tool_choice: "required",
tools: [
{
type: "shell",
environment: {
type: "container_auto",
network_policy: {
type: "allowlist",
allowed_domains: ["httpbin.org"],
domain_secrets: [
{
domain: "httpbin.org",
name: "API_KEY",
value: "debug-secret-123",
},
],
},
},
},
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
input=[
{
"role": "user",
"content": "Use curl to call https://httpbin.org/headers with header Authorization: Bearer $API_KEY. Tell me what you see in the final text response.",
}
],
tool_choice="required",
tools=[
{
"type": "shell",
"environment": {
"type": "container_auto",
"network_policy": {
"type": "allowlist",
"allowed_domains": ["httpbin.org"],
"domain_secrets": [
{
"domain": "httpbin.org",
"name": "API_KEY",
"value": "debug-secret-123",
}
],
},
},
}
],
)
print(response.output_text)
```
## Multi-turn workflows
To continue work in the same hosted environment, reuse the container and pass `previous_response_id`.
Continue a shell workflow
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5.5",
previous_response_id: "resp_2a8e5c9174d63b0f18a4c572de9f64a1b3c76d508e12f9ab47",
tools: [
{
type: "shell",
environment: {
type: "container_reference",
container_id: "cntr_f19c2b51e4a06793d82d54a7be0fc9154d3361ab28ce7f6041",
},
},
],
input: "Read /mnt/data/top5.csv and report the top candidate.",
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
previous_response_id="resp_2a8e5c9174d63b0f18a4c572de9f64a1b3c76d508e12f9ab47",
tools=[
{
"type": "shell",
"environment": {
"type": "container_reference",
"container_id": "cntr_f19c2b51e4a06793d82d54a7be0fc9154d3361ab28ce7f6041",
},
}
],
input="Read /mnt/data/top5.csv and report the top candidate.",
)
print(response.output_text)
```
## Shell output in Responses
Hosted shell and local shell use the same output item types. Shell runs are represented by paired output items:
- `shell_call`: commands requested by the model.
- `shell_call_output`: command output and exit outcomes.
## Local shell mode
You can also run shell commands in your own local runtime by executing `shell_call` actions and sending `shell_call_output` back to the model.
Use this mode when you need full control over execution environment, filesystem access, or existing internal tooling.
When you receive `shell_call` output items:
- Execute requested commands in your runtime.
- Capture `stdout`, `stderr`, and outcome.
- Return results as `shell_call_output` in the next request.
For legacy migration details, see the older [Local shell guide](https://developers.openai.com/api/docs/guides/tools-local-shell).
## Use local shell with Agents SDK
If you are using the [Agents SDK](https://developers.openai.com/api/docs/guides/tools#usage-in-the-agents-sdk), you can pass your own shell executor implementation to the shell tool helper.
You can find working examples in the SDK repositories.
TypeScript example for the shell tool in the Agents SDK.
Python example for the shell tool in the Agents SDK.
## Handling common errors
- If a command exceeds your execution timeout, return a timeout outcome and include partial captured output.
- If `max_output_length` is present on `shell_call`, include it in `shell_call_output`.
- Don't rely on interactive commands; shell tool execution should be non-interactive.
- Preserve non-zero exit outputs so the model can reason about recovery steps.
## Risks and safety
Enabling network access in the Containers API is a powerful capability, and it introduces meaningful security and data-governance risk. By default, network access isn't enabled. When enabled, outbound access should remain tightly scoped to trusted domains needed for the task.
Network-enabled containers can interact with third-party services and package registries. That creates risks including data leakage, prompt-injection-driven tool misuse, and accidental access beyond intended boundaries. These risks increase when policies are broad, static, or inconsistently enforced.
#### Understand prompt injection risks from network-retrieved content
Any external content fetched over the network may contain hidden instructions intended to manipulate model behavior. Treat untrusted network content as potentially adversarial, and require additional caution for actions that can modify data or systems.
#### Connect only to trusted destinations
Allow only domains you trust and actively maintain. Be cautious with intermediaries and aggregators that proxy to other services, and review their data handling and retention practices before you add them to your allowed domains list.
#### Build in reviews before and after requests are executed
Review the shell tool command and execution output, which are provided in the Responses API response. Capture requested hosts and actual outbound destinations for each session. Periodically review logs to verify access patterns match expectations, detect drift, and identify suspicious behavior.
#### Validate data residency and retention requirements
[OpenAI data controls](https://developers.openai.com/api/docs/guides/your-data) apply within OpenAI boundaries. However, data transmitted to third-party services over network connections is subject to their data retention policies. Ensure external endpoints meet your residency, retention, and compliance requirements.
---
# Skills
Agent Skills let you upload and reuse versioned bundles of files in hosted and local shell environments.
We support Skills in two form factors: local execution and hosted,
container-based execution. To run code on your own machine, use the local
execution mode of the [shell tool](https://developers.openai.com/api/docs/guides/tools-shell).
## What's a skill
A skill is a versioned bundle of files plus a `SKILL.md` manifest (front matter + instructions). Skills are modular instructions you can use to codify processes and conventions, from company style guides to multi-step workflows.
Skills are compatible with the open [Agent Skills standard](https://agentskills.io/home).
## Create a skill
You can upload a directory as multipart form data or upload a `.zip` that contains a single top-level folder.
### Option 1: Directory upload (multipart)
Upload multiple `files[]` parts. Each part includes the path inside a single top-level folder.
### Option 2: Zip upload
Zip the top-level folder and upload the zip file.
## Use skills with hosted shell
To mount skills in a hosted shell environment, attach them via `tools[].environment.skills` when calling the shell tool.
Use skills in hosted shell
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5.5",
tools: [
{
type: "shell",
environment: {
type: "container_auto",
skills: [
{ type: "skill_reference", skill_id: "" },
{ type: "skill_reference", skill_id: "", version: 2 },
],
},
},
],
input: "Use the skills to add 144 and 377, then compute triangle area with base 9 height 13.",
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
tools=[
{
"type": "shell",
"environment": {
"type": "container_auto",
"skills": [
{"type": "skill_reference", "skill_id": ""},
{"type": "skill_reference", "skill_id": "", "version": 2},
],
},
}
],
input="Use the skills to add 144 and 377, then compute triangle area with base 9 height 13.",
)
print(response.output_text)
```
### Prompting behavior
Once a skill is mounted, the model can decide when to use it. If you want more deterministic behavior, explicitly instruct the model to "use the `` skill" when appropriate.
## Use skills with local shell mode
Skills also work with local shell mode, but local shell and hosted shell do not accept the same skill attachment formats.
- Hosted shell supports uploaded `skill_reference` attachments, including curated skills and explicit versions.
- Local shell does not support `skill_reference` attachments. Instead, provide skill files from local file paths in the runtime you control.
Use the [Shell guide](https://developers.openai.com/api/docs/guides/tools-shell) for local shell execution details.
Use skills in local shell mode
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5.5",
tools: [
{
type: "shell",
environment: {
type: "local",
skills: [
{
name: "csv-insights",
description: "Summarize CSV files and produce a markdown report.",
path: "",
},
],
},
},
],
input: "Use the csv-insights skill and run locally to summarize today's CSV reports in this repo.",
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
tools=[
{
"type": "shell",
"environment": {
"type": "local",
"skills": [
{
"name": "csv-insights",
"description": "Summarize CSV files and produce a markdown report.",
"path": "",
}
],
},
}
],
input="Use the csv-insights skill and run locally to summarize today's CSV reports in this repo.",
)
print(response.output_text)
```
## Skills in the user prompt
When skills are available to the tool, the platform adds each skill's `name`, `description`, and `path` to user prompt context so the model knows the skill exists.
The model decides whether to invoke a skill based on this metadata. If the model invokes a skill, it uses the `path` to read the full Markdown instructions from `SKILL.md`.
Skill instructions are user prompt input (not system prompt input), so they're handled with the same priority as other user-provided instructions. For explicit control, you can still instruct the model to "use the `` skill."
## Limits and validation
- `SKILL.md` file matching is case-insensitive.
- Exactly one `skill.md`/`SKILL.md` file is allowed in a skill bundle.
- Skill front matter validation follows the [agent skills specification](https://agentskills.io/specification#name-field).
- Maximum zip upload size is `50 MB`.
- Maximum file count per skill version is `500`.
- Maximum uncompressed file size is `25 MB`.
## Safety with network access
It is very important to inspect any Skill used with the Responses API. Skills
introduce security risks such as prompt injection-driven data exfiltration.
Carefully review the [Risks and safety](#risks-and-safety) section below
before using this tool.
## Versioning and management
### Version pointers
- `default_version` is used when a version isn't provided.
- `latest_version` tracks the newest upload.
- `skill_reference.version` accepts an integer or `"latest"`.
### Create a new version
### Set default version
### Delete rules
- You can't delete the default version; set another default first.
- Deleting the last remaining version deletes the skill.
- Deleting a skill cascades to remove all versions.
## Curated skills
OpenAI maintains a set of first-party skills that can be referenced by id (for example, `openai-spreadsheets`).
## Inline skills
If you don't want to create a hosted skill, you can inline a zip bundle (base64) in the environment's `skills` array.
## Risks and safety
It's important to inspect any Skill used with the Responses API. Skills introduce security risks such as prompt injection-driven data exfiltration.
For Skills used in conjunction with network access, carefully review the [Risks and safety section for networking](https://developers.openai.com/api/docs/guides/tools-shell#risks-and-safety).
#### Treat Skills as privileged code and instructions
Skill content can influence planning, tool usage, and command execution. Any Skill should be reviewed as potentially untrusted input until validated by the developer.
### Don't expose an open Skills repository to end-users
Avoid product designs where consumer end-users can freely browse, select, or attach arbitrary Skills from an open catalog. This materially increases risk from:
- Prompt-injection and policy bypass via malicious SKILL.md instructions.
- Data exfiltration or destructive actions triggered by unvetted automation.
#### Integrate Skills at the developer level
Skills should be inspected and integrated by the developer, then exposed to end-users only through bounded product experiences. In practice:
- Map Skills to specific product workflows/use cases.
- Prevent end-user control over arbitrary Skill selection.
- Gate write or high-impact actions behind explicit approval and policy checks.
#### Require approval for sensitive actions
For workflows that can perform write or high-impact actions, require explicit approval before execution.
#### Validate data residency and retention requirements
We support Skills in two form factors: local execution and hosted container-based execution. Hosted skills follow the same container lifecycle as hosted shell: mounted skills and container files remain available while the container is active and are discarded when the container expires or is deleted. If you want execution to stay entirely on infrastructure you manage, use local shell mode. Read more about our [data controls](https://developers.openai.com/api/docs/guides/your-data).
---
# Speech to text
The Audio API provides two speech to text endpoints:
- `transcriptions`
- `translations`
Historically, both endpoints have been backed by our open source [Whisper model](https://openai.com/blog/whisper/) (`whisper-1`). The `transcriptions` endpoint now also supports higher quality model snapshots, with limited parameter support:
- `gpt-4o-mini-transcribe`
- `gpt-4o-transcribe`
- `gpt-4o-transcribe-diarize`
All endpoints can be used to:
- Transcribe audio into whatever language the audio is in.
- Translate and transcribe the audio into English.
File uploads are currently limited to 25 MB, and the following input file types are supported: `mp3`, `mp4`, `mpeg`, `mpga`, `m4a`, `wav`, and `webm`. Known speaker reference clips for diarization accept the same formats when provided as data URLs.
Use this guide for file uploads and bounded audio requests. If your
application needs live transcript deltas from a microphone, call, or media
stream, use [Realtime transcription](https://developers.openai.com/api/docs/guides/realtime-transcription)
instead.
## Quickstart
### Transcriptions
The transcriptions API takes as input the audio file you want to transcribe and the desired output file format for the transcription of the audio. All models support the same set of input formats. On output:
- `whisper-1` supports `json`, `text`, `srt`, `verbose_json`, and `vtt`.
- `gpt-4o-transcribe` and `gpt-4o-mini-transcribe` support `json` or plain `text`.
- `gpt-4o-transcribe-diarize` supports `json`, `text`, and `diarized_json` (which adds speaker segments to the response).
Transcribe audio
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const transcription = await openai.audio.transcriptions.create({
file: fs.createReadStream("/path/to/file/audio.mp3"),
model: "gpt-4o-transcribe",
});
console.log(transcription.text);
```
```python
from openai import OpenAI
client = OpenAI()
audio_file= open("/path/to/file/audio.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file
)
print(transcription.text)
```
```cli
openai audio:transcriptions create \\
--model gpt-4o-transcribe \\
--file /path/to/file/audio.mp3 \\
--raw-output \\
--transform text
```
```bash
curl --request POST \\
--url https://api.openai.com/v1/audio/transcriptions \\
--header "Authorization: Bearer $OPENAI_API_KEY" \\
--header 'Content-Type: multipart/form-data' \\
--form file=@/path/to/file/audio.mp3 \\
--form model=gpt-4o-transcribe
```
By default, the response type will be json with the raw text included.
```example-content
{
"text": "Imagine the wildest idea that you've ever had, and you're curious about how it might scale to something that's a 100, a 1,000 times bigger.
....
}
```
The Audio API also allows you to set additional parameters in a request. For example, if you want to set the `response_format` as `text`, your request would look like the following:
Additional options
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const transcription = await openai.audio.transcriptions.create({
file: fs.createReadStream("/path/to/file/speech.mp3"),
model: "gpt-4o-transcribe",
response_format: "text",
});
console.log(transcription.text);
```
```python
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/speech.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
response_format="text"
)
print(transcription.text)
```
```bash
curl --request POST \\
--url https://api.openai.com/v1/audio/transcriptions \\
--header "Authorization: Bearer $OPENAI_API_KEY" \\
--header 'Content-Type: multipart/form-data' \\
--form file=@/path/to/file/speech.mp3 \\
--form model=gpt-4o-transcribe \\
--form response_format=text
```
The [API Reference](https://developers.openai.com/api/docs/api-reference/audio) includes the full list of available parameters.
`gpt-4o-transcribe` and `gpt-4o-mini-transcribe` support `json` or `text`
responses and allow prompts and logprobs. `gpt-4o-transcribe-diarize` adds
speaker labels but requires `chunking_strategy` when your audio is longer than
30 seconds (`"auto"` is recommended) and does not support prompts, logprobs,
or `timestamp_granularities[]`.
### Speaker diarization
`gpt-4o-transcribe-diarize` produces speaker-aware transcripts. Request the `diarized_json` response format to receive an array of segments with `speaker`, `start`, and `end` metadata. Set `chunking_strategy` (either `"auto"` or a Voice Activity Detection configuration) so that the service can split the audio into segments; this is required when the input is longer than 30 seconds.
You can optionally supply up to four short audio references with `known_speaker_names[]` and `known_speaker_references[]` to map segments onto known speakers. Provide reference clips between 2–10 seconds in any input format supported by the main audio upload; encode them as [data URLs](https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Data_URLs) when using multipart form data.
Diarize a meeting recording
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const agentRef = fs.readFileSync("agent.wav").toString("base64");
const transcript = await openai.audio.transcriptions.create({
file: fs.createReadStream("meeting.wav"),
model: "gpt-4o-transcribe-diarize",
response_format: "diarized_json",
chunking_strategy: "auto",
extra_body: {
known_speaker_names: ["agent"],
known_speaker_references: ["data:audio/wav;base64," + agentRef],
},
});
for (const segment of transcript.segments) {
console.log(\`\${segment.speaker}: \${segment.text}\`, segment.start, segment.end);
}
```
```python
import base64
from openai import OpenAI
client = OpenAI()
def to_data_url(path: str) -> str:
with open(path, "rb") as fh:
return "data:audio/wav;base64," + base64.b64encode(fh.read()).decode("utf-8")
with open("meeting.wav", "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="gpt-4o-transcribe-diarize",
file=audio_file,
response_format="diarized_json",
chunking_strategy="auto",
extra_body={
"known_speaker_names": ["agent"],
"known_speaker_references": [to_data_url("agent.wav")],
},
)
for segment in transcript.segments:
print(segment.speaker, segment.text, segment.start, segment.end)
```
```bash
curl --request POST \\
--url https://api.openai.com/v1/audio/transcriptions \\
--header "Authorization: Bearer $OPENAI_API_KEY" \\
--header 'Content-Type: multipart/form-data' \\
--form file=@/path/to/file/meeting.wav \\
--form model=gpt-4o-transcribe-diarize \\
--form response_format=diarized_json \\
--form chunking_strategy=auto \\
--form 'known_speaker_names[]=agent' \\
--form 'known_speaker_references[]=data:audio/wav;base64,AAA...'
```
When `stream=true`, diarized responses emit `transcript.text.segment` events whenever a segment completes. `transcript.text.delta` events include a `segment_id` field, but diarized deltas do not stream partial speaker assignments until each segment is finalized.
`gpt-4o-transcribe-diarize` is currently available via
`/v1/audio/transcriptions` only and is not yet supported in the Realtime API.
### Translations
The translations API takes as input the audio file in any of the supported languages and transcribes, if necessary, the audio into English. This differs from our /Transcriptions endpoint since the output is not in the original input language and is instead translated to English text. This endpoint supports only the `whisper-1` model.
Translate audio
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const translation = await openai.audio.translations.create({
file: fs.createReadStream("/path/to/file/german.mp3"),
model: "whisper-1",
});
console.log(translation.text);
```
```python
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/german.mp3", "rb")
translation = client.audio.translations.create(
model="whisper-1",
file=audio_file,
)
print(translation.text)
```
```bash
curl --request POST \\
--url https://api.openai.com/v1/audio/translations \\
--header "Authorization: Bearer $OPENAI_API_KEY" \\
--header 'Content-Type: multipart/form-data' \\
--form file=@/path/to/file/german.mp3 \\
--form model=whisper-1 \\
```
In this case, the inputted audio was german and the outputted text looks like:
```example-content
Hello, my name is Wolfgang and I come from Germany. Where are you heading today?
```
We only support translation into English at this time.
## Supported languages
We currently [support the following languages](https://github.com/openai/whisper#available-models-and-languages) through both the `transcriptions` and `translations` endpoint:
Afrikaans, Arabic, Armenian, Azerbaijani, Belarusian, Bosnian, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Kannada, Kazakh, Korean, Latvian, Lithuanian, Macedonian, Malay, Marathi, Maori, Nepali, Norwegian, Persian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Thai, Turkish, Ukrainian, Urdu, Vietnamese, and Welsh.
While the underlying model was trained on 98 languages, we only list the languages that exceeded \<50% [word error rate](https://en.wikipedia.org/wiki/Word_error_rate) (WER) which is an industry standard benchmark for speech to text model accuracy. The model will return results for languages not listed above but the quality will be low.
We support some ISO 639-1 and 639-3 language codes for GPT-4o based models. For language codes we don’t have, try prompting for specific languages (i.e., “Output in English”).
## Timestamps
By default, the Transcriptions API will output a transcript of the provided audio in text. The [`timestamp_granularities[]` parameter](/api/docs/api-reference/audio/createTranscription#audio-createtranscription-timestamp_granularities) enables a more structured and timestamped json output format, with timestamps at the segment, word level, or both. This enables word-level precision for transcripts and video edits, which allows for the removal of specific frames tied to individual words.
Timestamp options
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const transcription = await openai.audio.transcriptions.create({
file: fs.createReadStream("audio.mp3"),
model: "whisper-1",
response_format: "verbose_json",
timestamp_granularities: ["word"]
});
console.log(transcription.words);
```
```python
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/speech.mp3", "rb")
transcription = client.audio.transcriptions.create(
file=audio_file,
model="whisper-1",
response_format="verbose_json",
timestamp_granularities=["word"]
)
print(transcription.words)
```
```bash
curl https://api.openai.com/v1/audio/transcriptions \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: multipart/form-data" \\
-F file="@/path/to/file/audio.mp3" \\
-F "timestamp_granularities[]=word" \\
-F model="whisper-1" \\
-F response_format="verbose_json"
```
The `timestamp_granularities[]` parameter is only supported for `whisper-1`.
## Longer inputs
By default, the Transcriptions API only supports files that are less than 25 MB. If you have an audio file that is longer than that, you will need to break it up into chunks of 25 MB's or less or used a compressed audio format. To get the best performance, we suggest that you avoid breaking the audio up mid-sentence as this may cause some context to be lost.
One way to handle this is to use the [PyDub open source Python package](https://github.com/jiaaro/pydub) to split the audio:
```python
from pydub import AudioSegment
song = AudioSegment.from_mp3("good_morning.mp3")
# PyDub handles time in milliseconds
ten_minutes = 10 * 60 * 1000
first_10_minutes = song[:ten_minutes]
first_10_minutes.export("good_morning_10.mp3", format="mp3")
```
_OpenAI makes no guarantees about the usability or security of 3rd party software like PyDub._
## Prompting
You can use a [prompt](https://developers.openai.com/api/docs/api-reference/audio/createTranscription#audio/createTranscription-prompt) to improve the quality of the transcripts generated by the Transcriptions API.
Prompting
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const transcription = await openai.audio.transcriptions.create({
file: fs.createReadStream("/path/to/file/speech.mp3"),
model: "gpt-4o-transcribe",
response_format: "text",
prompt:"The following conversation is a lecture about the recent developments around OpenAI, GPT-4.5 and the future of AI.",
});
console.log(transcription.text);
```
```python
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/speech.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
response_format="text",
prompt="The following conversation is a lecture about the recent developments around OpenAI, GPT-4.5 and the future of AI."
)
print(transcription.text)
```
```bash
curl --request POST \\
--url https://api.openai.com/v1/audio/transcriptions \\
--header "Authorization: Bearer $OPENAI_API_KEY" \\
--header 'Content-Type: multipart/form-data' \\
--form file=@/path/to/file/speech.mp3 \\
--form model=gpt-4o-transcribe \\
--form prompt="The following conversation is a lecture about the recent developments around OpenAI, GPT-4.5 and the future of AI."
```
For `gpt-4o-transcribe` and `gpt-4o-mini-transcribe`, you can use the `prompt` parameter to improve the quality of the transcription by giving the model additional context similarly to how you would prompt other GPT-4o models. Prompting is not currently available for `gpt-4o-transcribe-diarize`.
Here are some examples of how prompting can help in different scenarios:
1. Prompts can help correct specific words or acronyms that the model misrecognizes in the audio. For example, the following prompt improves the transcription of the words DALL·E and GPT-3, which were previously written as "GDP 3" and "DALI": "The transcript is about OpenAI which makes technology like DALL·E, GPT-3, and ChatGPT with the hope of one day building an AGI system that benefits all of humanity."
2. To preserve the context of a file that was split into segments, prompt the model with the transcript of the preceding segment. The model uses relevant information from the previous audio, improving transcription accuracy. The `whisper-1` model only considers the final 224 tokens of the prompt and ignores anything earlier. For multilingual inputs, Whisper uses a custom tokenizer. For English-only inputs, it uses the standard GPT-2 tokenizer. Find both tokenizers in the open source [Whisper Python package](https://github.com/openai/whisper/blob/main/whisper/tokenizer.py#L361).
3. Sometimes the model skips punctuation in the transcript. To prevent this, use a simple prompt that includes punctuation: "Hello, welcome to my lecture."
4. The model may also leave out common filler words in the audio. If you want to keep the filler words in your transcript, use a prompt that contains them: "Umm, let me think like, hmm... Okay, here's what I'm, like, thinking."
5. Some languages can be written in different ways, such as simplified or traditional Chinese. The model might not always use the writing style that you want for your transcript by default. You can improve this by using a prompt in your preferred writing style.
For `whisper-1`, the model tries to match the style of the prompt, so it's more likely to use capitalization and punctuation if the prompt does too. However, the current prompting system is more limited than our other language models and provides limited control over the generated text.
You can find more examples on improving your `whisper-1` transcriptions in the [improving reliability](#improving-reliability) section.
Streaming transcriptions
There are two ways you can stream your transcription depending on your use case and whether you are trying to transcribe an already completed audio recording or handle an ongoing stream of audio and use OpenAI for turn detection.
### Streaming the transcription of a completed audio recording
If you have an already completed audio recording, either because it's an audio file or you are using your own turn detection (like push-to-talk), you can use our Transcription API with `stream=True` to receive a stream of [transcript events](https://developers.openai.com/api/docs/api-reference/audio/transcript-text-delta-event) as soon as the model is done transcribing that part of the audio.
Stream transcriptions
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const stream = await openai.audio.transcriptions.create({
file: fs.createReadStream("/path/to/file/speech.mp3"),
model: "gpt-4o-mini-transcribe",
response_format: "text",
// highlight-start
stream: true,
// highlight-end
});
// highlight-start
for await (const event of stream) {
console.log(event);
}
// highlight-end
```
```python
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/speech.mp3", "rb")
stream = client.audio.transcriptions.create(
model="gpt-4o-mini-transcribe",
file=audio_file,
response_format="text",
# highlight-start
stream=True
# highlight-end
)
# highlight-start
for event in stream:
print(event)
# highlight-end
```
```bash
curl --request POST \\
--url https://api.openai.com/v1/audio/transcriptions \\
--header "Authorization: Bearer $OPENAI_API_KEY" \\
--header 'Content-Type: multipart/form-data' \\
--form file=@example.wav \\
--form model=whisper-1 \\
# highlight-start
--form stream=True
```
You will receive a stream of `transcript.text.delta` events as soon as the model is done transcribing that part of the audio, followed by a `transcript.text.done` event when the transcription is complete that includes the full transcript. When using `response_format="diarized_json"`, the stream also emits `transcript.text.segment` events with speaker labels each time a segment is finalized.
Additionally, you can use the `include[]` parameter to include `logprobs` in the response to get the log probabilities of the tokens in the transcription. These can be helpful to determine how confident the model is in the transcription of that particular part of the transcript.
Streamed transcription is not supported in `whisper-1`.
### Streaming the transcription of an ongoing audio recording
In the Realtime API, you can stream the transcription of an ongoing audio recording. To start a streaming session with the Realtime API, create a WebSocket connection with the following URL:
```
wss://api.openai.com/v1/realtime?intent=transcription
```
Below is an example payload for setting up a transcription session:
```json
{
"type": "transcription_session.update",
"input_audio_format": "pcm16",
"input_audio_transcription": {
"model": "gpt-4o-transcribe",
"prompt": "",
"language": ""
},
"turn_detection": {
"type": "server_vad",
"threshold": 0.5,
"prefix_padding_ms": 300,
"silence_duration_ms": 500
},
"input_audio_noise_reduction": {
"type": "near_field"
},
"include": ["item.input_audio_transcription.logprobs"]
}
```
To stream audio data to the API, append audio buffers:
```json
{
"type": "input_audio_buffer.append",
"audio": "Base64EncodedAudioData"
}
```
When in VAD mode, the API will respond with `input_audio_buffer.committed` every time a chunk of speech has been detected. Use `input_audio_buffer.committed.item_id` and `input_audio_buffer.committed.previous_item_id` to enforce the ordering.
The API responds with transcription events indicating speech start, stop, and completed transcriptions.
The primary resource used by the streaming ASR API is the `TranscriptionSession`:
```json
{
"object": "realtime.transcription_session",
"id": "string",
"input_audio_format": "pcm16",
"input_audio_transcription": [{
"model": "whisper-1" | "gpt-4o-transcribe" | "gpt-4o-mini-transcribe",
"prompt": "string",
"language": "string"
}],
"turn_detection": {
"type": "server_vad",
"threshold": "float",
"prefix_padding_ms": "integer",
"silence_duration_ms": "integer",
} | null,
"input_audio_noise_reduction": {
"type": "near_field" | "far_field"
},
"include": ["string"]
}
```
Authenticate directly through the WebSocket connection using your API key or an ephemeral token obtained from:
```
POST /v1/realtime/transcription_sessions
```
This endpoint returns an ephemeral token (`client_secret`) to securely authenticate WebSocket connections.
## Improving reliability
One of the most common challenges faced when using Whisper is the model often does not recognize uncommon words or acronyms. Here are some different techniques to improve the reliability of Whisper in these cases:
Using the prompt parameter
The first method involves using the optional prompt parameter to pass a dictionary of the correct spellings.
Because it wasn't trained with instruction-following techniques, Whisper operates more like a base GPT model. Keep in mind that Whisper only considers the first 224 tokens of the prompt.
Prompt parameter
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const transcription = await openai.audio.transcriptions.create({
file: fs.createReadStream("/path/to/file/speech.mp3"),
model: "whisper-1",
response_format: "text",
prompt:"ZyntriQix, Digique Plus, CynapseFive, VortiQore V8, EchoNix Array, OrbitalLink Seven, DigiFractal Matrix, PULSE, RAPT, B.R.I.C.K., Q.U.A.R.T.Z., F.L.I.N.T.",
});
console.log(transcription.text);
```
```python
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/speech.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="text",
prompt="ZyntriQix, Digique Plus, CynapseFive, VortiQore V8, EchoNix Array, OrbitalLink Seven, DigiFractal Matrix, PULSE, RAPT, B.R.I.C.K., Q.U.A.R.T.Z., F.L.I.N.T."
)
print(transcription.text)
```
```bash
curl --request POST \\
--url https://api.openai.com/v1/audio/transcriptions \\
--header "Authorization: Bearer $OPENAI_API_KEY" \\
--header 'Content-Type: multipart/form-data' \\
--form file=@/path/to/file/speech.mp3 \\
--form model=whisper-1 \\
--form prompt="ZyntriQix, Digique Plus, CynapseFive, VortiQore V8, EchoNix Array, OrbitalLink Seven, DigiFractal Matrix, PULSE, RAPT, B.R.I.C.K., Q.U.A.R.T.Z., F.L.I.N.T."
```
While it increases reliability, this technique is limited to 224 tokens, so your list of SKUs needs to be relatively small for this to be a scalable solution.
Post-processing with GPT-4
The second method involves a post-processing step using GPT-4 or GPT-3.5-Turbo.
We start by providing instructions for GPT-4 through the `system_prompt` variable. Similar to what we did with the prompt parameter earlier, we can define our company and product names.
Post-processing
```javascript
const systemPrompt = \`
You are a helpful assistant for the company ZyntriQix. Your task is
to correct any spelling discrepancies in the transcribed text. Make
sure that the names of the following products are spelled correctly:
ZyntriQix, Digique Plus, CynapseFive, VortiQore V8, EchoNix Array,
OrbitalLink Seven, DigiFractal Matrix, PULSE, RAPT, B.R.I.C.K.,
Q.U.A.R.T.Z., F.L.I.N.T. Only add necessary punctuation such as
periods, commas, and capitalization, and use only the context provided.
\`;
const transcript = await transcribe(audioFile);
const completion = await openai.chat.completions.create({
model: "gpt-4.1",
temperature: temperature,
messages: [
{
role: "system",
content: systemPrompt
},
{
role: "user",
content: transcript
}
],
store: true,
});
console.log(completion.choices[0].message.content);
```
```python
system_prompt = """
You are a helpful assistant for the company ZyntriQix. Your task is to correct
any spelling discrepancies in the transcribed text. Make sure that the names of
the following products are spelled correctly: ZyntriQix, Digique Plus,
CynapseFive, VortiQore V8, EchoNix Array, OrbitalLink Seven, DigiFractal
Matrix, PULSE, RAPT, B.R.I.C.K., Q.U.A.R.T.Z., F.L.I.N.T. Only add necessary
punctuation such as periods, commas, and capitalization, and use only the
context provided.
"""
def generate_corrected_transcript(temperature, system_prompt, audio_file):
response = client.chat.completions.create(
model="gpt-4.1",
temperature=temperature,
messages=[
{
"role": "system",
"content": system_prompt
},
{
"role": "user",
"content": transcribe(audio_file, "")
}
]
)
return completion.choices[0].message.content
corrected_text = generate_corrected_transcript(
0, system_prompt, fake_company_filepath
)
```
If you try this on your own audio file, you'll see that GPT-4 corrects many misspellings in the transcript. Due to its larger context window, this method might be more scalable than using Whisper's prompt parameter. It's also more reliable, as GPT-4 can be instructed and guided in ways that aren't possible with Whisper due to its lack of instruction following.
---
# Streaming API responses
By default, when you make a request to the OpenAI API, we generate the model's entire output before sending it back in a single HTTP response. When generating long outputs, waiting for a response can take time. Streaming responses lets you start printing or processing the beginning of the model's output while it continues generating the full response.
This guide focuses on HTTP streaming (`stream=true`) over server-sent events (SSE). For persistent WebSocket transport with incremental inputs via `previous_response_id`, see [the Responses API WebSocket mode](https://developers.openai.com/api/docs/guides/websocket-mode).
## Enable streaming
To start streaming responses, set `stream=True` in your request to the Responses endpoint:
The Responses API uses semantic events for streaming. Each event is typed with a predefined schema, so you can listen for events you care about.
For a full list of event types, see the [API reference for streaming](https://developers.openai.com/api/docs/api-reference/responses-streaming). Here are a few examples:
```python
type StreamingEvent =
| ResponseCreatedEvent
| ResponseInProgressEvent
| ResponseFailedEvent
| ResponseCompletedEvent
| ResponseOutputItemAdded
| ResponseOutputItemDone
| ResponseContentPartAdded
| ResponseContentPartDone
| ResponseOutputTextDelta
| ResponseOutputTextAnnotationAdded
| ResponseTextDone
| ResponseRefusalDelta
| ResponseRefusalDone
| ResponseFunctionCallArgumentsDelta
| ResponseFunctionCallArgumentsDone
| ResponseFileSearchCallInProgress
| ResponseFileSearchCallSearching
| ResponseFileSearchCallCompleted
| ResponseCodeInterpreterInProgress
| ResponseCodeInterpreterCallCodeDelta
| ResponseCodeInterpreterCallCodeDone
| ResponseCodeInterpreterCallInterpreting
| ResponseCodeInterpreterCallCompleted
| Error
```
## Read the responses
If you're using our SDK, every event is a typed instance. You can also identity individual events using the `type` property of the event.
Some key lifecycle events are emitted only once, while others are emitted multiple times as the response is generated. Common events to listen for when streaming text are:
```
- `response.created`
- `response.output_text.delta`
- `response.completed`
- `error`
```
For a full list of events you can listen for, see the [API reference for streaming](https://developers.openai.com/api/docs/api-reference/responses-streaming).
## Advanced use cases
For more advanced use cases, like streaming tool calls, check out the following dedicated guides:
- [Streaming function calls](https://developers.openai.com/api/docs/guides/function-calling#streaming)
- [Streaming structured output](https://developers.openai.com/api/docs/guides/structured-outputs#streaming)
## Moderation risk
Note that streaming the model's output in a production application makes it more difficult to moderate the content of the completions, as partial completions may be more difficult to evaluate. This may have implications for approved usage.
---
# Structured model outputs
export const snippetRefusalsChatCompletionsApi = {
python: `
class Step(BaseModel):
explanation: str
output: str
class MathReasoning(BaseModel):
steps: list[Step]
final_answer: str
completion = client.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": "You are a helpful math tutor. Guide the user through the solution step by step."},
{"role": "user", "content": "how can I solve 8x + 7 = -23"},
],
response_format=MathReasoning,
)
math_reasoning = completion.choices[0].message
# If the model refuses to respond, you will get a refusal message
if math_reasoning.refusal:
print(math_reasoning.refusal)
else:
print(math_reasoning.parsed)
`.trim(),
"javascript": `
const Step = z.object({
explanation: z.string(),
output: z.string(),
});
const MathReasoning = z.object({
steps: z.array(Step),
final_answer: z.string(),
});
const completion = await openai.chat.completions.parse({
model: "gpt-4o-2024-08-06",
messages: [
{ role: "system", content: "You are a helpful math tutor. Guide the user through the solution step by step." },
{ role: "user", content: "how can I solve 8x + 7 = -23" },
],
response_format: zodResponseFormat(MathReasoning, "math_reasoning"),
});
const math_reasoning = completion.choices[0].message
// If the model refuses to respond, you will get a refusal message
if (math_reasoning.refusal) {
console.log(math_reasoning.refusal);
} else {
console.log(math_reasoning.parsed);
}
`.trim(),
};
export const snippetRefusalsResponsesApi = {
python: `
class Step(BaseModel):
explanation: str
output: str
class MathReasoning(BaseModel):
steps: list[Step]
final_answer: str
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{"role": "system", "content": "You are a helpful math tutor. Guide the user through the solution step by step."},
{"role": "user", "content": "how can I solve 8x + 7 = -23"},
],
text_format=MathReasoning,
)
for output in response.output:
if output.type != "message":
raise Exception("Unexpected non message")
for item in output.content:
if item.type == "refusal":
# If the model refuses to respond, you will get a refusal message
print(item.refusal)
continue
if not item.parsed:
raise Exception("Could not parse response")
print(item.parsed)
`.trim(),
"javascript": `
const Step = z.object({
explanation: z.string(),
output: z.string(),
});
const MathReasoning = z.object({
steps: z.array(Step),
final_answer: z.string(),
});
const response = await openai.responses.parse({
model: "gpt-4o-2024-08-06",
input: [
{ role: "system", content: "You are a helpful math tutor. Guide the user through the solution step by step." },
{ role: "user", content: "how can I solve 8x + 7 = -23" }
],
text: {
format: zodTextFormat(MathReasoning, "math_response"),
},
});
for (const output of response.output) {
if (output.type != "message") {
throw new Error("Unexpected non message");
}
for (const item of output.content) {
if (item.type == "refusal") {
// If the model refuses to respond, you will get a refusal message
console.log(item.refusal);
continue;
}
if (!item.parsed) {
throw new Error("Could not parse response");
}
console.log(item.parsed);
}
}
`.trim(),
};
export const snippetRefusalApiResponseChatCompletionsApi = {
json: `
{
"id": "chatcmpl-9nYAG9LPNonX8DAyrkwYfemr3C8HC",
"object": "chat.completion",
"created": 1721596428,
"model": "gpt-4o-2024-08-06",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
// highlight-start
"refusal": "I'm sorry, I cannot assist with that request."
// highlight-end
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 81,
"completion_tokens": 11,
"total_tokens": 92,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"system_fingerprint": "fp_3407719c7f"
}
`.trim(),
};
export const snippetRefusalApiResponseResponsesApi = {
json: `
{
"id": "resp_1234567890",
"object": "response",
"created_at": 1721596428,
"status": "completed",
"completed_at": 1721596429,
"error": null,
"incomplete_details": null,
"input": [],
"instructions": null,
"max_output_tokens": null,
"model": "gpt-4o-2024-08-06",
"output": [{
"id": "msg_1234567890",
"type": "message",
"role": "assistant",
"content": [
// highlight-start
{
"type": "refusal",
"refusal": "I'm sorry, I cannot assist with that request."
}
// highlight-end
]
}],
"usage": {
"input_tokens": 81,
"output_tokens": 11,
"total_tokens": 92,
"output_tokens_details": {
"reasoning_tokens": 0,
}
},
}
`.trim(),
};
JSON is one of the most widely used formats in the world for applications to exchange data.
Structured Outputs is a feature that ensures the model will always generate responses that adhere to your supplied [JSON Schema](https://json-schema.org/overview/what-is-jsonschema), so you don't need to worry about the model omitting a required key, or hallucinating an invalid enum value.
Some benefits of Structured Outputs include:
1. **Reliable type-safety:** No need to validate or retry incorrectly formatted responses
1. **Explicit refusals:** Safety-based model refusals are now programmatically detectable
1. **Simpler prompting:** No need for strongly worded prompts to achieve consistent formatting
In addition to supporting JSON Schema in the REST API, the OpenAI SDKs for [Python](https://github.com/openai/openai-python/blob/main/helpers.md#structured-outputs-parsing-helpers) and [JavaScript](https://github.com/openai/openai-node/blob/master/helpers.md#structured-outputs-parsing-helpers) also make it easy to define object schemas using [Pydantic](https://docs.pydantic.dev/latest/) and [Zod](https://zod.dev/) respectively. Below, you can see how to extract information from unstructured text that conforms to a schema defined in code.
### Supported models
Structured Outputs is available in our [latest large language models](https://developers.openai.com/api/docs/models), starting with GPT-4o. Older models like `gpt-4-turbo` and earlier may use [JSON mode](#json-mode) instead.
When to use Structured Outputs via function calling vs via{" "}
text.format
Structured Outputs is available in two forms in the OpenAI API:
1. When using [function calling](https://developers.openai.com/api/docs/guides/function-calling)
2. When using a `json_schema` response format
Function calling is useful when you are building an application that bridges the models and functionality of your application.
For example, you can give the model access to functions that query a database in order to build an AI assistant that can help users with their orders, or functions that can interact with the UI.
Conversely, Structured Outputs via `response_format` are more suitable when you want to indicate a structured schema for use when the model responds to the user, rather than when the model calls a tool.
For example, if you are building a math tutoring application, you might want the assistant to respond to your user using a specific JSON Schema so that you can generate a UI that displays different parts of the model's output in distinct ways.
Put simply:
- If you are connecting the model to tools, functions, data, etc. in your
system, then you should use function calling - If you want to structure the
model's output when it responds to the user, then you should use a structured
`text.format`
The remainder of this guide will focus on non-function calling use cases in
the Responses API. To learn more about how to use Structured Outputs with
function calling, check out the{" "}
[Function Calling](https://developers.openai.com/api/docs/guides/function-calling#function-calling-with-structured-outputs){" "}
guide.
### Structured Outputs vs JSON mode
Structured Outputs is the evolution of [JSON mode](#json-mode). While both ensure valid JSON is produced, only Structured Outputs ensure schema adherence. Both Structured Outputs and JSON mode are supported in the Responses API, Chat Completions API, Assistants API, Fine-tuning API and Batch API.
We recommend always using Structured Outputs instead of JSON mode when possible.
However, Structured Outputs with `response_format: {type: "json_schema", ...}` is only supported with the `gpt-4o-mini`, `gpt-4o-mini-2024-07-18`, and `gpt-4o-2024-08-06` model snapshots and later.
| | Structured Outputs | JSON Mode |
|--------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------|
| **Outputs valid JSON** | Yes | Yes |
| **Adheres to schema** | Yes (see [supported schemas](#supported-schemas)) | No |
| **Compatible models** | `gpt-4o-mini`, `gpt-4o-2024-08-06`, and later | `gpt-3.5-turbo`, `gpt-4-*` and `gpt-4o-*` models |
| **Enabling** | `text: { format: { type: "json_schema", "strict": true, "schema": ... } }` | `text: { format: { type: "json_object" } }` |
## Examples
Structured data extraction
How to use Structured Outputs with text.format
Refusals with Structured Outputs
When using Structured Outputs with user-generated input, OpenAI models may occasionally refuse to fulfill the request for safety reasons. Since a refusal does not necessarily follow the schema you have supplied in `response_format`, the API response will include a new field called `refusal` to indicate that the model refused to fulfill the request.
When the `refusal` property appears in your output object, you might present the refusal in your UI, or include conditional logic in code that consumes the response to handle the case of a refused request.
The API response from a refusal will look something like this:
Tips and best practices
#### Handling user-generated input
If your application is using user-generated input, make sure your prompt includes instructions on how to handle situations where the input cannot result in a valid response.
The model will always try to adhere to the provided schema, which can result in hallucinations if the input is completely unrelated to the schema.
You could include language in your prompt to specify that you want to return empty parameters, or a specific sentence, if the model detects that the input is incompatible with the task.
#### Handling mistakes
Structured Outputs can still contain mistakes. If you see mistakes, try adjusting your instructions, providing examples in the system instructions, or splitting tasks into simpler subtasks. Refer to the [prompt engineering guide](https://developers.openai.com/api/docs/guides/prompt-engineering) for more guidance on how to tweak your inputs.
#### Avoid JSON schema divergence
To prevent your JSON Schema and corresponding types in your programming language from diverging, we strongly recommend using the native Pydantic/zod sdk support.
If you prefer to specify the JSON schema directly, you could add CI rules that flag when either the JSON schema or underlying data objects are edited, or add a CI step that auto-generates the JSON Schema from type definitions (or vice-versa).
## Streaming
## Supported schemas
## JSON mode
JSON mode is a more basic version of the Structured Outputs feature. While
JSON mode ensures that model output is valid JSON, Structured Outputs reliably
matches the model's output to the schema you specify. We recommend you use
Structured Outputs if it is supported for your use case.
When JSON mode is turned on, the model's output is ensured to be valid JSON, except for in some edge cases that you should detect and handle appropriately.
To turn on JSON mode with the Responses API you can set the `text.format` to `{ "type": "json_object" }`. If you are using function calling, JSON mode is always turned on.
Important notes:
- When using JSON mode, you must always instruct the model to produce JSON via some message in the conversation, for example via your system message. If you don't include an explicit instruction to generate JSON, the model may generate an unending stream of whitespace and the request may run continually until it reaches the token limit. To help ensure you don't forget, the API will throw an error if the string "JSON" does not appear somewhere in the context.
- JSON mode will not guarantee the output matches any specific schema, only that it is valid and parses without errors. You should use Structured Outputs to ensure it matches your schema, or if that is not possible, you should use a validation library and potentially retries to ensure that the output matches your desired schema.
- Your application must detect and handle the edge cases that can result in the model output not being a complete JSON object (see below)
Handling edge cases
## Resources
To learn more about Structured Outputs, we recommend browsing the following resources:
- Check out our [introductory cookbook](https://developers.openai.com/cookbook/examples/structured_outputs_intro) on Structured Outputs
- Learn [how to build multi-agent systems](https://developers.openai.com/cookbook/examples/structured_outputs_multi_agent) with Structured Outputs
---
# Supervised fine-tuning
Supervised fine-tuning (SFT) lets you train an OpenAI model with examples for your specific use case. The result is a customized model that more reliably produces your desired style and content.
OpenAI is winding down the fine-tuning platform. The platform is no longer
accessible to new users, but existing users of the fine-tuning platform will
be able to create training jobs for the coming months.
All fine-tuned models will remain available for inference until their base
models are [deprecated](https://developers.openai.com/api/docs/deprecations). The full timeline is
[here](https://developers.openai.com/api/docs/deprecations).
| How it works |
Best for |
Use with |
|
Provide examples of correct responses to prompts to guide the model's behavior.
Often uses human-generated "ground truth" responses to show the model how it should respond.
|
- Classification
- Nuanced translation
- Generating content in a specific format
- Correcting instruction-following failures
|
`gpt-4.1-2025-04-14`
`gpt-4.1-mini-2025-04-14`
`gpt-4.1-nano-2025-04-14`
|
## Overview
Supervised fine-tuning has four major parts:
1. Build your training dataset to determine what "good" looks like
1. Upload a training dataset containing example prompts and desired model output
1. Create a fine-tuning job for a base model using your training data
1. Evaluate your results using the fine-tuned model
**Good evals first!** Only invest in fine-tuning after setting up evals. You
need a reliable way to determine whether your fine-tuned model is performing
better than a base model.
[Set up evals →](https://developers.openai.com/api/docs/guides/evals)
## Build your dataset
Build a robust, representative dataset to get useful results from a fine-tuned model. Use the following techniques and considerations.
### Right number of examples
- The minimum number of examples you can provide for fine-tuning is 10
- We see improvements from fine-tuning on 50–100 examples, but the right number for you varies greatly and depends on the use case
- We recommend starting with 50 well-crafted demonstrations and [evaluating the results](https://developers.openai.com/api/docs/guides/evals)
If performance improves with 50 good examples, try adding examples to see further results. If 50 examples have no impact, rethink your task or prompt before adding training data.
### What makes a good example
- Whatever prompts and outputs you expect in your application, as realistic as possible
- Specific, clear questions and answers
- Use historical data, expert data, logged data, or [other types of collected data](https://developers.openai.com/api/docs/guides/evals)
### Formatting your data
- Use [JSONL format](https://jsonlines.org/), with one complete JSON structure on every line of the training data file
- Use the [chat completions format](https://developers.openai.com/api/docs/api-reference/fine-tuning/chat-input)
- Your file must have at least 10 lines
JSONL format example file
### Distilling from a larger model
One way to build a training data set for a smaller model is to distill the results of a large model to create training data for supervised fine tuning. The general flow of this technique is:
- Tune a prompt for a larger model (like `gpt-4.1`) until you get great performance against your eval criteria.
- Capture results generated from your model using whatever technique is convenient - note that the [Responses API](https://developers.openai.com/api/docs/api-reference/responses) stores model responses for 30 days by default.
- Use the captured responses from the large model that fit your criteria to generate a dataset using the tools and techniques described above.
- Tune a smaller model (like `gpt-4.1-mini`) using the dataset you created from the large model.
This technique can enable you to train a small model to perform similarly on a specific task to a larger, more costly model.
## Upload training data
Upload your dataset of examples to OpenAI. We use it to update the model's weights and produce outputs like the ones included in your data.
In addition to text completions, you can train the model to more effectively generate [structured JSON output](https://developers.openai.com/api/docs/guides/structured-outputs) or [function calls](https://developers.openai.com/api/docs/guides/function-calling).
Upload your data with button clicks
Call the API to upload your data
## Create a fine-tuning job
With your test data uploaded, [create a fine-tuning job](https://developers.openai.com/api/docs/api-reference/fine-tuning/create) to customize a base model using the training data you provide. When creating a fine-tuning job, you must specify:
- A base model (`model`) to use for fine-tuning. This can be either an OpenAI model ID or the ID of a previously fine-tuned model. See which models support fine-tuning in the [model docs](https://developers.openai.com/api/docs/models).
- A training file (`training_file`) ID. This is the file you uploaded in the previous step.
- A fine-tuning method (`method`). This specifies which fine-tuning method you want to use to customize the model. Supervised fine-tuning is the default.
Upload your data with button clicks
Call the API to upload your data
## Evaluate the result
Use the approaches below to check how your fine-tuned model performs. Adjust your prompts, data, and fine-tuning job as needed until you get the results you want. The best way to fine-tune is to continue iterating.
### Compare to evals
To see if your fine-tuned model performs better than the original base model, [use evals](https://developers.openai.com/api/docs/guides/evals). Before running your fine-tuning job, carve out data from the same training dataset you collected in step 1. This holdout data acts as a control group when you use it for evals. Make sure the training and holdout data have roughly the same diversity of user input types and model responses.
[Learn more about running evals](https://developers.openai.com/api/docs/guides/evals).
### Monitor the status
Check the status of a fine-tuning job in the dashboard or by polling the job ID in the API.
### Try using your fine-tuned model
Evaluate your newly optimized model by using it! When the fine-tuned model finishes training, use its ID in either the [Responses](https://developers.openai.com/api/docs/api-reference/responses) or [Chat Completions](https://developers.openai.com/api/docs/api-reference/chat) API, just as you would an OpenAI base model.
Use your model in the Playground
Use your model with an API call
### Use checkpoints if needed
Checkpoints are models you can use. We create a full model checkpoint for you at the end of each training epoch. They're useful in cases where your fine-tuned model improves early on but then memorizes the dataset instead of learning generalizable knowledge—called \_overfitting. Checkpoints provide versions of your customized model from various moments in the process.
Find checkpoints in the dashboard
Query the API for checkpoints
Currently, only the checkpoints for the last three epochs of the job are saved and available for use.
## Safety checks
Before launching in production, review and follow the following safety information.
How we assess for safety
Once a fine-tuning job is completed, we assess the resulting model’s behavior across 13 distinct safety categories. Each category represents a critical area where AI outputs could potentially cause harm if not properly controlled.
| Name | Description |
| :--------------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| advice | Advice or guidance that violates our policies. |
| harassment/threatening | Harassment content that also includes violence or serious harm towards any target. |
| hate | Content that expresses, incites, or promotes hate based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. Hateful content aimed at non-protected groups (e.g., chess players) is harassment. |
| hate/threatening | Hateful content that also includes violence or serious harm towards the targeted group based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. |
| highly-sensitive | Highly sensitive data that violates our policies. |
| illicit | Content that gives advice or instruction on how to commit illicit acts. A phrase like "how to shoplift" would fit this category. |
| propaganda | Praise or assistance for ideology that violates our policies. |
| self-harm/instructions | Content that encourages performing acts of self-harm, such as suicide, cutting, and eating disorders, or that gives instructions or advice on how to commit such acts. |
| self-harm/intent | Content where the speaker expresses that they are engaging or intend to engage in acts of self-harm, such as suicide, cutting, and eating disorders. |
| sensitive | Sensitive data that violates our policies. |
| sexual/minors | Sexual content that includes an individual who is under 18 years old. |
| sexual | Content meant to arouse sexual excitement, such as the description of sexual activity, or that promotes sexual services (excluding sex education and wellness). |
| violence | Content that depicts death, violence, or physical injury. |
Each category has a predefined pass threshold; if too many evaluated examples in a given category fail, OpenAI blocks the fine-tuned model from deployment. If your fine-tuned model does not pass the safety checks, OpenAI sends a message in the fine-tuning job explaining which categories don't meet the required thresholds. You can view the results in the moderation checks section of the fine-tuning job.
How to pass safety checks
In addition to reviewing any failed safety checks in the fine-tuning job object, you can retrieve details about which categories failed by querying the [fine-tuning API events endpoint](https://developers.openai.com/api/docs/api-reference/fine-tuning/list-events). Look for events of type `moderation_checks` for details about category results and enforcement. This information can help you narrow down which categories to target for retraining and improvement. The [model spec](https://cdn.openai.com/spec/model-spec-2024-05-08.html#overview) has rules and examples that can help identify areas for additional training data.
While these evaluations cover a broad range of safety categories, conduct your own evaluations of the fine-tuned model to ensure it's appropriate for your use case.
## Next steps
Now that you know the basics of supervised fine-tuning, explore these other methods as well.
[
Learn to fine-tune for computer vision with image inputs.
](https://developers.openai.com/api/docs/guides/vision-fine-tuning)
[
Fine-tune a model using direct preference optimization (DPO).
](https://developers.openai.com/api/docs/guides/direct-preference-optimization)
[
Fine-tune a reasoning model by grading its outputs.
](https://developers.openai.com/api/docs/guides/reinforcement-fine-tuning)
---
# Text generation
With the OpenAI API, you can use a [large language model](https://developers.openai.com/api/docs/models) to generate text from a prompt, as you might using [ChatGPT](https://chatgpt.com). Models can generate almost any kind of text response—like code, mathematical equations, structured JSON data, or human-like prose.
Use the [Responses API](https://developers.openai.com/api/docs/api-reference/responses) for direct model requests like this text-generation call.
An array of content generated by the model is in the `output` property of the response. In this simple example, we have just one output which looks like this:
```json
[
{
"id": "msg_67b73f697ba4819183a15cc17d011509",
"type": "message",
"role": "assistant",
"content": [
{
"type": "output_text",
"text": "Under the soft glow of the moon, Luna the unicorn danced through fields of twinkling stardust, leaving trails of dreams for every child asleep.",
"annotations": []
}
]
}
]
```
**The `output` array often has more than one item in it!** It can contain tool calls, data about reasoning tokens generated by [reasoning models](https://developers.openai.com/api/docs/guides/reasoning), and other items. It is not safe to assume that the model's text output is present at `output[0].content[0].text`.
Some of our [official SDKs](https://developers.openai.com/api/docs/libraries) include an `output_text` property on model responses for convenience, which aggregates all text outputs from the model into a single string. This may be useful as a shortcut to access text output from the model.
In addition to plain text, you can also have the model return structured data in JSON format—this feature is called [**Structured Outputs**](https://developers.openai.com/api/docs/guides/structured-outputs).
## Prompt engineering
**Prompt engineering** is the process of writing effective instructions for a model, such that it consistently generates content that meets your requirements.
Because the content generated from a model is non-deterministic, prompting to get your desired output is a mix of art and science. However, you can apply techniques and best practices to get good results consistently.
Some prompt engineering techniques work with every model, like using message roles. But different models might need to be prompted differently to produce the best results. Even different snapshots of models within the same family could produce different results. So as you build more complex applications, we strongly recommend:
- Pinning your production applications to specific [model snapshots](https://developers.openai.com/api/docs/models) (like `gpt-5-2025-08-07` for example) to ensure consistent behavior
- Building [evals](https://developers.openai.com/api/docs/guides/evals) that measure the behavior of your prompts so you can monitor prompt performance as you iterate, or when you change and upgrade model versions
Now, let's examine some tools and techniques available to you to construct prompts.
## Choosing models and APIs
OpenAI has many different [models](https://developers.openai.com/api/docs/models) and several APIs to choose from. [Reasoning models](https://developers.openai.com/api/docs/guides/reasoning), like o3 and GPT-5, behave differently from chat models and respond better to different prompts. One important note is that reasoning models perform better and demonstrate higher intelligence when used with the Responses API.
If you're building any text generation app, we recommend using the Responses API over the older Chat Completions API. And if you're using a reasoning model, it's especially useful to [migrate to Responses](https://developers.openai.com/api/docs/guides/migrate-to-responses).
## Message roles and instruction following
You can provide instructions to the model with [differing levels of authority](https://model-spec.openai.com/2025-02-12.html#chain_of_command) using the `instructions` API parameter along with **message roles**.
The `instructions` parameter gives the model high-level instructions on how it should behave while generating a response, including tone, goals, and examples of correct responses. Any instructions provided this way will take priority over a prompt in the `input` parameter.
Generate text with instructions
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5",
reasoning: { effort: "low" },
instructions: "${semicolonsDevMsg}",
input: "${semicolonsPrompt}",
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
reasoning={"effort": "low"},
instructions="${semicolonsDevMsg}",
input="${semicolonsPrompt}",
)
print(response.output_text)
```
```bash
curl "https://api.openai.com/v1/responses" \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"reasoning": {"effort": "low"},
"instructions": "${semicolonsDevMsg}",
"input": "${semicolonsPrompt}"
}'
```
The example above is roughly equivalent to using the following input messages in the `input` array:
Generate text with messages using different roles
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5",
reasoning: { effort: "low" },
input: [
{
role: "developer",
content: "${semicolonsDevMsg}"
},
{
role: "user",
content: "${semicolonsPrompt}",
},
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
reasoning={"effort": "low"},
input=[
{
"role": "developer",
"content": "${semicolonsDevMsg}"
},
{
"role": "user",
"content": "${semicolonsPrompt}"
}
]
)
print(response.output_text)
```
```bash
curl "https://api.openai.com/v1/responses" \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5",
"reasoning": {"effort": "low"},
"input": [
{
"role": "developer",
"content": "${semicolonsDevMsg}"
},
{
"role": "user",
"content": "${semicolonsPrompt}"
}
]
}'
```
Note that the `instructions` parameter only applies to the current response generation request. If you are [managing conversation state](https://developers.openai.com/api/docs/guides/conversation-state) with the `previous_response_id` parameter, the `instructions` used on previous turns will not be present in the context.
The [OpenAI model spec](https://model-spec.openai.com/2025-02-12.html#chain_of_command) describes how our models give different levels of priority to messages with different roles.
| developer |
user |
assistant |
|
`developer` messages are instructions provided by the application
developer, prioritized ahead of user messages.
|
`user` messages are instructions provided by an end user, prioritized
behind developer messages.
|
Messages generated by the model have the assistant role.
|
A multi-turn conversation may consist of several messages of these types, along with other content types provided by both you and the model. Learn more about [managing conversation state here](https://developers.openai.com/api/docs/guides/conversation-state).
You could think about `developer` and `user` messages like a function and its arguments in a programming language.
- `developer` messages provide the system's rules and business logic, like a function definition.
- `user` messages provide inputs and configuration to which the `developer` message instructions are applied, like arguments to a function.
## Reusable prompts
In the OpenAI dashboard, you can develop reusable [prompts](https://platform.openai.com/chat/edit) that you can use in API requests, rather than specifying the content of prompts in code. This way, you can more easily build and evaluate your prompts, and deploy improved versions of your prompts without changing your integration code.
Here's how it works:
1. **Create a reusable prompt** in the [dashboard](https://platform.openai.com/chat/edit) with placeholders like `{{customer_name}}`.
2. **Use the prompt** in your API request with the `prompt` parameter. The prompt parameter object has three properties you can configure:
- `id` — Unique identifier of your prompt, found in the dashboard
- `version` — A specific version of your prompt (defaults to the "current" version as specified in the dashboard)
- `variables` — A map of values to substitute in for variables in your prompt. The substitution values can either be strings, or other Response input message types like `input_image` or `input_file`. [See the full API reference](https://developers.openai.com/api/docs/api-reference/responses/create).
String variables
Generate text with a prompt template
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5",
prompt: {
id: "pmpt_abc123",
version: "2",
variables: {
customer_name: "Jane Doe",
product: "40oz juice box"
}
}
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
prompt={
"id": "pmpt_abc123",
"version": "2",
"variables": {
"customer_name": "Jane Doe",
"product": "40oz juice box"
}
}
)
print(response.output_text)
```
```bash
curl https://api.openai.com/v1/responses \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"model": "gpt-5",
"prompt": {
"id": "pmpt_abc123",
"version": "2",
"variables": {
"customer_name": "Jane Doe",
"product": "40oz juice box"
}
}
}'
```
Variables with file input
Prompt template with file input variable
```javascript
import fs from "fs";
import OpenAI from "openai";
const client = new OpenAI();
// Upload a PDF we will reference in the prompt variables
const file = await client.files.create({
file: fs.createReadStream("draconomicon.pdf"),
purpose: "user_data",
});
const response = await client.responses.create({
model: "gpt-5",
prompt: {
id: "pmpt_abc123",
variables: {
topic: "Dragons",
reference_pdf: {
type: "input_file",
file_id: file.id,
},
},
},
});
console.log(response.output_text);
```
```python
import openai, pathlib
client = openai.OpenAI()
# Upload a PDF we will reference in the variables
file = client.files.create(
file=open("draconomicon.pdf", "rb"),
purpose="user_data",
)
response = client.responses.create(
model="gpt-5",
prompt={
"id": "pmpt_abc123",
"variables": {
"topic": "Dragons",
"reference_pdf": {
"type": "input_file",
"file_id": file.id,
},
},
},
)
print(response.output_text)
```
```bash
# Assume you have already uploaded the PDF and obtained FILE_ID
curl https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5",
"prompt": {
"id": "pmpt_abc123",
"variables": {
"topic": "Dragons",
"reference_pdf": {
"type": "input_file",
"file_id": "file-abc123"
}
}
}
}'
```
## Next steps
Now that you known the basics of text inputs and outputs, you might want to check out one of these resources next.
[
Use the Playground to develop and iterate on prompts.
](https://platform.openai.com/chat/edit)
[
Ensure JSON data emitted from a model conforms to a JSON schema.
](https://developers.openai.com/api/docs/guides/structured-outputs)
[
Check out all the options for text generation in the API reference.
](https://developers.openai.com/api/docs/api-reference/responses)
---
# Text to speech
The Audio API provides a [`speech`](https://developers.openai.com/api/docs/api-reference/audio/createSpeech) endpoint based on our [GPT-4o mini TTS (text-to-speech) model](https://developers.openai.com/api/docs/models/gpt-4o-mini-tts). It comes with 11 built-in voices and can be used to:
- Narrate a written blog post
- Produce spoken audio in multiple languages
- Give realtime audio output using streaming
Here's an example of the `alloy` voice:
Our [usage policies](https://openai.com/policies/usage-policies) require you
to provide a clear disclosure to end users that the TTS voice they are hearing
is AI-generated and not a human voice.
## Quickstart
The `speech` endpoint takes three key inputs:
1. The [model](https://developers.openai.com/api/docs/api-reference/audio/createSpeech#audio-createspeech-model) you're using
1. The [text](https://developers.openai.com/api/docs/api-reference/audio/createSpeech#audio-createspeech-input) to be turned into audio
1. The [voice](https://developers.openai.com/api/docs/api-reference/audio/createSpeech#audio-createspeech-voice) that will speak the output
Here's a simple request example:
Generate spoken audio from input text
```javascript
import fs from "fs";
import path from "path";
import OpenAI from "openai";
const openai = new OpenAI();
const speechFile = path.resolve("./speech.mp3");
const mp3 = await openai.audio.speech.create({
model: "gpt-4o-mini-tts",
voice: "coral",
input: "Today is a wonderful day to build something people love!",
instructions: "Speak in a cheerful and positive tone.",
});
const buffer = Buffer.from(await mp3.arrayBuffer());
await fs.promises.writeFile(speechFile, buffer);
```
```python
from pathlib import Path
from openai import OpenAI
client = OpenAI()
speech_file_path = Path(__file__).parent / "speech.mp3"
with client.audio.speech.with_streaming_response.create(
model="gpt-4o-mini-tts",
voice="coral",
input="Today is a wonderful day to build something people love!",
instructions="Speak in a cheerful and positive tone.",
) as response:
response.stream_to_file(speech_file_path)
```
```bash
curl https://api.openai.com/v1/audio/speech \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"model": "gpt-4o-mini-tts",
"input": "Today is a wonderful day to build something people love!",
"voice": "coral",
"instructions": "Speak in a cheerful and positive tone."
}' \\
--output speech.mp3
```
```cli
openai audio:speech create \\
--model gpt-4o-mini-tts \\
--voice coral \\
--instructions "Speak in a cheerful and positive tone." \\
--input "Today is a wonderful day to build something people love!" \\
--output speech.mp3
```
By default, the endpoint outputs an MP3 of the spoken audio, but you can configure it to output any [supported format](#supported-output-formats).
### Text-to-speech models
For intelligent realtime applications, use the `gpt-4o-mini-tts` model, our newest and most reliable text-to-speech model. You can prompt the model to control aspects of speech, including:
- Accent
- Emotional range
- Intonation
- Impressions
- Speed of speech
- Tone
- Whispering
Our other text-to-speech models are `tts-1` and `tts-1-hd`. The `tts-1` model provides lower latency, but at a lower quality than the `tts-1-hd` model.
### Voice options
The TTS endpoint provides 13 built‑in voices to control how speech is rendered from text. **Hear and play with these voices in [OpenAI.fm](https://openai.fm), our interactive demo for trying the latest text-to-speech model in the OpenAI API**. Voices are currently optimized for English.
- `alloy`
- `ash`
- `ballad`
- `coral`
- `echo`
- `fable`
- `nova`
- `onyx`
- `sage`
- `shimmer`
- `verse`
- `marin`
- `cedar`
For best quality, we recommend using `marin` or `cedar`.
Voice availability depends on the model. The `tts-1` and `tts-1-hd` models support a smaller set: `alloy`, `ash`, `coral`, `echo`, `fable`, `onyx`, `nova`, `sage`, and `shimmer`.
If you're using the [Realtime API](https://developers.openai.com/api/docs/guides/realtime), note that the set of available voices is slightly different—see the [realtime conversations guide](https://developers.openai.com/api/docs/guides/realtime-conversations#voice-options) for current realtime voices.
### Streaming realtime audio
The Speech API provides support for realtime audio streaming using [chunk transfer encoding](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Transfer-Encoding). This means the audio can be played before the full file is generated and made accessible.
Stream spoken audio from input text directly to your speakers
```javascript
import OpenAI from "openai";
import { playAudio } from "openai/helpers/audio";
const openai = new OpenAI();
const response = await openai.audio.speech.create({
model: "gpt-4o-mini-tts",
voice: "coral",
input: "Today is a wonderful day to build something people love!",
instructions: "Speak in a cheerful and positive tone.",
response_format: "wav",
});
await playAudio(response);
```
```python
import asyncio
from openai import AsyncOpenAI
from openai.helpers import LocalAudioPlayer
openai = AsyncOpenAI()
async def main() -> None:
async with openai.audio.speech.with_streaming_response.create(
model="gpt-4o-mini-tts",
voice="coral",
input="Today is a wonderful day to build something people love!",
instructions="Speak in a cheerful and positive tone.",
response_format="pcm",
) as response:
await LocalAudioPlayer().play(response)
if __name__ == "__main__":
asyncio.run(main())
```
```bash
curl https://api.openai.com/v1/audio/speech \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"model": "gpt-4o-mini-tts",
"input": "Today is a wonderful day to build something people love!",
"voice": "coral",
"instructions": "Speak in a cheerful and positive tone.",
"response_format": "wav"
}' | ffplay -i -
```
For the fastest response times, we recommend using `wav` or `pcm` as the response format.
## Supported output formats
The default response format is `mp3`, but other formats like `opus` and `wav` are available.
- **MP3**: The default response format for general use cases.
- **Opus**: For internet streaming and communication, low latency.
- **AAC**: For digital audio compression, preferred by YouTube, Android, iOS.
- **FLAC**: For lossless audio compression, favored by audio enthusiasts for archiving.
- **WAV**: Uncompressed WAV audio, suitable for low-latency applications to avoid decoding overhead.
- **PCM**: Similar to WAV but contains the raw samples in 24kHz (16-bit signed, low-endian), without the header.
## Supported languages
The TTS model generally follows the Whisper model in terms of language support. Whisper [supports the following languages](https://github.com/openai/whisper#available-models-and-languages) and performs well, despite voices being optimized for English:
Afrikaans, Arabic, Armenian, Azerbaijani, Belarusian, Bosnian, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Kannada, Kazakh, Korean, Latvian, Lithuanian, Macedonian, Malay, Marathi, Maori, Nepali, Norwegian, Persian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Thai, Turkish, Ukrainian, Urdu, Vietnamese, and Welsh.
You can generate spoken audio in these languages by providing input text in the language of your choice.
## Custom voices
Custom voices enable you to create a unique voice for your agent or application. These voices can be used for audio output with the [Text to Speech API](https://developers.openai.com/api/docs/api-reference/audio/createSpeech), the [Realtime API](https://developers.openai.com/api/docs/api-reference/realtime), or the [Chat Completions API with audio output](https://developers.openai.com/api/docs/guides/audio).
To create a custom voice, you’ll provide a short sample audio reference that the model will seek to replicate.
Custom voices are limited to eligible customers. Contact our [sales
team](https://openai.com/contact-sales/) to learn more. Once enabled for your
organization, you’ll have access to the
[Voices](https://platform.openai.com/audio/voices) tab under Audio.
#### Creating a voice
Currently, voices must be created through an API request. See the API reference for the full set of API operations.
Creating a voice requires two separate audio recordings:
1. **Consent recording** — this recording captures the voice actor providing consent to create a likeness of their voice. The actor must read one of the consent phrases provided below.
2. **Sample recording** — the actual audio sample that the model will try to adhere to. The voice must match the consent recording.
**Tips for creating a high-quality voice**
The quality of your custom voice is highly dependent on the quality of the sample you provide. Optimizing the recording quality can make a big difference.
- Record in a quiet space with minimal echo.
- Use a professional XLR microphone.
- Stay about 7–8 inches from the mic with a pop filter in between, and keep that distance consistent.
- The model copies exactly what you give it—tone, cadence, energy, pauses, habits—so record the exact voice you want. Be consistent in energy, style, and accent throughout.
- Small variations in the audio sample can result in quality differences with the generated voice, it's worth trying multiple examples to find the best fit.
**Requirements and limitations**
- At most 20 voices can be created per organization.
- The audio samples must be 30 seconds or less.
- The audio samples must be one of the following types: `mpeg`, `wav`, `ogg`, `aac`, `flac`, `webm`, or `mp4`.
Refer to the Text-to-Speech Supplemental Agreement for additional terms of use.
**Creating a voice consent**
The consent audio recording must only include one of the following phrases. Any divergence from the script will lead to a failure.
| Language | Phrase |
| -------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| `de` | Ich bin der Eigentümer dieser Stimme und bin damit einverstanden, dass OpenAI diese Stimme zur Erstellung eines synthetischen Stimmmodells verwendet. |
| `en` | I am the owner of this voice and I consent to OpenAI using this voice to create a synthetic voice model. |
| `es` | Soy el propietario de esta voz y doy mi consentimiento para que OpenAI la utilice para crear un modelo de voz sintética. |
| `fr` | Je suis le propriétaire de cette voix et j'autorise OpenAI à utiliser cette voix pour créer un modèle de voix synthétique. |
| `hi` | मैं इस आवाज का मालिक हूं और मैं सिंथेटिक आवाज मॉडल बनाने के लिए OpenAI को इस आवाज का उपयोग करने की सहमति देता हूं |
| `id` | Saya adalah pemilik suara ini dan saya memberikan persetujuan kepada OpenAI untuk menggunakan suara ini guna membuat model suara sintetis. |
| `it` | Sono il proprietario di questa voce e acconsento che OpenAI la utilizzi per creare un modello di voce sintetica. |
| `ja` | 私はこの音声の所有者であり、OpenAIがこの音声を使用して音声合成 モデルを作成することを承認します。 |
| `ko` | 나는 이 음성의 소유자이며 OpenAI가 이 음성을 사용하여 음성 합성 모델을 생성할 것을 허용합니다. |
| `nl` | Ik ben de eigenaar van deze stem en ik geef OpenAI toestemming om deze stem te gebruiken om een synthetisch stemmodel te maken. |
| `pl` | Jestem właścicielem tego głosu i wyrażam zgodę na wykorzystanie go przez OpenAI w celu utworzenia syntetycznego modelu głosu. |
| `pt` | Eu sou o proprietário desta voz e autorizo o OpenAI a usá-la para criar um modelo de voz sintética. |
| `ru` | Я являюсь владельцем этого голоса и даю согласие OpenAI на использование этого голоса для создания модели синтетического голоса. |
| `uk` | Я є власником цього голосу і даю згоду OpenAI використовувати цей голос для створення синтетичної голосової моделі. |
| `vi` | Tôi là chủ sở hữu giọng nói này và tôi đồng ý cho OpenAI sử dụng giọng nói này để tạo mô hình giọng nói tổng hợp. |
| `zh` | 我是此声音的拥有者并授权OpenAI使用此声音创建语音合成模型 |
Then upload the recording via the API. A successful upload will return the consent recording ID that you’ll reference later. Note the consent can be used for multiple different voice creations if the same voice actor is making multiple attempts.
```bash
curl https://api.openai.com/v1/audio/voice_consents \
-X POST \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-F "name=test_consent" \
-F "language=en" \
-F "recording=@$HOME/tmp/voice_consent/consent_recording.wav;type=audio/x-wav"
```
**Creating a voice**
Next, you’ll create the actual voice by referencing the consent recording ID, and providing the voice sample.
```bash
curl https://api.openai.com/v1/audio/voices \
-X POST \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-F "name=test_voice" \
-F "audio_sample=@$HOME/tmp/voice_consent/audio_sample_recording.wav;type=audio/x-wav" \
-F "consent=cons_123abc"
```
If successful, the created voice will be listed under the [Audio tab](https://platform.openai.com/audio/voices).
#### Using a voice during speech generation
Speech generation will work as usual. Simply specify the ID of the voice in the `voice` parameter when [creating speech](https://developers.openai.com/api/docs/api-reference/audio/createSpeech), or when initiating a [realtime session](https://developers.openai.com/api/docs/api-reference/realtime/create-call#realtime_create_call-session-audio-output-voice).
**Text to speech example**
```bash
curl https://api.openai.com/v1/audio/speech \
-X POST \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-mini-tts",
"voice": {
"id": "voice_123abc"
},
"input": "Maple est le meilleur golden retriever du monde entier.",
"language": "fr",
"format": "wav"
}' \
--output sample.wav
```
**Realtime API example**
```javascript
const sessionConfig = JSON.stringify({
session: {
type: "realtime",
model: "gpt-realtime-2",
audio: {
output: {
voice: { id: "voice_123abc" },
},
},
},
});
```
## Related guides
Choose the right path for voice agents, translation, transcription, and
speech generation.
Review audio modalities, speech tasks, streaming, and request-based APIs.
---
# Theming and customization in ChatKit
import {
Inpaint,
Globe,
Playground,
Github,
Sparkles,
} from "@components/react/oai/platform/ui/Icon.react";
After following the [ChatKit quickstart](https://developers.openai.com/api/docs/guides/chatkit), learn how to change themes and add customization to your chat embed. Match your app’s aesthetic with light and dark themes, setting an accent color, controlling the density, and rounded corners.
## Overview
At a high level, customize the theme by passing in an options object. If you followed the [ChatKit quickstart](https://developers.openai.com/api/docs/guides/chatkit) to embed ChatKit in your frontend, use the React syntax below.
- **React**: Pass options to `useChatKit({...})`
- **Advanced integrations**: Set options with `chatkit.setOptions({...})`
In both integration types, the shape of the options object is the same.
## Explore customization options
Visit [ChatKit Studio](https://chatkit.studio) to see working implementations of ChatKit and interactive builders. If you like building by trying things rather than reading, these resources are a good starting point.
#### Explore ChatKit UI
Play with an interactive demo of ChatKit.
Browse available widgets.
Play with an interactive demo to learn by doing.
#### See working examples
See working examples of ChatKit and get inspired.
Clone a repo to start with a fully working template.
## Change the theme
Match the look and feel of your product by specifying colors, typography, and more. Below, we set to dark mode, change colors, round the corners, adjust the information density, and set the font.
For all theming options, see the [API reference](https://openai.github.io/chatkit-js/api/openai/chatkit/type-aliases/themeoption/).
```jsx
const options: Partial = {
theme: {
colorScheme: "dark",
color: {
accent: {
primary: "#2D8CFF",
level: 2
}
},
radius: "round",
density: "compact",
typography: { fontFamily: "'Inter', sans-serif" },
},
};
```
## Customize the start screen text
Let users know what to ask or guide their first input by changing the composer’s placeholder text.
```jsx
const options: Partial = {
composer: {
placeholder: "Ask anything about your data…",
},
startScreen: {
greeting: "Welcome to FeedbackBot!",
},
};
```
## Show starter prompts for new threads
Guide users on what to ask or do by suggesting prompt ideas when starting a conversation.
```js
const options: Partial = {
startScreen: {
greeting: "What can I help you build today?",
prompts: [
{
name: "Check on the status of a ticket",
prompt: "Can you help me check on the status of a ticket?",
icon: "search"
},
{
name: "Create Ticket",
prompt: "Can you help me create a new support ticket?",
icon: "write"
},
],
},
};
```
## Add custom buttons to the header
Custom header buttons help you add navigation, context, or actions relevant to your integration.
```jsx
const options: Partial = {
header: {
customButtonLeft: {
icon: "settings-cog",
onClick: () => openProfileSettings(),
},
customButtonRight: {
icon: "home",
onClick: () => openHomePage(),
},
},
};
```
## Enable file attachments
Attachments are disabled by default. To enable them, add attachments configuration.
Unless you are doing a custom backend, you must use the `hosted` upload strategy.
See the Python SDK docs for more information on other upload strategies work with a custom backend.
You can also control the number, size, and types of files that users can attach to messages.
```jsx
const options: Partial = {
composer: {
attachments: {
uploadStrategy: { type: 'hosted' },
maxSize: 20 * 1024 * 1024, // 20MB per file
maxCount: 3,
accept: { "application/pdf": [".pdf"], "image/*": [".png", ".jpg"] },
},
},
}
```
## Enable @mentions in the composer with entity tags
Let users tag custom “entities” with @-mentions. This enables richer conversation context and interactivity.
- Use `onTagSearch` to return a list of entities based on the input query.
- Use `onClick` to handle the click event of an entity.
```jsx
const options: Partial = {
entities: {
async onTagSearch(query) {
return [
{
id: "user_123",
title: "Jane Doe",
group: "People",
interactive: true,
},
{
id: "document_123",
title: "Quarterly Plan",
group: "Documents",
interactive: true,
},
]
},
onClick: (entity) => {
navigateToEntity(entity.id);
},
},
};
```
## Customize how entity tags appear
You can customize the appearance of entity tags on mouseover using widgets. Show rich previews such as a business card, document summary, or image when the user hovers over an entity tag.
Browse available widgets.
```jsx
const options: Partial = {
entities: {
async onTagSearch() { /* ... */ },
onRequestPreview: async (entity) => ({
preview: {
type: "Card",
children: [
{ type: "Text", value: `Profile: ${entity.title}` },
{ type: "Text", value: "Role: Developer" },
],
},
}),
},
};
```
## Add custom tools to the composer
Enhance productivity by letting users trigger app-specific actions from the composer bar. The selected tool
will be sent to the model as a tool preference.
```jsx
const options: Partial = {
composer: {
tools: [
{
id: 'add-note',
label: 'Add Note',
icon: 'write',
pinned: true,
},
],
},
};
```
## Toggle UI regions and features
Disable major UI regions and features if you need more customization over the options available in the header and want to implement your own instead. Disabling history can be useful when the concept of threads and history doesn't make sense for your use case—e.g., in a support chatbot.
```jsx
const options: Partial = {
history: { enabled: false },
header: { enabled: false },
};
```
## Override the locale
Override the default locale if you have an app-wide language setting. By default, the locale is set to the browser's locale.
```jsx
const options: Partial = {
locale: 'de-DE',
};
```
---
# Tool search
import {
hostedToolSearchExample,
hostedToolSearchResponse,
clientToolSearchExample,
clientToolSearchFirstResponse,
clientToolSearchFollowUp,
clientToolSearchLoadedFunctionCall,
} from "./tool-search-examples";
Tool search allows the model to dynamically search for and load tools into the model's context as needed. This allows you to avoid loading all tool definitions into the model's context up front and **may help reduce overall token usage and cost**. For optimal cost and latency, tool search is designed to **preserve the model’s cache**. When new tools are discovered by the model, they are injected at the end of the context window.
Only `gpt-5.4` and later models support `tool_search`.
To activate tool search, you must do two things:
1. Add `tool_search` as a tool in your `tools` array.
2. If you are using [functions](https://developers.openai.com/api/docs/guides/function-calling#defining-functions), mark the ones you want to defer with `defer_loading: true`. If you are using [MCP servers](https://developers.openai.com/api/docs/guides/tools-connectors-mcp), set `defer_loading: true` on the MCP server tool definition.
### Use namespaces where possible
You can use tool search with deferred [functions](https://developers.openai.com/api/docs/guides/function-calling#defining-functions), [namespaces](https://developers.openai.com/api/docs/guides/function-calling#defining-namespaces), or [MCP servers](https://developers.openai.com/api/docs/guides/tools-connectors-mcp), but we recommend using namespaces or MCP servers when possible. Our models have primarily been trained to search those surfaces, and token savings are usually more material there.
For namespaces, `defer_loading` applies to the functions inside the namespace, not to the namespace object itself.
At the start of a request, the model still sees the name and description of whatever is searchable. For a namespace or MCP server, that means the model sees only the namespace or server name and description at the beginning, without showing details of the individual functions contained within it until the tool search tool loads them. For an individual deferred function, the model still sees the function name and description, so in practice tool search is mostly deferring the parameter schema.
For maximum token savings, we recommend grouping deferred functions into namespaces or MCP servers with clear, high-level descriptions that give the model a strong overview of what is contained within them, so it can effectively search and load only the relevant functions. As a best practice, aim to keep each namespace to fewer than 10 functions for better token efficiency and model performance.
Namespaces can have a mix of tools that are deferred and not deferred. Tools without `defer_loading: true` are callable immediately, while deferred tools in the same namespace are loaded through tool search.
### Tool search types
There are two ways to use tool search:
- **Hosted tool search:** OpenAI searches across the deferred tools you declared in the request and returns the loaded subset in the same response.
- **Client-executed tool search:** The model emits a `tool_search_call`, your application performs the lookup, and you return a matching `tool_search_output`.
Start with hosted tool search if the candidate tools are already known when
you create the request. Use client-executed tool search when tool discovery
depends on project state, tenant state, or another system your application
controls.
## Hosted tool search
Hosted tool search is the simplest path when you already know the full inventory of [functions](https://developers.openai.com/api/docs/guides/function-calling#defining-functions), [namespaces](https://developers.openai.com/api/docs/guides/function-calling#defining-namespaces), or [MCP servers](https://developers.openai.com/api/docs/guides/tools-connectors-mcp) you want the model to search. You declare them up front, add `{"type": "tool_search"}`, and let the API decide what to load.
If the model decides it needs a deferred tool, the response includes two additional output items before the eventual function call:
- `tool_search_call`, which records the hosted search step.
- `tool_search_output`, which contains the loaded subset that becomes callable.
In hosted mode, `execution` is set to `server` and `call_id` is set to `null`.
For more complex tasks, the model can also load multiple namespaces or MCP servers in the same `tool_search_call`. For example, if it needs functions from different namespaces to complete one task, it may choose to search and load those surfaces together before making the subsequent function calls.
## Client-executed tool search
Client-executed tool search gives your application full control over how tool discovery works. This is useful when the available tools depend on information that is not practical to declare in the initial `tools` list.
Configure the `tool_search` tool with `execution: "client"` and a schema for the search arguments your application expects:
On the first turn, the model emits a `tool_search_call` and stops there:
Your application then performs the search and returns a `tool_search_output` with the tools it wants to load:
On the next turn, the loaded tool is callable like a normal function:
In client mode, `execution` is set to `client` and `call_id` is defined. Echo the same `call_id` from the `tool_search_call` in your `tool_search_output`.
## Advanced usage
### Keep namespace descriptions clear
Make namespace descriptions clear and descriptive of the use case, because the model relies on this description to decide when to load a subset of functions in that namespace. Avoid overly long descriptions. Instead, put richer detail in the deferred function descriptions that are loaded only when needed.
### Understand what gets loaded
`tool_search_output.tools` contains the list of tools that were dynamically loaded by the model. The model will be able to call any of these tools in future turns, so in client mode you do not need to load the same tool again across turns. Tools that were not listed as part of this array will not be available to the model. If you want to disable a loaded tool, you can remove it from the `tool_search_output` item where you define the loaded tool set, but note that changing the loaded tool set will break the model's cache from that point forward.
### Advanced injection patterns
Most integrations declare tools in the request's `tools` parameter. Client-executed tool search also supports more advanced patterns where your application returns tools that were not present in the original request. Treat this as an advanced workflow: validate the returned schemas carefully and only expose trusted tool definitions.
### Tool search and caching
All tools are loaded at the end of the model's context window. This holds true for both hosted tool search and client-executed tool search. This allows the model's cache to be preserved from one request to another, lowering overall costs and boosting speed.
## Related guides
- Use [function calling](https://developers.openai.com/api/docs/guides/function-calling) to define callable functions and custom tools.
- Use [Using tools](https://developers.openai.com/api/docs/guides/tools) for the broader tool landscape across Responses.
---
# Trace grading
Trace grading is the process of assigning structured scores or labels to an agent's trace—the end-to-end log of decisions, tool calls, and reasoning steps—to assess correctness, quality, or adherence to expectations. These annotations help identify where the agent did well or made mistakes, enabling targeted improvements in orchestration or behavior.
Trace evals use those graded traces to systematically evaluate agent performance across many examples, helping to benchmark changes, identify regressions, or validate improvements. Unlike black-box evaluations, trace evals provide more data to better understand why an agent succeeds or fails.
Use both features to track, analyze, and optimize the performance of groups of agents.
## Get started with traces
1. In the dashboard, navigate to Logs > [Traces](https://platform.openai.com/logs?api=traces).
1. Select a worfklow. You'll see logs from any workflows you created in [Agent Builder](https://developers.openai.com/api/docs/guides/agent-builder).
1. Select a trace to inspect your workflow.
1. Create a grader, and run it to grade your agents' performance against grader criteria.
Trace grading is a valuable tool for error identification at scale, which is critical for building resilience into your AI applications. Learn more about our recommended process in our [cookbook](https://developers.openai.com/cookbook/examples/evaluation/building_resilient_prompts_using_an_evaluation_flywheel).
## Evaluate traces with runs
1. Select **Grade all**. This takes you to the evaluation dashboard.
1. In the evaluation dashboard, add and edit test criteria.
1. Add a run to evaluate outputs. You can configure run options like model, date range, and tool calls to get more specificity in your eval.
Learn more about how you can use evals [here](https://developers.openai.com/api/docs/guides/evals).
---
# Under 18 API Guidance
Young people have unique needs online and offline, so developers should implement additional safeguards when using our API to serve minors (under 18 years old). These are in addition to requirements under our [usage policies](https://openai.com/policies/usage-policies/) and [terms and conditions](https://openai.com/policies/services-agreement/).
**Regulatory Standards**
Organizations serving minors must comply with all applicable child protection, safety, and privacy laws, including the Children's Online Privacy Protection Act (COPPA). You should not use OpenAI services to process any personal data of children under 13 or the applicable age of digital consent without first implementing zero data retention in our API. You are solely responsible for ensuring that you and your users use OpenAI services in compliance with applicable law.
**Safety Standards**
Organizations serving minors must take reasonable steps to ensure that the content they are serving to minors via the API is safe and age appropriate, in line with our usage policies to “Keep minors safe.” This may include, but is not limited to:
1. Providing age-appropriate disclosures to minors about AI tools and how to use them responsibly.
2. Implementing age-appropriate content filters to address potentially sensitive content.
3. Implementing reasonable monitoring and reporting mechanisms, including escalation paths for high-risk interactions.
4. Where required or otherwise appropriate for your use case, using age assurance systems to ensure only intended users can access the product.
**Best Practices**
Organizations serving minors should follow these best practices when interacting with our API:
- Exercise heightened care when handling minors’ data and interactions and take appropriate action when risks to young users are identified.
- Leverage available safety tools and follow technical safety measures that OpenAI may provide that are designed to tailor product experiences for specific user groups, including minors.
- Use OpenAI’s most current flagship models, which incorporate the latest safety protections, particularly when building experiences for minors.
OpenAI reserves the right to audit organizations for compliance with this policy. Customers who fail to demonstrate compliance may receive warnings and, in cases of repeated or serious noncompliance, may be subject to suspension or termination of API access.
---
# Upgrading to GPT-5.4
# Upgrading to GPT-5.4
Use this guide when the user explicitly asks to upgrade an existing integration to GPT-5.4. Pair it with current OpenAI docs lookups. The default target string is `gpt-5.4`.
## Upgrade posture
Upgrade with the narrowest safe change set:
- replace the model string first
- update only the prompts that are directly tied to that model usage
- prefer prompt-only upgrades when possible
- if the upgrade would require API-surface changes, parameter rewrites, tool rewiring, or broader code edits, mark it as blocked instead of stretching the scope
## Upgrade workflow
1. Inventory current model usage.
- Search for model strings, client calls, and prompt-bearing files.
- Include inline prompts, prompt templates, YAML or JSON configs, Markdown docs, and saved prompts when they are clearly tied to a model usage site.
2. Pair each model usage with its prompt surface.
- Prefer the closest prompt surface first: inline system or developer text, then adjacent prompt files, then shared templates.
- If you cannot confidently tie a prompt to the model usage, say so instead of guessing.
3. Classify the source model family.
- Common buckets: `gpt-4o` or `gpt-4.1`, `o1` or `o3` or `o4-mini`, early `gpt-5`, later `gpt-5.x`, or mixed and unclear.
4. Decide the upgrade class.
- `model string only`
- `model string + light prompt rewrite`
- `blocked without code changes`
5. Run the no-code compatibility gate.
- Check whether the current integration can accept `gpt-5.4` without API-surface changes or implementation changes.
- For long-running Responses or tool-heavy agents, check whether `phase` is already preserved or round-tripped when the host replays assistant items or uses preambles.
- If compatibility depends on code changes, return `blocked`.
- If compatibility is unclear, return `unknown` rather than improvising.
6. Recommend the upgrade.
- Default replacement string: `gpt-5.4`
- Keep the intervention small and behavior-preserving.
7. Deliver a structured recommendation.
- `Current model usage`
- `Recommended model-string updates`
- `Starting reasoning recommendation`
- `Prompt updates`
- `Phase assessment` when the flow is long-running, replayed, or tool-heavy
- `No-code compatibility check`
- `Validation plan`
- `Launch-day refresh items`
Output rule:
- Always emit a starting `reasoning_effort_recommendation` for each usage site.
- If the repo exposes the current reasoning setting, preserve it first unless the source guide says otherwise.
- If the repo does not expose the current setting, use the source-family starting mapping instead of returning `null`.
## Upgrade outcomes
### `model string only`
Choose this when:
- the existing prompts are already short, explicit, and task-bounded
- the workflow is not strongly research-heavy, tool-heavy, multi-agent, batch or completeness-sensitive, or long-horizon
- there are no obvious compatibility blockers
Default action:
- replace the model string with `gpt-5.4`
- keep prompts unchanged
- validate behavior with existing evals or spot checks
### `model string + light prompt rewrite`
Choose this when:
- the old prompt was compensating for weaker instruction following
- the workflow needs more persistence than the default tool-use behavior will likely provide
- the task needs stronger completeness, citation discipline, or verification
- the upgraded model becomes too verbose or under-complete unless instructed otherwise
- the workflow is research-heavy and needs stronger handling of sparse or empty retrieval results
- the workflow is coding-oriented, tool-heavy, or multi-agent, but the existing API surface and tool definitions can remain unchanged
Default action:
- replace the model string with `gpt-5.4`
- add one or two targeted prompt blocks
- read [Prompt guidance for GPT-5.4](https://developers.openai.com/api/docs/guides/prompt-guidance) to choose the smallest prompt changes that recover the old behavior
- avoid broad prompt cleanup unrelated to the upgrade
- for research workflows, default to `research_mode` + `citation_rules` + `empty_result_handling`; add `tool_persistence_rules` when the host already uses retrieval tools
- for dependency-aware or tool-heavy workflows, default to `tool_persistence_rules` + `dependency_checks` + `verification_loop`; add `parallel_tool_calling` only when retrieval steps are truly independent
- for coding or terminal workflows, default to `terminal_tool_hygiene` + `verification_loop`
- for multi-agent support or triage workflows, default to at least one of `tool_persistence_rules`, `completeness_contract`, or `verification_loop`
- for long-running Responses agents with preambles or multiple assistant messages, explicitly review whether `phase` is already handled; if adding or preserving `phase` would require code edits, mark the path as `blocked`
- do not classify a coding or tool-using Responses workflow as `blocked` just because the visible snippet is minimal; prefer `model string + light prompt rewrite` unless the repo clearly shows that a safe GPT-5.4 path would require host-side code changes
### `blocked`
Choose this when:
- the upgrade appears to require API-surface changes
- the upgrade appears to require parameter rewrites or reasoning-setting changes that are not exposed outside implementation code
- the upgrade would require changing tool definitions, tool handler wiring, or schema contracts
- you cannot confidently identify the prompt surface tied to the model usage
Default action:
- do not improvise a broader upgrade
- report the blocker and explain that the fix is out of scope for this guide
## No-code compatibility checklist
Before recommending a no-code upgrade, check:
1. Can the current host accept the `gpt-5.4` model string without changing client code or API surface?
2. Are the related prompts identifiable and editable?
3. Does the host depend on behavior that likely needs API-surface changes, parameter rewrites, or tool rewiring?
4. Would the likely fix be prompt-only, or would it need implementation changes?
5. Is the prompt surface close enough to the model usage that you can make a targeted change instead of a broad cleanup?
6. For long-running Responses or tool-heavy agents, is `phase` already preserved if the host relies on preambles, replayed assistant items, or multiple assistant messages?
If item 1 is no, items 3 through 4 point to implementation work, or item 6 is no and the fix needs code changes, return `blocked`.
If item 2 is no, return `unknown` unless the user can point to the prompt location.
Important:
- Existing use of tools, agents, or multiple usage sites is not by itself a blocker.
- If the current host can keep the same API surface and the same tool definitions, prefer `model string + light prompt rewrite` over `blocked`.
- Reserve `blocked` for cases that truly require implementation changes, not cases that only need stronger prompt steering.
## Scope boundaries
This guide may:
- update or recommend updated model strings
- update or recommend updated prompts
- inspect code and prompt files to understand where those changes belong
- inspect whether existing Responses flows already preserve `phase`
- flag compatibility blockers
This guide may not:
- move Chat Completions code to Responses
- move Responses code to another API surface
- rewrite parameter shapes
- change tool definitions or tool-call handling
- change structured-output wiring
- add or retrofit `phase` handling in implementation code
- edit business logic, orchestration logic, or SDK usage beyond a literal model-string replacement
If a safe GPT-5.4 upgrade requires any of those changes, mark the path as blocked and out of scope.
## Validation plan
- Validate each upgraded usage site with existing evals or realistic spot checks.
- Check whether the upgraded model still matches expected latency, output shape, and quality.
- If prompt edits were added, confirm each block is doing real work instead of adding noise.
- If the workflow has downstream impact, add a lightweight verification pass before finalization.
## Launch-day refresh items
When final GPT-5.4 guidance changes:
1. Replace release-candidate assumptions with final GPT-5.4 guidance where appropriate.
2. Re-check whether the default target string should stay `gpt-5.4` for all source families.
3. Re-check any prompt-block recommendations whose semantics may have changed.
4. Re-check research, citation, and compatibility guidance against the final model behavior.
5. Re-run the same upgrade scenarios and confirm the blocked-versus-viable boundaries still hold.
---
# Upgrading to GPT-5.5
# Upgrading to GPT-5.5
Use this guide when the user explicitly asks to upgrade an existing integration to GPT-5.5. Pair it with current OpenAI docs lookups. The default target string is `gpt-5.5`.
## Upgrade posture
Upgrade with the narrowest safe change set:
- replace the model string first
- update only the prompts that are directly tied to that model usage
- do not automatically upgrade older or ambiguous model usages that may be intentionally pinned, such as historical docs, examples, tests, eval baselines, comparison code, or low-cost fallback/routing paths. Unless the user explicitly asks to upgrade all model usage, leave those sites unchanged and list them as confirmation-needed
- prefer prompt-only upgrades when possible
- if the upgrade would require API-surface changes, parameter rewrites, tool rewiring, provider migration, or broader code edits, mark it as blocked instead of stretching the scope
## Upgrade workflow
1. Inventory current model usage.
- Search for model strings, client calls, and prompt-bearing files.
- Include inline prompts, prompt templates, YAML or JSON configs, Markdown docs, and saved prompts when they are clearly tied to a model usage site.
2. Pair each model usage with its prompt surface.
- Prefer the closest prompt surface first: inline system or developer text, then adjacent prompt files, then shared templates.
- If you cannot confidently tie a prompt to the model usage, say so instead of guessing.
3. Classify the source model family.
- Common buckets: GPT-5.4, GPT-5.3-Codex or GPT-5.2-Codex, earlier GPT-5.x, GPT-4o or GPT-4.1, reasoning models such as o1 or o3 or o4-mini, third-party model, or mixed and unclear.
4. Decide the upgrade class.
- `model string only`
- `model string + light prompt rewrite`
- `blocked without code changes`
5. Run the compatibility gate.
- Check whether the current integration can accept `gpt-5.5` without API-surface changes or implementation changes.
- Check whether structured outputs, tool schemas, function names, and downstream parsers can remain unchanged.
- For long-running Responses or tool-heavy agents, check whether `phase` is already preserved or round-tripped when the host replays assistant items or uses preambles.
- If compatibility depends on code changes, return `blocked`.
- If compatibility is unclear, return `unknown` rather than improvising.
6. Apply the upgrade when it is in scope.
- Default replacement string: `gpt-5.5`.
- Keep the intervention small and behavior-preserving.
- Start from the current reasoning effort when it is visible unless there is a measured reason to change it.
- For in-scope changes, update the model string and directly related prompts.
- For blocked or unknown changes, do not edit; report the blocker or uncertainty.
7. Summarize the result.
- `Current model usage`
- `Model-string updates`
- `Reasoning-effort handling`
- `Prompt updates`
- `Structured output and formatting assessment`
- `Tool-use assessment` when the flow uses tools, retrieval, or terminal actions
- `Phase assessment` when the flow is long-running, replayed, or tool-heavy
- `Compatibility check`
- `Validation performed`
Output rule:
- For each usage site, state the starting reasoning-effort recommendation.
- If the repo exposes the current reasoning setting, recommend preserving it first unless current OpenAI docs say otherwise.
- If the repo does not expose the current setting, recommend not adding one unless current OpenAI docs require it.
## Upgrade outcomes
### `model string only`
Choose this when:
- the source model is GPT-5.4
- the existing prompts are already short, explicit, and task-bounded
- the workflow does not rely on strict output formats, tool-call behavior, batch completeness, or long-horizon execution that should be validated after the upgrade
- there are no obvious compatibility blockers
Default action:
- replace the model string with `gpt-5.5`
- preserve the current reasoning effort
- keep prompts unchanged
- validate behavior with existing tests, realistic spot checks, or an existing eval suite when one is already available
### `model string + light prompt rewrite`
Choose this when:
- the task needs stronger completeness, citation discipline, verification, or dependency handling
- the upgraded model becomes too verbose, too dense, or hard to scan unless formatting is constrained
- the workflow has strict output shape requirements and lacks an explicit format contract, schema, or parser validation
- the workflow is research-heavy and needs stronger handling of sparse or empty retrieval results
- the workflow is coding-oriented, terminal-based, tool-heavy, or multi-agent, but the existing API surface and tool definitions can remain unchanged
Default action:
- replace the model string with `gpt-5.5`
- preserve the current reasoning effort for the first pass
- make only the smallest prompt edits needed for the observed workflow risk
- read the [GPT-5.5 prompting guide](https://developers.openai.com/api/docs/guides/prompt-guidance?model=gpt-5.5) to choose the smallest prompt changes that recover or improve behavior
- avoid broad prompt cleanup unrelated to the upgrade
- for research workflows, add citation rules, retrieval budgets, missing-evidence behavior, and validation guidance from the prompting guide
- for dependency-aware or tool-heavy workflows, add prerequisite checks, missing-context handling, explicit tool budgets, stop conditions, and validation guidance
- for coding or terminal workflows, add repo-specific constraints, acceptance criteria, and concrete validation commands
- for multi-agent support or triage workflows, add task ownership, handoff, completeness, and stopping criteria
- for long-running Responses agents with preambles or multiple assistant messages, explicitly review whether `phase` is already handled; if adding or preserving `phase` would require code edits, mark the path as `blocked`
- do not classify a coding or tool-using Responses workflow as `blocked` just because the visible snippet is minimal; prefer `model string + light prompt rewrite` unless the repo clearly shows that a safe GPT-5.5 path would require host-side code changes
### `blocked`
Choose this when:
- the upgrade appears to require API-surface changes
- the upgrade appears to require parameter rewrites or reasoning-setting changes that are not exposed outside implementation code
- the upgrade would require changing tool definitions, tool handler wiring, or schema contracts
- the user is asking for a tooling, IDE, plugin, shell, or environment migration rather than a model and prompt migration
- the integration depends on provider-specific APIs that do not map to the current OpenAI API surface without implementation work
- you cannot confidently identify the prompt surface tied to the model usage
Default action:
- do not improvise a broader upgrade
- report the blocker and explain that the fix is out of scope for this guide
- if useful, describe the smallest follow-up implementation task that would unblock the migration
## Compatibility checklist
Before applying or recommending a model-and-prompt-only upgrade, check:
1. Can the current host accept the `gpt-5.5` model string without changing client code or API surface?
2. Are the related prompts identifiable and editable?
3. Does the host depend on behavior that likely needs API-surface changes, parameter rewrites, provider migration, or tool rewiring?
4. Would the likely fix be prompt-only, or would it need implementation changes?
5. Is the prompt surface close enough to the model usage that you can make a targeted change instead of a broad cleanup?
6. Do strict structured outputs, schemas, or downstream parsers still have an explicit contract?
7. For long-running Responses or tool-heavy agents, is `phase` already preserved if the host relies on preambles, replayed assistant items, or multiple assistant messages?
8. Are latency, token, or price assumptions validated by tests, realistic spot checks, or an existing eval suite rather than inferred from general model positioning?
If item 1 is no, items 3 through 4 point to implementation work, or item 7 is no and the fix needs code changes, return `blocked`.
If item 2 is no, return `unknown` unless the user can point to the prompt location.
Important:
- Existing use of tools, agents, or multiple usage sites is not by itself a blocker.
- If the current host can keep the same API surface and the same tool definitions, prefer `model string + light prompt rewrite` over `blocked`.
- Reserve `blocked` for cases that truly require implementation changes, not cases that only need stronger prompt steering.
- Do not claim token savings without task-level validation.
## Scope boundaries
This guide may:
- update or recommend updated model strings
- update or recommend updated prompts
- inspect code and prompt files to understand where those changes belong
- inspect whether existing Responses flows already preserve `phase`
- flag compatibility blockers
- propose validation with existing tests, realistic spot checks, or existing eval suites
This guide may not:
- move Chat Completions code to Responses
- move Responses code to another API surface
- migrate SDKs, APIs, IDE configuration, shell hooks, plugins, or provider-specific tooling
- rewrite parameter shapes
- change tool definitions or tool-call handling
- change structured-output wiring
- add or retrofit `phase` handling in implementation code
- edit business logic, orchestration logic, SDK usage, IDE configuration, shell hooks, or plugin integration behavior except for model-string replacements and directly related prompt edits
If a safe GPT-5.5 upgrade requires any of those changes, mark the path as blocked and out of scope.
## Validation plan
- Validate each upgraded usage site with existing tests, realistic spot checks, or an existing eval suite when one is already available.
- Compare against the current GPT-5.4 baseline when available.
- Check task success, retry count, tool-call count, total tokens, latency, output shape, and user-visible quality.
- For specialized workflows, validate the contract that matters most instead of judging only general output quality.
- If prompt edits were added, confirm each block is doing real work instead of adding noise.
- If the workflow has downstream impact, add a lightweight verification pass before finalization.
---
---
latestModelInfo:
model: gpt-5.5
migrationGuide: /api/docs/guides/upgrading-to-gpt-5p5.md
promptingGuide: /api/docs/guides/prompt-guidance.md
---
# Using GPT-5.5
## Introduction
GPT-5.5 raises the baseline for complex production workflows. It’s a strong fit for coding use cases, tool-heavy agents, grounded assistants, long-context retrieval, product-spec-to-plan workflows, and customer-facing workflows where execution quality and response polish are critical.
To get the most out of GPT-5.5, treat it as a new model family to tune for, not a drop-in replacement for `gpt-5.2` or `gpt-5.4`. Begin migration with a fresh baseline instead of carrying over every instruction from an older prompt stack. Start with the smallest prompt that preserves the product contract, then tune reasoning effort, verbosity, tool descriptions, and output format against representative examples.
GPT-5.5 supports all API features that were already available with GPT-5.4, including [prompt caching](https://developers.openai.com/api/docs/guides/prompt-caching), [hosted tools](https://developers.openai.com/api/docs/guides/tools#available-tools), [tool search](https://developers.openai.com/api/docs/guides/tools-tool-search), [compaction](https://developers.openai.com/api/docs/guides/compaction), and `phase` handling for manually replayed assistant items.
See the [GPT-5.5 Prompting Guide](https://developers.openai.com/api/docs/guides/prompt-guidance?model=gpt-5.5) for examples of successful prompting patterns.
## What's new
- **More efficient reasoning:** GPT-5.5 reaches strong results with fewer reasoning tokens than prior models, even at the same reasoning effort. This is especially useful in complex, tool-heavy, or multi-step workflows where token savings compound.
- **Stronger task execution with outcome-first prompts:** GPT-5.5 is better at working from a clear goal, preserving constraints, and turning product intent into concrete next steps. Describe the expected outcome, success criteria, allowed side effects, evidence rules, and output shape. Avoid step-by-step process guidance unless the exact path matters.
- **Stronger and more precise tool use:** GPT-5.5 is especially useful on large tool surfaces, multi-step service workflows, and long-running agent tasks. It tends to be more precise in tool selection and argument use.
- **Tone is often more polished, but can be more direct:** GPT-5.5 often produces warmer, more readable answers with less prompt scaffolding.
## Behavioral changes
1. **Reasoning effort now defaults to `medium`:** GPT-5.5 defaults to `medium` reasoning effort. Treat `medium` as the recommended balanced starting point for quality, reliability, latency, and cost. For latency-sensitive workflows, evaluate `low` before `none` when tool use, planning, search, or multi-step decision making still matters. Reserve `none` for latency-critical tasks that don't need reasoning or multi-chained tool calls, such as lightweight voice turns, fast information retrieval, and classification. Increase to `high` or `xhigh` only when evals show a measurable quality gain that justifies the extra latency and cost. See the [Reasoning models documentation](https://developers.openai.com/api/docs/guides/reasoning) for more details on recommended settings.
Higher reasoning effort isn't automatically better. If the task has conflicting instructions, weak stopping criteria, or open-ended tool access, higher effort can lead to overthinking, unnecessary searching, or output quality regressions. Increase effort only when evals show a measurable quality gain.
2. **Image inputs preserve more visual detail by default:** GPT-5.5 updates the default handling for image inputs to preserve more visual detail and improve computer use performance. When `image_detail` is unset or set to `auto`, the model now uses `original` behavior, preserving images without resizing up to 10,240,000 pixels or a 6,000-pixel dimension limit. For `high`, specify the value directly; it preserves images without resizing up to 2,500,000 pixels or a 2,048-pixel dimension limit. `low` now focuses on context efficiency and resizes images above a 512-pixel dimension limit more aggressively than previous models. See the [Images and vision documentation](https://developers.openai.com/api/docs/guides/images-vision).
3. **Improved instruction following:** GPT-5.5 interprets prompts in a literal and thorough manner, enabling specific, descriptive instructions when the product requires them. Define success criteria and stopping rules, especially for long-running, tool-heavy, or evidence-gathering workflows. See [Write outcome-first prompts](https://developers.openai.com/api/docs/guides/prompt-guidance?model=gpt-5.5#outcome-first-prompts-and-stopping-conditions) and [Keep the right specificity](https://developers.openai.com/api/docs/guides/prompt-guidance?model=gpt-5.5#formatting).
4. **Default style is more concise and direct:** GPT-5.5 tends to be efficient, direct, and task-oriented by default. This is useful for many production workflows, but customer-facing or conversational experiences may need explicit personality, warmth, rationale, and formatting guidance. Use `text.verbosity` intentionally: `medium` is the default, and `low` is often a better starting point for concise responses. See the [GPT-5.5 prompting guide](https://developers.openai.com/api/docs/guides/prompt-guidance?model=gpt-5.5).
5. **Coding workflows need stronger orchestration:** GPT-5.5 is better suited to complex coding tasks that require planning, tool use, codebase navigation, verification, and multi-step execution. For coding agents, be explicit about reuse, subagent delegation, test expectations, acceptance criteria, and when to continue versus ask for help.
## Migration quickstart
### Automated migration with Codex
Codex can apply the recommended changes in this guide with the [OpenAI Docs Skill](https://github.com/openai/skills/tree/main/skills/.curated/openai-docs).
```text
$openai-docs migrate this project to gpt-5.5
```
To use this skill in other coding agents, download it from the [OpenAI skills repository](https://github.com/openai/skills/tree/main/skills/.curated/openai-docs).
### API and model parameters
- Update the model slug to `gpt-5.5`.
- Use the Responses API for any reasoning, tool-calling, or multi-turn use case.
- Tune `reasoning.effort`. Use `low` for efficient reasoning, `medium` for a balanced point on the latency/performance curve, `high` for complex agentic tasks that require hard reasoning and where latency matters less, and `xhigh` for the hardest asynchronous agentic tasks or evals that test the bounds of model intelligence. See the [Reasoning models documentation](https://developers.openai.com/api/docs/guides/reasoning).
- To configure for more concise responses, set `text.verbosity` to `low`. On GPT-5.5, this will result in proportionally more concise responses than `low` verbosity with GPT-5.4.
- For tool-heavy or long-running workflows, verify that your application handles `phase`, preambles, and assistant-item replay correctly.
- Benchmark against other models on accuracy, token consumption, and end-to-end latency.
### Prompting
- State the expected outcome and success criteria.
- Reduce or remove detailed step-by-step process guidance. Let GPT-5.5 choose the path unless the product requires that path.
- Remove output schema definitions from the prompt where possible. Use [Structured Outputs](https://developers.openai.com/api/docs/guides/structured-outputs) instead.
- Optimize your prompt for caching: [static parts first, dynamic parts last](https://developers.openai.com/api/docs/guides/prompt-caching).
- Drop the current date. The model is already aware of the current UTC date.
- Review and optimize your prompts based on the guidance in [Prompting GPT-5.5](https://developers.openai.com/api/docs/guides/prompt-guidance?model=gpt-5.5).
## Using reasoning models
This guidance applies to GPT-5 series models and is worth revisiting whenever teams move workloads onto reasoning models. GPT-5.5 carries forward many capabilities that first appeared in earlier models, but they're still worth reviewing if you are moving from an earlier GPT-5 model, GPT-4.1, or a reasoning model such as o3.
Teams can overlook these features because they sit partly in API configuration and orchestration rather than in the prompt itself. Used together, the Responses API, reasoning controls, verbosity, structured outputs, prompt caching, tool design, hosted tools, and state management help reasoning models deliver their best intelligence, reliability, latency, and cost profile.
- **Responses API:** GPT-5.5 works best in the [Responses API](https://developers.openai.com/api/docs/guides/migrate-to-responses). Use `previous_response_id` for multi-turn state handling. For stateless or Zero Data Retention flows, pass back the relevant returned output items each turn. See [Passing context from the previous response](https://developers.openai.com/api/docs/guides/conversation-state#passing-context-from-the-previous-response) for details.
- **Reasoning effort:** Use `reasoning.effort` to choose between `low`, `medium`, `high`, or `xhigh`. The default is `medium`, but many workloads will perform well with `low`. Reserve `none` for use cases where low latency is more important than intelligence. See [Reasoning Models](https://developers.openai.com/api/docs/guides/reasoning) for detailed recommendations.
- **Verbosity:** Use `text.verbosity` to control output length. Treat final answer length as separate from reasoning quality; specify word budgets, section counts, table widths, or JSON-only output where needed.
- **Structured Outputs:** Avoid describing the expected output schema in the prompt. Use [Structured Outputs](https://developers.openai.com/api/docs/guides/structured-outputs) for automatic validation and increased accuracy.
- **Prompt caching:** [Prompt caching](https://developers.openai.com/api/docs/guides/prompt-caching) works automatically for eligible long prompts and can reduce latency and input-token cost. To maximize cache hits, keep stable content at the beginning of the request. Put dynamic user-specific context near the end. For repeated traffic with common prefixes, use `prompt_cache_key` consistently and track `usage.prompt_tokens_details.cached_tokens`.
- **Tool calling:** GPT-5.5 supports the same tool-calling patterns as GPT-5.4, including function tools and tool-heavy agent workflows. Put most tool-specific guidance in the tool descriptions themselves: what the tool does, when to use it, required inputs, side effects, retry safety, and common error modes. Add tool-specific context to system instructions only when it applies across tools or materially changes the agent's operating policy.
- **Hosted tools and tool search:** Prefer [OpenAI-hosted tools](https://developers.openai.com/api/docs/guides/tools) where they fit the workflow, such as web search, file search, code interpreter, image generation, and computer use. Hosted tools reduce custom orchestration burden and keep common tool patterns aligned with the Responses API and Agents SDK. Use custom function tools when you need to call your own systems, enforce domain-specific side effects, or expose internal business workflows. For large tool catalogs, consider using [tool search](https://developers.openai.com/api/docs/guides/tools-tool-search) to defer tool definitions and load only the relevant subset.
- **Tool preambles:** Preambles can improve chat UX because the user sees an initial, useful status update before the model generates the final response. They also make tool use easier to follow: the model can state what it's about to check or do, then continue from that same assistant state after tool results arrive.
- **`phase` handling:** If your application manually manages Responses state by passing output items back each turn instead of using `previous_response_id`, preserve the `phase` parameter on returned assistant output items and pass it back unchanged. This is especially important when using reasoning effort, preambles, or repeated tool calls. See [Phase parameter](https://developers.openai.com/api/docs/guides/reasoning#phase-parameter).
- **Compaction:** For long-running agents, use [conversation/state compaction](https://developers.openai.com/api/docs/guides/compaction) intentionally. Preserve completed actions, active assumptions, IDs, tool outcomes, unresolved blockers, and the next concrete goal.
- **Agents SDK:** For new agentic systems, use the latest [Agents SDK](https://developers.openai.com/api/docs/guides/agents) patterns for tool orchestration, tracing, handoffs, and state management rather than rebuilding orchestration from scratch.
- **Current date:** GPT-5.5 is aware of the current date in UTC. You don't need to add the current date to system instructions. Add explicit date or timezone context only when the application needs a business-specific timezone, policy-effective date, user-local date, or other non-UTC reference point.
---
# Using realtime models
`gpt-realtime-2` is our state-of-the-art reasoning voice model for low-latency speech-to-speech applications. It can think before it speaks, follow instructions more reliably, use a larger context window, and call tools with greater precision than earlier realtime models.
To take advantage of these gains, design prompts with more intent. Define the assistant's responsibilities, decision points, tool-calling behavior, and guardrails clearly: what it should do, when it should do it, and what it should avoid.
Start simple. Do not over-prompt upfront. Begin with a minimal prompt, run
evaluations, then add instructions only for behaviors that fail in testing.
## Choose a model
| Model |
Use when |
Prompting focus |
gpt-realtime-2
|
You need the strongest realtime reasoning, tool use, and instruction
following.
|
Tune reasoning effort, preambles, tool policies, exact entity capture,
and long-session state.
|
gpt-realtime-1.5
|
You need a fast, reliable non-reasoning speech-to-speech model. |
Follow the core realtime prompt structure and test for latency-sensitive
behavior.
|
## Realtime 2.0 Prompting Guide
Use gpt-realtime-2 when the voice agent needs stronger
reasoning, tool selection, exact entity handling, or long-session state.
Start with reasoning.effort: "low", test default preamble
behavior, and define clear confirmation boundaries before write actions.
## What changed in Realtime 2
Prompt Realtime 2 as a reasoning voice agent, not as a basic voice bot.
| Change | What it means for prompts |
| ------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Reasoning | Allow the model to reason internally for complex tasks before speaking or calling tools. Use preambles to avoid awkward silence or unnecessary filler. |
| Prompt precision matters more | Replace broad guidance like "be helpful" with clear trigger, action, and exception rules: when to act, what to do, and when not to do it. |
| Instruction conflicts are more costly | Remove overlapping `always`, `never`, `only`, and `must` rules unless they are truly required. Define priority when rules compete. |
| Tool behavior is more steerable | Specify when the assistant should act immediately, ask for missing information, confirm high-precision details, retry after failure, or escalate. |
| Preambles are first-class behavior | The model may speak brief updates before longer reasoning or tool-use flows. Steer when preambles should appear, how short they should be, and when to skip them. |
| Expanded context window | `gpt-realtime-2` expands the realtime context window from 32k to 128k tokens, making it better suited for long sessions and larger system prompts. |
Preambles aren't hidden chain-of-thought. They're short spoken updates such as
"I'll check that order now." Don't ask the model to reveal private reasoning.
## Recommended prompt structure
Use short, labeled sections. The model should be able to find the relevant instructions quickly.
```text
# Role and Objective
# Personality and Tone
# Language
# Reasoning
# Message Channels
# Preambles
# Verbosity
# Tools
# Unclear Audio
# Entity Capture
# Long Context Behavior
# Escalation
```
Not every use case needs every section. Add the sections that are relevant for your product.
## Set reasoning effort
`gpt-realtime-2` can trade latency for deeper reasoning. Use the lowest reasoning level that still gives the assistant enough intelligence for the workflow.
Start with `low` for most production voice agents. Tune up or down based on task complexity, latency tolerance, and failure cost.
| Effort | Use when | Example |
| --------- | --------------------------------------------------- | ----------------------------------------------------------------------- |
| `minimal` | Lowest latency matters most and the task is simple. | Smart-home commands, timers, simple calendar checks. |
| `low` | You need responsiveness plus basic reasoning. | Customer support, order lookup, simple policy questions. |
| `medium` | The assistant must reason through multi-step tasks. | Technical support, diagnostics, complex routing. |
| `high` | Deeper reasoning materially improves success. | High-precision workflows, escalation decisions, tasks with constraints. |
| `xhigh` | Maximum reasoning is worth added latency and cost. | Complex planning, critical triage, high-stakes tool orchestration. |
Beyond the API setting, steer the model on when and how much to reason.
```text
## Reasoning
- For direct answers, simple lookups, and short confirmations, respond quickly and do not reason.
- For multi-step tasks, tool decisions, troubleshooting, or escalation, reason before acting.
- Do not perform extended reasoning when the user's audio is unclear; ask for clarification instead.
```
## Use preambles intentionally
Preambles are short spoken updates that keep a voice agent feeling responsive while it reasons, looks something up, or calls a tool. Used well, they reassure the user that the assistant is working. Used poorly, they become filler and increase perceived latency.
`gpt-realtime-2` generates preambles by default. Start by testing the default behavior. If it does not match your product experience, tune it explicitly.
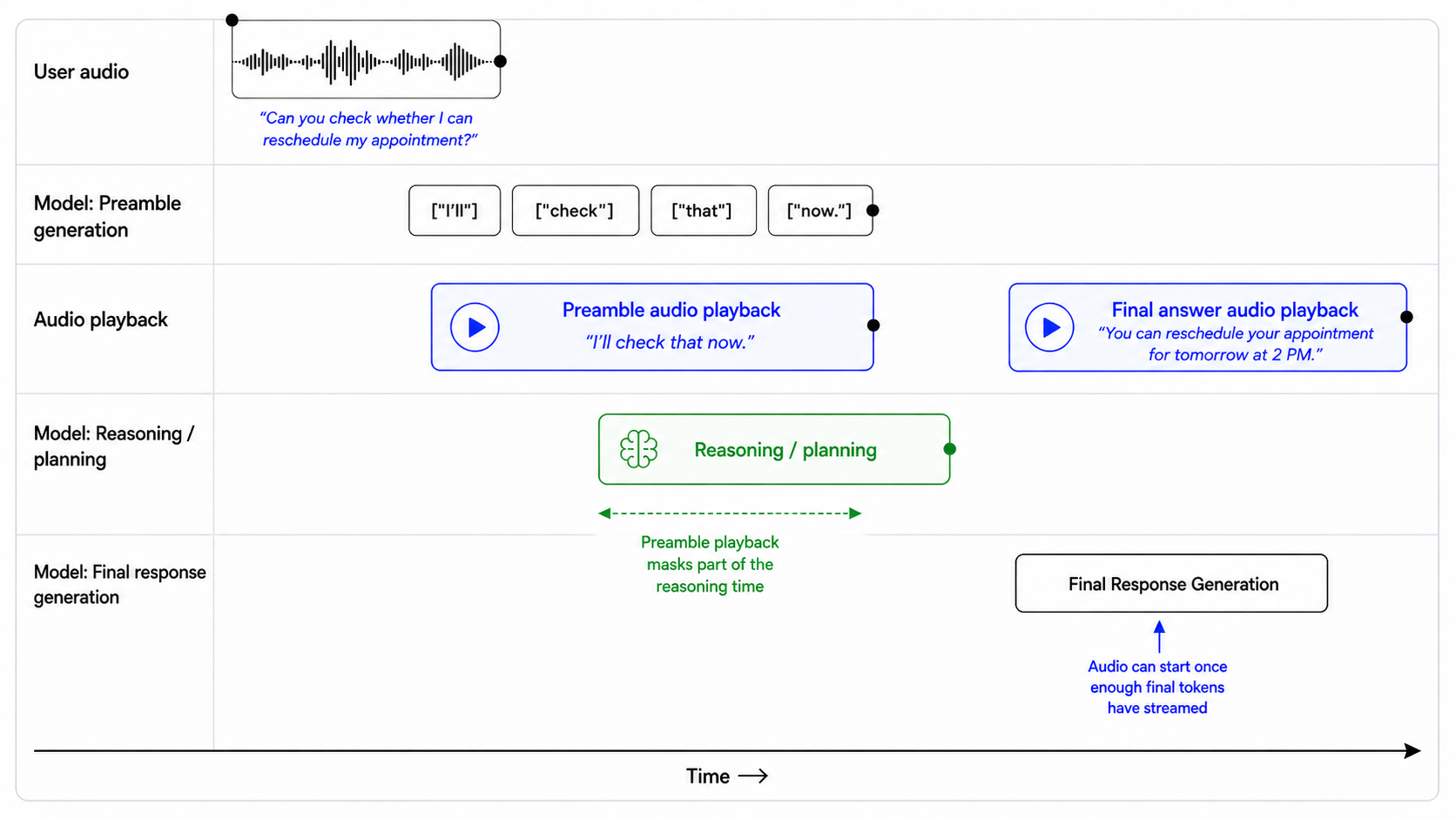
```text
## Preambles
Use short preambles only when they help the user understand that work is happening.
### When to use a preamble
Use a preamble when:
- you are about to call a tool that may take noticeable time;
- you need to reason through a multi-step request;
- you are checking records, availability, account state, or policy details;
- you are preparing an escalation or handoff;
- silence would make the assistant feel unresponsive.
When a preamble is needed, output it immediately before substantive reasoning or tool use.
### When to not use a preamble
Do not use a preamble when:
- the answer is direct and can be given immediately;
- the user is only confirming, correcting, or declining something;
- the audio is unclear and you need clarification;
- the latest audio is silence, background noise, hold music, TV audio, or side conversation;
- the tool call is lightweight and the user would not benefit from an update.
### Preamble style
When using a preamble:
- keep it natural, calm, and concise;
- vary the wording across turns;
- describe the action, not the internal reasoning;
- avoid filler.
Avoid phrases like:
- "Let me think..."
- "Hmm..."
- "One moment while I process that..."
- "I am now going to access the tool..."
### Preamble length
Use one short sentence.
Do not exceed two short sentences unless the user needs an explanation before a high-impact action.
### Prefer
- "I'll check that order now."
- "I'll look up your appointment details."
- "I'll verify that before we make any changes."
- "I'll check the policy and then give you the next step."
- "I'll pull that up so we can make sure it's the right account."
### Avoid
- "Let me think about that for a second."
- "Please wait while I process your request."
- "I'm going to use my tools now."
- "Interesting question. I will reason through this carefully."
```
## Control response length
`gpt-realtime-2` follows length guidance best when the prompt specifies how much detail to give for each task type. Instead of telling the model to "be concise," define what concise means in context: direct answers, tool results, troubleshooting, comparisons, and escalations may each need different response lengths.
```text
## Verbosity
- Direct answers: Use 1-2 short sentences.
- Clarifying questions: Ask one question at a time.
- Tool results: Summarize the result first, then give only the next useful action.
- Product or option comparisons: Include key differences, tradeoffs, and who each option fits.
- Troubleshooting: Give one step at a time unless the user asks for the full procedure.
- Escalations: Briefly explain why escalation is needed and what will happen next.
```
Example:
> User: Which plan should I choose?
> Assistant: If you want the lowest cost, choose Basic. If you need team permissions and shared billing, choose Pro. If compliance review or admin controls matter, choose Enterprise.
## Design tool behavior
`gpt-realtime-2` is stronger at tool calling, but tool behavior still depends on prompt and tool-spec design. If the prompt does not define when to act, ask, confirm, or recover, the assistant may call tools too early, ask unnecessary questions, or repeat failed calls.
### Set tool-call eagerness
High eagerness works well for read-only, low-risk actions. Low eagerness is better when tools modify data, trigger external effects, or depend on exact identifiers.
| Tool type | Default behavior |
| ----------------------------------- | --------------------------------------------------------- |
| Read-only, low-risk lookup | Call when intent and required fields are clear. |
| Read-only with exact identifier | Confirm the identifier before lookup. |
| User-visible communication | Draft or summarize before sending. |
| Account changes | Confirm before calling. |
| Purchases, cancellations, payments | Confirm amount, target, and consequence before calling. |
| Irreversible or high-impact actions | Confirm explicitly and offer escalation when appropriate. |
Use this balanced default when you have a mix of read and write actions. Tailor it based on your use case.
```text
## Tools
Use only the tools explicitly provided in the current tool list. Do not invent, assume, simulate, or rename tools.
For read-only tools:
- Call the tool when the user's intent is clear and all required fields are available.
- Do not ask for confirmation unless the lookup depends on a high-precision identifier or there is meaningful risk of using the wrong record.
- Ask a clarification question only if a required field is missing, ambiguous, or conflicting.
For write tools or external actions:
- Summarize the intended action before calling the tool.
- Include the key consequence, such as what will be changed, sent, canceled, ordered, or charged.
- Ask for confirmation.
- Do not call the tool until the user clearly confirms.
For exact identifiers:
- Treat order IDs, tracking numbers, account numbers, confirmation codes, phone numbers, and email addresses as high precision.
- Normalize only when the field type is clear.
- Confirm the final value before account-specific lookups, validation, or write actions.
After tool calls:
- Only say an action was completed after the tool call succeeds.
- If the tool fails, explain the failure briefly, avoid raw errors, and give the user a clear next step.
```
High-risk example:
> User: Charge my card for the remaining balance.
Bad:
> Assistant: I've charged your card.
Good:
> Assistant: To confirm, you want me to charge the card on file $248.16 for the remaining balance. Should I proceed?
### Recover from tool failures
Tool failures are part of the conversation. A good recovery should explain what happened and give the user a clear next step.
Do not treat every failure the same. Recovery behavior should depend on the tool type, failure mode, and user impact. Some failures should be handled silently with a retry. Others require asking the user to clarify, correct an identifier, confirm a new action, or choose an alternate path.
```text
## Tool Failures
If a tool call fails:
1. Briefly explain what failed in user-friendly language.
2. Do not blame the user or expose raw tool errors.
3. If the failure may be due to an exact identifier, read back the value used and ask the user to correct it.
4. If the failure may be temporary, offer to retry once.
5. If the same failure happens repeatedly, offer an alternate path or escalation.
Do not repeatedly call the same tool with the same arguments after failure.
Do not ask for a different identifier until you have first checked whether the captured value was correct.
```
Bad:
> Assistant: Something went wrong.
Good:
> Assistant: I couldn't find a match for O R D dash 3 1 2 5 B 2 3. Did I get any part of that wrong?
### Keep tool availability synchronized
Realtime models are eager to help. If the prompt mentions a tool that is not actually available, or if the tool list does not match the prompt, the model may invent a tool name or pretend it completed the action.
For example, if the prompt references `lookup_order`, but the provided tool is named `search_orders`, the model may call the wrong name or simulate the action.
```text
## Tool Availability
Use only the tools that are explicitly provided in the current tool list.
Do not invent, assume, or simulate tools. If a tool is mentioned in the instructions but is not present in the tool list, treat it as unavailable.
If the user requests an action that requires an unavailable tool:
1. Do not pretend to complete the action.
2. Briefly explain that the tool is not available.
3. Offer the closest supported next step.
Only say an action was completed after the relevant tool call succeeds.
```
Use the prompt audit meta prompt in the appendix to review production prompts
for contradictions, missing tools, and brittle instructions.
## Handle silence and background audio
Voice agents tend to respond by default. In production, they often hear audio that should not receive a spoken response, such as silence, background noise, hold music, TV audio, or side conversations.
Use a no-op wait tool when the assistant should stay quiet and keep listening. The tool gives the model a valid non-speaking action instead of making it say things like "I'm here" or "I didn't catch that."
Tool design:
```json
{
"name": "wait_for_user",
"description": "Call this when the latest audio does not need a spoken response, such as silence, background noise, hold music, TV audio, side conversation, or speech not addressed to the assistant. This tool helps end the turn without a spoken reply.",
"parameters": {
"type": "object",
"properties": {},
"required": []
}
}
```
Pair it with prompt instructions:
```text
## Handling Silence and Background Noise
If the latest audio is silence, background noise, hold music, TV audio, side conversation, or speech not addressed to you, call `wait_for_user`.
Do not respond conversationally after calling this tool.
Do not say "I'm here," "I didn't catch that," "Take your time," or "Let me know when you're ready."
Resume normal responses only when the user clearly addresses you or asks for help.
```
Use this for non-addressed audio, not for unclear user requests. If the user is clearly speaking to the assistant but the content is unintelligible, ask for clarification instead.
## Use message channels deliberately
`gpt-realtime-2` can produce user-visible intermediate messages in the commentary channel and final user-facing responses in the final channel. Use channel-specific instructions when the behavior depends on where it appears.
| Channel | User-visible? | Used for |
| ------------ | ------------- | -------------------------- |
| `commentary` | Yes | Preambles and tool calls. |
| `final` | Yes | Final user-facing message. |
For example, tool calls happen in the commentary channel. If you want the assistant to say something before, during, or after tool use, specify that behavior in relation to the commentary channel.
```text
Before calling tools in the commentary channel, briefly tell the user what you are doing.
```
`gpt-realtime-2` can emit multiple response phases in a single turn. In API output, this distinction is represented by the `response.done` event, which includes a `phase` value that indicates whether the content is commentary or the final answer.
You can use this field to handle each phase differently in your application. For example, commentary can be played or displayed as a short intermediate update, while `final_answer` can be reserved for the assistant's completed response.
```text
response.output[0].phase: "commentary"
response.output[1].phase: "final_answer"
```
Example response phases
User prompt:
> "I'm stuck on this AP Bio question [QUESTION]."
Shortened API response:
```json
{
"type": "response.done",
"response": {
"output": [
{
"phase": "commentary",
"content": [
{
"type": "output_audio",
"transcript": "Let's zero in on the enzyme's shape and binding, since that's the key idea here."
}
]
},
{
"phase": "final_answer",
"content": [
{
"type": "output_audio",
"transcript": "What changes at the active site at high temperature?"
}
]
}
]
}
}
```
## Handle unclear audio
The model should only act on audio it can understand with confidence. If the audio is unclear, the model should ask a brief clarification question instead of guessing.
Do not let the model infer missing words, call tools, capture entities, generate preambles, or spend hidden reasoning time trying to reconstruct what the user may have said.
```text
## Unclear Audio
- Only respond to clear audio or text.
- If the user's audio is not clear, ask for clarification using a short English phrase such as "Sorry, could you repeat that clearly?"
- Don't repeat the same unclear-audio clarification twice.
- Treat audio as unclear if it is ambiguous, noisy, silent, unintelligible, partially cut off, or if you are unsure of the exact words the user said.
- Do not guess what the user meant from unclear audio.
- Do not reason when the audio is unclear.
- Do not provide a preamble or call tools in the commentary channel when the audio is unclear.
```
Example:
> User audio: "Check order three one-" [cut off]
Bad:
> Assistant: I'll check order 31 now.
Good:
> Assistant: I heard only part of the order number. Could you repeat it digit by digit?
## Capture exact entities
Many realtime workflows depend on exact values: order IDs, tracking numbers, email addresses, confirmation codes, account numbers, claim numbers, ticket IDs, support references, and phone numbers.
Voice makes this hard. Users speak quickly, group numbers in different ways, spell partial values, use filler, correct themselves mid-turn, or pronounce characters that sound alike. One wrong digit can fail a lookup or retrieve the wrong account.
Capture entities conservatively. Collect one value at a time, normalize only what is clear, confirm high-precision values before tool calls, and make every correction recoverable.
### Collect one entity at a time
When a workflow needs multiple values, collect them one at a time. This prevents fields from blending together, especially in voice conversations.
```text
## Entity Collection Order
Collect required values one at a time.
- Ask for only the next missing value.
- Do not ask for multiple values in the same turn.
- Before asking, check whether the value was already provided earlier in the conversation or the session.
- If a possible value already exists, confirm it with the user before using it.
Example:
"I see tracking number ABC-54321 from earlier. Should I use that one, or do you have a different tracking number?"
Do not call tools until the current value has been collected, validated, and confirmed.
```
### Handle spelled-out characters
Use this when users spell IDs, codes, names, or email addresses one character at a time. The spoken form is input, not the final value.
```text
## Spelled-Out Characters
When a user dictates an ID, code, or email character by character, treat the spoken sequence as one compact value. Preserve explicitly spoken separators like dash, dot, underscore, slash, or plus; otherwise do not add spaces or separators.
Examples:
- "A B C one two three" -> "ABC123"
- "B C dash nine eight seven" -> "BC-987"
- "J O H N at example dot com" -> "john@example.com"
Do not insert spaces between spelled-out characters unless the user explicitly says the value contains spaces.
```
### Normalize spoken numbers carefully
For numeric identifiers, users may say digits individually, group them, or use natural number phrases. If the field expects one continuous numeric value, convert clear numeric speech into digits.
```text
## Spoken Number Handling
Convert spoken numbers into digits when collecting numeric identifiers.
Examples:
- "one two three four" -> "1234"
- "one twenty three" -> "123"
- "one nineteen" -> "119"
- "ninety nine eleven" -> "9911"
- "nine thousand nine hundred eleven" -> "9911"
If multiple interpretations are plausible, ask the user to clarify before using the value.
Example:
"I heard either 119 or 1-19. Could you repeat the number digit by digit?"
```
### Confirm exact identifiers before tool calls
Order IDs, tracking numbers, account numbers, claim numbers, confirmation codes, and similar identifiers are high-precision fields. Confirm them before using them in a tool call.
For numeric identifiers, read the value back digit by digit. Reading the value as a full number can hide errors.
Example:
> Assistant: Just to confirm, I heard 8... 3... 5... 2... 1. Is that right?
If the user corrects one character or digit, repeat the full corrected value before calling the tool.
Example:
> Assistant: Got it. I have 8... 3... 5... 7... 1. Is that correct?
```text
## Exact Identifier Confirmation
Before calling tools with high-precision identifiers:
- Confirm the final normalized value with the user.
- Read numeric identifiers back digit by digit.
- Do not use guessed, partial, or ambiguous values.
- If the user corrects the value, repeat the full corrected value before calling the tool.
```
### Confirm emails character by character
Email addresses are important values. Dots, dashes, underscores, repeated letters, and similar-sounding names can cause account lookup failures or send messages to the wrong address.
Ask the user to spell the email address:
> Assistant: Could you spell the email address character by character so I can make sure I have it exactly right?
When reading it back, confirm the exact final address:
> Assistant: Just to confirm, that is c-h-e-n at example dot com, right?
```text
## Email Confirmation
Email addresses must be captured exactly.
If the user says the email naturally without spelling it out, ask them to repeat it character by character.
Example:
"Could you spell the email address character by character so I can make sure I have it exactly right?"
When reading an email back, confirm the exact final email address.
Example:
"Just to confirm, that is c-h-e-n at example dot com, right?"
```
### Entity collection workflow
Example Entity collection workflow
Use this full workflow when a task requires exact values before any tool call.
```text
## Entity Collection Workflow
When a workflow requires an exact value, collect and confirm it before using it in any tool call.
Exact values include order IDs, tracking numbers, confirmation codes, account numbers, claim numbers, ticket IDs, support references, email addresses, phone numbers, and similar identifiers.
Follow this workflow:
1. Collect the next required value.
- Ask for only one missing value at a time.
- Do not ask for multiple exact values in the same turn.
- Before asking, check whether the value was already provided earlier in the conversation or session.
2. Normalize only what is clear.
- Convert clearly spoken digits or spelled-out characters into the expected format.
- Preserve explicit separators such as dashes, dots, underscores, slashes, and plus signs.
- Do not guess, infer, repair, or fill in unclear characters.
- If the value could be interpreted in more than one way, ask the user to repeat or clarify it.
3. Confirm the final value.
- Read back the normalized value before using it.
- For numeric identifiers, confirm digit by digit.
- For email addresses, confirm character by character when precision matters.
- Wait for a clear confirmation from the user.
4. Call the tool only after confirmation.
- Do not call lookup, account, messaging, payment, booking, or update tools with guessed, partial, ambiguous, or unconfirmed values.
5. Recover safely from corrections.
- If the user corrects any part of the value, update the value, repeat the full corrected value, and ask for confirmation again.
- Do not use the corrected value in a tool call until the user confirms the full final value.
Examples:
User: My order ID is ORD-3125B23.
Assistant: Just to confirm, I heard O-R-D dash 3-1-2-5-B-2-3. Is that right?
User: It is 83521 - actually, the fourth digit is 7.
Assistant: Got it. I have 8... 3... 5... 7... 1. Is that correct?
User: My email is chen@example.com.
Assistant: Could you spell that email address character by character so I can make sure I have it exactly right?
Never call tools with guessed, partial, ambiguous, or unconfirmed exact values.
```
## Avoid literal instruction traps
`gpt-realtime-2` follows instructions more literally than earlier realtime models. Prompts that worked well on older models may need tuning.
Use precise language. The model may prioritize the exact wording of an instruction over the broader behavior you intended. Broad or rigid rules can dominate the assistant's behavior in surprising ways, especially when multiple rules overlap.
Be careful with constraint words such as `must`, `only`, `never`, and `always`. Use them when the behavior is truly required, not as general emphasis. Overusing hard constraints can make the assistant rigid, overly cautious, or unable to handle reasonable exceptions.
Prefer precise scope:
```text
For write actions that modify user data, ask for confirmation before calling the tool.
```
Avoid broad scope:
```text
Always ask for confirmation before doing anything.
```
The broad version may cause unnecessary confirmations before harmless read-only lookups, such as checking order status, retrieving availability, or reading account information.
### Literal interpretation example
Example literal interpretation trap
This prompt is too narrow:
```text
When a confirmation code is provided, repeat it verbatim and wait for a clear yes.
```
User message:
> My order ID is ORD-3125B23.
Possible failure:
The model may not apply the rule because the user provided an order ID, not a confirmation code. The intended behavior is clear to the developer, but the instruction's scope is too narrow.
Safer rewrite:
```text
When the user provides an exact identifier, including confirmation codes, order IDs, ticket IDs, reset PINs, claim numbers, tracking numbers, or account numbers, repeat the captured value and wait for confirmation before using it in a tool call.
```
General prompting recommendations:
- Prefer explicit instructions over implied intent.
- Avoid unnecessary constraint words unless behavior truly must be rigid.
- Minimize contradictory guidance.
- Be cautious with layered or competing priority instructions.
- Test prompts incrementally. Small wording changes can have large behavioral effects.
- When migrating from earlier realtime models, expect some prompts to require restructuring for best results.
## Control language and accent separately
Language and accent should be controlled separately.
A user's accent is not the same as their intended language. A user may speak English with a Hindi, Spanish, French, or Mandarin accent and still expect English responses.
Avoid broad language instructions such as:
```text
Mirror the user.
Respond naturally in the user's language.
Switch languages when appropriate.
Sound local.
Adapt to the user's accent.
```
These are too broad. The model may interpret accent, filler words, backchannels, or isolated foreign words as a reason to switch languages.
### English language policy
```text
## Language
English is the default response language.
- Do not infer language from accent alone.
- Ignore short filler sounds, backchannels, and isolated foreign words for language detection.
- Only switch languages if the user explicitly asks or provides a substantive utterance in another language.
- If language confidence is low, ask a short clarification instead of guessing.
- Keep preambles, spoken bridges, tool-related messages, and final answers in the same language.
- Accent adaptation must not change the response language.
```
### Multilingual policy
```text
## Language
Default to English unless the user clearly uses another language.
Switch languages only when:
- the user explicitly asks to use another language;
- the user provides a substantive utterance in another language. A substantive utterance means the user gives a complete request, question, or correction in another language, not just a greeting, name, address, filler word, or borrowed phrase.
Do not switch languages based on:
- accent;
- pronunciation;
- filler words;
- short backchannels;
- names;
- addresses;
- isolated foreign words.
If uncertain, ask:
"Would you like me to continue in English or [LANGUAGE]?"
```
### Accent control
`gpt-realtime-2` can follow accent instructions more strongly, but vague accent prompts can cause drift or unintended language switching.
Accent-control prompts work best when they specify:
- the target accent;
- which characteristics should remain stable;
- the intended pacing, stress, and prosody;
- whether accent adaptation should affect language choice.
Instead of:
```text
Sound Australian.
```
Use:
```text
## Accent
Speak English with a light Australian accent.
- Keep the accent stable from the first word to the last.
- Use natural Australian vowel shaping, but keep speech easy to understand.
- Do not exaggerate the accent.
- Do not change response language based on the user's accent.
```
### Custom voices
Use [Custom Voices](https://developers.openai.com/blog/updates-audio-models#custom-voices) when standard voices cannot reliably meet brand, accent, or character requirements.
Prompting can steer accent, pacing, and delivery, but it cannot fully replace voice design. For use cases that require consistent branded voice identity or accent fidelity, consider [Custom Voices](https://developers.openai.com/blog/updates-audio-models#custom-voices).
Custom Voices are available only to approved customers. Contact your account team for access.
## Maintain state in long sessions
`gpt-realtime-2` expands the realtime context window from 32k to 128k tokens, making it better suited for long sessions. For dense two-way conversations, 128k tokens is best thought of as roughly 1-2 hours of dense raw audio context. This will vary depending on tool use, internal reasoning, injected records, and other session details.
For long-context use cases, `gpt-realtime-2` performs best when it can tell what information is current, what is background, and what should be ignored if sources conflict. Do not rely on the model to infer source priority from a raw transcript or large context dump. Use structure.
Use a structured pattern when starting a session with a large amount of context, such as retrieved records, prior conversation history, policies, summaries, account notes, or background documents.
Example long-session context template
```text
## Context
### Current State
- **Current task:** [current task]
- **Latest known state:** [current value]
- **Next safe step:** [what the assistant should do next]
### Authoritative Sources
- **Fact or record:** [fact or record]
- **Source:** [tool result / active policy / verified record]
- **Status:** current
- **Retrieved:** [date/time or this turn]
### Historical or Background Sources
- **Older fact or record:** [older fact or record]
- **Source:** [prior conversation / older record / summary]
- **Status:** stale or background
- **Note:** Do not use for current decisions if it conflicts with a current source.
### Relevant Policy or Rules
- [decision rule or constraint]
### Other Context
- [potentially useful but non-authoritative background]
```
## Migrate from earlier realtime models
When migrating from earlier realtime models, treat the prompt as a behavior surface, not just text to port.
1. Use Codex or a strong reasoning model to restructure the prompt around the latest Realtime prompting guidance. Include a link to this prompting guide to ground the migration in best practices.
2. Set reasoning effort to `low` instead of the default. Increase only for workflows that require deeper planning.
3. Audit tool names, parameters, enums, JSON schemas, and other settings to make sure they match the expected implementation.
4. Remove stale examples. Add short examples for happy paths, ambiguity, interruptions, tool calls, and fallback behavior.
5. Compare representative conversations before and after migration. Check for regressions against an existing eval and document intentional behavior changes.
6. Run a final consistency pass. Confirm the prompt clearly separates hard requirements, defaults, tool rules, safety rules, and fallback behavior.
7. Run evals, inspect representative failures, and iterate on the prompt until the target behaviors are reliable.
## Realtime 1.5 Prompting Guide
`gpt-realtime-1.5` is a speech-to-speech model in the Realtime API. The same `gpt-realtime` prompting guidance applies to this model.
Speech-to-speech systems are essential for enabling voice as a core AI interface. `gpt-realtime-1.5` supports robust, usable realtime voice agents that can handle mission-critical workflows at scale.
Compared with earlier realtime preview models, `gpt-realtime-1.5` delivers stronger instruction following, more reliable tool calling, better voice quality, and an overall smoother feel. These gains make it practical to move from chained approaches to true realtime experiences, cutting latency and producing responses that sound more natural and expressive.
Realtime models benefit from prompting techniques that wouldn't directly apply to text-based models. This prompting guide starts with a suggested prompt skeleton, then walks through each part with practical tips, small patterns you can copy, and examples you can adapt to your use case.
## General Tips
- **Iterate relentlessly**: Small wording changes can make or break behavior.
- Example: For unclear audio instruction, we swapped “inaudible” → “unintelligible” which improved noisy input handling.
- **Prefer bullets over paragraphs**: Clear, short bullets outperform long paragraphs.
- **Guide with examples**: The model closely follows sample phrases.
- **Be precise**: Ambiguity or conflicting instructions = degraded performance similar to GPT-5.
- **Control language**: Pin output to a target language if you see unwanted language switching.
- **Reduce repetition**: Add a Variety rule to reduce robotic phrasing.
- **Use capitalized text for emphasis**: Capitalizing key rules makes them stand out and easier for the model to follow.
- **Convert non-text rules to text**: instead of writing "IF x > 3 THEN ESCALATE", write, "IF MORE THAN THREE FAILURES THEN ESCALATE".
## Prompt Structure
Organizing your prompt makes it easier for the model to understand context and stay consistent across turns. It also makes it easier for you to iterate and modify problematic sections.
- **What it does**: Use clear, labeled sections in your system prompt so the model can find and follow them. Keep each section focused on one thing.
- **How to adapt**: Add domain-specific sections (e.g., Compliance, Brand Policy). Remove sections you don’t need (e.g., Reference Pronunciations if not struggling with pronunciation).
Example
```
# Role & Objective — who you are and what “success” means
# Personality & Tone — the voice and style to maintain
# Context — retrieved context, relevant info
# Reference Pronunciations — phonetic guides for tricky words
# Tools — names, usage rules, and preambles
# Instructions / Rules — do’s, don’ts, and approach
# Conversation Flow — states, goals, and transitions
# Safety & Escalation — fallback and handoff logic
```
## Role and Objective
This section defines who the agent is and what “done” means. The examples show two different identities to demonstrate how tightly the model will adhere to role and objective when they’re explicit.
- **When to use**: The model is not taking on the persona, role, or task scope you need.
- **What it does**: Pins identity of the voice agent so that its responses are conditioned to that role description
- **How to adapt**: Modify the role based on your use case
#### Example (model takes on a specific accent)
```
# Role & Objective
You are a Quebecois French-speaking customer service bot. Your task is to answer the user's question.
```
Earlier realtime preview:
`gpt-realtime-1.5`:
#### Example (model takes on a character)
```
# Role & Objective
You are a high-energy game-show host guiding the caller to guess a secret number from 1 to 100 to win 1,000,000$.
```
Earlier realtime preview:
`gpt-realtime-1.5`:
`gpt-realtime-1.5` is able to enact the specified role more reliably than earlier realtime preview models.
## Personality and Tone
`gpt-realtime-1.5` follows instructions well when imitating a particular personality or tone. You can tailor the voice experience and delivery depending on what your use case expects.
- **When to use**: Responses feel flat, overly verbose, or inconsistent across turns.
- **What it does**: Sets voice, brevity, and pacing so replies sound natural and consistent.
- **How to adapt**: Tune warmth/formality and default length. For regulated domains, favor neutral precision. Add other subsections that are relevant to your use case.
#### Example
```
# Personality & Tone
## Personality
- Friendly, calm and approachable expert customer service assistant.
## Tone
- Warm, concise, confident, never fawning.
## Length
2–3 sentences per turn.
```
#### Example (multi-emotion)
```
# Personality & Tone
- Start your response very happy
- Midway, change to sad
- At the end change your mood to very angry
```
`gpt-realtime-1.5`:
The model is able to adhere to the complex instructions and switch between three emotions throughout the audio response.
### Speed Instructions
In the Realtime API, the `speed` parameter changes playback rate, not how the model composes speech. To actually sound faster, add instructions that can guide the pacing.
- **When to use**: Users want faster speaking voice; playback speed (with speed parameter) alone doesn’t fix speaking style.
- **What it does**: Tunes speaking style (brevity, cadence) independent of client playback speed.
- **How to adapt**: Modify speed instruction to meet use case requirements.
#### Example
```
# Personality & Tone
## Personality
- Friendly, calm and approachable expert customer service assistant.
## Tone
- Warm, concise, confident, never fawning.
## Length
- 2–3 sentences per turn.
## Pacing
- Deliver your audio response fast, but do not sound rushed.
- Do not modify the content of your response, only increase speaking speed for the same response.
```
Earlier realtime preview:
`gpt-realtime-1.5`:
With explicit pacing instructions, `gpt-realtime-1.5` can produce a noticeably faster pace without sounding too hurried.
### Language Constraint
Language constraints ensure the model consistently responds in the intended language, even in challenging conditions like background noise or multilingual inputs.
- **When to use**: To prevent accidental language switching in multilingual or noisy environments.
- **What it does**: Locks output to the chosen language to prevent accidental language changes.
- **How to adapt**: Switch “English” to your target language; or add more complex instructions based on your use case.
#### Example (pinning to one language)
```
# Personality & Tone
## Personality
- Friendly, calm and approachable expert customer service assistant.
## Tone
- Warm, concise, confident, never fawning.
## Length
- 2–3 sentences per turn.
## Language
- The conversation will be only in English.
- Do not respond in any other language even if the user asks.
- If the user speaks another language, politely explain that support is limited to English.
```
These are the responses after applying the instruction using `gpt-realtime-1.5`.
#### Example (model teaches a language)
```
# Role & Objective
- You are a friendly, knowledgeable voice tutor for French learners.
- Your goal is to help the user improve their French speaking and listening skills through engaging conversation and clear explanations.
- Balance immersive French practice with supportive English guidance to ensure understanding and progress.
# Personality & Tone
## Personality
- Friendly, calm and approachable expert customer service assistant.
## Tone
- Warm, concise, confident, never fawning.
## Length
- 2–3 sentences per turn.
## Language
### Explanations
Use English when explaining grammar, vocabulary, or cultural context.
### Conversation
Speak in French when conducting practice, giving examples, or engaging in dialogue.
```
These are the responses after applying the instruction using `gpt-realtime-1.5`.
The model is able to code-switch from one language to another based on custom instructions.
### Reduce Repetition
The realtime model can follow sample phrases closely to stay on-brand, but it may overuse them, making responses sound robotic or repetitive. Adding a repetition rule helps maintain variety while preserving clarity and brand voice.
- **When to use**: Outputs recycle the same openings, fillers, or sentence patterns across turns or sessions.
- **What it does**: Adds a variety constraint—discourages repeated phrases, nudges synonyms and alternate sentence structures, and keeps required terms intact.
- **How to adapt**: Tune strictness (e.g., “don’t reuse the same opener more than once every N turns”), whitelist must-keep phrases (legal/compliance/brand), and allow tighter phrasing where consistency matters.
#### Example
```
# Personality & Tone
## Personality
- Friendly, calm and approachable expert customer service assistant.
## Tone
- Warm, concise, confident, never fawning.
## Length
- 2–3 sentences per turn.
## Language
- The conversation will be only in English.
- Do not respond in any other language even if the user asks.
- If the user speaks another language, politely explain that support is limited to English.
## Variety
- Do not repeat the same sentence twice.
- Vary your responses so they don't sound robotic.
```
These are the responses **before** applying the instruction using `gpt-realtime-1.5`. The model repeats the same confirmation: `Got it`.
These are the responses **after** applying the instruction using `gpt-realtime-1.5`.
Now the model is able to vary its responses and confirmation and not sound robotic.
## Reference Pronunciations
This section covers how to ensure the model pronounces important words, numbers, names, and terms correctly during spoken interactions.
- **When to use**: Brand names, technical terms, or locations are often mispronounced.
- **What it does**: Improves trust and clarity with phonetic hints.
- **How to adapt**: Keep to a short list; update as you hear errors.
#### Example
```
# Reference Pronunciations
When voicing these words, use the respective pronunciations:
- Pronounce “SQL” as “sequel.”
- Pronounce “PostgreSQL” as “post-gress.”
- Pronounce “Kyiv” as “KEE-iv.”
- Pronounce "Huawei" as “HWAH-way”
```
Earlier realtime preview:
`gpt-realtime-1.5`:
With the reference pronunciation instructions, `gpt-realtime-1.5` can correctly pronounce SQL as "sequel."
### Alphanumeric Pronunciations
Realtime S2S can blur or merge digits/letters when reading back key info (phone, credit card, order IDs). Explicit character-by-character confirmation prevents mishearing and drives clearer synthesis.
- **When to use**: If the model struggles to capture or read back phone numbers, card numbers, 2FA codes, order IDs, serials, addresses, unit numbers, or mixed alphanumeric strings.
- **What it does**: Forces the model to speak one character at a time with separators, then confirm with the user and reconfirm after corrections. Optionally uses a phonetic disambiguator for letters (e.g., “A as in Alpha”).
#### Example (general instruction section)
```
# Instructions/Rules
- When reading numbers or codes, speak each character separately, separated by hyphens (e.g., 4-1-5).
- Repeat EXACTLY the provided number; do not omit any digits.
```
_Tip: If you are following a conversation flow prompting strategy, you can specify which conversation state needs to apply the alpha-numeric pronunciations instruction._
#### Example (instruction in conversation state)
_(taken from the conversation flow of the prompt of our [openai-realtime-agents](https://github.com/openai/openai-realtime-agents/blob/main/src/app/agentConfigs/customerServiceRetail/authentication.ts))_
```txt
{
"id": "3_get_and_verify_phone",
"description": "Request phone number and verify by repeating it back.",
"instructions": [
"Politely request the user’s phone number.",
"Once provided, confirm it by repeating each digit and ask if it’s correct.",
"If the user corrects you, confirm AGAIN to make sure you understand.",
],
"examples": [
"I'll need some more information to access your account if that's okay. May I have your phone number, please?",
"You said 0-2-1-5-5-5-1-2-3-4, correct?",
"You said 4-5-6-7-8-9-0-1-2-3, correct?"
],
"transitions": [{
"next_step": "4_authentication_DOB",
"condition": "Once phone number is confirmed"
}]
}
```
These are the responses **before** applying the instruction using `gpt-realtime-1.5`.
> Sure! The number is 55119765423. Let me know if you need anything else!
These are the responses **after** applying the instruction using `gpt-realtime-1.5`.
> Sure! The number is: 5-5-1-1-1-9-7-6-5-4-2-3. Please let me know if you need anything else!
## Instructions
This section covers prompt guidance for instructing your model to solve your task, apply best practices, and fix possible problems.
Perhaps unsurprisingly, we recommend prompting patterns that are similar to [GPT-4.1 for best results](https://developers.openai.com/cookbook/examples/gpt4-1_prompting_guide).
### Instruction Following
Like GPT-4.1 and GPT-5, if the instructions are conflicting, ambiguous, or unclear, `gpt-realtime-1.5` will perform worse.
- **When to use**: Outputs drift from rules, skip phases, or misuse tools.
- **What it does**: Uses an LLM to point out ambiguity, conflicts, and missing definitions before you ship.
#### **Instructions Quality Prompt (can be used in ChatGPT or with API)**
Use the following prompt with GPT-5 to identify problematic areas in your prompt that you can fix.
```
## Role & Objective
You are a **Prompt-Critique Expert**.
Examine a user-supplied LLM prompt and surface any weaknesses following the instructions below.
## Instructions
Review the prompt that is meant for an LLM to follow and identify the following issues:
- Ambiguity: Could any wording be interpreted in more than one way?
- Lacking Definitions: Are there any class labels, terms, or concepts that are not defined that might be misinterpreted by an LLM?
- Conflicting, missing, or vague instructions: Are directions incomplete or contradictory?
- Unstated assumptions: Does the prompt assume the model has to be able to do something that is not explicitly stated?
## Do **NOT** list issues of the following types:
- Invent new instructions, tool calls, or external information. You do not know what tools need to be added that are missing.
- Issues that you are unsure about.
## Output Format
"""
# Issues
- Numbered list; include brief quote snippets.
# Improvements
- Numbered list; provide the revised lines you would change and how you would change them.
# Revised Prompt
- Revised prompt where you have applied all your improvements surgically with minimal edits to the original prompt
"""
```
#### **Prompt Optimization Meta Prompt (can be used in ChatGPT or with API)**
This meta-prompt helps you improve your base system prompt by targeting a specific failure mode. Provide the current prompt and describe the issue you’re seeing, the model (GPT-5) will suggest refined variants that tighten constraints and reduce the problem.
```
Here's my current prompt to an LLM:
[BEGIN OF CURRENT PROMPT]
{CURRENT_PROMPT}
[END OF CURRENT PROMPT]
But I see this issue happening from the LLM:
[BEGIN OF ISSUE]
{ISSUE}
[END OF ISSUE]
Can you provide some variants of the prompt so that the model can better understand the constraints to alleviate the issue?
```
### No Audio or Unclear Audio
Sometimes the model thinks it hears something and tries to respond. You can add a custom instruction telling the model how to behave when it hears unclear audio or user input. Modify the desired behavior to fit your use case. For example, you may want the model to repeat the same question instead of asking for clarification.
- **When to use**: Background noise, partial words, or silence trigger unwanted replies.
- **What it does**: Stops spurious responses and creates graceful clarification.
- **How to adapt**: Choose whether to ask for clarification or repeat the last question depending on use case.
#### Example (coughing and unclear audio)
```
# Instructions/Rules
...
## Unclear audio
- Always respond in the same language the user is speaking in, if unintelligible.
- Only respond to clear audio or text.
- If the user's audio is not clear (e.g. ambiguous input/background noise/silent/unintelligible) or if you did not fully hear or understand the user, ask for clarification using {preferred_language} phrases.
```
These are the responses **after** applying the instruction using `gpt-realtime-1.5`.
In this example, the model asks for clarification after my _(very)_ loud cough and unclear audio.
### Background Music or Sounds
Occasionally, the model may generate unintended background music, humming, rhythmic noises, or sound-like artifacts during speech generation. These artifacts can diminish clarity, distract users, or make the assistant feel less professional. The following instructions help prevent or significantly reduce these occurrences.
- **When to use**: Use when you observe unintended musical elements or sound effects in Realtime audio responses.
- **What it does**: Steers the model to avoid generating these unwanted audio artifacts.
- **How to adapt**: Adjust the instruction to try to explicitly suppress the specific sound patterns you are encountering.
#### Example
```
# Instructions/Rules
...
- Do not include any sound effects or onomatopoeic expressions in your responses.
```
## Tools
Use this section to tell the model how to use your functions and tools. Spell out when and when not to call a tool, which arguments to collect, what to say while a call is running, and how to handle errors or partial results.
### Tool Selection
`gpt-realtime-1.5` follows instructions closely. However, if you have instructions that conflict with what the model can access, such as mentioning tools in your prompt that are NOT passed in the tools list, it can lead to bad responses.
- **When to use**: Prompts mention tools that aren’t actually available.
- **What it does**: Reviews the available tools and system prompt to ensure they align.
#### Example
```
# Tools
## lookup_account(email_or_phone)
...
## check_outage(address)
...
```
We need to ensure the same tools are available and **the descriptions do not contradict each other**:
```json
[
{
"name": "lookup_account",
"description": "Retrieve a customer account using either an email or phone number to enable verification and account-specific actions.",
"parameters": {
...
},
{
"name": "check_outage",
"description": "Check for network outages affecting a given service address and return status and ETA if applicable.",
"parameters": {
...
}
]
```
### Tool Call Preambles
Some use cases could benefit from the Realtime model providing an audio response at the same time as calling a tool. This leads to a better user experience, masking latency. You can modify the sample phrase to fit your use case.
- **When to use**: Users need immediate confirmation at the same time as a tool call; helps mask latency.
- **What it does**: Adds a short, consistent preamble before a tool call.
#### Example
```
# Tools
- Before any tool call, say one short line like “I’m checking that now.” Then call the tool immediately.
```
These are the responses after applying the instruction using `gpt-realtime-1.5`.
Using the instruction, the model outputs an audio response "I'm checking that right now" at the same time as the tool call.
#### Tool Call Preambles + Sample Phrases
If you want to control more closely what type of phrases the model outputs at the same time it calls a tool, you can add sample phrases in the tool spec description.
#### Example
```python
tools = [
{
"name": "lookup_account",
"description": "Retrieve a customer account using either an email or phone number to enable verification and account-specific actions.
Preamble sample phrases:
- For security, I’ll pull up your account using the email on file.
- Let me look up your account by {email} now.
- I’m fetching the account linked to {phone} to verify access.
- One moment—I’m opening your account details."
"parameters": {
"..."
}
},
{
"name": "check_outage",
"description": "Check for network outages affecting a given service address and return status and ETA if applicable.
Preamble sample phrases:
- I’ll check for any outages at {service_address} right now.
- Let me look up network status for your area.
- I’m checking whether there’s an active outage impacting your address.
- One sec—verifying service status and any posted ETA.",
"parameters": {
"..."
}
}
]
```
### Tool Calls Without Confirmation
Sometimes the model might ask for confirmation before a tool call. For some use cases, this can lead to poor experience for the end user since the model is not being proactive.
- **When to use**: The agent asks for permission before obvious tool calls.
- **What it does**: Removes unnecessary confirmation loops.
#### Example
```
# Tools
- When calling a tool, do not ask for any user confirmation. Be proactive
```
These are the responses **after** applying the instruction using `gpt-realtime-1.5`.
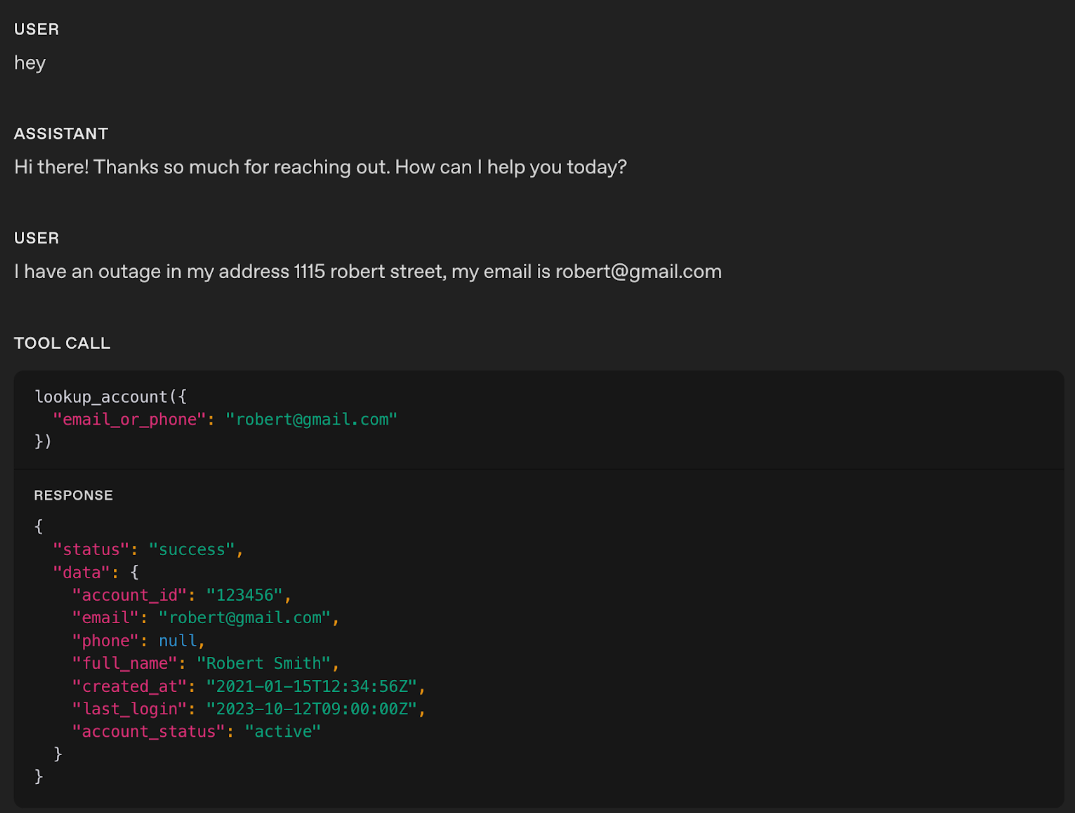
In the example, you notice that the realtime model did not produce any response audio; it directly called the respective tool.
_Tip: If you notice the model is jumping too quickly to call a tool, try softening the wording. For example, swapping out stronger terms like “proactive” with something gentler can help guide the model to take a calmer, less eager approach._
### Tool Call Performance
As use cases grow more complex and the number of available tools increases, it becomes critical to explicitly guide the model on when to use each tool and just as importantly, when not to. Clear usage rules not only improve tool call accuracy but also help the model choose the right tool at the right time.
- **When to use**: Model is struggling with tool call performance and needs the instructions to be explicit to reduce misuse.
- **What it does**: Add instructions on when to “use/avoid” each tool. You can also add instructions on sequences of tool calls (after Tool call A, you can call Tool call B or C)
#### Example
```
# Tools
- When you call any tools, you must output at the same time a response letting the user know that you are calling the tool.
## lookup_account(email_or_phone)
Use when: verifying identity or viewing plan/outage flags.
Do NOT use when: the user is clearly anonymous and only asks general questions.
## check_outage(address)
Use when: user reports connectivity issues or slow speeds.
Do NOT use when: question is billing-only.
## refund_credit(account_id, minutes)
Use when: confirmed outage > 240 minutes in the past 7 days.
Do NOT use when: outage is unconfirmed; route to Diagnose → check_outage first.
## schedule_technician(account_id, window)
Use when: repeated failures after reboot and outage status = false.
Do NOT use when: outage status = true (send status + ETA instead).
## escalate_to_human(account_id, reason)
Use when: user seems very frustrated, abuse/harassment, repeated failures, billing disputes >$50, or user requests escalation.
```
_Tip: If a tool call can fail unpredictably, add clear failure-handling instructions so the model responds gracefully._
### Tool Level Behavior
You can fine-tune how the model behaves for specific tools instead of applying one global rule. For example, you may want READ tools to be called proactively, while WRITE tools require explicit confirmation.
- **When to use**: Global instructions for proactiveness, confirmation, or preambles don’t suit every tool.
- **What it does**: Adds per-tool behavior rules that define whether the model should call the tool immediately, confirm first, or speak a preamble before the call.
#### Example
```
# TOOLS
- For the tools marked PROACTIVE: do not ask for confirmation from the user and do not output a preamble.
- For the tools marked as CONFIRMATION FIRST: always ask for confirmation to the user.
- For the tools marked as PREAMBLES: Before any tool call, say one short line like “I’m checking that now.” Then call the tool immediately.
## lookup_account(email_or_phone) — PROACTIVE
Use when: verifying identity or accessing billing.
Do NOT use when: caller refuses to identify after second request.
## check_outage(address) — PREAMBLES
Use when: caller reports failed connection or speed lower than 10 Mbps.
Do NOT use when: purely billing OR when internet speed is above 10 Mbps.
If either condition applies, inform the customer you cannot assist and hang up.
## refund_credit(account_id, minutes) — CONFIRMATION FIRST
Use when: confirmed outage > 240 minutes in the past 7 days (credit 60 minutes).
Do NOT use when: outage unconfirmed.
Confirmation phrase: “I can issue a credit for this outage—would you like me to go ahead?”
## schedule_technician(account_id, window) — CONFIRMATION FIRST
Use when: reboot + line checks fail AND outage=false.
Windows: “10am–12pm ET” or “2pm–4pm ET”.
Confirmation phrase: “I can schedule a technician to visit—should I book that for you?”
## escalate_to_human(account_id, reason) — PREAMBLES
Use when: harassment, threats, self-harm, repeated failure, billing disputes > $50, caller is frustrated, or caller requests escalation.
Preamble: “Let me connect you to a senior agent who can assist further.”
```
### Tool Output Formatting
Some tool outputs, especially long strings that must be repeated verbatim, can be out-of-distribution for the model. During training, tool outputs commonly look like JSON objects with named fields. If your tool returns a raw string and separately asks the model to “repeat exactly,” the model may be more prone to paraphrasing, truncation, or blending in its own preamble.
A practical fix is to make the tool output look like a normal tool result and make the verbatim requirement machine-explicit.
- **When to use:** A tool returns **long or complex structured content** (multi-sentence instructions, handoff packets, IDs/links, policy summaries, multi-step procedures, etc.) and you observe **truncation, paraphrasing, dropped fields, reordering, or the model blending in its own preamble/commentary**.
- **What it does:** Wraps the tool output in a **small, explicit JSON envelope** (e.g., `response_text` plus flags like `require_repeat_verbatim`, `format`, or `content_type`) so the response looks more **in-distribution** and the expected realization behavior is **machine-clear**.
- **How to adapt:** Keep the schema **minimal and stable**. Clearly document the expected tool output shape in both your **Tools instructions** and next to the **tool definition** (e.g., “If `require_repeat_verbatim` is true, output exactly `response_text` and nothing else,” or “Render `response_text` as-is; do not add, omit, or reorder fields from the tool output.”).
#### Examples
#### Example: raw string (more error-prone)
Tool returns:
```python
I just sent you an email with the verification link. Please open it and click “Confirm”.
```
Model sometimes says:
- “I’ve emailed you a verification link…” (paraphrase)
- Drops the last sentence (truncation)
- Adds extra commentary (“Can I help with anything else?”)
#### Example: wrapped JSON (more in-distribution, more reliable)
Tool returns:
```json
{
"response_text": "I just sent you an email with the verification link. Please open it and click “Confirm”.",
"require_repeat_verbatim": true
}
```
Because this looks like a typical tool result (JSON object), the model generally has an easier time:
- recognizing what the “authoritative” content is (response_text)
- understanding the realization constraint (require_repeat_verbatim)
- reproducing the tool output cleanly, without truncation or extra commentary
### Rephrase Supervisor Tool (Responder-Thinker Architecture)
In many voice setups, the realtime model acts as the responder (speaks to the user) while a stronger text model acts as the thinker (does planning, policy lookups, SOP completion). Text replies are not automatically good for speech, so the responder must rephrase the thinker’s text into an audio-friendly response before generating audio.
- **When to use**: When the responder’s spoken output sounds robotic, too long, or awkward after receiving a thinker response.
- **What it does**: Adds clear instructions that guide the responder to rephrase the thinker’s text into a short, natural, speech-first reply.
- **How to adapt**: Tweak phrasing style, openers, and brevity limits to match your use case expectations.
#### Example
```
# Tools
## Supervisor Tool
Name: getNextResponseFromSupervisor(relevantContextFromLastUserMessage: string)
When to call:
- Any request outside the allow list.
- Any factual, policy, account, or process question.
- Any action that might require internal lookups or system changes.
When not to call:
- Simple greetings and basic chitchat.
- Requests to repeat or clarify.
- Collecting parameters for later Supervisor use:
- phone_number for account help (getUserAccountInfo)
- zip_code for store lookup (findNearestStore)
- topic or keyword for policy lookup (lookupPolicyDocument)
Usage rules and preamble:
1) Say a neutral filler phrase to the user, then immediately call the tool. Approved fillers: “One moment.”, “Let me check.”, “Just a second.”, “Give me a moment.”, “Let me see.”, “Let me look into that.” Fillers must not imply success or failure.
2) Do not mention the “Supervisor” when responding with filler phrase.
3) relevantContextFromLastUserMessage is a one-line summary of the latest user message; use an empty string if nothing salient.
4) After the tool returns, apply Rephrase Supervisor and send your reply.
### Rephrase Supervisor
- Start with a brief conversational opener using active language, then flow into the answer (for example: “Thanks for waiting—”, “Just finished checking that.”, “I’ve got that pulled up now.”).
- Keep it short: no more than 2 sentences.
- Use this template: opener + one-sentence gist + up to 3 key details + a quick confirmation or choice (for example: “Does that match what you expected?”, “Want me to review options?”).
- Read numbers for speech: money naturally (“$45.20” → “forty-five dollars and twenty cents”), phone numbers 3-3-4, addresses with individual digits, dates/times plainly (“August twelfth”, “three-thirty p.m.”).
```
Here’s an example without the rephrasing instruction:
> Assistant: Your current credit card balance is positive at 32,323,232 AUD.
Here’s the same example with the rephrasing instruction:
> Assistant: Just finished checking that—your credit card balance is thirty-two million three hundred twenty-three thousand two hundred thirty-two dollars in your favor. Your last payment was processed on August first. Does that match what you expected?
### Common Tools
`gpt-realtime-1.5` has been trained to effectively use the following common tools. If your use case needs similar behavior, keep the names, signatures, and descriptions close to these to maximize reliability and to be more in-distribution.
Below are some of the important common tools that the model has been trained on:
#### Example
```
# answer(question: string)
Description: Call this when the customer asks a question that you don't have an answer to or asks to perform an action.
# escalate_to_human()
Description: Call this when a customer asks for escalation, or to talk to someone else, or expresses dissatisfaction with the call.
# finish_session()
Description: Call this when a customer says they're done with the session or doesn't want to continue. If it's ambiguous, confirm with the customer before calling.
```
## Conversation Flow
This section covers how to structure the dialogue into clear, goal-driven phases so the model knows exactly what to do at each step. It defines the purpose of each phase, the instructions for moving through it, and the concrete “exit criteria” for transitioning to the next. This prevents the model from stalling, skipping steps, or jumping ahead, and ensures the conversation stays organized from greeting to resolution.
As well, by organizing your prompt into various conversation states, it becomes easier to identify error modes and iterate more effectively.
- **When to use**: If conversations feel disorganized, stall before reaching the goal, or the model struggles to effectively complete the objective.
- **What it does**: Breaks the interaction into phases with clear goals, instructions and exit criteria.
- **How to adapt**: Rename phases to match your workflow; modify instructions for each phase to follow your intended behavior; keep “Exit when” concrete and minimal.
#### Example
```
# Conversation Flow
## 1) Greeting
Goal: Set tone and invite the reason for calling.
How to respond:
- Identify as NorthLoop Internet Support.
- Keep the opener brief and invite the caller’s goal.
- Confirm that customer is a Northloop customer
Exit to Discovery: Caller states they are a Northloop customer and mentions an initial goal or symptom.
## 2) Discover
Goal: Classify the issue and capture minimal details.
How to respond:
- Determine billing vs connectivity with one targeted question.
- For connectivity: collect the service address.
- For billing/account: collect email or phone used on the account.
Exit when: Intent and address (for connectivity) or email/phone (for billing) are known.
## 3) Verify
Goal: Confirm identity and retrieve the account.
How to respond:
- Once you have email or phone, call lookup_account(email_or_phone).
- If lookup fails, try the alternate identifier once; otherwise proceed with general guidance or offer escalation if account actions are required.
Exit when: Account ID is returned.
## 4) Diagnose
Goal: Decide outage vs local issue.
How to respond:
- For connectivity, call check_outage(address).
- If outage=true, skip local steps; move to Resolve with outage context.
- If outage=false, guide a short reboot/cabling check; confirm each step’s result before continuing.
Exit when: Root cause known.
## 5) Resolve
Goal: Apply fix, credit, or appointment.
How to respond:
- If confirmed outage > 240 minutes in the last 7 days, call refund_credit(account_id, 60).
- If outage=false and issue persists after basic checks, offer “10am–12pm ET” or “2pm–4pm ET” and call schedule_technician(account_id, chosen window).
- If the local fix worked, state the result and next steps briefly.
Exit when: A fix/credit/appointment has been applied and acknowledged by the caller.
## 6) Confirm/Close
Goal: Confirm outcome and end cleanly.
How to respond:
- Restate the result and any next step (e.g., stabilization window or tech ETA).
- Invite final questions; close politely if none.
Exit when: Caller declines more help.
```
### Sample Phrases
Sample phrases act as “anchor examples” for the model. They show the style, brevity, and tone you want it to follow, without locking it into one rigid response.
- **When to use**: Responses lack your brand style or are not consistent.
- **What it does**: Provides sample phrases the model can vary to stay natural and brief.
- **How to adapt**: Swap examples for brand-fit; keep the “do not always use” warning.
#### Example
```
# Sample Phrases
- Below are sample examples that you should use for inspiration. DO NOT ALWAYS USE THESE EXAMPLES, VARY YOUR RESPONSES.
Acknowledgements: “On it.” “One moment.” “Good question.”
Clarifiers: “Do you want A or B?” “What’s the deadline?”
Bridges: “Here’s the quick plan.” “Let’s keep it simple.”
Empathy (brief): “That’s frustrating—let’s fix it.”
Closers: “Anything else before we wrap?” “Happy to help next time.”
```
_Note: If your voice system ends up consistently only repeating the sample phrases, leading to a more robotic voice experience, try adding the Variety constraint. We’ve seen this fix the issue._
### Conversation flow + Sample Phrases
It is a useful pattern to add sample phrases in the different conversation flow states to teach the model what a good response looks like:
#### Example
```
# Conversation Flow
## 1) Greeting
Goal: Set tone and invite the reason for calling.
How to respond:
- Identify as NorthLoop Internet Support.
- Keep the opener brief and invite the caller’s goal.
Sample phrases (do not always repeat the same phrases, vary your responses):
- “Thanks for calling NorthLoop Internet—how can I help today?”
- “You’ve reached NorthLoop Support. What’s going on with your service?”
- “Hi there—tell me what you’d like help with.”
Exit when: Caller states an initial goal or symptom.
## 2) Discover
Goal: Classify the issue and capture minimal details.
How to respond:
- Determine billing vs connectivity with one targeted question.
- For connectivity: collect the service address.
- For billing/account: collect email or phone used on the account.
Sample phrases (do not always repeat the same phrases, vary your responses):
- “Is this about your bill or your internet speed?”
- “What address are you using for the connection?”
- “What’s the email or phone number on the account?”
Exit when: Intent and address (for connectivity) or email/phone (for billing) are known.
## 3) Verify
Goal: Confirm identity and retrieve the account.
How to respond:
- Once you have email or phone, call lookup_account(email_or_phone).
- If lookup fails, try the alternate identifier once; otherwise proceed with general guidance or offer escalation if account actions are required.
Sample phrases:
- “Thanks—looking up your account now.”
- “If that doesn’t pull up, what’s the other contact—email or phone?”
- “Found your account. I’ll take care of this.”
Exit when: Account ID is returned.
## 4) Diagnose
Goal: Decide outage vs local issue.
How to respond:
- For connectivity, call check_outage(address).
- If outage=true, skip local steps; move to Resolve with outage context.
- If outage=false, guide a short reboot/cabling check; confirm each step’s result before continuing.
Sample phrases (do not always repeat the same phrases, vary your responses):
- “I’m running a quick outage check for your area.”
- “No outage reported—let’s try a fast modem reboot.”
- “Please confirm the modem lights: is the internet light solid or blinking?”
Exit when: Root cause known.
## 5) Resolve
Goal: Apply fix, credit, or appointment.
How to respond:
- If confirmed outage > 240 minutes in the last 7 days, call refund_credit(account_id, 60).
- If outage=false and issue persists after basic checks, offer “10am–12pm ET” or “2pm–4pm ET” and call schedule_technician(account_id, chosen window).
- If the local fix worked, state the result and next steps briefly.
Sample phrases (do not always repeat the same phrases, vary your responses):
- “There’s been an extended outage—adding a 60-minute bill credit now.”
- “No outage—let’s book a technician. I can do 10am–12pm ET or 2pm–4pm ET.”
- “Credit applied—you’ll see it on your next bill.”
Exit when: A fix/credit/appointment has been applied and acknowledged by the caller.
## 6) Confirm/Close
Goal: Confirm outcome and end cleanly.
How to respond:
- Restate the result and any next step (e.g., stabilization window or tech ETA).
- Invite final questions; close politely if none.
Sample phrases (do not always repeat the same phrases, vary your responses):
- “We’re all set: [credit applied / appointment booked / service restored].”
- “You should see stable speeds within a few minutes.”
- “Your technician window is 10am–12pm ET.”
Exit when: Caller declines more help.
```
### Advanced Conversation Flow
As use cases grow more complex, you’ll need a structure that scales while keeping the model effective. The key is balancing maintainability with simplicity: too many rigid states can overload the model, hurting performance and making conversations feel robotic.
A better approach is to design flows that reduce the model’s perceived complexity. By handling state in a structured but flexible way, you make it easier for the model to stay focused and responsive, which improves user experience.
Two common patterns for managing complex scenarios are:
1. Conversation Flow as State Machine
2. Dynamic Conversation Flow via session.updates
#### Conversation Flow as State Machine
Define your conversation as a JSON structure that encodes both states and transitions. This makes it easy to reason about coverage, identify edge cases, and track changes over time. Since it’s stored as code, you can version, diff, and extend it as your flow evolves. A state machine also gives you fine-grained control over exactly how and when the conversation moves from one state to another.
#### Example
```json
# Conversation States
[
{
"id": "1_greeting",
"description": "Begin each conversation with a warm, friendly greeting, identifying the service and offering help.",
"instructions": [
"Use the company name 'Snowy Peak Boards' and provide a warm welcome.",
"Let them know upfront that for any account-specific assistance, you’ll need some verification details."
],
"examples": [
"Hello, this is Snowy Peak Boards. Thanks for reaching out! How can I help you today?"
],
"transitions": [{
"next_step": "2_get_first_name",
"condition": "Once greeting is complete."
}, {
"next_step": "3_get_and_verify_phone",
"condition": "If the user provides their first name."
}]
},
{
"id": "2_get_first_name",
"description": "Ask for the user’s name (first name only).",
"instructions": [
"Politely ask, 'Who do I have the pleasure of speaking with?'",
"Do NOT verify or spell back the name; just accept it."
],
"examples": [
"Who do I have the pleasure of speaking with?"
],
"transitions": [{
"next_step": "3_get_and_verify_phone",
"condition": "Once name is obtained, OR name is already provided."
}]
},
{
"id": "3_get_and_verify_phone",
"description": "Request phone number and verify by repeating it back.",
"instructions": [
"Politely request the user’s phone number.",
"Once provided, confirm it by repeating each digit and ask if it’s correct.",
"If the user corrects you, confirm AGAIN to make sure you understand.",
],
"examples": [
"I'll need some more information to access your account if that's okay. May I have your phone number, please?",
"You said 0-2-1-5-5-5-1-2-3-4, correct?",
"You said 4-5-6-7-8-9-0-1-2-3, correct?"
],
"transitions": [{
"next_step": "4_authentication_DOB",
"condition": "Once phone number is confirmed"
}]
},
...
```
#### Dynamic Conversation Flow
In this pattern, the conversation adapts in real time by updating the system prompt and tool list based on the current state. Instead of exposing the model to all possible rules and tools at once, you only provide what’s relevant to the active phase of the conversation.
When the end conditions for a state are met, you use session.update to transition, replacing the prompt and tools with those needed for the next phase.
This approach reduces the model’s cognitive load, making it easier for it to handle complex tasks without being distracted by unnecessary context.
#### Example
```python
from typing import Dict, List, Literal
State = Literal["verify", "resolve"]
# Allowed transitions
TRANSITIONS: Dict[State, List[State]] = {
"verify": ["resolve"],
"resolve": [] # terminal
}
def build_state_change_tool(current: State) -> dict:
allowed = TRANSITIONS[current]
readable = ", ".join(allowed) if allowed else "no further states (terminal)"
return {
"type": "function",
"name": "set_conversation_state",
"description": (
f"Switch the conversation phase. Current: '{current}'. "
f"You may switch only to: {readable}. "
"Call this AFTER exit criteria are satisfied."
),
"parameters": {
"type": "object",
"properties": {
"next_state": {"type": "string", "enum": allowed}
},
"required": ["next_state"]
}
}
# Minimal business tools per state
TOOLS_BY_STATE: Dict[State, List[dict]] = {
"verify": [{
"type": "function",
"name": "lookup_account",
"description": "Fetch account by email or phone.",
"parameters": {
"type": "object",
"properties": {"email_or_phone": {"type": "string"}},
"required": ["email_or_phone"]
}
}],
"resolve": [{
"type": "function",
"name": "schedule_technician",
"description": "Book a technician visit.",
"parameters": {
"type": "object",
"properties": {
"account_id": {"type": "string"},
"window": {"type": "string", "enum": ["10-12 ET", "14-16 ET"]}
},
"required": ["account_id", "window"]
}
}]
}
# Short, phase-specific instructions
INSTRUCTIONS_BY_STATE: Dict[State, str] = {
"verify": (
"# Role & Objective\n"
"Verify identity to access the account.\n\n"
"# Conversation (Verify)\n"
"- Ask for the email or phone on the account.\n"
"- Read back digits one-by-one (e.g., '4-1-5… Is that correct?').\n"
"Exit when: Account ID is returned.\n"
"When exit is satisfied: call set_conversation_state(next_state=\"resolve\")."
),
"resolve": (
"# Role & Objective\n"
"Apply a fix by booking a technician.\n\n"
"# Conversation (Resolve)\n"
"- Offer two windows: '10–12 ET' or '2–4 ET'.\n"
"- Book the chosen window.\n"
"Exit when: Appointment is confirmed.\n"
"When exit is satisfied: end the call politely."
)
}
def build_session_update(state: State) -> dict:
"""Return the JSON payload for a Realtime `session.update` event."""
return {
"type": "session.update",
"session": {
"instructions": INSTRUCTIONS_BY_STATE[state],
"tools": TOOLS_BY_STATE[state] + [build_state_change_tool(state)]
}
}
```
## Safety & Escalation
Often with Realtime voice agents, having a reliable way to escalate to a human is important. In this section, you should modify the instructions on WHEN to escalate depending on your use case.
- **When to use**: Model is struggling to determine when to properly escalate to a human or fallback system
- **What it does**: Defines fast, reliable escalation and what to say.
- **How to adapt**: Insert your own thresholds and what the model has to say.
#### Example
```
# Safety & Escalation
When to escalate (no extra troubleshooting):
- Safety risk (self-harm, threats, harassment)
- User explicitly asks for a human
- Severe dissatisfaction (e.g., “extremely frustrated,” repeated complaints, profanity)
- **2** failed tool attempts on the same task **or** **3** consecutive no-match/no-input events
- Out-of-scope or restricted (e.g., real-time news, financial/legal/medical advice)
What to say at the same time as calling the escalate_to_human tool (MANDATORY):
- “Thanks for your patience—I’m connecting you with a specialist now.”
- Then call the tool: `escalate_to_human`
Examples that would require escalation:
- “This is the third time the reset didn’t work. Just get me a person.”
- “I am extremely frustrated!”
```
The first example shows conversation responses from `gpt-4o-realtime-preview-2025-06-03` using the instruction.
The second example shows conversation responses from `gpt-realtime-1.5` using the instruction.

`gpt-realtime-1.5` is able to follow the instruction and escalate to a human more reliably.
File search
Search your files in a response
```python
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
input="What is deep research by OpenAI?",
tools=[{
"type": "file_search",
"vector_store_ids": ["
"]
}]
)
print(response)
```
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5.5",
input: "What is deep research by OpenAI?",
tools: [
{
type: "file_search",
vector_store_ids: [""],
},
],
});
console.log(response);
```
```csharp
using OpenAI.Responses;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5.5", apiKey: key);
ResponseCreationOptions options = new();
options.Tools.Add(ResponseTool.CreateFileSearchTool([""]));
OpenAIResponse response = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("What is deep research by OpenAI?"),
]),
], options);
Console.WriteLine(response.GetOutputText());
```
Remote MCP
Call a remote MCP server
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5.5",
"tools": [
{
"type": "mcp",
"server_label": "dmcp",
"server_description": "A Dungeons and Dragons MCP server to assist with dice rolling.",
"server_url": "https://dmcp-server.deno.dev/sse",
"require_approval": "never"
}
],
"input": "Roll 2d4+1"
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const resp = await client.responses.create({
model: "gpt-5.5",
tools: [
{
type: "mcp",
server_label: "dmcp",
server_description: "A Dungeons and Dragons MCP server to assist with dice rolling.",
server_url: "https://dmcp-server.deno.dev/sse",
require_approval: "never",
},
],
input: "Roll 2d4+1",
});
console.log(resp.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-5.5",
tools=[
{
"type": "mcp",
"server_label": "dmcp",
"server_description": "A Dungeons and Dragons MCP server to assist with dice rolling.",
"server_url": "https://dmcp-server.deno.dev/sse",
"require_approval": "never",
},
],
input="Roll 2d4+1",
)
print(resp.output_text)
```
```csharp
using OpenAI.Responses;
string key = Environment.GetEnvironmentVariable("OPENAI_API_KEY")!;
OpenAIResponseClient client = new(model: "gpt-5.5", apiKey: key);
ResponseCreationOptions options = new();
options.Tools.Add(ResponseTool.CreateMcpTool(
serverLabel: "dmcp",
serverUri: new Uri("https://dmcp-server.deno.dev/sse"),
toolCallApprovalPolicy: new McpToolCallApprovalPolicy(GlobalMcpToolCallApprovalPolicy.NeverRequireApproval)
));
OpenAIResponse response = (OpenAIResponse)client.CreateResponse([
ResponseItem.CreateUserMessageItem([
ResponseContentPart.CreateInputTextPart("Roll 2d4+1")
])
], options);
Console.WriteLine(response.GetOutputText());
```
## Available tools
Here's an overview of the tools available in the OpenAI platform—select one of them for further guidance on usage.
Call custom code to give the model access to additional data and
capabilities.
Include data from the Internet in model response generation.
Give the model access to new capabilities via Model Context Protocol (MCP)
servers.
Upload and reuse versioned skill bundles in hosted shell environments.
Run shell commands in hosted containers or in your own local runtime.
Create agentic workflows that enable a model to control a computer
interface.
Generate or edit images using GPT Image.
Search the contents of uploaded files for context when generating a
response.
Dynamically load relevant tools into the model’s context to optimize token
usage.
## Usage in the API
When making a request to generate a [model response](https://developers.openai.com/api/docs/api-reference/responses/create), you usually enable tool access by specifying configurations in the `tools` parameter. Each tool has its own unique configuration requirements—see the [Available tools](#available-tools) section for detailed instructions.
Based on the provided [prompt](https://developers.openai.com/api/docs/guides/text), the model automatically decides whether to use a configured tool. For instance, if your prompt requests information beyond the model's training cutoff date and web search is enabled, the model will typically invoke the web search tool to retrieve relevant, up-to-date information.
Some advanced workflows can also load more tool definitions during the interaction. For example, [tool search](https://developers.openai.com/api/docs/guides/tools-tool-search) can defer function definitions until the model decides they're needed.
You can explicitly control or guide this behavior by setting the `tool_choice` parameter [in the API request](https://developers.openai.com/api/docs/api-reference/responses/create).
## Usage in the Agents SDK
In the Agents SDK, the tool semantics stay the same, but the wiring moves into the agent definition and workflow design rather than a single Responses API request.
- Attach hosted tools, function tools, or hosted MCP tools directly on the agent when one specialist should call them itself.
- Expose a specialist as a tool when a manager should stay in control of the user-facing reply.
- Keep shell, apply patch, and computer-use harnesses in your runtime even when the SDK models the tool decision.
Wrap local logic as a function tool
```typescript
import { tool } from "@openai/agents";
import { z } from "zod";
const getWeatherTool = tool({
name: "get_weather",
description: "Get the weather for a given city.",
parameters: z.object({ city: z.string() }),
async execute({ city }) {
return \`The weather in \${city} is sunny.\`;
},
});
```
```python
from agents import function_tool
@function_tool
def get_weather(city: str) -> str:
"""Get the weather for a given city."""
return f"The weather in {city} is sunny."
```
Expose a specialist as a tool
```typescript
import { Agent } from "@openai/agents";
const summarizer = new Agent({
name: "Summarizer",
instructions: "Generate a concise summary of the supplied text.",
});
const mainAgent = new Agent({
name: "Research assistant",
tools: [
summarizer.asTool({
toolName: "summarize_text",
toolDescription: "Generate a concise summary of the supplied text.",
}),
],
});
```
```python
from agents import Agent
summarizer = Agent(
name="Summarizer",
instructions="Generate a concise summary of the supplied text.",
)
main_agent = Agent(
name="Research assistant",
tools=[
summarizer.as_tool(
tool_name="summarize_text",
tool_description="Generate a concise summary of the supplied text.",
)
],
)
```
Use [Agent definitions](https://developers.openai.com/api/docs/guides/agents/define-agents) when you are shaping a single specialist, [Orchestration and handoffs](https://developers.openai.com/api/docs/guides/agents/orchestration) when tools affect ownership, [Guardrails and human review](https://developers.openai.com/api/docs/guides/agents/guardrails-approvals) when tools affect approvals, and [Integrations and observability](https://developers.openai.com/api/docs/guides/agents/integrations-observability#mcp) when the capability comes from MCP.
---
# Vector embeddings
## What are embeddings?
OpenAI’s text embeddings measure the relatedness of text strings. Embeddings are commonly used for:
- **Search** (where results are ranked by relevance to a query string)
- **Clustering** (where text strings are grouped by similarity)
- **Recommendations** (where items with related text strings are recommended)
- **Anomaly detection** (where outliers with little relatedness are identified)
- **Diversity measurement** (where similarity distributions are analyzed)
- **Classification** (where text strings are classified by their most similar label)
An embedding is a vector (list) of floating point numbers. The [distance](#which-distance-function-should-i-use) between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
Visit our [pricing page](https://openai.com/api/pricing/) to learn about embeddings pricing. Requests are billed based on the number of [tokens](https://platform.openai.com/tokenizer) in the [input](https://developers.openai.com/api/docs/api-reference/embeddings/create#embeddings/create-input).
## How to get embeddings
To get an embedding, send your text string to the [embeddings API endpoint](https://developers.openai.com/api/docs/api-reference/embeddings) along with the embedding model name (e.g., `text-embedding-3-small`):
Example: Getting embeddings
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const embedding = await openai.embeddings.create({
model: "text-embedding-3-small",
input: "Your text string goes here",
encoding_format: "float",
});
console.log(embedding);
```
```python
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
input="Your text string goes here",
model="text-embedding-3-small"
)
print(response.data[0].embedding)
```
```bash
curl https://api.openai.com/v1/embeddings \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}'
```
The response contains the embedding vector (list of floating point numbers) along with some additional metadata. You can extract the embedding vector, save it in a vector database, and use for many different use cases.
```json
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.006929283495992422, -0.005336422007530928, -4.547132266452536e-5,
-0.024047505110502243
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
```
By default, the length of the embedding vector is `1536` for `text-embedding-3-small` or `3072` for `text-embedding-3-large`. To reduce the embedding's dimensions without losing its concept-representing properties, pass in the [dimensions parameter](https://developers.openai.com/api/docs/api-reference/embeddings/create#embeddings-create-dimensions). Find more detail on embedding dimensions in the [embedding use case section](#use-cases).
## Embedding models
OpenAI offers two powerful third-generation embedding model (denoted by `-3` in the model ID). Read the embedding v3 [announcement blog post](https://openai.com/blog/new-embedding-models-and-api-updates) for more details.
Usage is priced per input token. Below is an example of pricing pages of text per US dollar (assuming ~800 tokens per page):
| Model | ~ Pages per dollar | Performance on [MTEB](https://github.com/embeddings-benchmark/mteb) eval | Max input |
| ---------------------- | ------------------ | ------------------------------------------------------------------------ | --------- |
| text-embedding-3-small | 62,500 | 62.3% | 8192 |
| text-embedding-3-large | 9,615 | 64.6% | 8192 |
| text-embedding-ada-002 | 12,500 | 61.0% | 8192 |
## Use cases
Here we show some representative use cases, using the [Amazon fine-food reviews dataset](https://www.kaggle.com/snap/amazon-fine-food-reviews).
### Obtaining the embeddings
The dataset contains a total of 568,454 food reviews left by Amazon users up to October 2012. We use a subset of the 1000 most recent reviews for illustration purposes. The reviews are in English and tend to be positive or negative. Each review has a `ProductId`, `UserId`, `Score`, review title (`Summary`) and review body (`Text`). For example:
| Product Id | User Id | Score | Summary | Text |
| ---------- | -------------- | ----- | --------------------- | ------------------------------------------------- |
| B001E4KFG0 | A3SGXH7AUHU8GW | 5 | Good Quality Dog Food | I have bought several of the Vitality canned... |
| B00813GRG4 | A1D87F6ZCVE5NK | 1 | Not as Advertised | Product arrived labeled as Jumbo Salted Peanut... |
Below, we combine the review summary and review text into a single combined text. The model encodes this combined text and output a single vector embedding.
Get_embeddings_from_dataset.ipynb ```python
from openai import OpenAI
client = OpenAI()
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
df['ada_embedding'] = df.combined.apply(lambda x: get_embedding(x, model='text-embedding-3-small'))
df.to_csv('output/embedded_1k_reviews.csv', index=False)
```
To load the data from a saved file, you can run the following:
```python
import pandas as pd
df = pd.read_csv('output/embedded_1k_reviews.csv')
df['ada_embedding'] = df.ada_embedding.apply(eval).apply(np.array)
```
Reducing embedding dimensions
Using larger embeddings, for example storing them in a vector store for retrieval, generally costs more and consumes more compute, memory and storage than using smaller embeddings.
Both of our new embedding models were trained [with a technique](https://arxiv.org/abs/2205.13147) that allows developers to trade-off performance and cost of using embeddings. Specifically, developers can shorten embeddings (i.e. remove some numbers from the end of the sequence) without the embedding losing its concept-representing properties by passing in the [`dimensions` API parameter](https://developers.openai.com/api/docs/api-reference/embeddings/create#embeddings-create-dimensions). For example, on the MTEB benchmark, a `text-embedding-3-large` embedding can be shortened to a size of 256 while still outperforming an unshortened `text-embedding-ada-002` embedding with a size of 1536. You can read more about how changing the dimensions impacts performance in our [embeddings v3 launch blog post](https://openai.com/blog/new-embedding-models-and-api-updates#:~:text=Native%20support%20for%20shortening%20embeddings).
In general, using the `dimensions` parameter when creating the embedding is the suggested approach. In certain cases, you may need to change the embedding dimension after you generate it. When you change the dimension manually, you need to be sure to normalize the dimensions of the embedding as is shown below.
```python
from openai import OpenAI
import numpy as np
client = OpenAI()
def normalize_l2(x):
x = np.array(x)
if x.ndim == 1:
norm = np.linalg.norm(x)
if norm == 0:
return x
return x / norm
else:
norm = np.linalg.norm(x, 2, axis=1, keepdims=True)
return np.where(norm == 0, x, x / norm)
response = client.embeddings.create(
model="text-embedding-3-small", input="Testing 123", encoding_format="float"
)
cut_dim = response.data[0].embedding[:256]
norm_dim = normalize_l2(cut_dim)
print(norm_dim)
```
Dynamically changing the dimensions enables very flexible usage. For example, when using a vector data store that only supports embeddings up to 1024 dimensions long, developers can now still use our best embedding model `text-embedding-3-large` and specify a value of 1024 for the `dimensions` API parameter, which will shorten the embedding down from 3072 dimensions, trading off some accuracy in exchange for the smaller vector size.
Question answering using embeddings-based search
Question_answering_using_embeddings.ipynb
There are many common cases where the model is not trained on data which contains key facts and information you want to make accessible when generating responses to a user query. One way of solving this, as shown below, is to put additional information into the context window of the model. This is effective in many use cases but leads to higher token costs. In this notebook, we explore the tradeoff between this approach and embeddings bases search.
```python
query = f"""Use the below article on the 2022 Winter Olympics to answer the subsequent question. If the answer cannot be found, write "I don't know."
Article:
\"\"\"
{wikipedia_article_on_curling}
\"\"\"
Question: Which athletes won the gold medal in curling at the 2022 Winter Olympics?"""
response = client.chat.completions.create(
messages=[
{'role': 'system', 'content': 'You answer questions about the 2022 Winter Olympics.'},
{'role': 'user', 'content': query},
],
model=GPT_MODEL,
temperature=0,
)
print(response.choices[0].message.content)
```
Text search using embeddings
Semantic_text_search_using_embeddings.ipynb
To retrieve the most relevant documents we use the cosine similarity between the embedding vectors of the query and each document, and return the highest scored documents.
```python
from openai.embeddings_utils import get_embedding, cosine_similarity
def search_reviews(df, product_description, n=3, pprint=True):
embedding = get_embedding(product_description, model='text-embedding-3-small')
df['similarities'] = df.ada_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
return res
res = search_reviews(df, 'delicious beans', n=3)
```
Code search using embeddings
Code_search.ipynb
Code search works similarly to embedding-based text search. We provide a method to extract Python functions from all the Python files in a given repository. Each function is then indexed by the `text-embedding-3-small` model.
To perform a code search, we embed the query in natural language using the same model. Then we calculate cosine similarity between the resulting query embedding and each of the function embeddings. The highest cosine similarity results are most relevant.
```python
from openai.embeddings_utils import get_embedding, cosine_similarity
df['code_embedding'] = df['code'].apply(lambda x: get_embedding(x, model='text-embedding-3-small'))
def search_functions(df, code_query, n=3, pprint=True, n_lines=7):
embedding = get_embedding(code_query, model='text-embedding-3-small')
df['similarities'] = df.code_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
return res
res = search_functions(df, 'Completions API tests', n=3)
```
Recommendations using embeddings
Recommendation_using_embeddings.ipynb
Because shorter distances between embedding vectors represent greater similarity, embeddings can be useful for recommendation.
Below, we illustrate a basic recommender. It takes in a list of strings and one 'source' string, computes their embeddings, and then returns a ranking of the strings, ranked from most similar to least similar. As a concrete example, the linked notebook below applies a version of this function to the [AG news dataset](http://groups.di.unipi.it/~gulli/AG_corpus_of_news_articles.html) (sampled down to 2,000 news article descriptions) to return the top 5 most similar articles to any given source article.
```python
def recommendations_from_strings(
strings: List[str],
index_of_source_string: int,
model="text-embedding-3-small",
) -> List[int]:
"""Return nearest neighbors of a given string."""
# get embeddings for all strings
embeddings = [embedding_from_string(string, model=model) for string in strings]
# get the embedding of the source string
query_embedding = embeddings[index_of_source_string]
# get distances between the source embedding and other embeddings (function from embeddings_utils.py)
distances = distances_from_embeddings(query_embedding, embeddings, distance_metric="cosine")
# get indices of nearest neighbors (function from embeddings_utils.py)
indices_of_nearest_neighbors = indices_of_nearest_neighbors_from_distances(distances)
return indices_of_nearest_neighbors
```
Data visualization in 2D
Visualizing_embeddings_in_2D.ipynb
The size of the embeddings varies with the complexity of the underlying model. In order to visualize this high dimensional data we use the t-SNE algorithm to transform the data into two dimensions.
We color the individual reviews based on the star rating which the reviewer has given:
- 1-star: red
- 2-star: dark orange
- 3-star: gold
- 4-star: turquoise
- 5-star: dark green
The visualization seems to have produced roughly 3 clusters, one of which has mostly negative reviews.
```python
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import matplotlib
df = pd.read_csv('output/embedded_1k_reviews.csv')
matrix = df.ada_embedding.apply(eval).to_list()
# Create a t-SNE model and transform the data
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)
colors = ["red", "darkorange", "gold", "turquiose", "darkgreen"]
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
color_indices = df.Score.values - 1
colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
plt.title("Amazon ratings visualized in language using t-SNE")
```
Embedding as a text feature encoder for ML algorithms
Regression_using_embeddings.ipynb
An embedding can be used as a general free-text feature encoder within a machine learning model. Incorporating embeddings will improve the performance of any machine learning model, if some of the relevant inputs are free text. An embedding can also be used as a categorical feature encoder within a ML model. This adds most value if the names of categorical variables are meaningful and numerous, such as job titles. Similarity embeddings generally perform better than search embeddings for this task.
We observed that generally the embedding representation is very rich and information dense. For example, reducing the dimensionality of the inputs using SVD or PCA, even by 10%, generally results in worse downstream performance on specific tasks.
This code splits the data into a training set and a testing set, which will be used by the following two use cases, namely regression and classification.
```python
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
list(df.ada_embedding.values),
df.Score,
test_size = 0.2,
random_state=42
)
```
#### Regression using the embedding features
Embeddings present an elegant way of predicting a numerical value. In this example we predict the reviewer’s star rating, based on the text of their review. Because the semantic information contained within embeddings is high, the prediction is decent even with very few reviews.
We assume the score is a continuous variable between 1 and 5, and allow the algorithm to predict any floating point value. The ML algorithm minimizes the distance of the predicted value to the true score, and achieves a mean absolute error of 0.39, which means that on average the prediction is off by less than half a star.
```python
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(n_estimators=100)
rfr.fit(X_train, y_train)
preds = rfr.predict(X_test)
```
Classification using the embedding features
Classification_using_embeddings.ipynb
This time, instead of having the algorithm predict a value anywhere between 1 and 5, we will attempt to classify the exact number of stars for a review into 5 buckets, ranging from 1 to 5 stars.
After the training, the model learns to predict 1 and 5-star reviews much better than the more nuanced reviews (2-4 stars), likely due to more extreme sentiment expression.
```python
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
```
Zero-shot classification
Zero-shot_classification_with_embeddings.ipynb
We can use embeddings for zero shot classification without any labeled training data. For each class, we embed the class name or a short description of the class. To classify some new text in a zero-shot manner, we compare its embedding to all class embeddings and predict the class with the highest similarity.
```python
from openai.embeddings_utils import cosine_similarity, get_embedding
df= df[df.Score!=3]
df['sentiment'] = df.Score.replace({1:'negative', 2:'negative', 4:'positive', 5:'positive'})
labels = ['negative', 'positive']
label_embeddings = [get_embedding(label, model=model) for label in labels]
def label_score(review_embedding, label_embeddings):
return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])
prediction = 'positive' if label_score('Sample Review', label_embeddings) > 0 else 'negative'
```
Obtaining user and product embeddings for cold-start recommendation
User_and_product_embeddings.ipynb
We can obtain a user embedding by averaging over all of their reviews. Similarly, we can obtain a product embedding by averaging over all the reviews about that product. In order to showcase the usefulness of this approach we use a subset of 50k reviews to cover more reviews per user and per product.
We evaluate the usefulness of these embeddings on a separate test set, where we plot similarity of the user and product embedding as a function of the rating. Interestingly, based on this approach, even before the user receives the product we can predict better than random whether they would like the product.
```python
user_embeddings = df.groupby('UserId').ada_embedding.apply(np.mean)
prod_embeddings = df.groupby('ProductId').ada_embedding.apply(np.mean)
```
Clustering
Clustering.ipynb
Clustering is one way of making sense of a large volume of textual data. Embeddings are useful for this task, as they provide semantically meaningful vector representations of each text. Thus, in an unsupervised way, clustering will uncover hidden groupings in our dataset.
In this example, we discover four distinct clusters: one focusing on dog food, one on negative reviews, and two on positive reviews.
```python
import numpy as np
from sklearn.cluster import KMeans
matrix = np.vstack(df.ada_embedding.values)
n_clusters = 4
kmeans = KMeans(n_clusters = n_clusters, init='k-means++', random_state=42)
kmeans.fit(matrix)
df['Cluster'] = kmeans.labels_
```
## FAQ
### How can I tell how many tokens a string has before I embed it?
In Python, you can split a string into tokens with OpenAI's tokenizer [`tiktoken`](https://github.com/openai/tiktoken).
Example code:
```python
import tiktoken
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string("tiktoken is great!", "cl100k_base")
```
For third-generation embedding models like `text-embedding-3-small`, use the `cl100k_base` encoding.
More details and example code are in the OpenAI Cookbook guide [how to count tokens with tiktoken](https://developers.openai.com/cookbook/examples/how_to_count_tokens_with_tiktoken).
### How can I retrieve K nearest embedding vectors quickly?
For searching over many vectors quickly, we recommend using a vector database. You can find examples of working with vector databases and the OpenAI API [in our Cookbook](https://developers.openai.com/cookbook/examples/vector_databases/readme) on GitHub.
### Which distance function should I use?
We recommend [cosine similarity](https://en.wikipedia.org/wiki/Cosine_similarity). The choice of distance function typically doesn't matter much.
OpenAI embeddings are normalized to length 1, which means that:
- Cosine similarity can be computed slightly faster using just a dot product
- Cosine similarity and Euclidean distance will result in the identical rankings
### Can I share my embeddings online?
Yes, customers own their input and output from our models, including in the case of embeddings. You are responsible for ensuring that the content you input to our API does not violate any applicable law or our [Terms of Use](https://openai.com/policies/terms-of-use).
### Do V3 embedding models know about recent events?
No, the `text-embedding-3-large` and `text-embedding-3-small` models lack knowledge of events that occurred after September 2021. This is generally not as much of a limitation as it would be for text generation models but in certain edge cases it can reduce performance.
---
# Video generation with Sora
## Overview
Sora is OpenAI’s newest frontier in generative media – a state-of-the-art video model capable of creating richly detailed, dynamic clips with audio from natural language or images. Built on years of research into multimodal diffusion and trained on diverse visual data, Sora brings a deep understanding of 3D space, motion, and scene continuity to text-to-video generation.
The [Videos API](https://developers.openai.com/api/reference/resources/videos) exposes these capabilities to developers for the first time, enabling programmatic creation, extension, editing, and management of videos.
You can use it to:
- Create new videos from prompts.
- Guide a generation with an image reference.
- Reuse character assets across multiple generations for stronger visual consistency.
- Continue a completed clip with video extensions.
- Edit an existing video with targeted changes.
- Download finished videos and supporting assets.
- Submit large offline render queues through the [Batch API](https://developers.openai.com/api/docs/guides/batch).
## Models
The second generation Sora model comes in two variants, each tailored for different use cases.
### Sora 2
`sora-2` is designed for **speed and flexibility**. It’s ideal for the exploration phase, when you’re experimenting with tone, structure, or visual style and need quick feedback rather than perfect fidelity.
It generates good quality results quickly, making it well suited for rapid iteration, concepting, and rough cuts. `sora-2` is often more than sufficient for social media content, prototypes, and scenarios where turnaround time matters more than ultra-high fidelity.
### Sora 2 Pro
`sora-2-pro` produces higher quality results. It’s the better choice when you need **production-quality output**.
`sora-2-pro` takes longer to render and is more expensive to run, but it produces more polished, stable results. It’s best for high-resolution cinematic footage, marketing assets, and any situation where visual precision is critical.
Use `sora-2-pro` when you need 1080p exports in `1920x1080` or `1080x1920`.
Both `sora-2` and `sora-2-pro` support `16`- and `20`-second generations.
## Generate a video
Generating a video is an **asynchronous** process:
1. When you call the `POST /videos` endpoint, the API returns a job object with a job `id` and an initial `status`.
2. You can either poll the `GET /videos/{video_id}` endpoint until the status transitions to completed, or – for a more efficient approach – use webhooks (see the webhooks section below) to be notified automatically when the job finishes.
3. Once the job has reached the `completed` state you can fetch the final MP4 file with `GET /videos/{video_id}/content`.
### Start a render job
Start by calling `POST /videos` with a text prompt and the required parameters. The prompt defines the creative look and feel – subjects, camera, lighting, and motion – while parameters like `size` and `seconds` control the video's resolution and length.
Create a video
```python
from openai import OpenAI
openai = OpenAI()
video = openai.videos.create(
model="sora-2",
prompt="A video of a cool cat on a motorcycle in the night",
)
print("Video generation started:", video)
```
```bash
curl -X POST "https://api.openai.com/v1/videos" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: multipart/form-data" \\
-F prompt="Wide tracking shot of a teal coupe driving through a desert highway, heat ripples visible, hard sun overhead." \\
-F model="sora-2-pro" \\
-F size="1280x720" \\
-F seconds="8" \\
```
The response is a JSON object with a unique id and an initial status such as `queued` or `in_progress`. This means the render job has started.
```shell
{
"id": "video_68d7512d07848190b3e45da0ecbebcde004da08e1e0678d5",
"object": "video",
"created_at": 1758941485,
"status": "queued",
"model": "sora-2-pro",
"progress": 0,
"seconds": "8",
"size": "1280x720"
}
```
### Choose size and duration
Pick the smallest format that meets your production needs:
- Use shorter clips when you are iterating on prompt, motion, or composition.
- Generate videos up to `20` seconds when you need longer beats, fuller scenes, or fuller spots.
- Use `sora-2-pro` for higher-resolution exports in `1920x1080` or `1080x1920`.
Longer durations and 1080p jobs can take materially longer to complete than short 720p or 480p renders, so plan for higher latency in user-facing flows.
### Guardrails and restrictions
The API enforces several content restrictions:
- Only content suitable for audiences under 18 (a setting to bypass this restriction will be available in the future).
- Copyrighted characters and copyrighted music will be rejected.
- Real people—including public figures—cannot be generated.
- Character uploads that depict human likeness are blocked by default.
- Input images with faces of humans are currently rejected.
Make sure prompts, reference images, and transcripts respect these rules to avoid failed generations.
### Effective prompting
For best results, describe **shot type, subject, action, setting, and lighting**. For example:
- _“Wide shot of a child flying a red kite in a grassy park, golden hour sunlight, camera slowly pans upward.”_
- _“Close-up of a steaming coffee cup on a wooden table, morning light through blinds, soft depth of field.”_
This level of specificity helps the model produce consistent results without inventing unwanted details. For more advanced prompting techniques, please refer to our dedicated Sora 2 [prompting guide](https://developers.openai.com/cookbook/examples/sora/sora2_prompting_guide).
### Monitor progress
Video generation takes time. Depending on model, API load and resolution, **a single render may take several minutes**.
To manage this efficiently, you can poll the API to request status updates or you can get notified via a webhook.
#### Poll the status endpoint
Call `GET /videos/{video_id}` with the id returned from the create call. The response shows the job’s current status, progress percentage (if available), and any errors.
Typical states are `queued`, `in_progress`, `completed`, and `failed`. Poll at a reasonable interval (for example, every 10–20 seconds), use exponential backoff if necessary, and provide feedback to users that the job is still in progress.
Poll the status endpoint
```javascript
import OpenAI from 'openai';
const openai = new OpenAI();
async function main() {
const video = await openai.videos.createAndPoll({
model: 'sora-2',
prompt: "A video of the words 'Thank you' in sparkling letters",
});
if (video.status === 'completed') {
console.log('Video successfully completed: ', video);
} else {
console.log('Video creation failed. Status: ', video.status);
}
}
main();
```
```python
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI()
async def main() -> None:
video = await client.videos.create_and_poll(
model="sora-2",
prompt="A video of a cat on a motorcycle",
)
if video.status == "completed":
print("Video successfully completed: ", video)
else:
print("Video creation failed. Status: ", video.status)
asyncio.run(main())
```
Response example:
```shell
{
"id": "video_68d7512d07848190b3e45da0ecbebcde004da08e1e0678d5",
"object": "video",
"created_at": 1758941485,
"status": "in_progress",
"model": "sora-2-pro",
"progress": 33,
"seconds": "8",
"size": "1280x720"
}
```
#### Use webhooks for notifications
Instead of polling job status repeatedly with `GET`, register a [webhook](https://developers.openai.com/api/docs/guides/webhooks) to be notified automatically when a video generation completes or fails.
Webhooks can be configured in your [webhook settings page](https://platform.openai.com/settings/project/webhooks). When a job finishes, the API emits one of two event types: `video.completed` and `video.failed`. Each event includes the ID of the job that triggered it.
Example webhook payload:
```
{
"id": "evt_abc123",
"object": "event",
"created_at": 1758941485,
"type": "video.completed", // or "video.failed"
"data": {
"id": "video_abc123"
}
}
```
### Retrieve results
#### Download the MP4
Once the job reaches status `completed`, fetch the MP4 with `GET /videos/{video_id}/content`. This endpoint streams the binary video data and returns standard content headers, so you can either save the file directly to disk or pipe it to cloud storage.
Download the MP4
```javascript
import OpenAI from 'openai';
const openai = new OpenAI();
let video = await openai.videos.create({
model: 'sora-2',
prompt: "A video of the words 'Thank you' in sparkling letters",
});
console.log('Video generation started: ', video);
let progress = video.progress ?? 0;
while (video.status === 'in_progress' || video.status === 'queued') {
video = await openai.videos.retrieve(video.id);
progress = video.progress ?? 0;
// Display progress bar
const barLength = 30;
const filledLength = Math.floor((progress / 100) * barLength);
// Simple ASCII progress visualization for terminal output
const bar = '='.repeat(filledLength) + '-'.repeat(barLength - filledLength);
const statusText = video.status === 'queued' ? 'Queued' : 'Processing';
process.stdout.write(\`\${statusText}: [\${bar}] \${progress.toFixed(1)}%\`);
await new Promise((resolve) => setTimeout(resolve, 2000));
}
// Clear the progress line and show completion
process.stdout.write('\\n');
if (video.status === 'failed') {
console.error('Video generation failed');
return;
}
console.log('Video generation completed: ', video);
console.log('Downloading video content...');
const content = await openai.videos.downloadContent(video.id);
const body = content.arrayBuffer();
const buffer = Buffer.from(await body);
require('fs').writeFileSync('video.mp4', buffer);
console.log('Wrote video.mp4');
```
```bash
curl -L "https://api.openai.com/v1/videos/video_abc123/content" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
--output video.mp4
```
```python
from openai import OpenAI
import sys
import time
openai = OpenAI()
video = openai.videos.create(
model="sora-2",
prompt="A video of a cool cat on a motorcycle in the night",
)
print("Video generation started:", video)
progress = getattr(video, "progress", 0)
bar_length = 30
while video.status in ("in_progress", "queued"):
# Refresh status
video = openai.videos.retrieve(video.id)
progress = getattr(video, "progress", 0)
filled_length = int((progress / 100) * bar_length)
bar = "=" * filled_length + "-" * (bar_length - filled_length)
status_text = "Queued" if video.status == "queued" else "Processing"
sys.stdout.write(f"\r{status_text}: [{bar}] {progress:.1f}%")
sys.stdout.flush()
time.sleep(2)
# Move to next line after progress loop
sys.stdout.write("\n")
if video.status == "failed":
message = getattr(
getattr(video, "error", None), "message", "Video generation failed"
)
print(message)
return
print("Video generation completed:", video)
print("Downloading video content...")
content = openai.videos.download_content(video.id, variant="video")
content.write_to_file("video.mp4")
print("Wrote video.mp4")
```
You now have the final video file ready for playback, editing, or distribution. Download URLs are valid for a maximum of 1 hour after generation. If you need long-term storage, copy the file to your own storage system promptly.
#### Download supporting assets
For each completed video, you can also download a **thumbnail** and a **spritesheet**. These are lightweight assets useful for previews, scrubbers, or catalog displays. Use the `variant` query parameter to specify what you want to download. The default is `variant=video` for the MP4.
```shell
# Download a thumbnail
curl -L "https://api.openai.com/v1/videos/video_abc123/content?variant=thumbnail" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
--output thumbnail.webp
# Download a spritesheet
curl -L "https://api.openai.com/v1/videos/video_abc123/content?variant=spritesheet" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
--output spritesheet.jpg
```
## Use image references
You can guide a generation with an input image, which acts as **the first frame of your video**. This is useful if you need the output video to preserve the look of a brand asset, a character, or a specific environment.
Choose the `input_reference` format based on the request type:
- Use `input_reference` with an uploaded image in `multipart/form-data` requests.
- Use `input_reference` with a JSON object in `application/json` requests, including Batch. The JSON form accepts either `file_id` or `image_url`.
The image must match the target video's resolution (`size`).
Supported file formats are `image/jpeg`, `image/png`, and `image/webp`.
```shell
curl -X POST "https://api.openai.com/v1/videos" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: multipart/form-data" \
-F prompt="She turns around and smiles, then slowly walks out of the frame." \
-F model="sora-2-pro" \
-F size="1280x720" \
-F seconds="8" \
-F input_reference="@sample_720p.jpeg;type=image/jpeg"
```
| Input image generated with [OpenAI GPT Image](https://developers.openai.com/api/docs/guides/image-generation) | Generated video using Sora 2 (converted to GIF) |
| :---------------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------: |
| ![][sora_woman_skyline_original][Download this image](https://cdn.openai.com/API/docs/images/sora/woman_skyline_original_720p.jpeg) | ![][sora_woman_skyline_video] Prompt: _“She turns around and smiles, then slowly walks out of the frame.”_ |
| ![][sora_monster_original_jpeg][Download this image](https://cdn.openai.com/API/docs/images/sora/monster_original_720p.jpeg) | ![][sora_monster_original_gif] Prompt: _“The fridge door opens. A cute, chubby purple monster comes out of it.”_ |
## Use characters for consistency
Characters let you upload a reusable non-human subject and reference it across multiple generations. This is useful when you want an animal, mascot, or object to keep the same core appearance, styling, and screen presence across several shots.
Character uploads currently work best with short `2`- to `4`-second clips in
`16:9` or `9:16`, at `720p` to `1080p`. Character source videos work best when
they match the aspect ratio of the requested output. If the aspect ratios
differ, the character can appear stretched or distorted. A single video can
include up to two characters.
Characters are different from `input_reference`. An image reference conditions
the opening frame of a single generation, while a character asset can be reused
across future video requests.
Create the character by uploading a short MP4 clip to `POST /v1/videos/characters`, then include the returned character ID in the `characters` array when you create a video.
Character uploads that depict human likeness are blocked by default. Contact
your account manager or [reach out to our sales
team](https://openai.com/contact-sales/) to learn more about eligibility for
human-likeness access.
```shell
curl -X POST "https://api.openai.com/v1/videos/characters" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: multipart/form-data" \
-F "video=@character.mp4;type=video/mp4" \
-F "name=Mossy"
```
Mention the character name verbatim in your prompt. Passing the character ID
alone isn't enough to reliably preserve the character in the shot.
Characters can be combined with `input_reference`. Extensions don't support
characters.
```shell
curl -X POST "https://api.openai.com/v1/videos" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "sora-2",
"prompt": "A cinematic tracking shot of Mossy, a moss-covered teapot mascot, weaving through a lantern-lit market at dusk.",
"size": "1280x720",
"seconds": "8",
"characters": [
{ "id": "char_123" }
]
}'
```
## Extend completed videos
Video extensions let you continue an existing completed video and create a new stitched result. Provide the source video in the `video` field to `POST /v1/videos/extensions`, add a prompt describing how the scene should continue, and the API generates the next segment using the full source clip as context.
Use extensions when you want to preserve motion, camera direction, and scene continuity. If you only need to control the opening frame of a new generation, use `input_reference` instead.
Each extension can add up to `20` seconds. A single video can be extended up
to six times, for a maximum total length of `120` seconds. Extensions
currently accept only a source video and prompt. They don't support characters
or image references.
```shell
curl -X POST "https://api.openai.com/v1/videos/extensions" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"video": {
"id": "video_abc123"
},
"prompt": "Continue the scene as the camera rises over the rooftops and reveals the sunrise.",
"seconds": "8"
}'
```
## Edit existing videos
Editing lets you take an existing video and make targeted adjustments without regenerating everything from scratch. Send `POST /v1/videos/edits` with a prompt and a `video` reference, and the system reuses the original structure, continuity, and composition while applying the modification. This works best when you make a single, well-defined change because smaller, focused edits preserve more of the original fidelity and reduce the risk of introducing artifacts.
Video generations could previously be edited using the remix endpoint, which
is being deprecated. Use the edits endpoint for new integrations.
The `video` field accepts either a video ID or an uploaded video. If you pass a
video ID, the API infers the model from the source video.
Editing uploaded videos is only available to eligible customers. Contact your
account manager or [reach out to our sales
team](https://openai.com/contact-sales/) if you need this workflow.
```shell
curl -X POST "https://api.openai.com/v1/videos/edits" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"video": {
"id": "video_abc123"
},
"prompt": "Shift the color palette to teal, sand, and rust, with a warm backlight."
}'
```
If you upload a new video instead of editing an existing generation, set
`model` explicitly in the request.
```shell
curl -X POST "https://api.openai.com/v1/videos/edits" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: multipart/form-data" \
-F "video=@source.mp4;type=video/mp4" \
-F "model=sora-2-pro" \
-F "prompt=Shift the color palette to teal, sand, and rust, with a warm backlight."
```
Editing is especially valuable for iteration because it lets you refine without discarding what already works. By constraining each edit to one clear adjustment, you keep the visual style, subject consistency, and camera framing stable, while still exploring variations in mood, palette, or staging. This makes it far easier to build polished sequences through small, reliable steps.
| Original video | Edited generated video |
| :----------------------------: | :-----------------------------------------------------------------------------: |
| ![][sora_monster_original_gif] | ![][sora_monster_orange] Prompt: _“Change the color of the monster to orange.”_ |
| ![][sora_monster_original_gif] | ![][sora_monster_2monsters] Prompt: _“A second monster comes out right after.”_ |
## Run video jobs through the Batch API
Use the [Batch API](https://developers.openai.com/api/docs/guides/batch) when you need to queue many video renders for offline processing, review pipelines, or studio workflows. Each line in the batch input file uses the same JSON request body you would send to `POST /v1/videos`, which makes it a good fit for shot lists and scheduled render queues.
For video generation in Batch:
- Batch currently supports `POST /v1/videos` only.
- Batch requests must use JSON, not multipart.
- Upload assets ahead of time and reference them from the JSON request body.
- Use `input_reference` for image-guided generations in Batch. In JSON requests, pass `input_reference` as an object with either `file_id` or `image_url`.
- Multipart `input_reference` uploads, including video reference inputs, aren't supported in Batch.
- Batch-generated videos are available for download for up to `24` hours after the batch completes.
```jsonl
{"custom_id":"shot-001","method":"POST","url":"/v1/videos","body":{"model":"sora-2-pro","prompt":"Slow dolly shot through a miniature paper city at blue hour, soft fog, practical window lights flickering on.","size":"1920x1080","seconds":"20"}}
{"custom_id":"shot-002","method":"POST","url":"/v1/videos","body":{"model":"sora-2-pro","prompt":"Portrait close-up of a red panda chef plating noodles in a stainless-steel kitchen, shallow depth of field.","size":"1080x1920","seconds":"16"}}
```
When a batch reaches `completed`, the video jobs in its output have already reached a terminal state such as `completed`, `failed`, or `expired`. Use stable `custom_id` values so you can map batch results back to your internal shot IDs, editorial queue, or asset pipeline, then download final assets with the returned video IDs.
## Maintain your library
Use `GET /videos` to enumerate your videos. The endpoint supports optional query parameters for pagination and sorting.
```shell
curl "https://api.openai.com/v1/videos?limit=20&after=video_123&order=asc" \
-H "Authorization: Bearer $OPENAI_API_KEY" | jq .
```
Use `DELETE /videos/{video_id}` to remove videos you no longer need from OpenAI’s storage.
```shell
curl -X DELETE "https://api.openai.com/v1/videos/REPLACE_WITH_YOUR_VIDEO_ID" \
-H "Authorization: Bearer $OPENAI_API_KEY" | jq .
```
[sora_woman_skyline_original]: https://cdn.openai.com/API/docs/images/sora/sora_woman_skyline_original_2.jpeg
[sora_woman_skyline_video]: https://cdn.openai.com/API/docs/images/sora/sora_woman_skyline_video.gif
[sora_monster_original_jpeg]: https://cdn.openai.com/API/docs/images/sora/sora_monster_original_2.jpeg
[sora_monster_original_gif]: https://cdn.openai.com/API/docs/images/sora/sora_monster_original.gif
[sora_monster_orange]: https://cdn.openai.com/API/docs/images/sora/sora_monster_orange.gif
[sora_monster_2monsters]: https://cdn.openai.com/API/docs/images/sora/sora_monster_2monsters.gif
---
# Vision fine-tuning
Vision fine-tuning uses image inputs for [supervised fine-tuning](https://developers.openai.com/api/docs/guides/supervised-fine-tuning) to improve the model's understanding of image inputs. This guide will take you through this subset of SFT, and outline some of the important considerations for fine-tuning with image inputs.
OpenAI is winding down the fine-tuning platform. The platform is no longer
accessible to new users, but existing users of the fine-tuning platform will
be able to create training jobs for the coming months.
All fine-tuned models will remain available for inference until their base
models are [deprecated](https://developers.openai.com/api/docs/deprecations). The full timeline is
[here](https://developers.openai.com/api/docs/deprecations).
| How it works |
Best for |
Use with |
|
Provide image inputs for supervised fine-tuning to improve the model's understanding of image inputs.
|
- Image classification
- Correcting failures in instruction following for complex prompts
|
`gpt-4o-2024-08-06`
|
## Data format
Just as you can [send one or many image inputs and create model responses based on them](https://developers.openai.com/api/docs/guides/vision), you can include those same message types within your JSONL training data files. Images can be provided either as HTTP URLs or data URLs containing Base64-encoded images.
Here's an example of an image message on a line of your JSONL file. Below, the JSON object is expanded for readability, but typically this JSON would appear on a single line in your data file:
```json
{
"messages": [
{
"role": "system",
"content": "You are an assistant that identifies and describes artworks."
},
{
"role": "user",
"content": "Describe this artwork."
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://api.nga.gov/iiif/a2e6da57-3cd1-4235-b20e-95dcaefed6c8/full/!800,800/0/default.jpg"
}
}
]
},
{
"role": "assistant",
"content": "This appears to be a traditional painted artwork with a central human subject."
}
]
}
```
Uploading training data for vision fine-tuning follows the [same process described here](https://developers.openai.com/api/docs/guides/supervised-fine-tuning).
## Image data requirements
#### Size
- Your training file can contain a maximum of 50,000 examples that contain images (not including text examples).
- Each example can have at most 10 images.
- Each image can be at most 10 MB.
#### Format
- Images must be JPEG, PNG, or WEBP format.
- Your images must be in the RGB or RGBA image mode.
- You cannot include images as output from messages with the `assistant` role.
#### Content moderation policy
We scan your images before training to ensure that they comply with our usage policy. This may introduce latency in file validation before fine-tuning begins.
Images containing the following will be excluded from your dataset and not used for training:
- People
- Faces
- Children
- CAPTCHAs
#### What to do if your images get skipped
Your images can get skipped during training for the following reasons:
- **contains CAPTCHAs**, **contains people**, **contains faces**, **contains children**
- Remove the image. For now, we cannot fine-tune models with images containing these entities.
- **inaccessible URL**
- Ensure that the image URL is publicly accessible.
- **image too large**
- Please ensure that your images fall within our [dataset size limits](#size).
- **invalid image format**
- Please ensure that your images fall within our [dataset format](#format).
## Best practices
#### Reducing training cost
If you set the `detail` parameter for an image to `low`, the image is resized to 512 by 512 pixels and is only represented by 85 tokens regardless of its size. This will reduce the cost of training. [See here for more information.](https://developers.openai.com/api/docs/guides/vision#low-or-high-fidelity-image-understanding)
```json
{
"type": "image_url",
"image_url": {
"url": "https://api.nga.gov/iiif/a2e6da57-3cd1-4235-b20e-95dcaefed6c8/full/!800,800/0/default.jpg",
"detail": "low"
}
}
```
#### Control image quality
To control the fidelity of image understanding, set the `detail` parameter of `image_url` to `low`, `high`, or `auto` for each image. This will also affect the number of tokens per image that the model sees during training time, and will affect the cost of training. [See here for more information](https://developers.openai.com/api/docs/guides/vision#low-or-high-fidelity-image-understanding).
## Safety checks
Before launching in production, review and follow the following safety information.
How we assess for safety
Once a fine-tuning job is completed, we assess the resulting model’s behavior across 13 distinct safety categories. Each category represents a critical area where AI outputs could potentially cause harm if not properly controlled.
| Name | Description |
| :--------------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| advice | Advice or guidance that violates our policies. |
| harassment/threatening | Harassment content that also includes violence or serious harm towards any target. |
| hate | Content that expresses, incites, or promotes hate based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. Hateful content aimed at non-protected groups (e.g., chess players) is harassment. |
| hate/threatening | Hateful content that also includes violence or serious harm towards the targeted group based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. |
| highly-sensitive | Highly sensitive data that violates our policies. |
| illicit | Content that gives advice or instruction on how to commit illicit acts. A phrase like "how to shoplift" would fit this category. |
| propaganda | Praise or assistance for ideology that violates our policies. |
| self-harm/instructions | Content that encourages performing acts of self-harm, such as suicide, cutting, and eating disorders, or that gives instructions or advice on how to commit such acts. |
| self-harm/intent | Content where the speaker expresses that they are engaging or intend to engage in acts of self-harm, such as suicide, cutting, and eating disorders. |
| sensitive | Sensitive data that violates our policies. |
| sexual/minors | Sexual content that includes an individual who is under 18 years old. |
| sexual | Content meant to arouse sexual excitement, such as the description of sexual activity, or that promotes sexual services (excluding sex education and wellness). |
| violence | Content that depicts death, violence, or physical injury. |
Each category has a predefined pass threshold; if too many evaluated examples in a given category fail, OpenAI blocks the fine-tuned model from deployment. If your fine-tuned model does not pass the safety checks, OpenAI sends a message in the fine-tuning job explaining which categories don't meet the required thresholds. You can view the results in the moderation checks section of the fine-tuning job.
How to pass safety checks
In addition to reviewing any failed safety checks in the fine-tuning job object, you can retrieve details about which categories failed by querying the [fine-tuning API events endpoint](https://platform.openai.com/docs/api-reference/fine-tuning/list-events). Look for events of type `moderation_checks` for details about category results and enforcement. This information can help you narrow down which categories to target for retraining and improvement. The [model spec](https://cdn.openai.com/spec/model-spec-2024-05-08.html#overview) has rules and examples that can help identify areas for additional training data.
While these evaluations cover a broad range of safety categories, conduct your own evaluations of the fine-tuned model to ensure it's appropriate for your use case.
## Next steps
Now that you know the basics of vision fine-tuning, explore these other methods as well.
[
Fine-tune a model by providing correct outputs for sample inputs.
](https://developers.openai.com/api/docs/guides/supervised-fine-tuning)
[
Fine-tune a model using direct preference optimization (DPO).
](https://developers.openai.com/api/docs/guides/direct-preference-optimization)
[
Fine-tune a reasoning model by grading its outputs.
](https://developers.openai.com/api/docs/guides/reinforcement-fine-tuning)
---
# Voice activity detection (VAD)
Voice activity detection (VAD) is a feature available in the Realtime API allowing to automatically detect when the user has started or stopped speaking.
It is enabled by default in [speech-to-speech](https://developers.openai.com/api/docs/guides/realtime-conversations) or [transcription](https://developers.openai.com/api/docs/guides/realtime-transcription) Realtime sessions, but is optional and can be turned off.
## Overview
When VAD is enabled, the audio is chunked automatically and the Realtime API sends events to indicate when the user has started or stopped speaking:
- `input_audio_buffer.speech_started`: The start of a speech turn
- `input_audio_buffer.speech_stopped`: The end of a speech turn
You can use these events to handle speech turns in your application. For example, you can use them to manage conversation state or process transcripts in chunks.
You can use the `turn_detection` property of the `session.update` event to configure how audio is chunked within each speech-to-text sample.
There are two modes for VAD:
- `server_vad`: Automatically chunks the audio based on periods of silence.
- `semantic_vad`: Chunks the audio when the model believes based on the words said by the user that they have completed their utterance.
The default value is `server_vad`.
Read below to learn more about the different modes.
## Server VAD
Server VAD is the default mode for Realtime sessions, and uses periods of silence to automatically chunk the audio.
You can adjust the following properties to fine-tune the VAD settings:
- `threshold`: Activation threshold (0 to 1). A higher threshold will require louder audio to activate the model, and thus might perform better in noisy environments.
- `prefix_padding_ms`: Amount of audio (in milliseconds) to include before the VAD detected speech.
- `silence_duration_ms`: Duration of silence (in milliseconds) to detect speech stop. With shorter values turns will be detected more quickly.
Here is an example VAD configuration:
```json
{
"type": "session.update",
"session": {
"turn_detection": {
"type": "server_vad",
"threshold": 0.5,
"prefix_padding_ms": 300,
"silence_duration_ms": 500,
"create_response": true, // only in conversation mode
"interrupt_response": true // only in conversation mode
}
}
}
```
## Semantic VAD
Semantic VAD is a new mode that uses a semantic classifier to detect when the user has finished speaking, based on the words they have uttered.
This classifier scores the input audio based on the probability that the user is done speaking. When the probability is low, the model will wait for a timeout, whereas when it is high, there is no need to wait.
For example, user audio that trails off with an "ummm..." would result in a longer timeout than a definitive statement.
With this mode, the model is less likely to interrupt the user during a speech-to-speech conversation, or chunk a transcript before the user is done speaking.
Semantic VAD can be activated by setting `turn_detection.type` to `semantic_vad` in a [`session.update`](https://developers.openai.com/api/docs/api-reference/realtime-client-events/session/update) event.
It can be configured like this:
```json
{
"type": "session.update",
"session": {
"turn_detection": {
"type": "semantic_vad",
"eagerness": "low" | "medium" | "high" | "auto", // optional
"create_response": true, // only in conversation mode
"interrupt_response": true, // only in conversation mode
}
}
}
```
The optional `eagerness` property is a way to control how eager the model is to interrupt the user, tuning the maximum wait timeout. In transcription mode, even if the model doesn't reply, it affects how the audio is chunked.
- `auto` is the default value, and is equivalent to `medium`.
- `low` will let the user take their time to speak.
- `high` will chunk the audio as soon as possible.
If you want the model to respond more often in conversation mode, or to return transcription events faster in transcription mode, you can set `eagerness` to `high`.
On the other hand, if you want to let the user speak uninterrupted in conversation mode, or if you would like larger transcript chunks in transcription mode, you can set `eagerness` to `low`.
---
# Voice agents
import {
Bolt,
Cube,
Desktop,
Phone,
} from "@components/react/oai/platform/ui/Icon.react";
Voice agents turn the same agent concepts into spoken, low-latency interactions. The key design choice is deciding whether the model should work directly with live audio or whether your application should explicitly chain speech-to-text, text reasoning, and text-to-speech.
## Choose the right architecture
| Architecture | Best for | Why |
| ----------------------------------------- | --------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| Speech-to-speech with live audio sessions | Natural, low-latency conversations | The model handles live audio input and output directly |
| Chained voice pipeline | Predictable workflows or extending an existing text agent | Your app keeps explicit control over transcription, text reasoning, and speech output |
Agent Builder doesn't currently support voice workflows, so voice stays an SDK-first surface.
## Recommended starting points
The examples below are intentionally different architectures, not matching language tabs. The TypeScript and Python libraries expose different voice helpers today:
- In TypeScript, the fastest path to a browser-based voice assistant is a `RealtimeAgent` and `RealtimeSession`.
- In Python, the simplest path to extending an existing text agent into voice is a chained `VoicePipeline`.
## Build a speech-to-speech voice agent
Use the live audio API path when the interaction should feel conversational and immediate. This is the best starting point for voice agents that need barge-in, low first-audio latency, natural turn taking, and realtime tool use.
The usual browser flow is:
1. Your application server creates an ephemeral client secret for the live audio session.
2. Your frontend creates a `RealtimeSession`.
3. The session connects over WebRTC in the browser or WebSocket on the server.
4. The agent handles audio turns, tools, interruptions, and handoffs inside that session.
From there, attach tools, handoffs, and guardrails to the `RealtimeAgent` the same way you would attach them to a text agent. Keep audio transport concerns in the session layer, and keep business logic in the agent definition.
Start with the transport docs when you need lower-level control:
- [Realtime and audio overview](https://developers.openai.com/api/docs/guides/realtime)
- [Live audio API with WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc)
- [Live audio API with WebSocket](https://developers.openai.com/api/docs/guides/realtime-websocket)
## Build a chained voice workflow
Use the chained path when you want stronger control over intermediate text, existing text-agent reuse, or a simpler extension path from a non-voice workflow. In that design, your application explicitly manages:
1. speech-to-text
2. the agent workflow itself
3. text-to-speech
This is often the better fit for support flows, approval-heavy flows, or cases where you want durable transcripts and deterministic logic between each stage.
Use this path when each stage needs to be visible or replaceable. For example, you might store the transcript, run policy checks before the text agent responds, call internal systems, then generate speech only after the workflow reaches an approved answer.
## Voice agents still use the same core agent building blocks
The voice surface changes the transport and audio loop, but the core workflow decisions are the same:
- Use [Using tools](https://developers.openai.com/api/docs/guides/tools#usage-in-the-agents-sdk) when the voice agent needs external capabilities.
- Use [Running agents](https://developers.openai.com/api/docs/guides/agents/running-agents) when spoken workflows need streaming, continuation, or durable state.
- Use [Orchestration and handoffs](https://developers.openai.com/api/docs/guides/agents/orchestration) when spoken workflows branch across specialists.
- Use [Guardrails and human review](https://developers.openai.com/api/docs/guides/agents/guardrails-approvals) when spoken workflows need safety checks or approvals.
- Use [Integrations and observability](https://developers.openai.com/api/docs/guides/agents/integrations-observability) when you need MCP-backed capabilities or want to inspect how the voice workflow behaved.
The practical rule is: choose the audio architecture first, then design the rest of the agent workflow the same way you would for text.
## Next steps
Choose the right realtime or audio guide for your use case.
Work with the Realtime session lifecycle and event model.
Connect browser and mobile audio directly to a Realtime session.
Tune reasoning, preambles, tools, entity capture, and voice behavior.
---
# Web search
import {
CheckCircleFilled,
XCircle,
} from "@components/react/oai/platform/ui/Icon.react";
import {
customUserLocationExampleCoarse,
customUserLocationExampleCoarseChat,
listSourcesExample,
returnTokenBudgetExample,
searchContextSize,
} from "./web-search-examples";
Web search allows models to access up-to-date information from the internet and provide answers with sourced citations. To enable this, use the web search tool in the Responses API or, in some cases, Chat Completions.
There are three main types of web search available with OpenAI models:
1. Non‑reasoning web search: The non-reasoning model sends the user’s query to the web search tool, which returns the response based on top results. There’s no internal planning and the model simply passes along the search tool’s responses. This method is fast and ideal for quick lookups.
2. Agentic search with reasoning models is an approach where the model actively manages the search process. It can perform web searches as part of its chain of thought, analyze results, and decide whether to keep searching. This flexibility makes agentic search well suited to complex workflows, but it also means searches take longer than quick lookups. For example, you can adjust reasoning levels on models like `gpt-5.5` to change both the depth and latency of the search.
3. Deep research is a specialized, agent-driven method for in-depth, extended investigations by reasoning models. The model conducts web searches as part of its chain of thought, often tapping into hundreds of sources. Deep research can run for several minutes and is best used with background mode. Use `gpt-5.5` with reasoning set to `high` or `xhigh`.
## Choose an integration
| Use case | Recommended path | Notes |
| --------------------------------------------- | --------------------------------------------- | ----------------------------------------------------------------------------------------------------------- |
| New web search integration | Responses API with `web_search` and `gpt-5.5` | Supports hosted web search controls such as filters, sources, live-access control, and longer research runs |
| Existing Chat Completions search integration | Chat Completions with `gpt-5-search-api` | Use this only when you need to preserve a Chat Completions integration |
| Multi-step research or long-running reporting | `gpt-5.5` with `high` or `xhigh` reasoning | Use background mode for reports that can take several minutes |
Using the [Responses API](https://developers.openai.com/api/docs/api-reference/responses), you can enable web search by configuring it in the `tools` array in an API request to generate content. Like any other tool, the model can choose to search the web or not based on the content of the input prompt.
For new Responses API integrations, use `{ "type": "web_search" }`. The earlier `web_search_preview` tool remains available for legacy integrations, but it does not support newer controls such as `filters`, `external_web_access`, and `return_token_budget`.
## Output and citations
Model responses that use the web search tool will include two parts:
- A `web_search_call` output item with the ID of the search call, along with the action taken in `web_search_call.action`. The action is one of:
- `search`, which represents a web search. It will usually (but not always) includes the search `queries` which were searched. Search actions incur a tool call cost (see [pricing](https://developers.openai.com/api/docs/pricing#built-in-tools)).
- `open_page`, which represents a page being opened. Supported in reasoning models.
- `find_in_page`, which represents searching within a page. Supported in reasoning models.
- A `message` output item containing:
- The text result in `message.content[0].text`
- Annotations `message.content[0].annotations` for the cited URLs
By default, the model's response will include inline citations for URLs found in the web search results. In addition to this, the `url_citation` annotation object will contain the URL, title and location of the cited source.
When displaying web results or information contained in web results to end
users, inline citations must be made clearly visible and clickable in your
user interface.
```json
[
{
"type": "web_search_call",
"id": "ws_67c9fa0502748190b7dd390736892e100be649c1a5ff9609",
"status": "completed",
"action": {
"type": "search",
"query": "latest news about AI"
}
},
{
"id": "msg_67c9fa077e288190af08fdffda2e34f20be649c1a5ff9609",
"type": "message",
"status": "completed",
"role": "assistant",
"content": [
{
"type": "output_text",
"text": "On March 6, 2025, several news...",
"annotations": [
{
"type": "url_citation",
"start_index": 2606,
"end_index": 2758,
"url": "https://...",
"title": "Title..."
}
]
}
]
}
]
```
## Migrating from legacy web search
| If you use | Recommended path | Notes |
| ------------------------------------------------------- | ------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------- |
| `web_search_preview` in Responses | Migrate to `web_search` | `web_search` supports newer controls such as `filters`, `external_web_access`, and `return_token_budget` |
| `gpt-4o-search-preview` or `gpt-4o-mini-search-preview` | Migrate to Responses `web_search`, or use `gpt-5-search-api` if you must stay on Chat Completions | The preview search models are deprecated and shut down on 2026-07-23 |
| Chat Completions search integrations | Use `gpt-5-search-api`, or migrate to Responses `web_search` for more tool controls and optional search | Chat Completions search models always search before responding; Responses search is a tool |
## Search context size
`search_context_size` controls how much context from web search results is made available to the model before it generates a response. Use `low` for simple lookups, `medium` for a balanced default, and `high` when the answer may require more detail from search results. This setting does not set an exact token count or guarantee a specific number of sources or citations.
## Run longer web research
`return_token_budget` controls how much web search result content the tool can return during a Responses API search run with GPT-5+ reasoning models. Keep the default for most requests. Set it to `unlimited` only for high-effort research or evaluation runs that need to inspect many pages and might otherwise stop at the standard returned-token cap.
Use `unlimited` selectively because it can increase latency and cost. For long-running multi-search tasks, use background mode (`background: true`) so the request can keep running asynchronously and you can retrieve the final response later.
| Value | Behavior |
| ----------- | ---------------------------------------------------------------------------------------------------------------------------- |
| `default` | Uses the standard returned-token budget for web search results. This is the same behavior as omitting `return_token_budget`. |
| `unlimited` | Removes the default returned-token budget for the web search run. |
This parameter applies only to the hosted Responses API `web_search` tool with GPT-5+ reasoning web search. It does not change the search context window, and it does not apply to non-reasoning web search, legacy Search API paths, container web search, Chat Completions search models, or `web_search_preview`. Only `default` and `unlimited` are supported values; `null`, numbers, and other strings are rejected.
## Domain filtering
Domain filtering in web search lets you limit results to a specific set of domains. With the `filters` parameter you can configure up to 100 `allowed_domains` or up to 100 `blocked_domains`. When formatting domains, omit the HTTP or HTTPS prefix. For example, use `openai.com` instead of `https://openai.com/`. This approach also includes subdomains in the search. Note that domain filtering is only available in the Responses API with the `web_search` tool.
## Sources
To view all URLs retrieved during a web search, use the `sources` field. Unlike inline citations, which show only the most relevant references, sources returns the complete list of URLs the model consulted when forming its response.
The number of sources is often greater than the number of citations. Real-time third-party feeds are also surfaced here and are labeled as `oai-sports`, `oai-weather`, or `oai-finance`. The sources field is available with both the `web_search` and `web_search_preview` tools.
## User location
To refine search results based on geography, you can specify an approximate user location using country, city, region, and/or timezone.
- The `city` and `region` fields are free text strings, like `Minneapolis` and `Minnesota` respectively.
- The `country` field is a two-letter [ISO country code](https://en.wikipedia.org/wiki/ISO_3166-1), like `US`.
- The `timezone` field is an [IANA timezone](https://timeapi.io/documentation/iana-timezones) like `America/Chicago`.
Note that user location is not supported for deep research models using web
search.
## Live internet access
Control whether the web search tool fetches live content or uses only cached/indexed results in the Responses API.
- Set `external_web_access: false` on the `web_search` tool to run in offline/cache‑only mode.
- Default is `true` (live access) if you do not set it.
- Preview variants (`web_search_preview`) ignore this parameter and behave as if `external_web_access` is `true`.
## Limitations
#### Chat Completions API
The Chat Completions API supports only specialized search models for web search. These models do not support Responses API `web_search` features such as domain filters, complete source lists, live-access control, and returned-token budget control.
| Model | Context window | Limitation |
| ---------------------------- | -------------: | -------------------------------------------------------------------------------------------------------------------------------------------- |
| `gpt-5-search-api` | 200k | Uses the Chat Completions search model path |
| `gpt-4o-search-preview` | 128k | Uses the Chat Completions search model path; [deprecated, shutdown 2026-07-23](https://developers.openai.com/api/docs/deprecations#2026-04-22-legacy-gpt-model-snapshots) |
| `gpt-4o-mini-search-preview` | 128k | Uses the Chat Completions search model path; [deprecated, shutdown 2026-07-23](https://developers.openai.com/api/docs/deprecations#2026-04-22-legacy-gpt-model-snapshots) |
#### Responses API
Use the hosted `web_search` tool. The Responses API still accepts `web_search_preview` for legacy integrations, but use `web_search` for new integrations.
For a larger model context window, use `gpt-5.5`. The web search context window remains 128k.
| Model | Model context window | Limitation |
| -------------- | -------------------: | ---------------------------------------------------------------------------------------------------------------------------------- |
| `gpt-4.1` | 1M | Search context is limited to 128k |
| `gpt-4.1-mini` | 1M | Search context is limited to 128k |
| `o4-mini` | 200k | Search context is limited to 128k; [deprecated, shutdown 2026-10-23](https://developers.openai.com/api/docs/deprecations#2026-04-22-legacy-gpt-model-snapshots) |
For Responses API web search, the search context window is limited to 128k, even when the model context window is larger.
- Web search does not support [`gpt-5`](https://developers.openai.com/api/docs/models/gpt-5) with `minimal` reasoning.
- [`gpt-5.4`](https://developers.openai.com/api/docs/models/gpt-5.4) with reasoning effort set to `none` may produce lower-quality results.
- Responses API web search uses the underlying model's tiered rate limits.
- `web_search_preview` does not support `filters` or `return_token_budget`, and ignores `external_web_access`.
- With `tool_choice: "auto"`, search is optional. Use `tool_choice: "required"` or a specific web search tool choice when search must run.
## Usage notes
| API Availability |
Rate limits |
Notes |
|
[Responses](https://developers.openai.com/api/docs/api-reference/responses)
[Chat Completions](https://developers.openai.com/api/docs/api-reference/chat)
[Assistants](https://developers.openai.com/api/docs/api-reference/assistants)
|
Same as tiered rate limits for underlying [model](https://developers.openai.com/api/docs/models) used
with the tool.
|
[Pricing](https://developers.openai.com/api/docs/pricing#built-in-tools)
[ZDR and data residency](https://developers.openai.com/api/docs/guides/your-data)
|
---
# Webhooks
OpenAI [webhooks](http://chatgpt.com/?q=eli5+what+is+a+webhook?) allow you to receive real-time notifications about events in the API, such as when a batch completes, a background response is generated, or a fine-tuning job finishes. Webhooks are delivered to an HTTP endpoint you control, following the [Standard Webhooks specification](https://github.com/standard-webhooks/standard-webhooks/blob/main/spec/standard-webhooks.md). The full list of webhook events can be found in the [API reference](https://developers.openai.com/api/docs/api-reference/webhook-events).
[
View the full list of webhook events.
](https://developers.openai.com/api/docs/api-reference/webhook-events)
Below are examples of simple servers capable of ingesting webhooks from OpenAI, specifically for the [`response.completed`](https://developers.openai.com/api/docs/api-reference/webhook-events/response/completed) event.
Webhooks server
```python
import os
from openai import OpenAI, InvalidWebhookSignatureError
from flask import Flask, request, Response
app = Flask(__name__)
client = OpenAI(webhook_secret=os.environ["OPENAI_WEBHOOK_SECRET"])
@app.route("/webhook", methods=["POST"])
def webhook():
try:
# with webhook_secret set above, unwrap will raise an error if the signature is invalid
event = client.webhooks.unwrap(request.data, request.headers)
if event.type == "response.completed":
response_id = event.data.id
response = client.responses.retrieve(response_id)
print("Response output:", response.output_text)
return Response(status=200)
except InvalidWebhookSignatureError as e:
print("Invalid signature", e)
return Response("Invalid signature", status=400)
if __name__ == "__main__":
app.run(port=8000)
```
```javascript
import OpenAI from "openai";
import express from "express";
const app = express();
const client = new OpenAI({ webhookSecret: process.env.OPENAI_WEBHOOK_SECRET });
// Don't use express.json() because signature verification needs the raw text body
app.use(express.text({ type: "application/json" }));
app.post("/webhook", async (req, res) => {
try {
const event = await client.webhooks.unwrap(req.body, req.headers);
if (event.type === "response.completed") {
const response_id = event.data.id;
const response = await client.responses.retrieve(response_id);
const output_text = response.output
.filter((item) => item.type === "message")
.flatMap((item) => item.content)
.filter((contentItem) => contentItem.type === "output_text")
.map((contentItem) => contentItem.text)
.join("");
console.log("Response output:", output_text);
}
res.status(200).send();
} catch (error) {
if (error instanceof OpenAI.InvalidWebhookSignatureError) {
console.error("Invalid signature", error);
res.status(400).send("Invalid signature");
} else {
throw error;
}
}
});
app.listen(8000, () => {
console.log("Webhook server is running on port 8000");
});
```
To see a webhook like this one in action, you can set up a webhook endpoint in the OpenAI dashboard subscribed to `response.completed`, and then make an API request to [generate a response in background mode](https://developers.openai.com/api/docs/guides/background).
You can also trigger test events with sample data from the [webhook settings page](https://platform.openai.com/settings/project/webhooks).
Generate a background response
```bash
curl https://api.openai.com/v1/responses \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-5.5",
"input": "Write a very long novel about otters in space.",
"background": true
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const resp = await client.responses.create({
model: "gpt-5.5",
input: "Write a very long novel about otters in space.",
background: true,
});
console.log(resp.status);
```
```python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-5.5",
input="Write a very long novel about otters in space.",
background=True,
)
print(resp.status)
```
In this guide, you will learn how to create webook endpoints in the dashboard, set up server-side code to handle them, and verify that inbound requests originated from OpenAI.
## Creating webhook endpoints
To start receiving webhook requests on your server, log in to the dashboard and [open the webhook settings page](https://platform.openai.com/settings/project/webhooks). Webhooks are configured per-project.
Click the "Create" button to create a new webhook endpoint. You will configure three things:
- A name for the endpoint (just for your reference).
- A public URL to a server you control.
- One or more event types to subscribe to. When they occur, OpenAI will send an HTTP POST request to the URL specified.
 After creating a new webhook, you'll receive a signing secret to use for server-side verification of incoming webhook requests. Save this value for later, since you won't be able to view it again.
With your webhook endpoint created, you'll next set up a server-side endpoint to handle those incoming event payloads.
## Handling webhook requests on a server
When an event happens that you're subscribed to, your webhook URL will receive an HTTP POST request like this:
```
POST https://yourserver.com/webhook
user-agent: OpenAI/1.0 (+https://platform.openai.com/docs/webhooks)
content-type: application/json
webhook-id: wh_685342e6c53c8190a1be43f081506c52
webhook-timestamp: 1750287078
webhook-signature: v1,K5oZfzN95Z9UVu1EsfQmfVNQhnkZ2pj9o9NDN/H/pI4=
{
"object": "event",
"id": "evt_685343a1381c819085d44c354e1b330e",
"type": "response.completed",
"created_at": 1750287018,
"data": { "id": "resp_abc123" }
}
```
Your endpoint should respond quickly to these incoming HTTP requests with a successful (`2xx`) status code, indicating successful receipt. To avoid timeouts, we recommend offloading any non-trivial processing to a background worker so that the endpoint can respond immediately.
If the endpoint doesn't return a successful (`2xx`) status code, or doesn't respond within a few seconds, the webhook request will be retried. OpenAI will continue to attempt delivery for up to 72 hours with exponential backoff. Note that `3xx` redirects will not be followed; they are treated as failures and your endpoint should be updated to use the final destination URL.
In rare cases, due to internal system issues, OpenAI may deliver duplicate copies of the same webhook event. You can use the `webhook-id` header as an idempotency key to deduplicate.
### Testing webhooks locally
Testing webhooks requires a URL that is available on the public Internet. This can make development tricky, since your local development environment likely isn't open to the public. A few options that may help:
- [ngrok](https://ngrok.com/) which can expose your localhost server on a public URL
- Cloud development environments like [Replit](https://replit.com/), [GitHub Codespaces](https://github.com/features/codespaces), [Cloudflare Workers](https://workers.cloudflare.com/), or [v0 from Vercel](https://v0.dev/).
## Verifying webhook signatures
While you can receive webhook events from OpenAI and process the results without any verification, you should verify that incoming requests are coming from OpenAI, especially if your webhook will take any kind of action on the backend. The headers sent along with webhook requests contain information that can be used in combination with a webhook secret key to verify that the webhook originated from OpenAI.
When you create a webhook endpoint in the OpenAI dashboard, you'll be given a signing secret that you should make available on your server as an environment variable:
```
export OPENAI_WEBHOOK_SECRET=""
```
The simplest way to verify webhook signatures is by using the `unwrap()` method of the official OpenAI SDK helpers:
Signature verification with the OpenAI SDK
```python
client = OpenAI()
webhook_secret = os.environ["OPENAI_WEBHOOK_SECRET"]
# will raise if the signature is invalid
event = client.webhooks.unwrap(request.data, request.headers, secret=webhook_secret)
```
```javascript
const client = new OpenAI();
const webhook_secret = process.env.OPENAI_WEBHOOK_SECRET;
// will throw if the signature is invalid
const event = client.webhooks.unwrap(req.body, req.headers, { secret: webhook_secret });
```
Signatures can also be verified with the [Standard Webhooks libraries](https://github.com/standard-webhooks/standard-webhooks/tree/main?tab=readme-ov-file#reference-implementations):
Signature verification with Standard Webhooks libraries
```rust
use standardwebhooks::Webhook;
let webhook_secret = std::env::var("OPENAI_WEBHOOK_SECRET").expect("OPENAI_WEBHOOK_SECRET not set");
let wh = Webhook::new(webhook_secret);
wh.verify(webhook_payload, webhook_headers).expect("Webhook verification failed");
```
```php
$webhook_secret = getenv("OPENAI_WEBHOOK_SECRET");
$wh = new \\StandardWebhooks\\Webhook($webhook_secret);
$wh->verify($webhook_payload, $webhook_headers);
```
Alternatively, if needed, you can implement your own signature verification [as described in the Standard Webhooks spec](https://github.com/standard-webhooks/standard-webhooks/blob/main/spec/standard-webhooks.md#verifying-webhook-authenticity)
If you misplace or accidentally expose your signing secret, you can generate a new one by [rotating the signing secret](https://platform.openai.com/settings/project/webhooks).
---
# Webhooks and server-side controls
The Realtime API allows clients to connect directly to the API server via WebRTC or SIP. However, you'll most likely want tool use and other business logic to reside on your application server to keep this logic private and client-agnostic.
Keep tool use, business logic, and other details secure on the server side by connecting over a “sideband” control channel. We now have sideband options for both SIP and WebRTC connections.
A sideband connection means there are two active connections to the same Realtime session: one from the user's client and one from your application server. The server connection can be used to monitor the session, update instructions, and respond to tool calls.
## With WebRTC
1. When [establishing a peer connection](https://developers.openai.com/api/docs/guides/realtime-webrtc) you fetch and receive an SDP response from the Realtime API to configure the connection. If you used the sample code from the WebRTC guide, that looks something like this:
```javascript
const baseUrl = "https://api.openai.com/v1/realtime/calls";
const sdpResponse = await fetch(baseUrl, {
method: "POST",
body: offer.sdp,
headers: {
Authorization: `Bearer ${EPHEMERAL_KEY}`,
"Content-Type": "application/sdp",
},
});
```
2. The fetch response will contain a `Location` header that has a unique call ID that can be used on the server to establish a WebSocket connection to that same Realtime session.
```javascript
// Location: /v1/realtime/calls/rtc_123456
const location = sdpResponse.headers.get("Location");
const callId = location?.split("/").pop();
console.log(callId);
```
3. On a server, you can then [listen for events and configure the session](https://developers.openai.com/api/docs/guides/realtime-conversations) just as you would from a typical Realtime API WebSocket connection, using that call ID with the URL
`wss://api.openai.com/v1/realtime?call_id=rtc_xxxxx`, as shown below:
```javascript
const callId = "rtc_u1_9c6574da8b8a41a18da9308f4ad974ce";
// Connect to a WebSocket for the in-progress call
const url = "wss://api.openai.com/v1/realtime?call_id=" + callId;
const ws = new WebSocket(url, {
headers: {
Authorization: "Bearer " + process.env.OPENAI_API_KEY,
},
});
ws.on("open", function open() {
console.log("Connected to server.");
// Send client events over the WebSocket once connected
ws.send(
JSON.stringify({
type: "session.update",
session: {
type: "realtime",
instructions: "Be extra nice today!",
},
})
);
});
// Listen for and parse server events
ws.on("message", function incoming(message) {
console.log(JSON.parse(message.toString()));
});
```
In this way, you are able to add tools, monitor sessions, and carry out business logic on the server instead of needing to configure those actions on the client.
## With SIP
1. A user connects to OpenAI via phone over SIP.
2. OpenAI sends a webhook to your application’s server webhook URL, notifying your app of the state of the session. The webhook will look something like:
```json
POST https://my_website.com/webhook_endpoint
user-agent: OpenAI/1.0 (+https://platform.openai.com/docs/webhooks)
content-type: application/json
webhook-id: wh_685342e6c53c8190a1be43f081506c52 # unique id for idempotency
webhook-timestamp: 1750287078 # timestamp of delivery attempt
webhook-signature: v1,K5oZfzN95Z9UVu1EsfQmfVNQhnkZ2pj9o9NDN/H/pI4= # signature to verify authenticity from OpenAI
{
"object": "event",
"id": "evt_685343a1381c819085d44c354e1b330e",
"type": "realtime.call.incoming",
"created_at": 1750287018, // Unix timestamp
"data": {
"call_id": "some_unique_id",
"sip_headers": [
{ "name": "From", "value": "sip:+142555512112@sip.example.com" },
{ "name": "To", "value": "sip:+18005551212@sip.example.com" },
{ "name": "Call-ID", "value": "03782086-4ce9-44bf-8b0d-4e303d2cc590"}
]
}
}
```
3. The application server opens a WebSocket connection to the Realtime API using the `call_id` value provided in the webhook, via a URL like this: `wss://api.openai.com/v1/realtime?call_id={callId}`. The WebSocket connection will live for the life of the SIP call.
The WebSocket connection can then be used to send and receive events to control the call, just as you would if the session was initiated with a WebSocket connection. This includes monitoring the call, updating instructions dynamically, and responding to tool calls.
---
# WebSocket Mode
The Responses API supports a WebSocket mode for long-running, tool-call-heavy workflows. In this mode, you keep a persistent connection to `/v1/responses` and continue each turn by sending only new input items plus `previous_response_id`.
WebSocket mode is compatible with both Zero Data Retention (ZDR) and `store=false`.
## Why use WebSocket mode
WebSocket mode is most useful when a workflow involves many model-tool round trips (for example, agentic coding or orchestration loops with repeated tool calls).
Because the connection stays open and each turn sends only incremental input, WebSocket mode reduces per-turn continuation overhead and improves end-to-end latency across long chains. For rollouts with 20+ tool calls, we have seen up to roughly 40% faster end-to-end execution.
## Connect and create responses
In WebSocket mode, start each turn by sending a `response.create` event from the client. The payload mirrors the normal [Responses create body](https://developers.openai.com/api/reference/resources/responses/methods/create), except that transport-specific fields like `stream` and `background` are not used.
```python
from websocket import create_connection
import json
import os
ws = create_connection(
"wss://api.openai.com/v1/responses",
header=[
f"Authorization: Bearer {os.environ['OPENAI_API_KEY']}",
],
)
ws.send(
json.dumps(
{
"type": "response.create",
"model": "gpt-5.5",
"store": False,
"input": [
{
"type": "message",
"role": "user",
"content": [{"type": "input_text", "text": "Find fizz_buzz()"}],
}
],
"tools": [],
}
)
)
```
Clients can optionally warm up request state by sending `response.create` with `generate: false`. This is useful when you already know the tools, instructions, and/or custom messages you plan to send with an upcoming turn. `generate: false` does not return a model output, but prepares request state so the next generated turn can start faster. The warmup request returns a response ID that you can chain from with `previous_response_id`, including on later turns in a response chain. The next section explains how to continue a session using `previous_response_id` and incremental inputs.
## Continue with incremental inputs
To continue a run, send another `response.create` with:
- `previous_response_id` set to the prior response ID.
- `input` containing only new items (for example, tool outputs and the next user message).
```python
ws.send(
json.dumps(
{
"type": "response.create",
"model": "gpt-5.5",
"store": False,
"previous_response_id": "resp_123",
"input": [
{
"type": "function_call_output",
"call_id": "call_123",
"output": "tool result",
},
{
"type": "message",
"role": "user",
"content": [{"type": "input_text", "text": "Now optimize it."}],
},
],
"tools": [],
}
)
)
```
## How continuation works
WebSocket mode uses the same `previous_response_id` chaining semantics as HTTP mode, but it adds a lower-latency continuation path on the active socket.
On an active WebSocket connection, the service keeps one previous-response state in a connection-local in-memory cache (the most recent response). Continuing from that most recent response is fast because the service can reuse connection-local state. Because the previous-response state is retained only in memory and is not written to disk, you can use WebSocket mode in a way that is compatible with `store=false` and Zero Data Retention (ZDR).
If a `previous_response_id` is not in the in-memory cache, behavior depends on whether you store responses:
- With `store=true`, the service may hydrate older response IDs from persisted state when available. Continuation can still work, but it usually loses the in-memory latency benefit.
- With `store=false` (including ZDR), there is no persisted fallback. If the ID is uncached, the request returns `previous_response_not_found`.
If a turn fails (`4xx` or `5xx`), the service evicts the referenced `previous_response_id` from the connection-local cache. This prevents reusing stale cached state for that failed continuation.
## Compaction and creating new responses
If you are using compaction, there are two different continuation patterns:
### Server-side compaction (`context_management`)
When you enable server-side compaction (`context_management` with `compact_threshold`), compaction happens during normal `/responses` generation. In WebSocket mode, you continue the same way you normally do: send the next `response.create` with the latest `previous_response_id` and only new input items.
### Standalone `/responses/compact`
The standalone [`/responses/compact` endpoint](https://developers.openai.com/api/docs/api-reference/responses/compact) returns a new compacted input window, not a response ID. After compaction, create a new response on your WebSocket connection using the compacted window as `input` (plus the next user/tool items).
Start a new chain by omitting `previous_response_id` or setting it to `null`. Pass the compacted output as-is; do not prune the returned window.
```python
# Compact your current window (HTTP call)
compacted = client.responses.compact(
model="gpt-5.5",
input=long_input_items_array,
)
# Start a new response on the WebSocket using the compacted window
ws.send(
json.dumps(
{
"type": "response.create",
"model": "gpt-5.5",
"store": False,
"input": [
*compacted.output,
{
"type": "message",
"role": "user",
"content": [{"type": "input_text", "text": "Continue from here."}],
},
],
"tools": [],
}
)
)
```
## Connection behavior and limits
- Server events and ordering match the existing Responses streaming event model.
- A single WebSocket connection can receive multiple `response.create` messages, but it runs them sequentially (one in-flight response at a time).
- No multiplexing support today. Use multiple connections if you need parallel runs.
- Connection duration is limited to 60 minutes. Reconnect when the limit is reached.
## Reconnect and recover
When a connection closes (or hits the 60-minute limit), open a new WebSocket connection and continue with one of these patterns:
1. If your prior response is persisted (`store=true`) and you have a valid response ID, continue with `previous_response_id` and new input items.
2. If you cannot continue the chain (for example, `store=false`/ZDR or `previous_response_not_found`), start a new response by setting `previous_response_id` to `null` (or omitting it) and send the full input context for the next turn.
3. If you compacted context with `/responses/compact`, use the returned compacted window as the base `input` for that new response, then append the latest user/tool items.
## Errors to handle
`previous_response_not_found`
```json
{
"type": "error",
"status": 400,
"error": {
"code": "previous_response_not_found",
"message": "Previous response with id 'resp_abc' not found.",
"param": "previous_response_id"
}
}
```
`websocket_connection_limit_reached`
```json
{
"type": "error",
"error": {
"type": "invalid_request_error",
"code": "websocket_connection_limit_reached",
"message": "Responses websocket connection limit reached (60 minutes). Create a new websocket connection to continue."
},
"status": 400
}
```
## Related guides
- [Conversation state](https://developers.openai.com/api/docs/guides/conversation-state)
- [Streaming API responses](https://developers.openai.com/api/docs/guides/streaming-responses)
- [Responses streaming events reference](https://developers.openai.com/api/docs/api-reference/responses-streaming)
---
# Working with evals
Evaluations (often called **evals**) test model outputs to ensure they meet style and content criteria that you specify. Writing evals to understand how your LLM applications are performing against your expectations, especially when upgrading or trying new models, is an essential component to building reliable applications.
In this guide, we will focus on **configuring evals programmatically using the [Evals API](https://developers.openai.com/api/docs/api-reference/evals)**. If you prefer, you can also configure evals [in the OpenAI dashboard](https://platform.openai.com/evaluations).
If you're new to evaluations, or want a more iterative environment to
experiment in as you build your eval, consider trying
[Datasets](https://developers.openai.com/api/docs/guides/evaluation-getting-started) instead.
Broadly, there are three steps to build and run evals for your LLM application.
1. Describe the task to be done as an eval
1. Run your eval with test inputs (a prompt and input data)
1. Analyze the results, then iterate and improve on your prompt
This process is somewhat similar to behavior-driven development (BDD), where you begin by specifying how the system should behave before implementing and testing the system. Let's see how we would complete each of the steps above using the [Evals API](https://developers.openai.com/api/docs/api-reference/evals).
## Create an eval for a task
Creating an eval begins by describing a task to be done by a model. Let's say that we would like to use a model to classify the contents of IT support tickets into one of three categories: `Hardware`, `Software`, or `Other`.
To implement this use case, you can use either the [Chat Completions API](https://developers.openai.com/api/docs/api-reference/chat) or the [Responses API](https://developers.openai.com/api/docs/api-reference/responses). Both examples below combine a [developer message](https://developers.openai.com/api/docs/guides/text) with a user message containing the text of a support ticket.
Categorize IT support tickets
```bash
curl https://api.openai.com/v1/responses \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"model": "gpt-4.1",
"input": [
{
"role": "developer",
"content": "Categorize the following support ticket into one of Hardware, Software, or Other."
},
{
"role": "user",
"content": "My monitor wont turn on - help!"
}
]
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const instructions = \`
You are an expert in categorizing IT support tickets. Given the support
ticket below, categorize the request into one of "Hardware", "Software",
or "Other". Respond with only one of those words.
\`;
const ticket = "My monitor won't turn on - help!";
const response = await client.responses.create({
model: "gpt-4.1",
input: [
{ role: "developer", content: instructions },
{ role: "user", content: ticket },
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
instructions = """
You are an expert in categorizing IT support tickets. Given the support
ticket below, categorize the request into one of "Hardware", "Software",
or "Other". Respond with only one of those words.
"""
ticket = "My monitor won't turn on - help!"
response = client.responses.create(
model="gpt-4.1",
input=[
{"role": "developer", "content": instructions},
{"role": "user", "content": ticket},
],
)
print(response.output_text)
```
Let's set up an eval to test this behavior [via API](https://developers.openai.com/api/docs/api-reference/evals). An eval needs two key ingredients:
- `data_source_config`: A schema for the test data you will use along with the eval.
- `testing_criteria`: The [graders](https://developers.openai.com/api/docs/guides/graders) that determine if the model output is correct.
Create an eval
```bash
curl https://api.openai.com/v1/evals \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"name": "IT Ticket Categorization",
"data_source_config": {
"type": "custom",
"item_schema": {
"type": "object",
"properties": {
"ticket_text": { "type": "string" },
"correct_label": { "type": "string" }
},
"required": ["ticket_text", "correct_label"]
},
"include_sample_schema": true
},
"testing_criteria": [
{
"type": "string_check",
"name": "Match output to human label",
"input": "{{ sample.output_text }}",
"operation": "eq",
"reference": "{{ item.correct_label }}"
}
]
}'
```
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const evalObj = await openai.evals.create({
name: "IT Ticket Categorization",
data_source_config: {
type: "custom",
item_schema: {
type: "object",
properties: {
ticket_text: { type: "string" },
correct_label: { type: "string" }
},
required: ["ticket_text", "correct_label"],
},
include_sample_schema: true,
},
testing_criteria: [
{
type: "string_check",
name: "Match output to human label",
input: "{{ sample.output_text }}",
operation: "eq",
reference: "{{ item.correct_label }}",
},
],
});
console.log(evalObj);
```
```python
from openai import OpenAI
client = OpenAI()
eval_obj = client.evals.create(
name="IT Ticket Categorization",
data_source_config={
"type": "custom",
"item_schema": {
"type": "object",
"properties": {
"ticket_text": {"type": "string"},
"correct_label": {"type": "string"},
},
"required": ["ticket_text", "correct_label"],
},
"include_sample_schema": True,
},
testing_criteria=[
{
"type": "string_check",
"name": "Match output to human label",
"input": "{{ sample.output_text }}",
"operation": "eq",
"reference": "{{ item.correct_label }}",
}
],
)
print(eval_obj)
```
Explanation: data_source_config parameter
Running this eval will require a test data set that represents the type of data you expect your prompt to work with (more on creating the test data set later in this guide). In our `data_source_config` parameter, we specify that each **item** in the data set will conform to a [JSON schema](https://json-schema.org/) with two properties:
- `ticket_text`: a string of text with the contents of a support ticket
- `correct_label`: a "ground truth" output that the model should match, provided by a human
Since we will be referencing a **sample** in our test criteria (the output generated by a model given our prompt), we also set `include_sample_schema` to `true`.
```json
{
"type": "custom",
"item_schema": {
"type": "object",
"properties": {
"ticket": { "type": "string" },
"category": { "type": "string" }
},
"required": ["ticket", "category"]
},
"include_sample_schema": true
}
```
Explanation: testing_criteria parameter
In our `testing_criteria`, we define how we will conclude if the model output satisfies our requirements for each item in the data set. In this case, we just want the model to output one of three category strings based on the input ticket. The string it outputs should exactly match the human-labeled `correct_label` field in our test data. So in this case, we will want to use a `string_check` grader to evaluate the output.
In the test configuration, we will introduce template syntax, represented by the `{{` and `}}` brackets below. This is how we will insert dynamic content into the test for this eval.
- `{{ item.correct_label }}` refers to the ground truth value in our test data.
- `{{ sample.output_text }}` refers to the content we will generate from a model to evaluate our prompt - we'll show how to do that when we actually kick off the eval run.
```json
{
"type": "string_check",
"name": "Category string match",
"input": "{{ sample.output_text }}",
"operation": "eq",
"reference": "{{ item.category }}"
}
```
After creating the eval, it will be assigned a UUID that you will need to address it later when kicking off a run.
```json
{
"object": "eval",
"id": "eval_67e321d23b54819096e6bfe140161184",
"data_source_config": {
"type": "custom",
"schema": { ... omitted for brevity... }
},
"testing_criteria": [
{
"name": "Match output to human label",
"id": "Match output to human label-c4fdf789-2fa5-407f-8a41-a6f4f9afd482",
"type": "string_check",
"input": "{{ sample.output_text }}",
"reference": "{{ item.correct_label }}",
"operation": "eq"
}
],
"name": "IT Ticket Categorization",
"created_at": 1742938578,
"metadata": {}
}
```
Now that we've created an eval that describes the desired behavior of our application, let's test a prompt with a set of test data.
## Test a prompt with your eval
Now that we have defined how we want our app to behave in an eval, let's construct a prompt that reliably generates the correct output for a representative sample of test data.
### Uploading test data
There are several ways to provide test data for eval runs, but it may be convenient to upload a [JSONL](https://jsonlines.org/) file that contains data in the schema we specified when we created our eval. A sample JSONL file that conforms to the schema we set up is below:
```json
{ "item": { "ticket_text": "My monitor won't turn on!", "correct_label": "Hardware" } }
{ "item": { "ticket_text": "I'm in vim and I can't quit!", "correct_label": "Software" } }
{ "item": { "ticket_text": "Best restaurants in Cleveland?", "correct_label": "Other" } }
```
This data set contains both test inputs and ground truth labels to compare model outputs against.
Next, let's upload our test data file to the OpenAI platform so we can reference it later. You can upload files [in the dashboard here](https://platform.openai.com/storage/files), but it's possible to [upload files via API](https://developers.openai.com/api/docs/api-reference/files/create) as well. The samples below assume you are running the command in a directory where you saved the sample JSON data above to a file called `tickets.jsonl`:
Upload a test data file
```bash
curl https://api.openai.com/v1/files \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-F purpose="evals" \\
-F file="@tickets.jsonl"
```
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const file = await openai.files.create({
file: fs.createReadStream("tickets.jsonl"),
purpose: "evals",
});
console.log(file);
```
```python
from openai import OpenAI
client = OpenAI()
file = client.files.create(
file=open("tickets.jsonl", "rb"),
purpose="evals"
)
print(file)
```
When you upload the file, make note of the unique `id` property in the response payload (also available in the UI if you uploaded via the browser) - we will need to reference that value later:
```json
{
"object": "file",
"id": "file-CwHg45Fo7YXwkWRPUkLNHW",
"purpose": "evals",
"filename": "tickets.jsonl",
"bytes": 208,
"created_at": 1742834798,
"expires_at": null,
"status": "processed",
"status_details": null
}
```
### Creating an eval run
With our test data in place, let's evaluate a prompt and see how it performs against our test criteria. Via API, we can do this by [creating an eval run](https://developers.openai.com/api/docs/api-reference/evals/createRun).
Make sure to replace `YOUR_EVAL_ID` and `YOUR_FILE_ID` with the unique IDs of the eval configuration and test data files you created in the steps above.
Create an eval run
```bash
curl https://api.openai.com/v1/evals/YOUR_EVAL_ID/runs \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"name": "Categorization text run",
"data_source": {
"type": "responses",
"model": "gpt-4.1",
"input_messages": {
"type": "template",
"template": [
{"role": "developer", "content": "You are an expert in categorizing IT support tickets. Given the support ticket below, categorize the request into one of Hardware, Software, or Other. Respond with only one of those words."},
{"role": "user", "content": "{{ item.ticket_text }}"}
]
},
"source": { "type": "file_id", "id": "YOUR_FILE_ID" }
}
}'
```
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const run = await openai.evals.runs.create("YOUR_EVAL_ID", {
name: "Categorization text run",
data_source: {
type: "responses",
model: "gpt-4.1",
input_messages: {
type: "template",
template: [
{ role: "developer", content: "You are an expert in categorizing IT support tickets. Given the support ticket below, categorize the request into one of 'Hardware', 'Software', or 'Other'. Respond with only one of those words." },
{ role: "user", content: "{{ item.ticket_text }}" },
],
},
source: { type: "file_id", id: "YOUR_FILE_ID" },
},
});
console.log(run);
```
```python
from openai import OpenAI
client = OpenAI()
run = client.evals.runs.create(
"YOUR_EVAL_ID",
name="Categorization text run",
data_source={
"type": "responses",
"model": "gpt-4.1",
"input_messages": {
"type": "template",
"template": [
{"role": "developer", "content": "You are an expert in categorizing IT support tickets. Given the support ticket below, categorize the request into one of 'Hardware', 'Software', or 'Other'. Respond with only one of those words."},
{"role": "user", "content": "{{ item.ticket_text }}"},
],
},
"source": {"type": "file_id", "id": "YOUR_FILE_ID"},
},
)
print(run)
```
When we create the run, we set up a prompt using either a [Chat Completions](https://developers.openai.com/api/docs/guides/text?api-mode=chat) messages array or a [Responses](https://developers.openai.com/api/docs/api-reference/responses) input. This prompt is used to generate a model response for every line of test data in your data set. We can use the double curly brace syntax to template in the dynamic variable `item.ticket_text`, which is drawn from the current test data item.
If the eval run is successfully created, you'll receive an API response that looks like this:
```json
{
"object": "eval.run",
"id": "evalrun_67e44c73eb6481909f79a457749222c7",
"eval_id": "eval_67e44c5becec81909704be0318146157",
"report_url": "https://platform.openai.com/evaluation/evals/abc123",
"status": "queued",
"model": "gpt-4.1",
"name": "Categorization text run",
"created_at": 1743015028,
"result_counts": { ... },
"per_model_usage": null,
"per_testing_criteria_results": null,
"data_source": {
"type": "responses",
"source": {
"type": "file_id",
"id": "file-J7MoX9ToHXp2TutMEeYnwj"
},
"input_messages": {
"type": "template",
"template": [
{
"type": "message",
"role": "developer",
"content": {
"type": "input_text",
"text": "You are an expert in...."
}
},
{
"type": "message",
"role": "user",
"content": {
"type": "input_text",
"text": "{{item.ticket_text}}"
}
}
]
},
"model": "gpt-4.1",
"sampling_params": null
},
"error": null,
"metadata": {}
}
```
Your eval run has now been queued, and it will execute asynchronously as it processes every row in your data set, generating responses for testing with the prompt and model we specified.
## Analyze the results
To receive updates when a run succeeds, fails, or is canceled, create a webhook endpoint and subscribe to the `eval.run.succeeded`, `eval.run.failed`, and `eval.run.canceled` events. See the [webhooks guide](https://developers.openai.com/api/docs/guides/webhooks) for more details.
Depending on the size of your dataset, the eval run may take some time to complete. You can view current status in the dashboard, but you can also [fetch the current status of an eval run via API](https://developers.openai.com/api/docs/api-reference/evals/getRun):
Retrieve eval run status
```bash
curl https://api.openai.com/v1/evals/YOUR_EVAL_ID/runs/YOUR_RUN_ID \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json"
```
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const run = await openai.evals.runs.retrieve("YOUR_RUN_ID", {
eval_id: "YOUR_EVAL_ID",
});
console.log(run);
```
```python
from openai import OpenAI
client = OpenAI()
run = client.evals.runs.retrieve("YOUR_EVAL_ID", "YOUR_RUN_ID")
print(run)
```
You'll need the UUID of both your eval and eval run to fetch its status. When you do, you'll see eval run data that looks like this:
```json
{
"object": "eval.run",
"id": "evalrun_67e44c73eb6481909f79a457749222c7",
"eval_id": "eval_67e44c5becec81909704be0318146157",
"report_url": "https://platform.openai.com/evaluation/evals/xxx",
"status": "completed",
"model": "gpt-4.1",
"name": "Categorization text run",
"created_at": 1743015028,
"result_counts": {
"total": 3,
"errored": 0,
"failed": 0,
"passed": 3
},
"per_model_usage": [
{
"model_name": "gpt-4o-2024-08-06",
"invocation_count": 3,
"prompt_tokens": 166,
"completion_tokens": 6,
"total_tokens": 172,
"cached_tokens": 0
}
],
"per_testing_criteria_results": [
{
"testing_criteria": "Match output to human label-40d67441-5000-4754-ab8c-181c125803ce",
"passed": 3,
"failed": 0
}
],
"data_source": {
"type": "responses",
"source": {
"type": "file_id",
"id": "file-J7MoX9ToHXp2TutMEeYnwj"
},
"input_messages": {
"type": "template",
"template": [
{
"type": "message",
"role": "developer",
"content": {
"type": "input_text",
"text": "You are an expert in categorizing IT support tickets. Given the support ticket below, categorize the request into one of Hardware, Software, or Other. Respond with only one of those words."
}
},
{
"type": "message",
"role": "user",
"content": {
"type": "input_text",
"text": "{{item.ticket_text}}"
}
}
]
},
"model": "gpt-4.1",
"sampling_params": null
},
"error": null,
"metadata": {}
}
```
The API response contains granular information about test criteria results, API usage for generating model responses, and a `report_url` property that takes you to a page in the dashboard where you can explore the results visually.
In our simple test, the model reliably generated the content we wanted for a small test case sample. In reality, you will often have to run your eval with more criteria, different prompts, and different data sets. But the process above gives you all the tools you need to build robust evals for your LLM apps!
## Next steps
Now you know how to create and run evals via API, and using the dashboard! Here are a few other resources that may be useful to you as you continue to improve your model results.
Keep tabs on the performance of your prompts as you iterate on them.
Compare the results of many different prompts and models at once.
Examine stored completions to test for prompt regressions.
[
Improve a model's ability to generate responses tailored to your use case.
](https://developers.openai.com/api/docs/guides/fine-tuning)
[
Learn how to distill large model results to smaller, cheaper, and faster
models.
](https://developers.openai.com/api/docs/guides/distillation)
---
# SDKs and CLI
This page covers the main ways to build with the [OpenAI API](https://developers.openai.com/api/docs/api-reference): official SDKs for application code, the OpenAI CLI for shell-native workflows, the Agents SDK for orchestration, or your own preferred HTTP client.
## Create and export an API key
Before you begin, [create an API key in the dashboard](https://platform.openai.com/api-keys), which you'll use to securely [access the API](https://developers.openai.com/api/docs/api-reference/authentication). Store the key in a safe location, like a [`.zshrc` file](https://www.freecodecamp.org/news/how-do-zsh-configuration-files-work/) or another text file on your computer. Once you've generated an API key, export it as an [environment variable](https://en.wikipedia.org/wiki/Environment_variable) in your terminal.
After creating a new webhook, you'll receive a signing secret to use for server-side verification of incoming webhook requests. Save this value for later, since you won't be able to view it again.
With your webhook endpoint created, you'll next set up a server-side endpoint to handle those incoming event payloads.
## Handling webhook requests on a server
When an event happens that you're subscribed to, your webhook URL will receive an HTTP POST request like this:
```
POST https://yourserver.com/webhook
user-agent: OpenAI/1.0 (+https://platform.openai.com/docs/webhooks)
content-type: application/json
webhook-id: wh_685342e6c53c8190a1be43f081506c52
webhook-timestamp: 1750287078
webhook-signature: v1,K5oZfzN95Z9UVu1EsfQmfVNQhnkZ2pj9o9NDN/H/pI4=
{
"object": "event",
"id": "evt_685343a1381c819085d44c354e1b330e",
"type": "response.completed",
"created_at": 1750287018,
"data": { "id": "resp_abc123" }
}
```
Your endpoint should respond quickly to these incoming HTTP requests with a successful (`2xx`) status code, indicating successful receipt. To avoid timeouts, we recommend offloading any non-trivial processing to a background worker so that the endpoint can respond immediately.
If the endpoint doesn't return a successful (`2xx`) status code, or doesn't respond within a few seconds, the webhook request will be retried. OpenAI will continue to attempt delivery for up to 72 hours with exponential backoff. Note that `3xx` redirects will not be followed; they are treated as failures and your endpoint should be updated to use the final destination URL.
In rare cases, due to internal system issues, OpenAI may deliver duplicate copies of the same webhook event. You can use the `webhook-id` header as an idempotency key to deduplicate.
### Testing webhooks locally
Testing webhooks requires a URL that is available on the public Internet. This can make development tricky, since your local development environment likely isn't open to the public. A few options that may help:
- [ngrok](https://ngrok.com/) which can expose your localhost server on a public URL
- Cloud development environments like [Replit](https://replit.com/), [GitHub Codespaces](https://github.com/features/codespaces), [Cloudflare Workers](https://workers.cloudflare.com/), or [v0 from Vercel](https://v0.dev/).
## Verifying webhook signatures
While you can receive webhook events from OpenAI and process the results without any verification, you should verify that incoming requests are coming from OpenAI, especially if your webhook will take any kind of action on the backend. The headers sent along with webhook requests contain information that can be used in combination with a webhook secret key to verify that the webhook originated from OpenAI.
When you create a webhook endpoint in the OpenAI dashboard, you'll be given a signing secret that you should make available on your server as an environment variable:
```
export OPENAI_WEBHOOK_SECRET=""
```
The simplest way to verify webhook signatures is by using the `unwrap()` method of the official OpenAI SDK helpers:
Signature verification with the OpenAI SDK
```python
client = OpenAI()
webhook_secret = os.environ["OPENAI_WEBHOOK_SECRET"]
# will raise if the signature is invalid
event = client.webhooks.unwrap(request.data, request.headers, secret=webhook_secret)
```
```javascript
const client = new OpenAI();
const webhook_secret = process.env.OPENAI_WEBHOOK_SECRET;
// will throw if the signature is invalid
const event = client.webhooks.unwrap(req.body, req.headers, { secret: webhook_secret });
```
Signatures can also be verified with the [Standard Webhooks libraries](https://github.com/standard-webhooks/standard-webhooks/tree/main?tab=readme-ov-file#reference-implementations):
Signature verification with Standard Webhooks libraries
```rust
use standardwebhooks::Webhook;
let webhook_secret = std::env::var("OPENAI_WEBHOOK_SECRET").expect("OPENAI_WEBHOOK_SECRET not set");
let wh = Webhook::new(webhook_secret);
wh.verify(webhook_payload, webhook_headers).expect("Webhook verification failed");
```
```php
$webhook_secret = getenv("OPENAI_WEBHOOK_SECRET");
$wh = new \\StandardWebhooks\\Webhook($webhook_secret);
$wh->verify($webhook_payload, $webhook_headers);
```
Alternatively, if needed, you can implement your own signature verification [as described in the Standard Webhooks spec](https://github.com/standard-webhooks/standard-webhooks/blob/main/spec/standard-webhooks.md#verifying-webhook-authenticity)
If you misplace or accidentally expose your signing secret, you can generate a new one by [rotating the signing secret](https://platform.openai.com/settings/project/webhooks).
---
# Webhooks and server-side controls
The Realtime API allows clients to connect directly to the API server via WebRTC or SIP. However, you'll most likely want tool use and other business logic to reside on your application server to keep this logic private and client-agnostic.
Keep tool use, business logic, and other details secure on the server side by connecting over a “sideband” control channel. We now have sideband options for both SIP and WebRTC connections.
A sideband connection means there are two active connections to the same Realtime session: one from the user's client and one from your application server. The server connection can be used to monitor the session, update instructions, and respond to tool calls.
## With WebRTC
1. When [establishing a peer connection](https://developers.openai.com/api/docs/guides/realtime-webrtc) you fetch and receive an SDP response from the Realtime API to configure the connection. If you used the sample code from the WebRTC guide, that looks something like this:
```javascript
const baseUrl = "https://api.openai.com/v1/realtime/calls";
const sdpResponse = await fetch(baseUrl, {
method: "POST",
body: offer.sdp,
headers: {
Authorization: `Bearer ${EPHEMERAL_KEY}`,
"Content-Type": "application/sdp",
},
});
```
2. The fetch response will contain a `Location` header that has a unique call ID that can be used on the server to establish a WebSocket connection to that same Realtime session.
```javascript
// Location: /v1/realtime/calls/rtc_123456
const location = sdpResponse.headers.get("Location");
const callId = location?.split("/").pop();
console.log(callId);
```
3. On a server, you can then [listen for events and configure the session](https://developers.openai.com/api/docs/guides/realtime-conversations) just as you would from a typical Realtime API WebSocket connection, using that call ID with the URL
`wss://api.openai.com/v1/realtime?call_id=rtc_xxxxx`, as shown below:
```javascript
const callId = "rtc_u1_9c6574da8b8a41a18da9308f4ad974ce";
// Connect to a WebSocket for the in-progress call
const url = "wss://api.openai.com/v1/realtime?call_id=" + callId;
const ws = new WebSocket(url, {
headers: {
Authorization: "Bearer " + process.env.OPENAI_API_KEY,
},
});
ws.on("open", function open() {
console.log("Connected to server.");
// Send client events over the WebSocket once connected
ws.send(
JSON.stringify({
type: "session.update",
session: {
type: "realtime",
instructions: "Be extra nice today!",
},
})
);
});
// Listen for and parse server events
ws.on("message", function incoming(message) {
console.log(JSON.parse(message.toString()));
});
```
In this way, you are able to add tools, monitor sessions, and carry out business logic on the server instead of needing to configure those actions on the client.
## With SIP
1. A user connects to OpenAI via phone over SIP.
2. OpenAI sends a webhook to your application’s server webhook URL, notifying your app of the state of the session. The webhook will look something like:
```json
POST https://my_website.com/webhook_endpoint
user-agent: OpenAI/1.0 (+https://platform.openai.com/docs/webhooks)
content-type: application/json
webhook-id: wh_685342e6c53c8190a1be43f081506c52 # unique id for idempotency
webhook-timestamp: 1750287078 # timestamp of delivery attempt
webhook-signature: v1,K5oZfzN95Z9UVu1EsfQmfVNQhnkZ2pj9o9NDN/H/pI4= # signature to verify authenticity from OpenAI
{
"object": "event",
"id": "evt_685343a1381c819085d44c354e1b330e",
"type": "realtime.call.incoming",
"created_at": 1750287018, // Unix timestamp
"data": {
"call_id": "some_unique_id",
"sip_headers": [
{ "name": "From", "value": "sip:+142555512112@sip.example.com" },
{ "name": "To", "value": "sip:+18005551212@sip.example.com" },
{ "name": "Call-ID", "value": "03782086-4ce9-44bf-8b0d-4e303d2cc590"}
]
}
}
```
3. The application server opens a WebSocket connection to the Realtime API using the `call_id` value provided in the webhook, via a URL like this: `wss://api.openai.com/v1/realtime?call_id={callId}`. The WebSocket connection will live for the life of the SIP call.
The WebSocket connection can then be used to send and receive events to control the call, just as you would if the session was initiated with a WebSocket connection. This includes monitoring the call, updating instructions dynamically, and responding to tool calls.
---
# WebSocket Mode
The Responses API supports a WebSocket mode for long-running, tool-call-heavy workflows. In this mode, you keep a persistent connection to `/v1/responses` and continue each turn by sending only new input items plus `previous_response_id`.
WebSocket mode is compatible with both Zero Data Retention (ZDR) and `store=false`.
## Why use WebSocket mode
WebSocket mode is most useful when a workflow involves many model-tool round trips (for example, agentic coding or orchestration loops with repeated tool calls).
Because the connection stays open and each turn sends only incremental input, WebSocket mode reduces per-turn continuation overhead and improves end-to-end latency across long chains. For rollouts with 20+ tool calls, we have seen up to roughly 40% faster end-to-end execution.
## Connect and create responses
In WebSocket mode, start each turn by sending a `response.create` event from the client. The payload mirrors the normal [Responses create body](https://developers.openai.com/api/reference/resources/responses/methods/create), except that transport-specific fields like `stream` and `background` are not used.
```python
from websocket import create_connection
import json
import os
ws = create_connection(
"wss://api.openai.com/v1/responses",
header=[
f"Authorization: Bearer {os.environ['OPENAI_API_KEY']}",
],
)
ws.send(
json.dumps(
{
"type": "response.create",
"model": "gpt-5.5",
"store": False,
"input": [
{
"type": "message",
"role": "user",
"content": [{"type": "input_text", "text": "Find fizz_buzz()"}],
}
],
"tools": [],
}
)
)
```
Clients can optionally warm up request state by sending `response.create` with `generate: false`. This is useful when you already know the tools, instructions, and/or custom messages you plan to send with an upcoming turn. `generate: false` does not return a model output, but prepares request state so the next generated turn can start faster. The warmup request returns a response ID that you can chain from with `previous_response_id`, including on later turns in a response chain. The next section explains how to continue a session using `previous_response_id` and incremental inputs.
## Continue with incremental inputs
To continue a run, send another `response.create` with:
- `previous_response_id` set to the prior response ID.
- `input` containing only new items (for example, tool outputs and the next user message).
```python
ws.send(
json.dumps(
{
"type": "response.create",
"model": "gpt-5.5",
"store": False,
"previous_response_id": "resp_123",
"input": [
{
"type": "function_call_output",
"call_id": "call_123",
"output": "tool result",
},
{
"type": "message",
"role": "user",
"content": [{"type": "input_text", "text": "Now optimize it."}],
},
],
"tools": [],
}
)
)
```
## How continuation works
WebSocket mode uses the same `previous_response_id` chaining semantics as HTTP mode, but it adds a lower-latency continuation path on the active socket.
On an active WebSocket connection, the service keeps one previous-response state in a connection-local in-memory cache (the most recent response). Continuing from that most recent response is fast because the service can reuse connection-local state. Because the previous-response state is retained only in memory and is not written to disk, you can use WebSocket mode in a way that is compatible with `store=false` and Zero Data Retention (ZDR).
If a `previous_response_id` is not in the in-memory cache, behavior depends on whether you store responses:
- With `store=true`, the service may hydrate older response IDs from persisted state when available. Continuation can still work, but it usually loses the in-memory latency benefit.
- With `store=false` (including ZDR), there is no persisted fallback. If the ID is uncached, the request returns `previous_response_not_found`.
If a turn fails (`4xx` or `5xx`), the service evicts the referenced `previous_response_id` from the connection-local cache. This prevents reusing stale cached state for that failed continuation.
## Compaction and creating new responses
If you are using compaction, there are two different continuation patterns:
### Server-side compaction (`context_management`)
When you enable server-side compaction (`context_management` with `compact_threshold`), compaction happens during normal `/responses` generation. In WebSocket mode, you continue the same way you normally do: send the next `response.create` with the latest `previous_response_id` and only new input items.
### Standalone `/responses/compact`
The standalone [`/responses/compact` endpoint](https://developers.openai.com/api/docs/api-reference/responses/compact) returns a new compacted input window, not a response ID. After compaction, create a new response on your WebSocket connection using the compacted window as `input` (plus the next user/tool items).
Start a new chain by omitting `previous_response_id` or setting it to `null`. Pass the compacted output as-is; do not prune the returned window.
```python
# Compact your current window (HTTP call)
compacted = client.responses.compact(
model="gpt-5.5",
input=long_input_items_array,
)
# Start a new response on the WebSocket using the compacted window
ws.send(
json.dumps(
{
"type": "response.create",
"model": "gpt-5.5",
"store": False,
"input": [
*compacted.output,
{
"type": "message",
"role": "user",
"content": [{"type": "input_text", "text": "Continue from here."}],
},
],
"tools": [],
}
)
)
```
## Connection behavior and limits
- Server events and ordering match the existing Responses streaming event model.
- A single WebSocket connection can receive multiple `response.create` messages, but it runs them sequentially (one in-flight response at a time).
- No multiplexing support today. Use multiple connections if you need parallel runs.
- Connection duration is limited to 60 minutes. Reconnect when the limit is reached.
## Reconnect and recover
When a connection closes (or hits the 60-minute limit), open a new WebSocket connection and continue with one of these patterns:
1. If your prior response is persisted (`store=true`) and you have a valid response ID, continue with `previous_response_id` and new input items.
2. If you cannot continue the chain (for example, `store=false`/ZDR or `previous_response_not_found`), start a new response by setting `previous_response_id` to `null` (or omitting it) and send the full input context for the next turn.
3. If you compacted context with `/responses/compact`, use the returned compacted window as the base `input` for that new response, then append the latest user/tool items.
## Errors to handle
`previous_response_not_found`
```json
{
"type": "error",
"status": 400,
"error": {
"code": "previous_response_not_found",
"message": "Previous response with id 'resp_abc' not found.",
"param": "previous_response_id"
}
}
```
`websocket_connection_limit_reached`
```json
{
"type": "error",
"error": {
"type": "invalid_request_error",
"code": "websocket_connection_limit_reached",
"message": "Responses websocket connection limit reached (60 minutes). Create a new websocket connection to continue."
},
"status": 400
}
```
## Related guides
- [Conversation state](https://developers.openai.com/api/docs/guides/conversation-state)
- [Streaming API responses](https://developers.openai.com/api/docs/guides/streaming-responses)
- [Responses streaming events reference](https://developers.openai.com/api/docs/api-reference/responses-streaming)
---
# Working with evals
Evaluations (often called **evals**) test model outputs to ensure they meet style and content criteria that you specify. Writing evals to understand how your LLM applications are performing against your expectations, especially when upgrading or trying new models, is an essential component to building reliable applications.
In this guide, we will focus on **configuring evals programmatically using the [Evals API](https://developers.openai.com/api/docs/api-reference/evals)**. If you prefer, you can also configure evals [in the OpenAI dashboard](https://platform.openai.com/evaluations).
If you're new to evaluations, or want a more iterative environment to
experiment in as you build your eval, consider trying
[Datasets](https://developers.openai.com/api/docs/guides/evaluation-getting-started) instead.
Broadly, there are three steps to build and run evals for your LLM application.
1. Describe the task to be done as an eval
1. Run your eval with test inputs (a prompt and input data)
1. Analyze the results, then iterate and improve on your prompt
This process is somewhat similar to behavior-driven development (BDD), where you begin by specifying how the system should behave before implementing and testing the system. Let's see how we would complete each of the steps above using the [Evals API](https://developers.openai.com/api/docs/api-reference/evals).
## Create an eval for a task
Creating an eval begins by describing a task to be done by a model. Let's say that we would like to use a model to classify the contents of IT support tickets into one of three categories: `Hardware`, `Software`, or `Other`.
To implement this use case, you can use either the [Chat Completions API](https://developers.openai.com/api/docs/api-reference/chat) or the [Responses API](https://developers.openai.com/api/docs/api-reference/responses). Both examples below combine a [developer message](https://developers.openai.com/api/docs/guides/text) with a user message containing the text of a support ticket.
Categorize IT support tickets
```bash
curl https://api.openai.com/v1/responses \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"model": "gpt-4.1",
"input": [
{
"role": "developer",
"content": "Categorize the following support ticket into one of Hardware, Software, or Other."
},
{
"role": "user",
"content": "My monitor wont turn on - help!"
}
]
}'
```
```javascript
import OpenAI from "openai";
const client = new OpenAI();
const instructions = \`
You are an expert in categorizing IT support tickets. Given the support
ticket below, categorize the request into one of "Hardware", "Software",
or "Other". Respond with only one of those words.
\`;
const ticket = "My monitor won't turn on - help!";
const response = await client.responses.create({
model: "gpt-4.1",
input: [
{ role: "developer", content: instructions },
{ role: "user", content: ticket },
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
instructions = """
You are an expert in categorizing IT support tickets. Given the support
ticket below, categorize the request into one of "Hardware", "Software",
or "Other". Respond with only one of those words.
"""
ticket = "My monitor won't turn on - help!"
response = client.responses.create(
model="gpt-4.1",
input=[
{"role": "developer", "content": instructions},
{"role": "user", "content": ticket},
],
)
print(response.output_text)
```
Let's set up an eval to test this behavior [via API](https://developers.openai.com/api/docs/api-reference/evals). An eval needs two key ingredients:
- `data_source_config`: A schema for the test data you will use along with the eval.
- `testing_criteria`: The [graders](https://developers.openai.com/api/docs/guides/graders) that determine if the model output is correct.
Create an eval
```bash
curl https://api.openai.com/v1/evals \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"name": "IT Ticket Categorization",
"data_source_config": {
"type": "custom",
"item_schema": {
"type": "object",
"properties": {
"ticket_text": { "type": "string" },
"correct_label": { "type": "string" }
},
"required": ["ticket_text", "correct_label"]
},
"include_sample_schema": true
},
"testing_criteria": [
{
"type": "string_check",
"name": "Match output to human label",
"input": "{{ sample.output_text }}",
"operation": "eq",
"reference": "{{ item.correct_label }}"
}
]
}'
```
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const evalObj = await openai.evals.create({
name: "IT Ticket Categorization",
data_source_config: {
type: "custom",
item_schema: {
type: "object",
properties: {
ticket_text: { type: "string" },
correct_label: { type: "string" }
},
required: ["ticket_text", "correct_label"],
},
include_sample_schema: true,
},
testing_criteria: [
{
type: "string_check",
name: "Match output to human label",
input: "{{ sample.output_text }}",
operation: "eq",
reference: "{{ item.correct_label }}",
},
],
});
console.log(evalObj);
```
```python
from openai import OpenAI
client = OpenAI()
eval_obj = client.evals.create(
name="IT Ticket Categorization",
data_source_config={
"type": "custom",
"item_schema": {
"type": "object",
"properties": {
"ticket_text": {"type": "string"},
"correct_label": {"type": "string"},
},
"required": ["ticket_text", "correct_label"],
},
"include_sample_schema": True,
},
testing_criteria=[
{
"type": "string_check",
"name": "Match output to human label",
"input": "{{ sample.output_text }}",
"operation": "eq",
"reference": "{{ item.correct_label }}",
}
],
)
print(eval_obj)
```
Explanation: data_source_config parameter
Running this eval will require a test data set that represents the type of data you expect your prompt to work with (more on creating the test data set later in this guide). In our `data_source_config` parameter, we specify that each **item** in the data set will conform to a [JSON schema](https://json-schema.org/) with two properties:
- `ticket_text`: a string of text with the contents of a support ticket
- `correct_label`: a "ground truth" output that the model should match, provided by a human
Since we will be referencing a **sample** in our test criteria (the output generated by a model given our prompt), we also set `include_sample_schema` to `true`.
```json
{
"type": "custom",
"item_schema": {
"type": "object",
"properties": {
"ticket": { "type": "string" },
"category": { "type": "string" }
},
"required": ["ticket", "category"]
},
"include_sample_schema": true
}
```
Explanation: testing_criteria parameter
In our `testing_criteria`, we define how we will conclude if the model output satisfies our requirements for each item in the data set. In this case, we just want the model to output one of three category strings based on the input ticket. The string it outputs should exactly match the human-labeled `correct_label` field in our test data. So in this case, we will want to use a `string_check` grader to evaluate the output.
In the test configuration, we will introduce template syntax, represented by the `{{` and `}}` brackets below. This is how we will insert dynamic content into the test for this eval.
- `{{ item.correct_label }}` refers to the ground truth value in our test data.
- `{{ sample.output_text }}` refers to the content we will generate from a model to evaluate our prompt - we'll show how to do that when we actually kick off the eval run.
```json
{
"type": "string_check",
"name": "Category string match",
"input": "{{ sample.output_text }}",
"operation": "eq",
"reference": "{{ item.category }}"
}
```
After creating the eval, it will be assigned a UUID that you will need to address it later when kicking off a run.
```json
{
"object": "eval",
"id": "eval_67e321d23b54819096e6bfe140161184",
"data_source_config": {
"type": "custom",
"schema": { ... omitted for brevity... }
},
"testing_criteria": [
{
"name": "Match output to human label",
"id": "Match output to human label-c4fdf789-2fa5-407f-8a41-a6f4f9afd482",
"type": "string_check",
"input": "{{ sample.output_text }}",
"reference": "{{ item.correct_label }}",
"operation": "eq"
}
],
"name": "IT Ticket Categorization",
"created_at": 1742938578,
"metadata": {}
}
```
Now that we've created an eval that describes the desired behavior of our application, let's test a prompt with a set of test data.
## Test a prompt with your eval
Now that we have defined how we want our app to behave in an eval, let's construct a prompt that reliably generates the correct output for a representative sample of test data.
### Uploading test data
There are several ways to provide test data for eval runs, but it may be convenient to upload a [JSONL](https://jsonlines.org/) file that contains data in the schema we specified when we created our eval. A sample JSONL file that conforms to the schema we set up is below:
```json
{ "item": { "ticket_text": "My monitor won't turn on!", "correct_label": "Hardware" } }
{ "item": { "ticket_text": "I'm in vim and I can't quit!", "correct_label": "Software" } }
{ "item": { "ticket_text": "Best restaurants in Cleveland?", "correct_label": "Other" } }
```
This data set contains both test inputs and ground truth labels to compare model outputs against.
Next, let's upload our test data file to the OpenAI platform so we can reference it later. You can upload files [in the dashboard here](https://platform.openai.com/storage/files), but it's possible to [upload files via API](https://developers.openai.com/api/docs/api-reference/files/create) as well. The samples below assume you are running the command in a directory where you saved the sample JSON data above to a file called `tickets.jsonl`:
Upload a test data file
```bash
curl https://api.openai.com/v1/files \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-F purpose="evals" \\
-F file="@tickets.jsonl"
```
```javascript
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
const file = await openai.files.create({
file: fs.createReadStream("tickets.jsonl"),
purpose: "evals",
});
console.log(file);
```
```python
from openai import OpenAI
client = OpenAI()
file = client.files.create(
file=open("tickets.jsonl", "rb"),
purpose="evals"
)
print(file)
```
When you upload the file, make note of the unique `id` property in the response payload (also available in the UI if you uploaded via the browser) - we will need to reference that value later:
```json
{
"object": "file",
"id": "file-CwHg45Fo7YXwkWRPUkLNHW",
"purpose": "evals",
"filename": "tickets.jsonl",
"bytes": 208,
"created_at": 1742834798,
"expires_at": null,
"status": "processed",
"status_details": null
}
```
### Creating an eval run
With our test data in place, let's evaluate a prompt and see how it performs against our test criteria. Via API, we can do this by [creating an eval run](https://developers.openai.com/api/docs/api-reference/evals/createRun).
Make sure to replace `YOUR_EVAL_ID` and `YOUR_FILE_ID` with the unique IDs of the eval configuration and test data files you created in the steps above.
Create an eval run
```bash
curl https://api.openai.com/v1/evals/YOUR_EVAL_ID/runs \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '{
"name": "Categorization text run",
"data_source": {
"type": "responses",
"model": "gpt-4.1",
"input_messages": {
"type": "template",
"template": [
{"role": "developer", "content": "You are an expert in categorizing IT support tickets. Given the support ticket below, categorize the request into one of Hardware, Software, or Other. Respond with only one of those words."},
{"role": "user", "content": "{{ item.ticket_text }}"}
]
},
"source": { "type": "file_id", "id": "YOUR_FILE_ID" }
}
}'
```
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const run = await openai.evals.runs.create("YOUR_EVAL_ID", {
name: "Categorization text run",
data_source: {
type: "responses",
model: "gpt-4.1",
input_messages: {
type: "template",
template: [
{ role: "developer", content: "You are an expert in categorizing IT support tickets. Given the support ticket below, categorize the request into one of 'Hardware', 'Software', or 'Other'. Respond with only one of those words." },
{ role: "user", content: "{{ item.ticket_text }}" },
],
},
source: { type: "file_id", id: "YOUR_FILE_ID" },
},
});
console.log(run);
```
```python
from openai import OpenAI
client = OpenAI()
run = client.evals.runs.create(
"YOUR_EVAL_ID",
name="Categorization text run",
data_source={
"type": "responses",
"model": "gpt-4.1",
"input_messages": {
"type": "template",
"template": [
{"role": "developer", "content": "You are an expert in categorizing IT support tickets. Given the support ticket below, categorize the request into one of 'Hardware', 'Software', or 'Other'. Respond with only one of those words."},
{"role": "user", "content": "{{ item.ticket_text }}"},
],
},
"source": {"type": "file_id", "id": "YOUR_FILE_ID"},
},
)
print(run)
```
When we create the run, we set up a prompt using either a [Chat Completions](https://developers.openai.com/api/docs/guides/text?api-mode=chat) messages array or a [Responses](https://developers.openai.com/api/docs/api-reference/responses) input. This prompt is used to generate a model response for every line of test data in your data set. We can use the double curly brace syntax to template in the dynamic variable `item.ticket_text`, which is drawn from the current test data item.
If the eval run is successfully created, you'll receive an API response that looks like this:
```json
{
"object": "eval.run",
"id": "evalrun_67e44c73eb6481909f79a457749222c7",
"eval_id": "eval_67e44c5becec81909704be0318146157",
"report_url": "https://platform.openai.com/evaluation/evals/abc123",
"status": "queued",
"model": "gpt-4.1",
"name": "Categorization text run",
"created_at": 1743015028,
"result_counts": { ... },
"per_model_usage": null,
"per_testing_criteria_results": null,
"data_source": {
"type": "responses",
"source": {
"type": "file_id",
"id": "file-J7MoX9ToHXp2TutMEeYnwj"
},
"input_messages": {
"type": "template",
"template": [
{
"type": "message",
"role": "developer",
"content": {
"type": "input_text",
"text": "You are an expert in...."
}
},
{
"type": "message",
"role": "user",
"content": {
"type": "input_text",
"text": "{{item.ticket_text}}"
}
}
]
},
"model": "gpt-4.1",
"sampling_params": null
},
"error": null,
"metadata": {}
}
```
Your eval run has now been queued, and it will execute asynchronously as it processes every row in your data set, generating responses for testing with the prompt and model we specified.
## Analyze the results
To receive updates when a run succeeds, fails, or is canceled, create a webhook endpoint and subscribe to the `eval.run.succeeded`, `eval.run.failed`, and `eval.run.canceled` events. See the [webhooks guide](https://developers.openai.com/api/docs/guides/webhooks) for more details.
Depending on the size of your dataset, the eval run may take some time to complete. You can view current status in the dashboard, but you can also [fetch the current status of an eval run via API](https://developers.openai.com/api/docs/api-reference/evals/getRun):
Retrieve eval run status
```bash
curl https://api.openai.com/v1/evals/YOUR_EVAL_ID/runs/YOUR_RUN_ID \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json"
```
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const run = await openai.evals.runs.retrieve("YOUR_RUN_ID", {
eval_id: "YOUR_EVAL_ID",
});
console.log(run);
```
```python
from openai import OpenAI
client = OpenAI()
run = client.evals.runs.retrieve("YOUR_EVAL_ID", "YOUR_RUN_ID")
print(run)
```
You'll need the UUID of both your eval and eval run to fetch its status. When you do, you'll see eval run data that looks like this:
```json
{
"object": "eval.run",
"id": "evalrun_67e44c73eb6481909f79a457749222c7",
"eval_id": "eval_67e44c5becec81909704be0318146157",
"report_url": "https://platform.openai.com/evaluation/evals/xxx",
"status": "completed",
"model": "gpt-4.1",
"name": "Categorization text run",
"created_at": 1743015028,
"result_counts": {
"total": 3,
"errored": 0,
"failed": 0,
"passed": 3
},
"per_model_usage": [
{
"model_name": "gpt-4o-2024-08-06",
"invocation_count": 3,
"prompt_tokens": 166,
"completion_tokens": 6,
"total_tokens": 172,
"cached_tokens": 0
}
],
"per_testing_criteria_results": [
{
"testing_criteria": "Match output to human label-40d67441-5000-4754-ab8c-181c125803ce",
"passed": 3,
"failed": 0
}
],
"data_source": {
"type": "responses",
"source": {
"type": "file_id",
"id": "file-J7MoX9ToHXp2TutMEeYnwj"
},
"input_messages": {
"type": "template",
"template": [
{
"type": "message",
"role": "developer",
"content": {
"type": "input_text",
"text": "You are an expert in categorizing IT support tickets. Given the support ticket below, categorize the request into one of Hardware, Software, or Other. Respond with only one of those words."
}
},
{
"type": "message",
"role": "user",
"content": {
"type": "input_text",
"text": "{{item.ticket_text}}"
}
}
]
},
"model": "gpt-4.1",
"sampling_params": null
},
"error": null,
"metadata": {}
}
```
The API response contains granular information about test criteria results, API usage for generating model responses, and a `report_url` property that takes you to a page in the dashboard where you can explore the results visually.
In our simple test, the model reliably generated the content we wanted for a small test case sample. In reality, you will often have to run your eval with more criteria, different prompts, and different data sets. But the process above gives you all the tools you need to build robust evals for your LLM apps!
## Next steps
Now you know how to create and run evals via API, and using the dashboard! Here are a few other resources that may be useful to you as you continue to improve your model results.
Keep tabs on the performance of your prompts as you iterate on them.
Compare the results of many different prompts and models at once.
Examine stored completions to test for prompt regressions.
[
Improve a model's ability to generate responses tailored to your use case.
](https://developers.openai.com/api/docs/guides/fine-tuning)
[
Learn how to distill large model results to smaller, cheaper, and faster
models.
](https://developers.openai.com/api/docs/guides/distillation)
---
# SDKs and CLI
This page covers the main ways to build with the [OpenAI API](https://developers.openai.com/api/docs/api-reference): official SDKs for application code, the OpenAI CLI for shell-native workflows, the Agents SDK for orchestration, or your own preferred HTTP client.
## Create and export an API key
Before you begin, [create an API key in the dashboard](https://platform.openai.com/api-keys), which you'll use to securely [access the API](https://developers.openai.com/api/docs/api-reference/authentication). Store the key in a safe location, like a [`.zshrc` file](https://www.freecodecamp.org/news/how-do-zsh-configuration-files-work/) or another text file on your computer. Once you've generated an API key, export it as an [environment variable](https://en.wikipedia.org/wiki/Environment_variable) in your terminal.
macOS / Linux
Export an environment variable on macOS or Linux systems
```bash
export OPENAI_API_KEY="your_api_key_here"
```
Windows
Export an environment variable in PowerShell
```bash
setx OPENAI_API_KEY "your_api_key_here"
```
OpenAI SDKs are configured to automatically read your API key from the system environment.
## Install an official SDK
## Use the Agents SDK
Use the official OpenAI SDKs above for direct API requests. Use the Agents SDK
when your application needs code-first orchestration for agents, tools,
handoffs, guardrails, tracing, or sandbox execution.
Build your first agent with the Agents SDK.
- [OpenAI Agents SDK for TypeScript](https://github.com/openai/openai-agents-js)
- [OpenAI Agents SDK for Python](https://github.com/openai/openai-agents-python)
## Azure OpenAI libraries
Microsoft's Azure team maintains libraries that are compatible with both the OpenAI API and Azure OpenAI services. Read the library documentation below to learn how you can use them with the OpenAI API.
- [Azure OpenAI client library for .NET](https://github.com/Azure/azure-sdk-for-net/tree/main/sdk/openai/Azure.AI.OpenAI)
- [Azure OpenAI client library for JavaScript](https://github.com/Azure/azure-sdk-for-js/tree/main/sdk/openai/openai)
- [Azure OpenAI client library for Java](https://github.com/Azure/azure-sdk-for-java/tree/main/sdk/openai/azure-ai-openai)
- [Azure OpenAI client library for Go](https://github.com/Azure/azure-sdk-for-go/tree/main/sdk/ai/azopenai)
---
## Community libraries
The libraries below are built and maintained by the broader developer community. You can also [watch our OpenAPI specification](https://github.com/openai/openai-openapi) repository on GitHub to get timely updates on when we make changes to our API.
Please note that OpenAI does not verify the correctness or security of these projects. **Use them at your own risk!**
### Clojure
- [openai-clojure](https://github.com/wkok/openai-clojure) by [wkok](https://github.com/wkok)
### Dart/Flutter
- [openai](https://github.com/anasfik/openai) by [anasfik](https://github.com/anasfik)
### Delphi
- [DelphiOpenAI](https://github.com/HemulGM/DelphiOpenAI) by [HemulGM](https://github.com/HemulGM)
### Elixir
- [openai.ex](https://github.com/mgallo/openai.ex) by [mgallo](https://github.com/mgallo)
### Kotlin
- [openai-kotlin](https://github.com/Aallam/openai-kotlin) by [Mouaad Aallam](https://github.com/Aallam)
### PHP
- [orhanerday/open-ai](https://packagist.org/packages/orhanerday/open-ai) by [orhanerday](https://github.com/orhanerday)
- [openai-php client](https://github.com/openai-php/client) by [openai-php](https://github.com/openai-php)
### Rust
- [async-openai](https://github.com/64bit/async-openai) by [64bit](https://github.com/64bit)
### Scala
- [openai-scala-client](https://github.com/cequence-io/openai-scala-client) by [cequence-io](https://github.com/cequence-io)
### Swift
- [AIProxySwift](https://github.com/lzell/AIProxySwift) by [Lou Zell](https://github.com/lzell)
- [OpenAIKit](https://github.com/dylanshine/openai-kit) by [dylanshine](https://github.com/dylanshine)
- [OpenAI](https://github.com/MacPaw/OpenAI/) by [MacPaw](https://github.com/MacPaw)
### Unity
- [com.openai.unity](https://github.com/RageAgainstThePixel/com.openai.unity) by [RageAgainstThePixel](https://github.com/RageAgainstThePixel)
### Unreal Engine
- [OpenAI-Api-Unreal](https://github.com/KellanM/OpenAI-Api-Unreal) by [KellanM](https://github.com/KellanM)
## Other OpenAI repositories
- [tiktoken](https://github.com/openai/tiktoken) - counting tokens
- [simple-evals](https://github.com/openai/simple-evals) - simple evaluation library
- [mle-bench](https://github.com/openai/mle-bench) - library to evaluate machine learning engineer agents
- [gym](https://github.com/openai/gym) - reinforcement learning library
- [swarm](https://github.com/openai/swarm) - educational orchestration repository
---
# OpenAI CLI
Interact with the OpenAI API directly from your terminal with the `openai` command-line tool.
## Installation
Install the CLI with Homebrew:
```bash
brew install openai/tools/openai
```
Or install it with Go 1.25 or later:
```bash
go install 'github.com/openai/openai-cli/cmd/openai@latest'
```
Older versions of the Python SDK also installed a legacy `openai` command. If you already had that package installed and the command you see does not match this guide, your shell may still be resolving the older binary. Fresh CLI installs are not affected.
## Authentication
The CLI reads your API key from `OPENAI_API_KEY`:
Command:
```bash
export OPENAI_API_KEY="sk-..."
```
If you don't have an API key yet, [create one in the dashboard](https://platform.openai.com/api-keys).
For Admin API endpoints, set `OPENAI_ADMIN_KEY` instead. The SDK layer selects the admin key or default API key based on the endpoint being called.
To point at a different API host, set `OPENAI_BASE_URL`.
## Use cases
Use the CLI when the work belongs naturally in the terminal:
- Generate local artifacts such as images or speech.
- Extract structured data into JSONL for later shell steps.
- Use Responses with files, computer use, and current web context in the cloud.
- Create projects and API keys with Admin APIs.
Use it directly for one-off terminal requests, or from scripts when agents need repeatable batch work over files and generated artifacts.
## CLI vs subagents for Codex
Use the CLI for repeatable API work you want to inspect and rerun, such as batch extraction, file transforms, artifact generation, or deliberate model selection. Use subagents when the work still needs judgment, such as exploring code, comparing hypotheses, debugging, or reviewing changes.
## Global flags
These options work across commands:
| Flag | Use |
| ------------- | ------------------------------------------------------------------------------------------------------------ |
| `--format` | Print responses as `auto`, `json`, `jsonl`, `pretty`, `raw`, `yaml`, or `explore`. |
| `--transform` | Extract or reshape response data with a GJSON path before printing. |
| `--debug` | Print request and response details to stderr. Authorization is redacted; review headers before sharing logs. |
This guide focuses on CLI patterns. For the latest arguments and response shapes for any API family, use the live [API reference](https://developers.openai.com/api/reference).
You can also change the base URL when you need to point the CLI at another compatible endpoint, such as a deployment that supports a different model set or only a subset of the API surface.
## Responses
Use Responses for text generation, structured extraction, web search, file understanding, and repeatable Codex-authored batch scripts.
### Send your first request
Command:
```bash
openai responses create \
--model gpt-5.5 \
--input "Say hello in one sentence."
```
Output:
```json
{
"id": "resp_...",
"object": "response",
"status": "completed",
"model": "gpt-5.5-...",
"output": [
{
"type": "message",
"role": "assistant",
"content": [
{
"type": "output_text",
"text": "Hello!"
}
]
}
],
"usage": {
"input_tokens": 12,
"output_tokens": 6,
"total_tokens": 18
},
"...": "additional response fields omitted"
}
```
The CLI prints the full API response object by default. Examples on this page keep representative fields such as `id`, `status`, `model`, `output`, and `usage`, and omit the rest.
Responses output can include non-message items, such as reasoning items, before the assistant message. When you need assistant text, select the message item by type instead of assuming it is always `output[0]`:
```bash
--transform 'output.#(type=="message").content.0.text'
```
### Add a local file to the prompt
For a simple local file, build the prompt inline with command substitution:
```bash
openai responses create \
--model gpt-5.5 \
--input "Summarize this note in one sentence.
$(cat ./note.md)
" \
--format yaml \
--transform 'output.#(type=="message").content.0.text'
```
Output:
```text
The note says the launch checklist is ready except for final support ownership.
```
### Passing request bodies
Use flags for short scalar inputs. Use a YAML heredoc for multiline prompts, tools, files, or nested request bodies. The heredoc can contain the same request fields you would otherwise pass as flags.
Be careful with string values that look like YAML, especially prompts that contain `:` or `{}`. On flags, the generated parser may interpret those values as structured YAML instead of plain text. If a prompt starts looking like configuration, put it under `input: |` in a YAML body instead:
Command:
```bash
openai responses create \
--format yaml \
--transform 'output.#(type=="message").content.0.text' <<'YAML'
model: gpt-5.5
instructions: Return exactly one sentence.
max_output_tokens: 120
input: |
Summarize this release note in one sentence.
Fixed the image generation example and added CLI installation guidance.
YAML
```
Output:
```text
The release note updates the CLI docs with corrected image generation and installation guidance.
```
When the prompt itself needs shell assembly, build a YAML body and pipe it into the command:
```bash
{
printf 'input: |\n'
printf ' Summarize this note in one sentence.\n\n'
printf ' \n'
sed 's/^/ /' ./note.md
printf ' \n'
} | openai responses create \
--model gpt-5.5 \
--format yaml \
--transform 'output.#(type=="message").content.0.text'
```
### Write structured data to JSON
Use structured outputs when downstream scripts need stable JSON. Save reusable schemas to disk:
Save as `schema.json`:
```json
{
"type": "json_schema",
"name": "fact",
"strict": true,
"schema": {
"type": "object",
"additionalProperties": false,
"properties": {
"person": { "type": "string" },
"topic": { "type": "string" }
},
"required": ["person", "topic"]
}
}
```
Command:
```bash
openai responses create \
--model gpt-5.5 \
--instructions "Extract the person and topic from the input." \
--input "Ada Lovelace wrote notes about the Analytical Engine." \
--text.format "$(cat ./schema.json)" \
--format yaml \
--transform 'output.#(type=="message").content.0.text'
```
Output:
```json
{ "person": "Ada Lovelace", "topic": "notes about the Analytical Engine" }
```
### Write structured records to JSONL
When one input may produce many records, ask the model for an array and flatten it into JSONL so later shell steps can process one record per line:
Save as `records-schema.json`:
```json
{
"type": "json_schema",
"name": "items",
"strict": true,
"schema": {
"type": "object",
"additionalProperties": false,
"properties": {
"items": {
"type": "array",
"items": {
"type": "object",
"additionalProperties": false,
"properties": {
"title": { "type": "string" },
"summary": { "type": "string" },
"evidence": { "type": "string" }
},
"required": ["title", "summary", "evidence"]
}
}
},
"required": ["items"]
}
}
```
Command:
```bash
: > records.jsonl
for file in notes/*.md; do
extracted="$(
openai responses create \
--model gpt-5.5 \
--text.format "$(cat ./records-schema.json)" \
--raw-output \
--transform 'output.#(type=="message").content.0.text' <
$(sed 's/^/ /' "$file")
YAML
)"
jq -r --arg source "$file" \
'.items[]? + {source: $source} | @json' \
<<<"$extracted" >> records.jsonl
done
```
This keeps the model response structured while producing one JSON object per line for later shell steps.
### Web search
Responses can call hosted tools from the same YAML request body:
Command:
```bash
openai responses create \
--model gpt-5.5 \
--format yaml \
--transform 'output.#(type=="message").content.0.text' <<'YAML'
tools:
- type: web_search
input: |
Research the latest material news for AAPL.
Return three concise bullets and cite sources in the text.
YAML
```
Output:
```text
- Apple announced ...
- Analysts highlighted ...
- The company said ...
```
### File inputs
For uploaded files such as PDFs, create the file first, capture its ID, and pass it as `input_file.file_id`:
Command:
```bash
FILE_ID=$(
openai files create \
--file ./brief.pdf \
--purpose user_data \
--format yaml \
--transform id
)
openai responses create \
--model gpt-5.5 \
--format yaml \
--transform 'output.#(type=="message").content.0.text' < hero.png
printf 'wrote hero.png\n'
```
Output:
```text
wrote hero.png
```
Current limitation: image commands do not yet have native `--output` support, so image generation still requires extracting `b64_json` and decoding it yourself.
For `gpt-image-2`, omit `--input-fidelity`; image inputs are always processed at high fidelity. Do not use `--background transparent` with `gpt-image-2`. The model also supports broader `--size` values than earlier GPT Image models, as long as the requested resolution satisfies the Image API size constraints.
### Edit an image
Image editing uses the same base64 extraction pattern after the edit request succeeds:
Command:
```bash
openai images edit \
--model gpt-image-2 \
--image ./hero.png \
--prompt "Turn the cube bright green." \
--format yaml \
--transform 'data.0.b64_json' | base64 --decode > hero-edited.png
printf 'wrote hero-edited.png\n'
```
Output:
```text
wrote hero-edited.png
```
If a local image edit upload fails with an `UploadFile` type error, update the CLI and retry.
## Speech
Create an MP3 locally with the speech API:
Command:
```bash
openai audio:speech create \
--model gpt-4o-mini-tts \
--voice marin \
--input "The OpenAI CLI can call the API from ordinary shell scripts." \
--output speech.mp3
```
Output:
```text
Wrote output to: speech.mp3
```
Play it with whatever local audio tool is available on your machine. On macOS:
```bash
afplay speech.mp3
```
Use `--instructions` to shape delivery and `--input` for the words that should be spoken. Instructions work well for cues such as pace, energy, warmth, formality, emphasis, or audience:
```bash
openai audio:speech create \
--model gpt-4o-mini-tts \
--voice marin \
--instructions "Whisper very quickly, like a hurried stage cue, while staying clear and intelligible." \
--input "The launch checklist is ready. Please send final feedback by Friday at noon." \
--output reminder.mp3
```
## Transcription
Print plain transcript text for shell pipelines:
Command:
```bash
openai audio:transcriptions create \
--model gpt-4o-transcribe \
--file ./speech.mp3 \
--transform text \
--raw-output
```
Output:
```text
The OpenAI CLI can call the API from ordinary shell scripts.
```
Use the response format that matches the artifact you need:
| Need | Command shape |
| --------------------------- | -------------------------------------------------------------------- |
| Plain transcript text | `--model gpt-4o-transcribe --transform text --raw-output` |
| Subtitle files | `--model whisper-1 --response-format srt` or `--response-format vtt` |
| Segment or word timestamps | `--model whisper-1 --response-format verbose_json` |
| Speaker-labeled diarization | `--model gpt-4o-transcribe-diarize --response-format diarized_json` |
For word-level timing, request the verbose transcription shape:
Command:
```bash
openai audio:transcriptions create \
--model whisper-1 \
--file ./speech.mp3 \
--response-format verbose_json \
--timestamp-granularity word \
--format json
```
Output:
```json
{
"task": "transcribe",
"language": "english",
"duration": 6,
"text": "The OpenAI CLI can call the API from ordinary shell scripts.",
"words": [
{ "word": "The", "start": 0, "end": 0.42 },
{ "word": "OpenAI", "start": 0.42, "end": 1.22 }
],
"...": "additional response fields omitted"
}
```
For speaker-labeled output, use the diarization model and request `diarized_json`:
Command:
```bash
openai audio:transcriptions create \
--model gpt-4o-transcribe-diarize \
--file ./speech.mp3 \
--response-format diarized_json \
--format json
```
Output:
```json
{
"text": "The OpenAI CLI can call the API from ordinary shell scripts.",
"segments": [
{
"type": "transcript.text.segment",
"id": "seg_0",
"start": 0.05,
"end": 5.25,
"text": " The OpenAI CLI can call the API from ordinary shell scripts.",
"speaker": "A"
}
],
"...": "additional response fields omitted"
}
```
`whisper-1` supports `json`, `text`, `srt`, `verbose_json`, and `vtt`. `diarized_json` is the format that carries `segments[].speaker`; with the same diarization model and plain `json`, the response contains transcript text but not speaker labels.
## Admin APIs
Use Admin APIs for organization management, credential provisioning, compliance, and usage-monitoring workflows. Set `OPENAI_ADMIN_KEY`, then call the generated `admin:organization:*` commands.
To provision a new machine credential, [create a project](https://developers.openai.com/api/reference/resources/admin/subresources/organization/subresources/projects/methods/create), [create a service account](https://developers.openai.com/api/reference/resources/admin/subresources/organization/subresources/projects/subresources/service_accounts/methods/create) inside that project, and use the returned API key.
### Create a project, service account, and API key
Creating a service account in that project returns an unredacted API key for the service account.
Command:
```bash
# Create the project that will own this app or agent and save the response.
openai admin:organization:projects create \
--name "automation project" \
--format json > project.json
PROJECT_ID="$(jq -r '.id' project.json)"
# Create a service account inside the project and save the full response.
openai admin:organization:projects:service-accounts create \
--project-id "$PROJECT_ID" \
--name "automation bot" \
--format json > service-account.json
# Extract the returned API key into an env file for the workload to use.
jq -r '.api_key.value | "OPENAI_API_KEY=\(.)"' \
service-account.json > .env
```
Output:
```json
{
"object": "organization.project.service_account",
"id": "svc_acct_...",
"name": "automation bot",
"role": "member",
"api_key": {
"id": "key_...",
"value": "sk-..."
}
}
```
This writes the project response to `project.json`, parses its ID into the next command, writes the service-account response to `service-account.json`, and writes the returned credential to `.env` as `OPENAI_API_KEY=...`. Treat both JSON files as secrets, and add `project.json`, `service-account.json`, and `.env` to `.gitignore` before using this pattern in a repository.
For the rest of the surface, see the [Admin APIs guide](https://developers.openai.com/api/docs/guides/admin-apis) and the current [Administration API reference](https://developers.openai.com/api/reference/administration/overview). Be careful about giving unvetted actors access to admin keys.
---
# Building MCP servers for ChatGPT Apps and API integrations
[Model Context Protocol](https://modelcontextprotocol.io/introduction) (MCP) is an open protocol that's becoming the industry standard for extending AI models with additional tools and knowledge. Remote MCP servers can be used to connect models over the Internet to new data sources and capabilities.
In this guide, we'll cover how to build a remote MCP server that reads data from a private data source (a [vector store](https://developers.openai.com/api/docs/guides/retrieval)) and makes it available in ChatGPT as a data-only app (formerly called a connector) for chat, deep research, and company knowledge, as well as [via API](https://developers.openai.com/api/docs/guides/deep-research).
**Note**: For ChatGPT app setup (developer mode, connecting your MCP server, and optional UI), start with the Apps SDK docs: [Quickstart](https://developers.openai.com/apps-sdk/quickstart), [Build your MCP server](https://developers.openai.com/apps-sdk/build/mcp-server), [Connect from ChatGPT](https://developers.openai.com/apps-sdk/deploy/connect-chatgpt), and [Authentication](https://developers.openai.com/apps-sdk/build/auth). If you are building a data-only app, you can skip UI resources and just expose tools.
**Terminology update**: As of **December 17, 2025**, ChatGPT renamed connectors to apps. Existing functionality remains, but current docs and product UI use "apps". See the Help Center updates: [ChatGPT apps with sync](https://help.openai.com/en/articles/10847137-chatgpt-apps-with-sync), [Company knowledge in ChatGPT](https://help.openai.com/en/articles/12628342-company-knowledge-in-chatgpt-business-enterprise-and-edu), and [Admin controls, security, and compliance in apps](https://help.openai.com/en/articles/11509118-admin-controls-security-and-compliance-in-apps-connectors-enterprise-edu-and-business).
## Configure a data source
You can use data from any source to power a remote MCP server, but for simplicity, we will use [vector stores](https://developers.openai.com/api/docs/guides/retrieval) in the OpenAI API. Begin by uploading a PDF document to a new vector store - [you can use this public domain 19th century book about cats](https://cdn.openai.com/API/docs/cats.pdf) for an example.
You can upload files and create a vector store [in the dashboard here](https://platform.openai.com/storage/vector_stores), or you can create vector stores and upload files via API. [Follow the vector store guide](https://developers.openai.com/api/docs/guides/retrieval) to set up a vector store and upload a file to it.
Make a note of the vector store's unique ID to use in the example to follow.
## Create an MCP server
Next, let's create a remote MCP server that will do search queries against our vector store, and be able to return document content for files with a given ID.
In this example, we are going to build our MCP server using Python and [FastMCP](https://github.com/jlowin/fastmcp). A full implementation of the server will be provided at the end of this section, along with instructions for running it on [Replit](https://replit.com/).
Note that there are a number of other MCP server frameworks you can use in a variety of programming languages. Whichever framework you use though, the tool definitions in your server will need to conform to the shape described here.
To work with ChatGPT deep research and company knowledge (and deep research via API), your MCP server should implement two read-only tools: `search` and `fetch`, using the compatibility schema in [Company knowledge compatibility](https://developers.openai.com/apps-sdk/build/mcp-server#company-knowledge-compatibility).
Declare an output schema for each tool so clients can validate the result shape.
In FastMCP, typed return models can generate this schema automatically; the
example below passes `output_schema` explicitly from the same models.
### `search` tool
The `search` tool is responsible for returning a list of relevant search results from your MCP server's data source, given a user's query.
_Arguments:_
A single query string.
_Returns:_
An object with a single key, `results`, whose value is an array of result objects. Each result object should include:
- `id` - a unique ID for the document or search result item
- `title` - human-readable title.
- `url` - canonical URL for citation.
In MCP, return this object as `structuredContent` and include the same value as
a JSON-encoded string in the [content array](https://modelcontextprotocol.io/docs/learn/architecture#understanding-the-tool-execution-response)
for compatibility.
The final tool response should look like:
```json
{
"structuredContent": {
"results": [{ "id": "doc-1", "title": "...", "url": "..." }]
},
"content": [
{
"type": "text",
"text": "{\"results\":[{\"id\":\"doc-1\",\"title\":\"...\",\"url\":\"...\"}]}"
}
]
}
```
### `fetch` tool
The fetch tool is used to retrieve the full contents of a search result document or item.
_Arguments:_
A string which is a unique identifier for the search document.
_Returns:_
A single object with the following properties:
- `id` - a unique ID for the document or search result item
- `title` - a string title for the search result item
- `text` - The full text of the document or item
- `url` - a URL to the document or search result item. Useful for citing
specific resources in research.
- `metadata` - an optional key/value pairing of data about the result
In MCP, return this object as `structuredContent` and include the same value as
a JSON-encoded string in the content array for compatibility.
The final tool response should look like:
```json
{
"structuredContent": {
"id": "doc-1",
"title": "...",
"text": "full text...",
"url": "https://example.com/doc",
"metadata": { "source": "vector_store" }
},
"content": [
{
"type": "text",
"text": "{\"id\":\"doc-1\",\"title\":\"...\",\"text\":\"full text...\",\"url\":\"https://example.com/doc\",\"metadata\":{\"source\":\"vector_store\"}}"
}
]
}
```
### Server example
An easy way to try out this example MCP server is using [Replit](https://replit.com/). You can configure this sample application with your own API credentials and vector store information to try it yourself.
Remix the server example on Replit to test live.
A full implementation of both the `search` and `fetch` tools in FastMCP is below also for convenience.
Full implementation - FastMCP server
```python
"""
Sample MCP Server for ChatGPT Integration
This server implements the Model Context Protocol (MCP) with search and fetch
capabilities designed to work with ChatGPT's chat and deep research features.
"""
import logging
import os
from typing import Any
from fastmcp import FastMCP
from openai import OpenAI
from pydantic import BaseModel
class SearchResult(BaseModel):
id: str
title: str
url: str
class SearchOutput(BaseModel):
results: list[SearchResult]
class FetchOutput(BaseModel):
id: str
title: str
text: str
url: str
metadata: dict[str, Any] | None = None
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# OpenAI configuration
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
VECTOR_STORE_ID = os.environ.get("VECTOR_STORE_ID", "")
# Initialize OpenAI client
openai_client = OpenAI()
server_instructions = """
This MCP server provides search and document retrieval capabilities
for ChatGPT Apps and deep research. Use the search tool to find relevant documents
based on keywords, then use the fetch tool to retrieve complete
document content with citations.
"""
def create_server():
"""Create and configure the MCP server with search and fetch tools."""
# Initialize the FastMCP server
mcp = FastMCP(name="Sample MCP Server",
instructions=server_instructions)
@mcp.tool(output_schema=SearchOutput.model_json_schema())
async def search(query: str) -> SearchOutput:
"""
Search for documents using OpenAI Vector Store search.
This tool searches through the vector store to find semantically relevant matches.
Returns a list of search results with basic information. Use the fetch tool to get
complete document content.
Args:
query: Search query string. Natural language queries work best for semantic search.
Returns:
Dictionary with 'results' key containing list of matching documents.
Each result includes id, title, and URL.
"""
if not query or not query.strip():
return SearchOutput(results=[])
if not openai_client:
logger.error("OpenAI client not initialized - API key missing")
raise ValueError(
"OpenAI API key is required for vector store search")
# Search the vector store using OpenAI API
logger.info(f"Searching {VECTOR_STORE_ID} for query: '{query}'")
response = openai_client.vector_stores.search(
vector_store_id=VECTOR_STORE_ID, query=query)
results = []
# Process the vector store search results
if hasattr(response, 'data') and response.data:
for i, item in enumerate(response.data):
# Extract file_id, filename, and content
item_id = getattr(item, 'file_id', f"vs_{i}")
item_filename = getattr(item, 'filename', f"Document {i+1}")
result = SearchResult(
id=item_id,
title=item_filename,
url=f"https://platform.openai.com/storage/files/{item_id}",
)
results.append(result)
logger.info(f"Vector store search returned {len(results)} results")
return SearchOutput(results=results)
@mcp.tool(output_schema=FetchOutput.model_json_schema())
async def fetch(id: str) -> FetchOutput:
"""
Retrieve complete document content by ID for detailed
analysis and citation. This tool fetches the full document
content from OpenAI Vector Store. Use this after finding
relevant documents with the search tool to get complete
information for analysis and proper citation.
Args:
id: File ID from vector store (file-xxx) or local document ID
Returns:
Complete document with id, title, full text content,
optional URL, and metadata
Raises:
ValueError: If the specified ID is not found
"""
if not id:
raise ValueError("Document ID is required")
if not openai_client:
logger.error("OpenAI client not initialized - API key missing")
raise ValueError(
"OpenAI API key is required for vector store file retrieval")
logger.info(f"Fetching content from vector store for file ID: {id}")
# Fetch file content from vector store
content_response = openai_client.vector_stores.files.content(
vector_store_id=VECTOR_STORE_ID, file_id=id)
# Get file metadata
file_info = openai_client.vector_stores.files.retrieve(
vector_store_id=VECTOR_STORE_ID, file_id=id)
# Extract content from paginated response
file_content = ""
if hasattr(content_response, 'data') and content_response.data:
# Combine all content chunks from FileContentResponse objects
content_parts = []
for content_item in content_response.data:
if hasattr(content_item, 'text'):
content_parts.append(content_item.text)
file_content = "\n".join(content_parts)
else:
file_content = "No content available"
# Use filename as title and create proper URL for citations
filename = getattr(file_info, 'filename', f"Document {id}")
result = FetchOutput(
id=id,
title=filename,
text=file_content,
url=f"https://platform.openai.com/storage/files/{id}",
)
# Add metadata if available from file info
if hasattr(file_info, 'attributes') and file_info.attributes:
result.metadata = dict(file_info.attributes)
logger.info(f"Fetched vector store file: {id}")
return result
return mcp
def main():
"""Main function to start the MCP server."""
# Verify OpenAI client is initialized
if not openai_client:
logger.error(
"OpenAI API key not found. Please set OPENAI_API_KEY environment variable."
)
raise ValueError("OpenAI API key is required")
logger.info(f"Using vector store: {VECTOR_STORE_ID}")
# Create the MCP server
server = create_server()
# Configure and start the server
logger.info("Starting MCP server on 0.0.0.0:8000")
logger.info("Server will be accessible via SSE transport")
try:
# Use FastMCP's built-in run method with SSE transport
server.run(transport="sse", host="0.0.0.0", port=8000)
except KeyboardInterrupt:
logger.info("Server stopped by user")
except Exception as e:
logger.error(f"Server error: {e}")
raise
if __name__ == "__main__":
main()
```
Replit setup
On Replit, you will need to configure two environment variables in the "Secrets" UI:
- `OPENAI_API_KEY` - Your standard OpenAI API key
- `VECTOR_STORE_ID` - The unique identifier of a vector store that can be used for search - the one you created earlier.
On free Replit accounts, server URLs are active for as long as the editor is active, so while you are testing, you'll need to keep the browser tab open. You can get a URL for your MCP server by clicking on the chainlink icon:
In the long dev URL, ensure it ends with `/sse/`, which is the server-sent events (streaming) interface to the MCP server. This is the URL you will use to connect your app in ChatGPT and call it via API. An example Replit URL looks like:
```
https://777xxx.janeway.replit.dev/sse/
```
## Test and connect your MCP server
You can test your MCP server with a deep research model [in the prompts dashboard](https://platform.openai.com/chat). Create a new prompt, or edit an existing one, and add a new MCP tool to the prompt configuration. Remember that MCP servers used via API for deep research have to be configured with no approval required.
If you are testing this server in ChatGPT as an app, follow [Connect from ChatGPT](https://developers.openai.com/apps-sdk/deploy/connect-chatgpt).
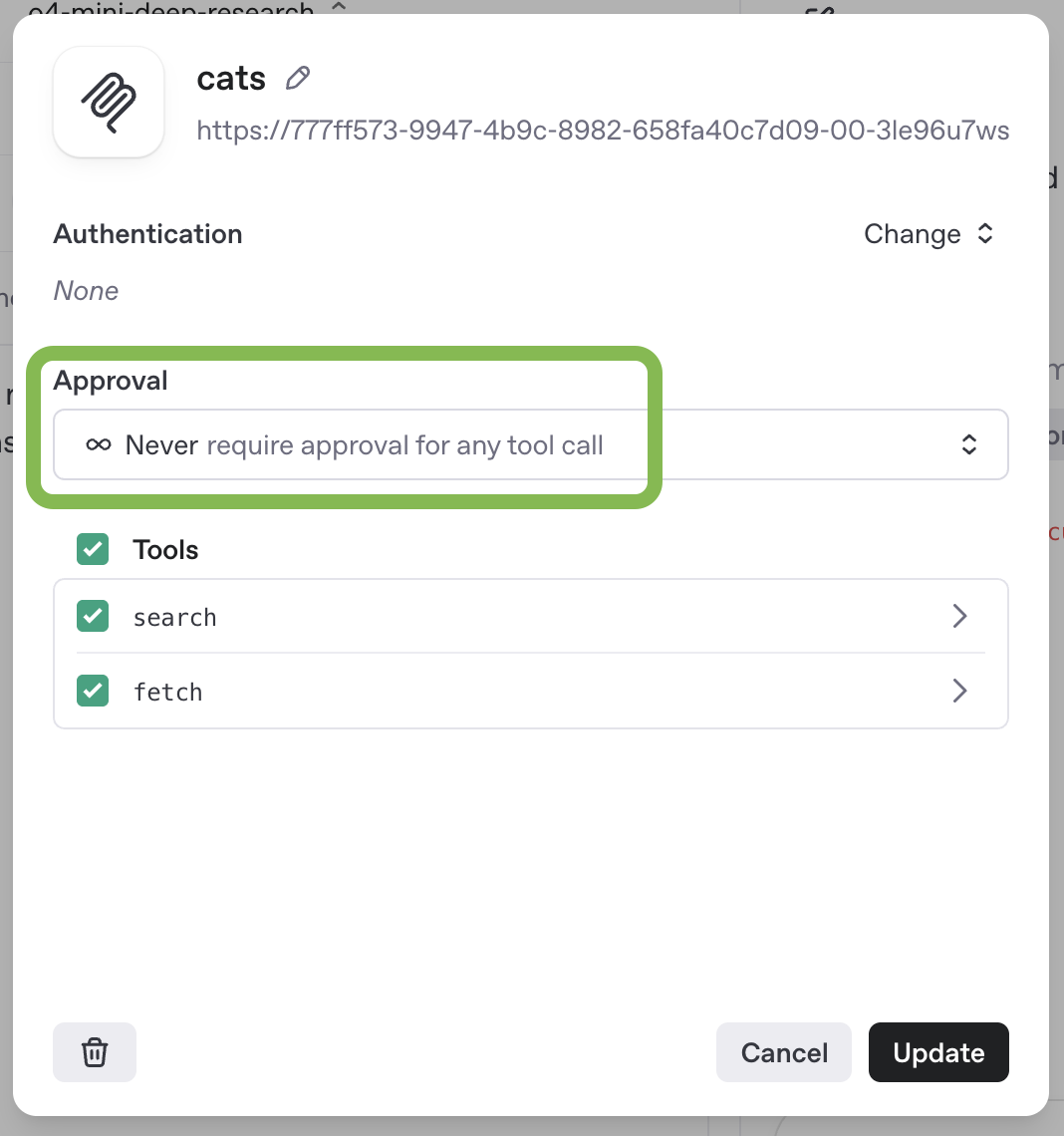
Once you have configured your MCP server, you can chat with a model using it via the Prompts UI.
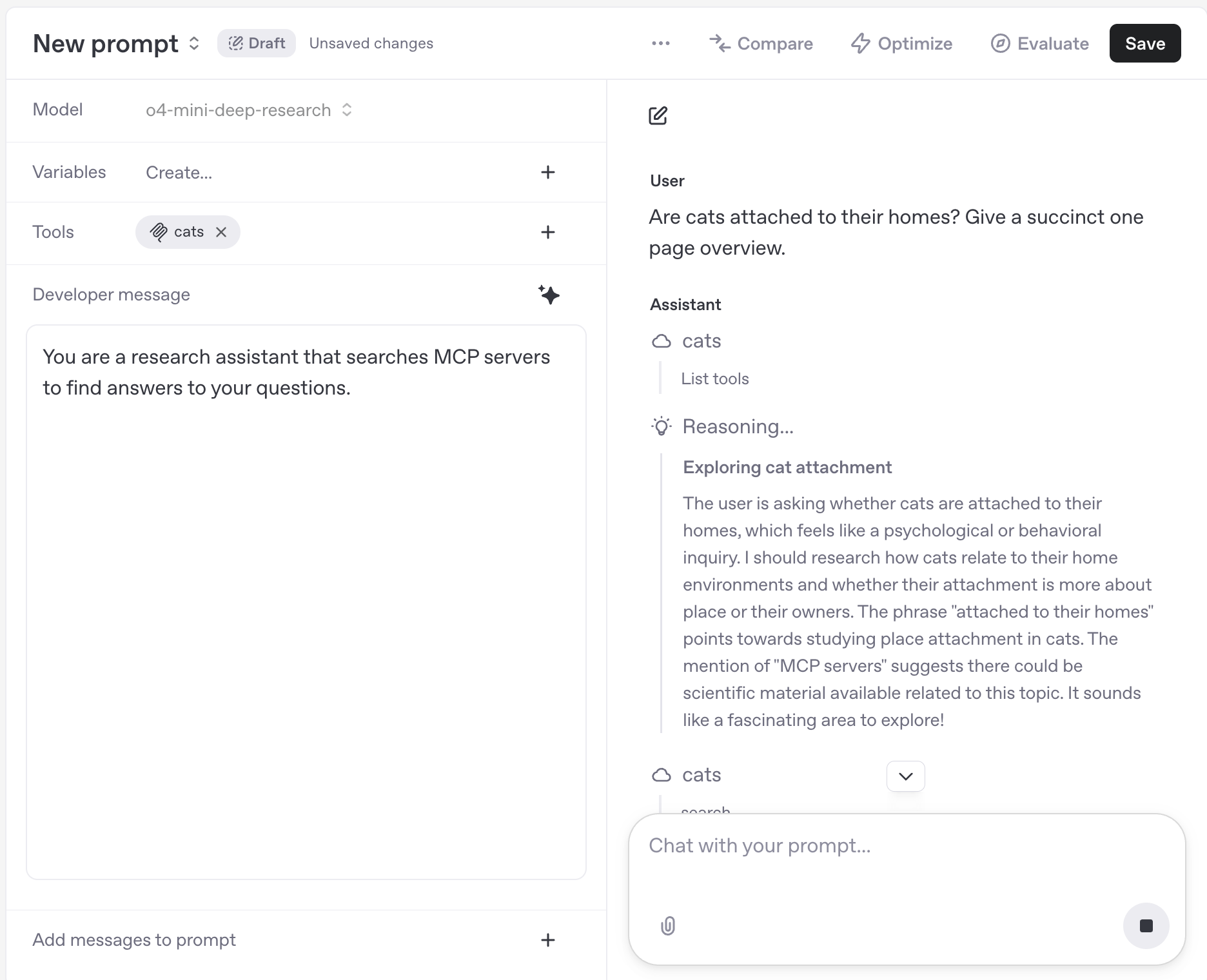
You can test the MCP server using the Responses API directly with a request like this one:
```bash
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o4-mini-deep-research",
"input": [
{
"role": "developer",
"content": [
{
"type": "input_text",
"text": "You are a research assistant that searches MCP servers to find answers to your questions."
}
]
},
{
"role": "user",
"content": [
{
"type": "input_text",
"text": "Are cats attached to their homes? Give a succinct one page overview."
}
]
}
],
"reasoning": {
"summary": "auto"
},
"tools": [
{
"type": "mcp",
"server_label": "cats",
"server_url": "https://777ff573-9947-4b9c-8982-658fa40c7d09-00-3le96u7wsymx.janeway.replit.dev/sse/",
"allowed_tools": [
"search",
"fetch"
],
"require_approval": "never"
}
]
}'
```
### Handle authentication
As someone building a custom remote MCP server, authorization and authentication help you protect your data. We recommend using OAuth with [Client ID Metadata Documents](https://modelcontextprotocol.io/specification/2025-11-25/basic/authorization#client-id-metadata-documents) for client registration when your authorization server supports CIMD and the connector creator chooses it. ChatGPT supports CIMD with public-client token exchange (`none`) or signed client assertion token exchange (`private_key_jwt`). Dynamic client registration remains supported when configured. For ChatGPT app auth requirements, see [Authentication](https://developers.openai.com/apps-sdk/build/auth). For protocol details, read the [MCP user guide](https://modelcontextprotocol.io/docs/concepts/transports#authentication-and-authorization) or the [authorization specification](https://modelcontextprotocol.io/specification/2025-11-25/basic/authorization).
If you connect your custom remote MCP server in ChatGPT as an app, users in your workspace will get an OAuth flow to your application.
### Connect in ChatGPT
1. Import your remote MCP server in [ChatGPT settings](https://chatgpt.com/#settings).
1. Create and configure your app in **Apps & Connectors** using your server URL.
1. Test your app by running prompts in chat and deep research.
For detailed setup steps, see [Connect from ChatGPT](https://developers.openai.com/apps-sdk/deploy/connect-chatgpt).
## Risks and safety
Custom MCP servers enable you to connect your ChatGPT workspace to external applications, which allows ChatGPT to access, send and receive data in these applications. Please note that custom MCP servers are not developed or verified by OpenAI, and are third-party services that are subject to their own terms and conditions.
If you come across a malicious MCP server, please report it to security@openai.com.
### Prompt injection-related risks
Prompt injections are a form of attack where an attacker embeds malicious instructions in content that one of our models is likely to encounter–such as a webpage–with the intention that the instructions override ChatGPT’s intended behavior. If the model obeys the injected instructions it may take actions the user and developer never intended—including sending private data to an external destination.
For example, you might ask ChatGPT to find a restaurant for a group dinner by checking your calendar and recent emails. While researching, it might encounter a malicious comment—essentially a harmful piece of content designed to trick the agent into performing unintended actions—directing it to retrieve a password reset code from Gmail and send it to a malicious website.
Below is a table of specific scenarios to consider. We recommend reviewing this table carefully to inform your decision about whether to use custom MCPs.
| Scenario / Risk | Is it safe if I trust the MCP’s developer? | What can I do to reduce risk? |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| An attacker may somehow insert a prompt injection attack into data accessible via the MCP.
_Examples:_
• For a customer support MCP, an attacker could send you a customer support request with a prompt injection attack. | Trusting a MCP’s developer does not make this safe.
For this to be safe you need to trust _all content that can be accessed within the MCP_. | • Do not use a MCP if it could contain malicious or untrusted user input, even if you trust the developer of the MCP.
• Configure access to minimize how many people have access to the MCP. |
| A malicious MCP may request excessive parameters to a read or write action.
_Example:_
• An employee flight booking MCP could expose a read action to get a flight schedule, but request parameters including `summaryOfConversation`, `userAnnualIncome`, `userHomeAddress`. | Trusting a MCP’s developer does not necessarily make this safe.
A MCP’s developer may consider it reasonable to be requesting certain data that you do not consider acceptable to share. | • When sideloading MCPs, carefully review the parameters being requested for each action and ensure there is no privacy overreach. |
| An attacker may use a prompt injection attack to trick ChatGPT into fetching sensitive data from a custom MCP, to then be sent to the attacker.
_Example:_
• An attacker may deliver a prompt injection attack to one of the enterprise users via a different MCP (e.g. for email), where the attack attempts to trick ChatGPT into reading sensitive data from some internal tool MCP and then attempt to exfiltrate it. | Trusting a MCP’s developer does not make this safe.
Everything within the new MCP could be safe and trusted since the risk is this data being stolen by attacks coming from a different malicious source. | • _ChatGPT is designed to protect users_, but attackers may attempt to steal your data, so be aware of the risk and consider whether taking it makes sense.
• Configure access to minimize how many people have access to MCPs with particularly sensitive data. |
| An attacker may use a prompt injection attack to exfiltrate sensitive information through a write action to a custom MCP.
_Example:_
• An attacker uses a prompt injection attack (via a different MCP) to trick ChatGPT into fetching sensitive data, and then exfiltrates it by tricking ChatGPT into using a MCP for a customer support system to send it to the attacker. | Trusting a MCP’s developer does not make this safe.
Even if you fully trust the MCP, if write actions have any consequences that can be observed by an attacker, they could attempt to take advantage of it. | • Users should review write actions carefully when they happen (to ensure they were intended and do not contain any data that shouldn’t be shared). |
| An attacker may use a prompt injection attack to exfiltrate sensitive information through a read action to a malicious custom MCP (since these can be logged by the MCP). | This attack only works if the MCP is malicious, or if the MCP incorrectly marks write actions as read actions.
If you trust a MCP’s developer to correctly only mark read actions as _read_, and trust that developer to not attempt to steal data, then this risk is likely minimal. | • Only use MCPs from developers that you trust (though note this isn’t sufficient to make it safe). |
| An attacker may use a prompt injection attack to trick ChatGPT into taking a harmful or destructive write action via a custom MCP that users did not intend. | Trusting a MCP’s developer does not make this safe.
Everything within the new MCP could be safe and trusted, and this risk still exists since the attack comes from a different malicious source. | • Users should carefully review write actions to ensure they are intended and correct.
• ChatGPT is designed to protect users, but attackers may attempt to trick ChatGPT into taking unintended write actions.
• Configure access to minimize how many people have access to MCPs with particularly sensitive data. |
### Non-prompt injection related risks
There are additional risks of custom MCPs, unrelated to prompt injection attacks:
- **Write actions can increase both the usefulness and the risks of MCP servers**, because they make it possible for the server to take potentially destructive actions rather than simply providing information back to ChatGPT. ChatGPT currently requires manual confirmation in any conversation before write actions can be taken. The confirmation will flag potentially sensitive data but you should only use write actions in situations where you have carefully considered, and are comfortable with, the possibility that ChatGPT might make a mistake involving such an action. It is possible for write actions to occur even if the MCP server has tagged the action as read only, making it even more important that you trust the custom MCP server before deploying to ChatGPT.
- **Any MCP server may receive sensitive data as part of querying**. Even when the server is not malicious, it will have access to whatever data ChatGPT supplies during the interaction, potentially including sensitive data the user may earlier have provided to ChatGPT. For instance, such data could be included in queries ChatGPT sends to the MCP server when using deep research or chat app tools.
### Connecting to trusted servers
We recommend that you do not connect to a custom MCP server unless you know and trust the underlying application.
For example, always pick official servers hosted by the service providers themselves (e.g., connect to the Stripe server hosted by Stripe themselves on mcp.stripe.com, instead of an unofficial Stripe MCP server hosted by a third party). Because there aren't many official MCP servers today, you may be tempted to use a MCP server hosted by an organization that doesn't operate that server and simply proxies requests to that service via an API. This is not recommended—and you should only connect to an MCP once you’ve carefully reviewed how they use your data and have verified that you can trust the server. When building and connecting to your own MCP server, double check that it's the correct server. Be very careful with which data you provide in response to requests to your MCP server, and with how you treat the data sent to you as part of OpenAI calling your MCP server.
Your remote MCP server permits others to connect OpenAI to your services and allows OpenAI to access, send and receive data, and take action in these services. Avoid putting any sensitive information in the JSON for your tools, and avoid storing any sensitive information from ChatGPT users accessing your remote MCP server.
As someone building an MCP server, don't put anything malicious in your tool definitions.
---
# Pricing
import {
GroupedPricingTable,
PricingTable,
pricingHtml,
pricingTooltipHeading,
TextTokenPricingTables,
withDataSharing,
withLegacy,
} from "./pricing.jsx";
 Below is the full Open API Schema that the Actions GPT Returned:
```yaml
openapi: 3.1.0
info:
title: NWS Weather API
description: Access to weather data including forecasts, alerts, and observations.
version: 1.0.0
servers:
- url: https://api.weather.gov
description: Main API Server
paths:
/points/{latitude},{longitude}:
get:
operationId: getPointData
summary: Get forecast grid endpoints for a specific location
parameters:
- name: latitude
in: path
required: true
schema:
type: number
format: float
description: Latitude of the point
- name: longitude
in: path
required: true
schema:
type: number
format: float
description: Longitude of the point
responses:
"200":
description: Successfully retrieved grid endpoints
content:
application/json:
schema:
type: object
properties:
properties:
type: object
properties:
forecast:
type: string
format: uri
forecastHourly:
type: string
format: uri
forecastGridData:
type: string
format: uri
/gridpoints/{office}/{gridX},{gridY}/forecast:
get:
operationId: getGridpointForecast
summary: Get forecast for a given grid point
parameters:
- name: office
in: path
required: true
schema:
type: string
description: Weather Forecast Office ID
- name: gridX
in: path
required: true
schema:
type: integer
description: X coordinate of the grid
- name: gridY
in: path
required: true
schema:
type: integer
description: Y coordinate of the grid
responses:
"200":
description: Successfully retrieved gridpoint forecast
content:
application/json:
schema:
type: object
properties:
properties:
type: object
properties:
periods:
type: array
items:
type: object
properties:
number:
type: integer
name:
type: string
startTime:
type: string
format: date-time
endTime:
type: string
format: date-time
temperature:
type: integer
temperatureUnit:
type: string
windSpeed:
type: string
windDirection:
type: string
icon:
type: string
format: uri
shortForecast:
type: string
detailedForecast:
type: string
```
ChatGPT uses the **info** at the top (including the description in particular) to determine if this action is relevant for the user query.
```yaml
info:
title: NWS Weather API
description: Access to weather data including forecasts, alerts, and observations.
version: 1.0.0
```
Then the **parameters** below further define each part of the schema. For example, we're informing ChatGPT that the _office_ parameter refers to the Weather Forecast Office (WFO).
```yaml
/gridpoints/{office}/{gridX},{gridY}/forecast:
get:
operationId: getGridpointForecast
summary: Get forecast for a given grid point
parameters:
- name: office
in: path
required: true
schema:
type: string
description: Weather Forecast Office ID
```
**Key:** Pay special attention to the **schema names** and **descriptions** that you use in this Open API schema. ChatGPT uses those names and descriptions to understand (a) which API action should be called and (b) which parameter should be used. If a field is restricted to only certain values, you can also provide an "enum" with descriptive category names.
While you can just try the Open API schema directly in a GPT Action, debugging directly in ChatGPT can be a challenge. We recommend using a 3rd party service, like [Postman](https://www.postman.com/), to test that your API call is working properly. Postman is free to sign up, verbose in its error-handling, and comprehensive in its authentication options. It even gives you the option of importing Open API schemas directly (see below).
Below is the full Open API Schema that the Actions GPT Returned:
```yaml
openapi: 3.1.0
info:
title: NWS Weather API
description: Access to weather data including forecasts, alerts, and observations.
version: 1.0.0
servers:
- url: https://api.weather.gov
description: Main API Server
paths:
/points/{latitude},{longitude}:
get:
operationId: getPointData
summary: Get forecast grid endpoints for a specific location
parameters:
- name: latitude
in: path
required: true
schema:
type: number
format: float
description: Latitude of the point
- name: longitude
in: path
required: true
schema:
type: number
format: float
description: Longitude of the point
responses:
"200":
description: Successfully retrieved grid endpoints
content:
application/json:
schema:
type: object
properties:
properties:
type: object
properties:
forecast:
type: string
format: uri
forecastHourly:
type: string
format: uri
forecastGridData:
type: string
format: uri
/gridpoints/{office}/{gridX},{gridY}/forecast:
get:
operationId: getGridpointForecast
summary: Get forecast for a given grid point
parameters:
- name: office
in: path
required: true
schema:
type: string
description: Weather Forecast Office ID
- name: gridX
in: path
required: true
schema:
type: integer
description: X coordinate of the grid
- name: gridY
in: path
required: true
schema:
type: integer
description: Y coordinate of the grid
responses:
"200":
description: Successfully retrieved gridpoint forecast
content:
application/json:
schema:
type: object
properties:
properties:
type: object
properties:
periods:
type: array
items:
type: object
properties:
number:
type: integer
name:
type: string
startTime:
type: string
format: date-time
endTime:
type: string
format: date-time
temperature:
type: integer
temperatureUnit:
type: string
windSpeed:
type: string
windDirection:
type: string
icon:
type: string
format: uri
shortForecast:
type: string
detailedForecast:
type: string
```
ChatGPT uses the **info** at the top (including the description in particular) to determine if this action is relevant for the user query.
```yaml
info:
title: NWS Weather API
description: Access to weather data including forecasts, alerts, and observations.
version: 1.0.0
```
Then the **parameters** below further define each part of the schema. For example, we're informing ChatGPT that the _office_ parameter refers to the Weather Forecast Office (WFO).
```yaml
/gridpoints/{office}/{gridX},{gridY}/forecast:
get:
operationId: getGridpointForecast
summary: Get forecast for a given grid point
parameters:
- name: office
in: path
required: true
schema:
type: string
description: Weather Forecast Office ID
```
**Key:** Pay special attention to the **schema names** and **descriptions** that you use in this Open API schema. ChatGPT uses those names and descriptions to understand (a) which API action should be called and (b) which parameter should be used. If a field is restricted to only certain values, you can also provide an "enum" with descriptive category names.
While you can just try the Open API schema directly in a GPT Action, debugging directly in ChatGPT can be a challenge. We recommend using a 3rd party service, like [Postman](https://www.postman.com/), to test that your API call is working properly. Postman is free to sign up, verbose in its error-handling, and comprehensive in its authentication options. It even gives you the option of importing Open API schemas directly (see below).
 ## Step 2: Identify authentication requirements
This Weather 3rd party service does not require authentication, so you can skip that step for this Custom GPT. For other GPT Actions that do require authentication, there are 2 options: API Key or OAuth. Asking ChatGPT can help you get started for most common applications. For example, if I needed to use OAuth to authenticate to Google Cloud, I can provide a screenshot and ask for details: _“I’m building a connection to Google Cloud via OAuth. Please provide instructions for how to fill out each of these boxes.”_
## Step 2: Identify authentication requirements
This Weather 3rd party service does not require authentication, so you can skip that step for this Custom GPT. For other GPT Actions that do require authentication, there are 2 options: API Key or OAuth. Asking ChatGPT can help you get started for most common applications. For example, if I needed to use OAuth to authenticate to Google Cloud, I can provide a screenshot and ask for details: _“I’m building a connection to Google Cloud via OAuth. Please provide instructions for how to fill out each of these boxes.”_
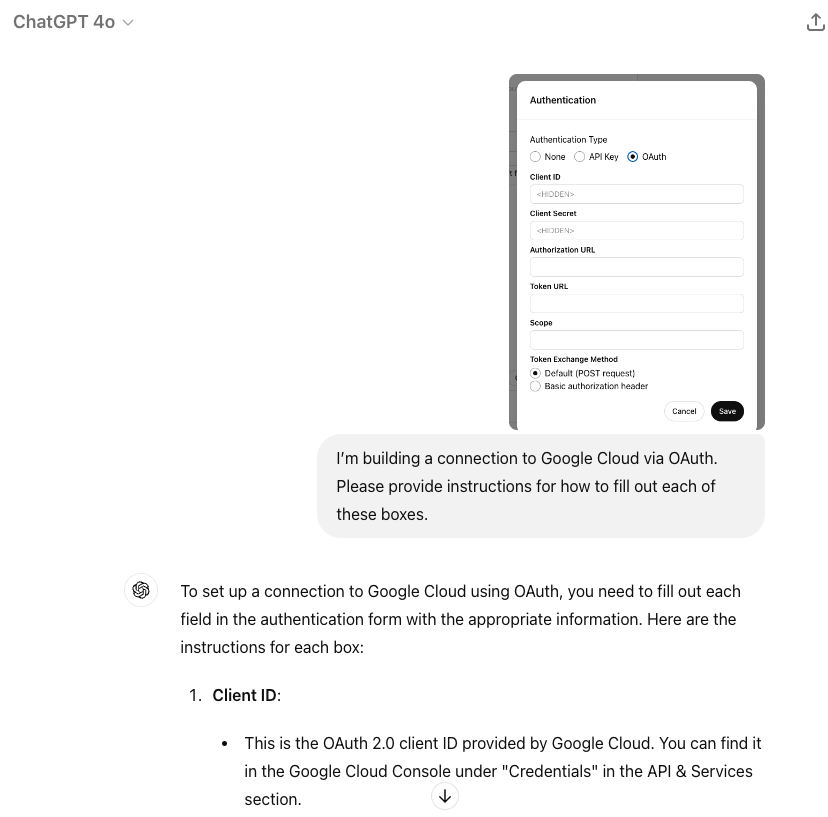 Often, ChatGPT provides the correct directions on all 5 elements. Once you have those basics ready, try testing and debugging the authentication in Postman or another similar service. If you encounter an error, provide the error to ChatGPT, and it can usually help you debug from there.
## Step 3: Create the GPT Action and test
Now is the time to create your Custom GPT. If you've never created a Custom GPT before, start at our [Creating a GPT guide](https://help.openai.com/en/articles/8554397-creating-a-gpt).
1. Provide a name, description, and image to describe your Custom GPT
2. Go to the Action section and paste in your Open API schema. Take a note of the Action names and json parameters when writing your instructions.
3. Add in your authentication settings
4. Go back to the main page and add in instructions
There are many ways to write successful instructions: the most important thing is that the instructions enable the model to reflect the user's preferences.
Typically, there are three sections:
1. _Context_ to explain to the model what the GPT Action(s) is doing
2. _Instructions_ on the sequence of steps – this is where you reference the Action name and any parameters the API call needs to pay attention to
3. _Additional Notes_ if there’s anything to keep in mind
Here’s an example of the instructions for the Weather GPT. Notice how the instructions refer to the API action name and json parameters from the Open API schema.
```
**Context**: A user needs information related to a weather forecast of a specific location.
**Instructions**:
1. The user will provide a lat-long point or a general location or landmark (e.g. New York City, the White House). If the user does not provide one, ask for the relevant location
2. If the user provides a general location or landmark, convert that into a lat-long coordinate. If required, browse the web to look up the lat-long point.
3. Run the "getPointData" API action and retrieve back the gridId, gridX, and gridY parameters.
4. Apply those variables as the office, gridX, and gridY variables in the "getGridpointForecast" API action to retrieve back a forecast
5. Use that forecast to answer the user's question
**Additional Notes**:
- Assume the user uses US weather units (e.g. Fahrenheit) unless otherwise specified
- If the user says "Let's get started" or "What do I do?", explain the purpose of this Custom GPT
```
### Test the GPT Action
Next to each action, you'll see a **Test** button. Click on that for each action. In the test, you can see the detailed input and output of each API call.
Often, ChatGPT provides the correct directions on all 5 elements. Once you have those basics ready, try testing and debugging the authentication in Postman or another similar service. If you encounter an error, provide the error to ChatGPT, and it can usually help you debug from there.
## Step 3: Create the GPT Action and test
Now is the time to create your Custom GPT. If you've never created a Custom GPT before, start at our [Creating a GPT guide](https://help.openai.com/en/articles/8554397-creating-a-gpt).
1. Provide a name, description, and image to describe your Custom GPT
2. Go to the Action section and paste in your Open API schema. Take a note of the Action names and json parameters when writing your instructions.
3. Add in your authentication settings
4. Go back to the main page and add in instructions
There are many ways to write successful instructions: the most important thing is that the instructions enable the model to reflect the user's preferences.
Typically, there are three sections:
1. _Context_ to explain to the model what the GPT Action(s) is doing
2. _Instructions_ on the sequence of steps – this is where you reference the Action name and any parameters the API call needs to pay attention to
3. _Additional Notes_ if there’s anything to keep in mind
Here’s an example of the instructions for the Weather GPT. Notice how the instructions refer to the API action name and json parameters from the Open API schema.
```
**Context**: A user needs information related to a weather forecast of a specific location.
**Instructions**:
1. The user will provide a lat-long point or a general location or landmark (e.g. New York City, the White House). If the user does not provide one, ask for the relevant location
2. If the user provides a general location or landmark, convert that into a lat-long coordinate. If required, browse the web to look up the lat-long point.
3. Run the "getPointData" API action and retrieve back the gridId, gridX, and gridY parameters.
4. Apply those variables as the office, gridX, and gridY variables in the "getGridpointForecast" API action to retrieve back a forecast
5. Use that forecast to answer the user's question
**Additional Notes**:
- Assume the user uses US weather units (e.g. Fahrenheit) unless otherwise specified
- If the user says "Let's get started" or "What do I do?", explain the purpose of this Custom GPT
```
### Test the GPT Action
Next to each action, you'll see a **Test** button. Click on that for each action. In the test, you can see the detailed input and output of each API call.
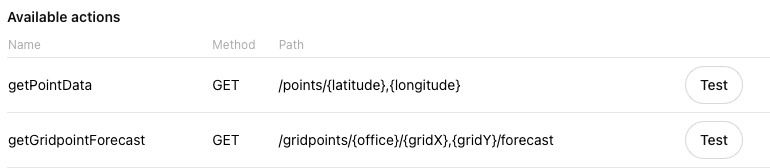 If your API call is working in a 3rd party tool like Postman and not in ChatGPT, there are a few possible culprits:
- The parameters in ChatGPT are wrong or missing
- An authentication issue in ChatGPT
- Your instructions are incomplete or unclear
- The descriptions in the Open API schema are unclear
If your API call is working in a 3rd party tool like Postman and not in ChatGPT, there are a few possible culprits:
- The parameters in ChatGPT are wrong or missing
- An authentication issue in ChatGPT
- Your instructions are incomplete or unclear
- The descriptions in the Open API schema are unclear
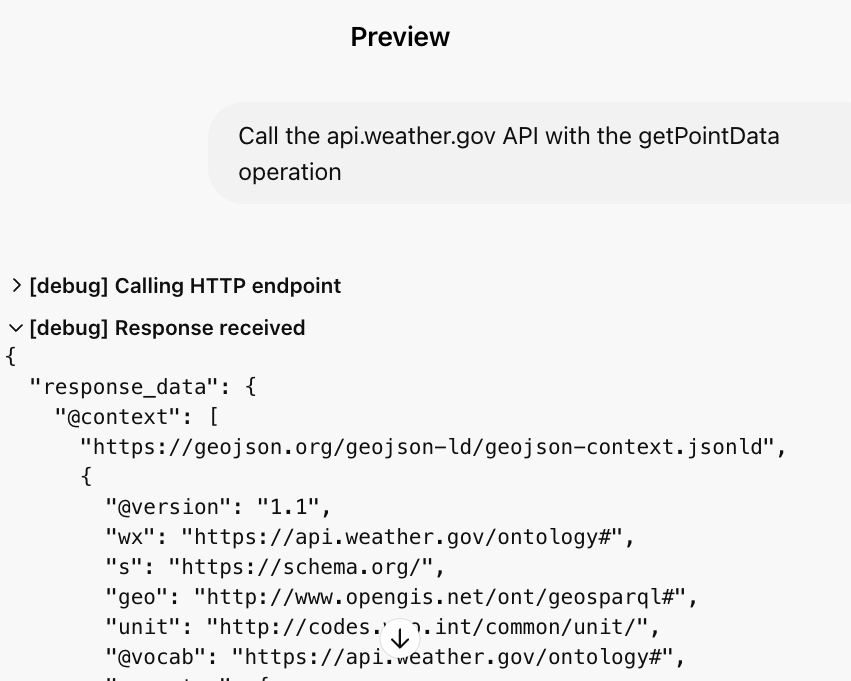 ## Step 4: Set up callback URL in the 3rd party app
If your GPT Action uses OAuth Authentication, you’ll need to set up the callback URL in your 3rd party application. Once you set up a GPT Action with OAuth, ChatGPT provides you with a callback URL (this will update any time you update one of the OAuth parameters). Copy that callback URL and add it to the appropriate place in your application.
## Step 4: Set up callback URL in the 3rd party app
If your GPT Action uses OAuth Authentication, you’ll need to set up the callback URL in your 3rd party application. Once you set up a GPT Action with OAuth, ChatGPT provides you with a callback URL (this will update any time you update one of the OAuth parameters). Copy that callback URL and add it to the appropriate place in your application.
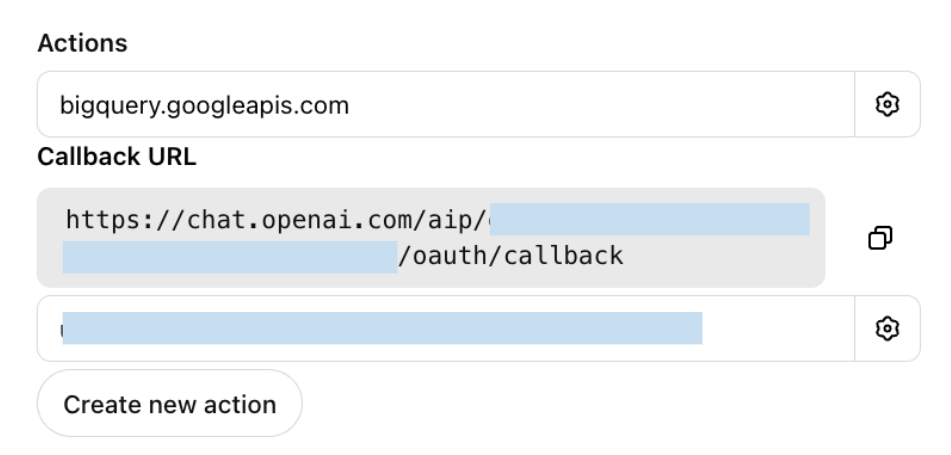 ## Step 5: Evaluate the Custom GPT
Even though you tested the GPT Action in the step above, you still need to evaluate if the Instructions and GPT Action function in the way users expect. Try to come up with at least 5-10 representative questions (the more, the better) of an **“evaluation set”** of questions to ask your Custom GPT.
**Key:** Test that the Custom GPT handles each one of your questions as you expect.
An example question: _“What should I pack for a trip to the White House this weekend?”_ tests the Custom GPT’s ability to: (1) convert a landmark to a lat-long, (2) run both GPT Actions, and (3) answer the user’s question.
## Step 5: Evaluate the Custom GPT
Even though you tested the GPT Action in the step above, you still need to evaluate if the Instructions and GPT Action function in the way users expect. Try to come up with at least 5-10 representative questions (the more, the better) of an **“evaluation set”** of questions to ask your Custom GPT.
**Key:** Test that the Custom GPT handles each one of your questions as you expect.
An example question: _“What should I pack for a trip to the White House this weekend?”_ tests the Custom GPT’s ability to: (1) convert a landmark to a lat-long, (2) run both GPT Actions, and (3) answer the user’s question.
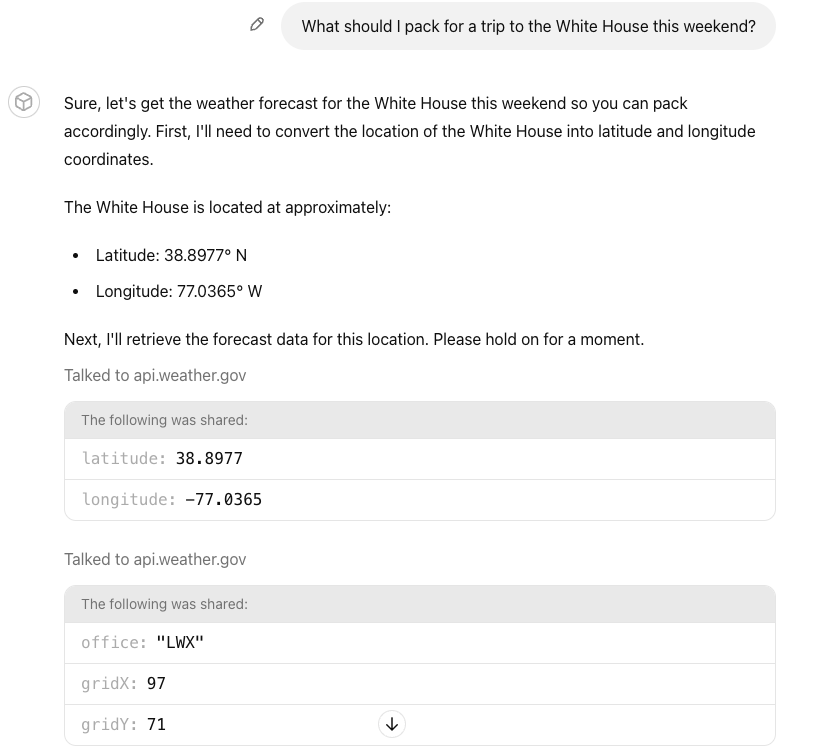
 ## Common Debugging Steps
_Challenge:_ The GPT Action is calling the wrong API call (or not calling it at all)
- _Solution:_ Make sure the descriptions of the Actions are clear - and refer to the Action names in your Custom GPT Instructions
_Challenge:_ The GPT Action is calling the right API call but not using the parameters correctly
- _Solution:_ Add or modify the descriptions of the parameters in the GPT Action
_Challenge:_ The Custom GPT is not working but I am not getting a clear error
- _Solution:_ Make sure to test the Action - there are more robust logs in the test window. If that is still unclear, use Postman or another 3rd party service to better diagnose.
_Challenge:_ The Custom GPT is giving an authentication error
- _Solution:_ Make sure your callback URL is set up correctly. Try testing the exact same authentication settings in Postman or another 3rd party service
_Challenge:_ The Custom GPT cannot handle more difficult / ambiguous questions
- _Solution:_ Try to prompt engineer your instructions in the Custom GPT. See examples in our [prompt engineering guide](https://developers.openai.com/api/docs/guides/prompt-engineering)
This concludes the guide to building a Custom GPT. Good luck building and leveraging the [OpenAI developer forum](https://community.openai.com/) if you have additional questions.
---
# GPT Action authentication
Actions offer different authentication schemas to accommodate various use cases. To specify the authentication schema for your action, use the GPT editor and select "None", "API Key", or "OAuth".
By default, the authentication method for all actions is set to "None", but you can change this and allow different actions to have different authentication methods.
## No authentication
We support flows without authentication for applications where users can send requests directly to your API without needing an API key or signing in with OAuth.
Consider using no authentication for initial user interactions as you might experience a user drop off if they are forced to sign into an application. You can create a "signed out" experience and then move users to a "signed in" experience by enabling a separate action.
## API key authentication
Just like how a user might already be using your API, we allow API key authentication through the GPT editor UI. We encrypt the secret key when we store it in our database to keep your API key secure.
This approach is useful if you have an API that takes slightly more consequential actions than the no authentication flow but does not require an individual user to sign in. Adding API key authentication can protect your API and give you more fine-grained access controls along with visibility into where requests are coming from.
## OAuth
Actions allow OAuth sign in for each user. This is the best way to provide personalized experiences and make the most powerful actions available to users. A simple example of the OAuth flow with actions will look like the following:
- To start, select "Authentication" in the GPT editor UI, and select "OAuth".
- You will be prompted to enter the OAuth client ID, client secret, authorization URL, token URL, and scope.
- The client ID and secret can be simple text strings but should [follow OAuth best practices](https://www.oauth.com/oauth2-servers/client-registration/client-id-secret/).
- We store an encrypted version of the client secret, while the client ID is available to end users.
- OAuth requests will include the following information: `request={'grant_type': 'authorization_code', 'client_id': 'YOUR_CLIENT_ID', 'client_secret': 'YOUR_CLIENT_SECRET', 'code': 'abc123', 'redirect_uri': 'https://chat.openai.com/aip/{g-YOUR-GPT-ID-HERE}/oauth/callback'}` Note: `https://chatgpt.com/aip/{g-YOUR-GPT-ID-HERE}/oauth/callback` is also valid.
- In order for someone to use an action with OAuth, they will need to send a message that invokes the action and then the user will be presented with a "Sign in to [domain]" button in the ChatGPT UI.
- The `authorization_url` endpoint should return a response that looks like:
`{ "access_token": "example_token", "token_type": "bearer", "refresh_token": "example_token", "expires_in": 59 }`
- During the user sign in process, ChatGPT makes a request to your `authorization_url` using the specified `authorization_content_type`, we expect to get back an access token and optionally a [refresh token](https://auth0.com/learn/refresh-tokens) which we use to periodically fetch a new access token.
- Each time a user makes a request to the action, the user’s token will be passed in the Authorization header: ("Authorization": "[Bearer/Basic] [user’s token]").
- We require that OAuth applications make use of the [state parameter](https://auth0.com/docs/secure/attack-protection/state-parameters#set-and-compare-state-parameter-values) for security reasons.
Failure to login issues on Custom GPTs (Redirect URLs)?
- Be sure to enable this redirect URL in your OAuth application:
- #1 Redirect URL: `https://chat.openai.com/aip/{g-YOUR-GPT-ID-HERE}/oauth/callback` (Different domain possible for some clients)
- #2 Redirect URL: `https://chatgpt.com/aip/{g-YOUR-GPT-ID-HERE}/oauth/callback` (Get your GPT ID in the URL bar of the ChatGPT UI once you save) if you have several GPTs you'd need to enable for each or a wildcard depending on risk tolerance.
- Debug Note: Your Auth Provider will typically log failures (e.g. 'redirect_uri is not registered for client'), which helps debug login issues as well.
---
# GPT Actions
GPT Actions are stored in [Custom GPTs](https://openai.com/blog/introducing-gpts), which enable users to customize ChatGPT for specific use cases by providing instructions, attaching documents as knowledge, and connecting to 3rd party services.
GPT Actions empower ChatGPT users to interact with external applications via RESTful APIs calls outside of ChatGPT simply by using natural language. They convert natural language text into the json schema required for an API call. GPT Actions are usually either used to do [data retrieval](https://developers.openai.com/api/docs/actions/data-retrieval) to ChatGPT (e.g. query a Data Warehouse) or take action in another application (e.g. file a JIRA ticket).
## How GPT Actions work
At their core, GPT Actions leverage [Function Calling](https://developers.openai.com/api/docs/guides/function-calling) to execute API calls.
Similar to ChatGPT's Data Analysis capability (which generates Python code and then executes it), they leverage Function Calling to (1) decide which API call is relevant to the user's question and (2) generate the json input necessary for the API call. Then finally, the GPT Action executes the API call using that json input.
Developers can even specify the authentication mechanism of an action, and the Custom GPT will execute the API call using the third party app’s authentication. GPT Actions obfuscates the complexity of the API call to the end user: they simply ask a question in natural language, and ChatGPT provides the output in natural language as well.
## The Power of GPT Actions
APIs allow for **interoperability** to enable your organization to access other applications. However, enabling users to access the right information from 3rd-party APIs can require significant overhead from developers.
GPT Actions provide a viable alternative: developers can now simply describe the schema of an API call, configure authentication, and add in some instructions to the GPT, and ChatGPT provides the bridge between the user's natural language questions and the API layer.
## Simplified example
The [getting started guide](https://developers.openai.com/api/docs/actions/getting-started) walks through an example using two API calls from [weather.gov](https://developers.openai.com/api/docs/actions/weather.gov) to generate a forecast:
- /points/\{latitude},\{longitude} inputs lat-long coordinates and outputs forecast office (wfo) and x-y coordinates
- /gridpoints/\{office}/\{gridX},\{gridY}/forecast inputs wfo,x,y coordinates and outputs a forecast
Once a developer has encoded the json schema required to populate both of those API calls in a GPT Action, a user can simply ask "What I should pack on a trip to Washington DC this weekend?" The GPT Action will then figure out the lat-long of that location, execute both API calls in order, and respond with a packing list based on the weekend forecast it receives back.
In this example, GPT Actions will supply api.weather.gov with two API inputs:
/points API call:
```json
{
"latitude": 38.9072,
"longitude": -77.0369
}
```
/forecast API call:
```json
{
"wfo": "LWX",
"x": 97,
"y": 71
}
```
## Get started on building
Check out the [getting started guide](https://developers.openai.com/api/docs/actions/getting-started) for a deeper dive on this weather example and our [actions library](https://developers.openai.com/api/docs/actions/actions-library) for pre-built example GPT Actions of the most common 3rd party apps.
## Additional information
- Familiarize yourself with our [GPT policies](https://openai.com/policies/usage-policies#:~:text=or%20educational%20purposes.-,Building%20with%20ChatGPT,-Shared%20GPTs%20allow)
- Check out the [GPT data privacy FAQs](https://help.openai.com/en/articles/8554402-gpts-data-privacy-faqs)
- Find answers to [common GPT questions](https://help.openai.com/en/articles/8554407-gpts-faq)
---
# GPT Actions library
## Purpose
While GPT Actions should be significantly less work for an API developer to set up than an entire application using those APIs from scratch, there’s still some set up required to get GPT Actions up and running. A Library of GPT Actions is meant to provide guidance for building GPT Actions on common applications.
## Getting started
If you’ve never built an action before, start by reading the [getting started guide](https://developers.openai.com/api/docs/actions/getting-started) first to understand better how actions work.
Generally, this guide is meant for people with familiarity and comfort with calling API calls. For debugging help, try to explain your issues to ChatGPT - and include screenshots.
## How to access
[The OpenAI Cookbook](https://developers.openai.com/cookbook) has a [directory](https://developers.openai.com/cookbook/topic/chatgpt) of 3rd party applications and middleware application.
### 3rd party Actions cookbook
GPT Actions can integrate with HTTP services directly. GPT Actions leveraging SaaS API directly will authenticate and request resources directly from SaaS providers, such as [Google Drive](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_action_google_drive) or [Snowflake](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_action_snowflake_direct).
### Middleware Actions cookbook
GPT Actions can benefit from having a middleware. It allows pre-processing, data formatting, data filtering or even connection to endpoints not exposed through HTTP (e.g: databases). Multiple middleware cookbooks are available describing an example implementation path, such as [Azure](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_middleware_azure_function), [GCP](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_middleware_google_cloud_function) and [AWS](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_middleware_aws_function).
## Give us feedback
Are there integrations that you’d like us to prioritize? Are there errors in our integrations? File a PR or issue on the cookbook page's github, and we’ll take a look.
## Contribute to our library
If you’re interested in contributing to our library, please follow the below guidelines, then submit a PR in github for us to review. In general, follow the template similar to [this example GPT Action](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_action_bigquery).
Guidelines - include the following sections:
- Application Information - describe the 3rd party application, and include a link to app website and API docs
- Custom GPT Instructions - include the exact instructions to be included in a Custom GPT
- OpenAPI Schema - include the exact OpenAPI schema to be included in the GPT Action
- Authentication Instructions - for OAuth, include the exact set of items (authorization URL, token URL, scope, etc.); also include instructions on how to write the callback URL in the application (as well as any other steps)
- FAQ and Troubleshooting - what are common pitfalls that users may encounter? Write them here and workarounds
## Disclaimers
This action library is meant to be a guide for interacting with 3rd parties that OpenAI have no control over. These 3rd parties may change their API settings or configurations, and OpenAI cannot guarantee these Actions will work in perpetuity. Please see them as a starting point.
This guide is meant for developers and people with comfort writing API calls. Non-technical users will likely find these steps challenging.
---
# Production notes on GPT Actions
## Rate limits
Consider implementing rate limiting on the API endpoints you expose. ChatGPT will respect 429 response codes and dynamically back off from sending requests to your action after receiving a certain number of 429's or 500's in a short period of time.
## Timeouts
When making API calls during the actions experience, timeouts take place if the following thresholds are exceeded:
- 45 seconds round trip for API calls
## Use TLS and HTTPS
All traffic to your action must use TLS 1.2 or later on port 443 with a valid public certificate.
## IP egress ranges
ChatGPT will call your action from an IP address from one of the [CIDR blocks](https://en.wikipedia.org/wiki/Classless_Inter-Domain_Routing) listed in [chatgpt-connectors.json](https://openai.com/chatgpt-connectors.json)
You may wish to explicitly allowlist these IP addresses. This list is updated automatically periodically.
## Multiple authentication schemas
When defining an action, you can mix a single authentication type (OAuth or API key) along with endpoints that do not require authentication.
You can learn more about action authentication on our [actions authentication page](https://developers.openai.com/api/docs/actions/authentication).
## Open API specification limits
Keep in mind the following limits in your OpenAPI specification, which are subject to change:
- 300 characters max for each API endpoint description/summary field in API specification
- 700 characters max for each API parameter description field in API specification
## Additional limitations
There are a few limitations to be aware of when building with actions:
- Custom headers are not supported
- With the exception of Google, Microsoft and Adobe OAuth domains, all domains used in an OAuth flow must be the same as the domain used for the primary endpoints
- Request and response payloads must be less than 100,000 characters each
- Requests timeout after 45 seconds
- Requests and responses can only contain text (no images or video)
## Consequential flag
In the OpenAPI specification, you can now set certain endpoints as "consequential" as shown below:
```yaml
paths:
/todo:
get:
operationId: getTODOs
description: Fetches items in a TODO list from the API.
security: []
post:
operationId: updateTODOs
description: Mutates the TODO list.
x-openai-isConsequential: true
```
A good example of a consequential action is booking a hotel room and paying for it on behalf of a user.
- If the `x-openai-isConsequential` field is `true`, ChatGPT treats the operation as "must always prompt the user for confirmation before running" and don't show an "always allow" button (both are features of GPTs designed to give builders and users more control over actions).
- If the `x-openai-isConsequential` field is `false`, ChatGPT shows the "always allow button".
- If the field isn't present, ChatGPT defaults all GET operations to `false` and all other operations to `true`
## Best practices on feeding examples
Here are some best practices to follow when writing your GPT instructions and descriptions in your schema, as well as when designing your API responses:
1. Your descriptions should not encourage the GPT to use the action when the user hasn't asked for your action's particular category of service.
_Bad example_:
> Whenever the user mentions any type of task, ask if they would like to use the TODO action to add something to their todo list.
_Good example_:
> The TODO list can add, remove and view the user's TODOs.
2. Your descriptions should not prescribe specific triggers for the GPT to use the action. ChatGPT is designed to use your action automatically when appropriate.
_Bad example_:
> When the user mentions a task, respond with "Would you like me to add this to your TODO list? Say 'yes' to continue."
_Good example_:
> [no instructions needed for this]
3. Action responses from an API should return raw data instead of natural language responses unless it's necessary. The GPT will provide its own natural language response using the returned data.
_Bad example_:
> I was able to find your todo list! You have 2 todos: get groceries and walk the dog. I can add more todos if you'd like!
_Good example_:
> \{ "todos": [ "get groceries", "walk the dog" ] }
## How GPT Action data is used
GPT Actions connect ChatGPT to external apps. If a user interacts with a GPT’s custom action, ChatGPT may send parts of their conversation to the action’s endpoint.
If you have questions or run into additional limitations, you can join the discussion on the [OpenAI developer forum](https://community.openai.com).
---
# Sending and returning files with GPT Actions
## Sending files
POST requests can include up to ten files (including DALL-E generated images) from the conversation. They will be sent as URLs which are valid for five minutes.
For files to be part of your POST request, the parameter must be named `openaiFileIdRefs` and the description should explain to the model the type and quantity of the files which your API is expecting.
The `openaiFileIdRefs` parameter will be populated with an array of JSON objects. Each object contains:
- `name` The name of the file. This will be an auto generated name when created by DALL-E.
- `id` A stable identifier for the file.
- `mime_type` The mime type of the file. For user uploaded files this is based on file extension.
- `download_link` The URL to fetch the file which is valid for five minutes.
Here’s an example of an `openaiFileIdRefs` array with two elements:
```json
[
{
"name": "dalle-Lh2tg7WuosbyR9hk",
"id": "file-XFlOqJYTPBPwMZE3IopCBv1Z",
"mime_type": "image/webp",
"download_link": "https://files.oaiusercontent.com/file-XFlOqJYTPBPwMZE3IopCBv1Z?se=2024-03-11T20%3A29%3A52Z&sp=r&sv=2021-08-06&sr=b&rscc=max-age%3D31536000%2C%20immutable&rscd=attachment%3B%20filename%3Da580bae6-ea30-478e-a3e2-1f6c06c3e02f.webp&sig=ZPWol5eXACxU1O9azLwRNgKVidCe%2BwgMOc/TdrPGYII%3D"
},
{
"name": "2023 Benefits Booklet.pdf",
"id": "file-s5nX7o4junn2ig0J84r8Q0Ew",
"mime_type": "application/pdf",
"download_link": "https://files.oaiusercontent.com/file-s5nX7o4junn2ig0J84r8Q0Ew?se=2024-03-11T20%3A29%3A52Z&sp=r&sv=2021-08-06&sr=b&rscc=max-age%3D299%2C%20immutable&rscd=attachment%3B%20filename%3D2023%2520Benefits%2520Booklet.pdf&sig=Ivhviy%2BrgoyUjxZ%2BingpwtUwsA4%2BWaRfXy8ru9AfcII%3D"
}
]
```
Actions can include files uploaded by the user, images generated by DALL-E, and files created by Code Interpreter.
### OpenAPI Example
```yaml
/createWidget:
post:
operationId: createWidget
summary: Creates a widget based on an image.
description: Uploads a file reference using its file id. This file should be an image created by DALL·E or uploaded by the user. JPG, WEBP, and PNG are supported for widget creation.
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
openaiFileIdRefs:
type: array
items:
type: string
```
While this schema shows `openaiFileIdRefs` as being an array of type `string`, at runtime this will be populated with an array of JSON objects as previously shown.
## Returning files
Requests may return up to 10 files. Each file may be up to 10 MB and cannot be an image or video.
These files will become part of the conversation similarly to if a user uploaded them, meaning they may be made available to code interpreter, file search, and sent as part of subsequent action invocations. In the web app users will see that the files have been returned and can download them.
To return files, the body of the response must contain an `openaiFileResponse` parameter. This parameter must always be an array and must be populated in one of two ways.
### Inline option
Each element of the array is a JSON object which contains:
- `name` The name of the file. This will be visible to the user.
- `mime_type` The MIME type of the file. This is used to determine eligibility and which features have access to the file.
- `content` The base64 encoded contents of the file.
Here’s an example of an openaiFileResponse array with two elements:
```json
[
{
"name": "example_document.pdf",
"mime_type": "application/pdf",
"content": "JVBERi0xLjQKJcfsj6IKNSAwIG9iago8PC9MZW5ndGggNiAwIFIvRmlsdGVyIC9GbGF0ZURlY29kZT4+CnN0cmVhbQpHhD93PQplbmRzdHJlYW0KZW5kb2JqCg=="
},
{
"name": "sample_spreadsheet.csv",
"mime_type": "text/csv",
"content": "iVBORw0KGgoAAAANSUhEUgAAAAUAAAAFCAYAAACNbyblAAAAHElEQVQI12P4//8/w38GIAXDIBKE0DHxgljNBAAO9TXL0Y4OHwAAAABJRU5ErkJggg=="
}
]
```
OpenAPI example
```yaml
/papers:
get:
operationId: findPapers
summary: Retrieve PDFs of relevant academic papers.
description: Provided an academic topic, up to five relevant papers will be returned as PDFs.
parameters:
- in: query
name: topic
required: true
schema:
type: string
description: The topic the papers should be about.
responses:
"200":
description: Zero to five academic paper PDFs
content:
application/json:
schema:
type: object
properties:
openaiFileResponse:
type: array
items:
type: object
properties:
name:
type: string
description: The name of the file.
mime_type:
type: string
description: The MIME type of the file.
content:
type: string
format: byte
description: The content of the file in base64 encoding.
```
### URL option
Each element of the array is a URL referencing a file to be downloaded. The headers `Content-Disposition` and `Content-Type` must be set such that a file name and MIME type can be determined. The name of the file will be visible to the user. The MIME type of the file determines eligibility and which features have access to the file.
There is a 10 second timeout for fetching each file.
Here’s an example of an `openaiFileResponse` array with two elements:
```json
[
"https://example.com/f/dca89f18-16d4-4a65-8ea2-ededced01646",
"https://example.com/f/01fad6b0-635b-4803-a583-0f678b2e6153"
]
```
Here’s an example of the required headers for each URL:
```
Content-Type: application/pdf
Content-Disposition: attachment; filename="example_document.pdf"
```
OpenAPI example
```yaml
/papers:
get:
operationId: findPapers
summary: Retrieve PDFs of relevant academic papers.
description: Provided an academic topic, up to five relevant papers will be returned as PDFs.
parameters:
- in: query
name: topic
required: true
schema:
type: string
description: The topic the papers should be about.
responses:
'200':
description: Zero to five academic paper PDFs
content:
application/json:
schema:
type: object
properties:
openaiFileResponse:
type: array
items:
type: string
format: uri
description: URLs to fetch the files.
```
---
# Assistants API deep dive
export const snippetFileCreate = {
python: `
file = client.files.create(
file=open("revenue-forecast.csv", "rb"),
purpose='assistants'
)
`.trim(),
"node.js": `
const file = await openai.files.create({
file: fs.createReadStream("revenue-forecast.csv"),
purpose: "assistants",
});
`.trim(),
curl: `
curl https://api.openai.com/v1/files \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-F purpose="assistants" \\
-F file="@revenue-forecast.csv"
`.trim(),
};
export const snippetAssistantCreation = {
python: `
assistant = client.beta.assistants.create(
name="Data visualizer",
description="You are great at creating beautiful data visualizations. You analyze data present in .csv files, understand trends, and come up with data visualizations relevant to those trends. You also share a brief text summary of the trends observed.",
model="gpt-4o",
tools=[{"type": "code_interpreter"}],
tool_resources={
"code_interpreter": {
"file_ids": [file.id]
}
}
)
`.trim(),
"node.js": `
const assistant = await openai.beta.assistants.create({
name: "Data visualizer",
description: "You are great at creating beautiful data visualizations. You analyze data present in .csv files, understand trends, and come up with data visualizations relevant to those trends. You also share a brief text summary of the trends observed.",
model: "gpt-4o",
tools: [{"type": "code_interpreter"}],
tool_resources: {
"code_interpreter": {
"file_ids": [file.id]
}
}
});
`.trim(),
curl: `
curl https://api.openai.com/v1/assistants \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-H "OpenAI-Beta: assistants=v2" \\
-d '{
"name": "Data visualizer",
"description": "You are great at creating beautiful data visualizations. You analyze data present in .csv files, understand trends, and come up with data visualizations relevant to those trends. You also share a brief text summary of the trends observed.",
"model": "gpt-4o",
"tools": [{"type": "code_interpreter"}],
"tool_resources": {
"code_interpreter": {
"file_ids": ["file-BK7bzQj3FfZFXr7DbL6xJwfo"]
}
}
}'
`.trim(),
};
export const snippetThreadCreation = {
python: `
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": "Create 3 data visualizations based on the trends in this file.",
"attachments": [
{
"file_id": file.id,
"tools": [{"type": "code_interpreter"}]
}
]
}
]
)
`.trim(),
"node.js": `
const thread = await openai.beta.threads.create({
messages: [
{
"role": "user",
"content": "Create 3 data visualizations based on the trends in this file.",
"attachments": [
{
file_id: file.id,
tools: [{type: "code_interpreter"}]
}
]
}
]
});
`.trim(),
curl: `
curl https://api.openai.com/v1/threads \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-H "OpenAI-Beta: assistants=v2" \\
-d '{
"messages": [
{
"role": "user",
"content": "Create 3 data visualizations based on the trends in this file.",
"attachments": [
{
"file_id": "file-ACq8OjcLQm2eIG0BvRM4z5qX",
"tools": [{"type": "code_interpreter"}]
}
]
}
]
}'
`.trim(),
};
export const snippetImageCreation = {
python: `
file = client.files.create(
file=open("myimage.png", "rb"),
purpose="vision"
)
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the difference between these images?"
},
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.png"}
},
{
"type": "image_file",
"image_file": {"file_id": file.id}
},
],
}
]
)
`.trim(),
"node.js": `
const file = await openai.files.create({
file: fs.createReadStream("myimage.png"),
purpose: "vision",
});
const thread = await openai.beta.threads.create({
messages: [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the difference between these images?"
},
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.png"}
},
{
"type": "image_file",
"image_file": {"file_id": file.id}
},
]
}
]
});
`.trim(),
curl: `
# Upload a file with an "vision" purpose
curl https://api.openai.com/v1/files \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-F purpose="vision" \\
-F file="@/path/to/myimage.png"
## Pass the file ID in the content
curl https://api.openai.com/v1/threads \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-H "OpenAI-Beta: assistants=v2" \\
-d '{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the difference between these images?"
},
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.png"}
},
{
"type": "image_file",
"image_file": {"file_id": file.id}
}
]
}
]
}'
`.trim(),
};
export const snippetLowHighFidelity = {
python: `
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is this an image of?"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png",
"detail": "high"
}
},
],
}
]
)
`.trim(),
"node.js": `
const thread = await openai.beta.threads.create({
messages: [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is this an image of?"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png",
"detail": "high"
}
},
]
}
]
});
`.trim(),
curl: `
curl https://api.openai.com/v1/threads \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-H "OpenAI-Beta: assistants=v2" \\
-d '{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is this an image of?"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png",
"detail": "high"
}
},
]
}
]
}'
`.trim(),
};
export const snippetMessageAnnotations = {
python: `
# Retrieve the message object
message = client.beta.threads.messages.retrieve(
thread_id="...",
message_id="..."
)
# Extract the message content
message_content = message.content[0].text
annotations = message_content.annotations
citations = []
# Iterate over the annotations and add footnotes
for index, annotation in enumerate(annotations): # Replace the text with a footnote
message_content.value = message_content.value.replace(annotation.text, f' [{index}]')
# Gather citations based on annotation attributes
if (file_citation := getattr(annotation, 'file_citation', None)):
cited_file = client.files.retrieve(file_citation.file_id)
citations.append(f'[{index}] {file_citation.quote} from {cited_file.filename}')
elif (file_path := getattr(annotation, 'file_path', None)):
cited_file = client.files.retrieve(file_path.file_id)
citations.append(f'[{index}] Click
## Common Debugging Steps
_Challenge:_ The GPT Action is calling the wrong API call (or not calling it at all)
- _Solution:_ Make sure the descriptions of the Actions are clear - and refer to the Action names in your Custom GPT Instructions
_Challenge:_ The GPT Action is calling the right API call but not using the parameters correctly
- _Solution:_ Add or modify the descriptions of the parameters in the GPT Action
_Challenge:_ The Custom GPT is not working but I am not getting a clear error
- _Solution:_ Make sure to test the Action - there are more robust logs in the test window. If that is still unclear, use Postman or another 3rd party service to better diagnose.
_Challenge:_ The Custom GPT is giving an authentication error
- _Solution:_ Make sure your callback URL is set up correctly. Try testing the exact same authentication settings in Postman or another 3rd party service
_Challenge:_ The Custom GPT cannot handle more difficult / ambiguous questions
- _Solution:_ Try to prompt engineer your instructions in the Custom GPT. See examples in our [prompt engineering guide](https://developers.openai.com/api/docs/guides/prompt-engineering)
This concludes the guide to building a Custom GPT. Good luck building and leveraging the [OpenAI developer forum](https://community.openai.com/) if you have additional questions.
---
# GPT Action authentication
Actions offer different authentication schemas to accommodate various use cases. To specify the authentication schema for your action, use the GPT editor and select "None", "API Key", or "OAuth".
By default, the authentication method for all actions is set to "None", but you can change this and allow different actions to have different authentication methods.
## No authentication
We support flows without authentication for applications where users can send requests directly to your API without needing an API key or signing in with OAuth.
Consider using no authentication for initial user interactions as you might experience a user drop off if they are forced to sign into an application. You can create a "signed out" experience and then move users to a "signed in" experience by enabling a separate action.
## API key authentication
Just like how a user might already be using your API, we allow API key authentication through the GPT editor UI. We encrypt the secret key when we store it in our database to keep your API key secure.
This approach is useful if you have an API that takes slightly more consequential actions than the no authentication flow but does not require an individual user to sign in. Adding API key authentication can protect your API and give you more fine-grained access controls along with visibility into where requests are coming from.
## OAuth
Actions allow OAuth sign in for each user. This is the best way to provide personalized experiences and make the most powerful actions available to users. A simple example of the OAuth flow with actions will look like the following:
- To start, select "Authentication" in the GPT editor UI, and select "OAuth".
- You will be prompted to enter the OAuth client ID, client secret, authorization URL, token URL, and scope.
- The client ID and secret can be simple text strings but should [follow OAuth best practices](https://www.oauth.com/oauth2-servers/client-registration/client-id-secret/).
- We store an encrypted version of the client secret, while the client ID is available to end users.
- OAuth requests will include the following information: `request={'grant_type': 'authorization_code', 'client_id': 'YOUR_CLIENT_ID', 'client_secret': 'YOUR_CLIENT_SECRET', 'code': 'abc123', 'redirect_uri': 'https://chat.openai.com/aip/{g-YOUR-GPT-ID-HERE}/oauth/callback'}` Note: `https://chatgpt.com/aip/{g-YOUR-GPT-ID-HERE}/oauth/callback` is also valid.
- In order for someone to use an action with OAuth, they will need to send a message that invokes the action and then the user will be presented with a "Sign in to [domain]" button in the ChatGPT UI.
- The `authorization_url` endpoint should return a response that looks like:
`{ "access_token": "example_token", "token_type": "bearer", "refresh_token": "example_token", "expires_in": 59 }`
- During the user sign in process, ChatGPT makes a request to your `authorization_url` using the specified `authorization_content_type`, we expect to get back an access token and optionally a [refresh token](https://auth0.com/learn/refresh-tokens) which we use to periodically fetch a new access token.
- Each time a user makes a request to the action, the user’s token will be passed in the Authorization header: ("Authorization": "[Bearer/Basic] [user’s token]").
- We require that OAuth applications make use of the [state parameter](https://auth0.com/docs/secure/attack-protection/state-parameters#set-and-compare-state-parameter-values) for security reasons.
Failure to login issues on Custom GPTs (Redirect URLs)?
- Be sure to enable this redirect URL in your OAuth application:
- #1 Redirect URL: `https://chat.openai.com/aip/{g-YOUR-GPT-ID-HERE}/oauth/callback` (Different domain possible for some clients)
- #2 Redirect URL: `https://chatgpt.com/aip/{g-YOUR-GPT-ID-HERE}/oauth/callback` (Get your GPT ID in the URL bar of the ChatGPT UI once you save) if you have several GPTs you'd need to enable for each or a wildcard depending on risk tolerance.
- Debug Note: Your Auth Provider will typically log failures (e.g. 'redirect_uri is not registered for client'), which helps debug login issues as well.
---
# GPT Actions
GPT Actions are stored in [Custom GPTs](https://openai.com/blog/introducing-gpts), which enable users to customize ChatGPT for specific use cases by providing instructions, attaching documents as knowledge, and connecting to 3rd party services.
GPT Actions empower ChatGPT users to interact with external applications via RESTful APIs calls outside of ChatGPT simply by using natural language. They convert natural language text into the json schema required for an API call. GPT Actions are usually either used to do [data retrieval](https://developers.openai.com/api/docs/actions/data-retrieval) to ChatGPT (e.g. query a Data Warehouse) or take action in another application (e.g. file a JIRA ticket).
## How GPT Actions work
At their core, GPT Actions leverage [Function Calling](https://developers.openai.com/api/docs/guides/function-calling) to execute API calls.
Similar to ChatGPT's Data Analysis capability (which generates Python code and then executes it), they leverage Function Calling to (1) decide which API call is relevant to the user's question and (2) generate the json input necessary for the API call. Then finally, the GPT Action executes the API call using that json input.
Developers can even specify the authentication mechanism of an action, and the Custom GPT will execute the API call using the third party app’s authentication. GPT Actions obfuscates the complexity of the API call to the end user: they simply ask a question in natural language, and ChatGPT provides the output in natural language as well.
## The Power of GPT Actions
APIs allow for **interoperability** to enable your organization to access other applications. However, enabling users to access the right information from 3rd-party APIs can require significant overhead from developers.
GPT Actions provide a viable alternative: developers can now simply describe the schema of an API call, configure authentication, and add in some instructions to the GPT, and ChatGPT provides the bridge between the user's natural language questions and the API layer.
## Simplified example
The [getting started guide](https://developers.openai.com/api/docs/actions/getting-started) walks through an example using two API calls from [weather.gov](https://developers.openai.com/api/docs/actions/weather.gov) to generate a forecast:
- /points/\{latitude},\{longitude} inputs lat-long coordinates and outputs forecast office (wfo) and x-y coordinates
- /gridpoints/\{office}/\{gridX},\{gridY}/forecast inputs wfo,x,y coordinates and outputs a forecast
Once a developer has encoded the json schema required to populate both of those API calls in a GPT Action, a user can simply ask "What I should pack on a trip to Washington DC this weekend?" The GPT Action will then figure out the lat-long of that location, execute both API calls in order, and respond with a packing list based on the weekend forecast it receives back.
In this example, GPT Actions will supply api.weather.gov with two API inputs:
/points API call:
```json
{
"latitude": 38.9072,
"longitude": -77.0369
}
```
/forecast API call:
```json
{
"wfo": "LWX",
"x": 97,
"y": 71
}
```
## Get started on building
Check out the [getting started guide](https://developers.openai.com/api/docs/actions/getting-started) for a deeper dive on this weather example and our [actions library](https://developers.openai.com/api/docs/actions/actions-library) for pre-built example GPT Actions of the most common 3rd party apps.
## Additional information
- Familiarize yourself with our [GPT policies](https://openai.com/policies/usage-policies#:~:text=or%20educational%20purposes.-,Building%20with%20ChatGPT,-Shared%20GPTs%20allow)
- Check out the [GPT data privacy FAQs](https://help.openai.com/en/articles/8554402-gpts-data-privacy-faqs)
- Find answers to [common GPT questions](https://help.openai.com/en/articles/8554407-gpts-faq)
---
# GPT Actions library
## Purpose
While GPT Actions should be significantly less work for an API developer to set up than an entire application using those APIs from scratch, there’s still some set up required to get GPT Actions up and running. A Library of GPT Actions is meant to provide guidance for building GPT Actions on common applications.
## Getting started
If you’ve never built an action before, start by reading the [getting started guide](https://developers.openai.com/api/docs/actions/getting-started) first to understand better how actions work.
Generally, this guide is meant for people with familiarity and comfort with calling API calls. For debugging help, try to explain your issues to ChatGPT - and include screenshots.
## How to access
[The OpenAI Cookbook](https://developers.openai.com/cookbook) has a [directory](https://developers.openai.com/cookbook/topic/chatgpt) of 3rd party applications and middleware application.
### 3rd party Actions cookbook
GPT Actions can integrate with HTTP services directly. GPT Actions leveraging SaaS API directly will authenticate and request resources directly from SaaS providers, such as [Google Drive](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_action_google_drive) or [Snowflake](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_action_snowflake_direct).
### Middleware Actions cookbook
GPT Actions can benefit from having a middleware. It allows pre-processing, data formatting, data filtering or even connection to endpoints not exposed through HTTP (e.g: databases). Multiple middleware cookbooks are available describing an example implementation path, such as [Azure](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_middleware_azure_function), [GCP](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_middleware_google_cloud_function) and [AWS](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_middleware_aws_function).
## Give us feedback
Are there integrations that you’d like us to prioritize? Are there errors in our integrations? File a PR or issue on the cookbook page's github, and we’ll take a look.
## Contribute to our library
If you’re interested in contributing to our library, please follow the below guidelines, then submit a PR in github for us to review. In general, follow the template similar to [this example GPT Action](https://developers.openai.com/cookbook/examples/chatgpt/gpt_actions_library/gpt_action_bigquery).
Guidelines - include the following sections:
- Application Information - describe the 3rd party application, and include a link to app website and API docs
- Custom GPT Instructions - include the exact instructions to be included in a Custom GPT
- OpenAPI Schema - include the exact OpenAPI schema to be included in the GPT Action
- Authentication Instructions - for OAuth, include the exact set of items (authorization URL, token URL, scope, etc.); also include instructions on how to write the callback URL in the application (as well as any other steps)
- FAQ and Troubleshooting - what are common pitfalls that users may encounter? Write them here and workarounds
## Disclaimers
This action library is meant to be a guide for interacting with 3rd parties that OpenAI have no control over. These 3rd parties may change their API settings or configurations, and OpenAI cannot guarantee these Actions will work in perpetuity. Please see them as a starting point.
This guide is meant for developers and people with comfort writing API calls. Non-technical users will likely find these steps challenging.
---
# Production notes on GPT Actions
## Rate limits
Consider implementing rate limiting on the API endpoints you expose. ChatGPT will respect 429 response codes and dynamically back off from sending requests to your action after receiving a certain number of 429's or 500's in a short period of time.
## Timeouts
When making API calls during the actions experience, timeouts take place if the following thresholds are exceeded:
- 45 seconds round trip for API calls
## Use TLS and HTTPS
All traffic to your action must use TLS 1.2 or later on port 443 with a valid public certificate.
## IP egress ranges
ChatGPT will call your action from an IP address from one of the [CIDR blocks](https://en.wikipedia.org/wiki/Classless_Inter-Domain_Routing) listed in [chatgpt-connectors.json](https://openai.com/chatgpt-connectors.json)
You may wish to explicitly allowlist these IP addresses. This list is updated automatically periodically.
## Multiple authentication schemas
When defining an action, you can mix a single authentication type (OAuth or API key) along with endpoints that do not require authentication.
You can learn more about action authentication on our [actions authentication page](https://developers.openai.com/api/docs/actions/authentication).
## Open API specification limits
Keep in mind the following limits in your OpenAPI specification, which are subject to change:
- 300 characters max for each API endpoint description/summary field in API specification
- 700 characters max for each API parameter description field in API specification
## Additional limitations
There are a few limitations to be aware of when building with actions:
- Custom headers are not supported
- With the exception of Google, Microsoft and Adobe OAuth domains, all domains used in an OAuth flow must be the same as the domain used for the primary endpoints
- Request and response payloads must be less than 100,000 characters each
- Requests timeout after 45 seconds
- Requests and responses can only contain text (no images or video)
## Consequential flag
In the OpenAPI specification, you can now set certain endpoints as "consequential" as shown below:
```yaml
paths:
/todo:
get:
operationId: getTODOs
description: Fetches items in a TODO list from the API.
security: []
post:
operationId: updateTODOs
description: Mutates the TODO list.
x-openai-isConsequential: true
```
A good example of a consequential action is booking a hotel room and paying for it on behalf of a user.
- If the `x-openai-isConsequential` field is `true`, ChatGPT treats the operation as "must always prompt the user for confirmation before running" and don't show an "always allow" button (both are features of GPTs designed to give builders and users more control over actions).
- If the `x-openai-isConsequential` field is `false`, ChatGPT shows the "always allow button".
- If the field isn't present, ChatGPT defaults all GET operations to `false` and all other operations to `true`
## Best practices on feeding examples
Here are some best practices to follow when writing your GPT instructions and descriptions in your schema, as well as when designing your API responses:
1. Your descriptions should not encourage the GPT to use the action when the user hasn't asked for your action's particular category of service.
_Bad example_:
> Whenever the user mentions any type of task, ask if they would like to use the TODO action to add something to their todo list.
_Good example_:
> The TODO list can add, remove and view the user's TODOs.
2. Your descriptions should not prescribe specific triggers for the GPT to use the action. ChatGPT is designed to use your action automatically when appropriate.
_Bad example_:
> When the user mentions a task, respond with "Would you like me to add this to your TODO list? Say 'yes' to continue."
_Good example_:
> [no instructions needed for this]
3. Action responses from an API should return raw data instead of natural language responses unless it's necessary. The GPT will provide its own natural language response using the returned data.
_Bad example_:
> I was able to find your todo list! You have 2 todos: get groceries and walk the dog. I can add more todos if you'd like!
_Good example_:
> \{ "todos": [ "get groceries", "walk the dog" ] }
## How GPT Action data is used
GPT Actions connect ChatGPT to external apps. If a user interacts with a GPT’s custom action, ChatGPT may send parts of their conversation to the action’s endpoint.
If you have questions or run into additional limitations, you can join the discussion on the [OpenAI developer forum](https://community.openai.com).
---
# Sending and returning files with GPT Actions
## Sending files
POST requests can include up to ten files (including DALL-E generated images) from the conversation. They will be sent as URLs which are valid for five minutes.
For files to be part of your POST request, the parameter must be named `openaiFileIdRefs` and the description should explain to the model the type and quantity of the files which your API is expecting.
The `openaiFileIdRefs` parameter will be populated with an array of JSON objects. Each object contains:
- `name` The name of the file. This will be an auto generated name when created by DALL-E.
- `id` A stable identifier for the file.
- `mime_type` The mime type of the file. For user uploaded files this is based on file extension.
- `download_link` The URL to fetch the file which is valid for five minutes.
Here’s an example of an `openaiFileIdRefs` array with two elements:
```json
[
{
"name": "dalle-Lh2tg7WuosbyR9hk",
"id": "file-XFlOqJYTPBPwMZE3IopCBv1Z",
"mime_type": "image/webp",
"download_link": "https://files.oaiusercontent.com/file-XFlOqJYTPBPwMZE3IopCBv1Z?se=2024-03-11T20%3A29%3A52Z&sp=r&sv=2021-08-06&sr=b&rscc=max-age%3D31536000%2C%20immutable&rscd=attachment%3B%20filename%3Da580bae6-ea30-478e-a3e2-1f6c06c3e02f.webp&sig=ZPWol5eXACxU1O9azLwRNgKVidCe%2BwgMOc/TdrPGYII%3D"
},
{
"name": "2023 Benefits Booklet.pdf",
"id": "file-s5nX7o4junn2ig0J84r8Q0Ew",
"mime_type": "application/pdf",
"download_link": "https://files.oaiusercontent.com/file-s5nX7o4junn2ig0J84r8Q0Ew?se=2024-03-11T20%3A29%3A52Z&sp=r&sv=2021-08-06&sr=b&rscc=max-age%3D299%2C%20immutable&rscd=attachment%3B%20filename%3D2023%2520Benefits%2520Booklet.pdf&sig=Ivhviy%2BrgoyUjxZ%2BingpwtUwsA4%2BWaRfXy8ru9AfcII%3D"
}
]
```
Actions can include files uploaded by the user, images generated by DALL-E, and files created by Code Interpreter.
### OpenAPI Example
```yaml
/createWidget:
post:
operationId: createWidget
summary: Creates a widget based on an image.
description: Uploads a file reference using its file id. This file should be an image created by DALL·E or uploaded by the user. JPG, WEBP, and PNG are supported for widget creation.
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
openaiFileIdRefs:
type: array
items:
type: string
```
While this schema shows `openaiFileIdRefs` as being an array of type `string`, at runtime this will be populated with an array of JSON objects as previously shown.
## Returning files
Requests may return up to 10 files. Each file may be up to 10 MB and cannot be an image or video.
These files will become part of the conversation similarly to if a user uploaded them, meaning they may be made available to code interpreter, file search, and sent as part of subsequent action invocations. In the web app users will see that the files have been returned and can download them.
To return files, the body of the response must contain an `openaiFileResponse` parameter. This parameter must always be an array and must be populated in one of two ways.
### Inline option
Each element of the array is a JSON object which contains:
- `name` The name of the file. This will be visible to the user.
- `mime_type` The MIME type of the file. This is used to determine eligibility and which features have access to the file.
- `content` The base64 encoded contents of the file.
Here’s an example of an openaiFileResponse array with two elements:
```json
[
{
"name": "example_document.pdf",
"mime_type": "application/pdf",
"content": "JVBERi0xLjQKJcfsj6IKNSAwIG9iago8PC9MZW5ndGggNiAwIFIvRmlsdGVyIC9GbGF0ZURlY29kZT4+CnN0cmVhbQpHhD93PQplbmRzdHJlYW0KZW5kb2JqCg=="
},
{
"name": "sample_spreadsheet.csv",
"mime_type": "text/csv",
"content": "iVBORw0KGgoAAAANSUhEUgAAAAUAAAAFCAYAAACNbyblAAAAHElEQVQI12P4//8/w38GIAXDIBKE0DHxgljNBAAO9TXL0Y4OHwAAAABJRU5ErkJggg=="
}
]
```
OpenAPI example
```yaml
/papers:
get:
operationId: findPapers
summary: Retrieve PDFs of relevant academic papers.
description: Provided an academic topic, up to five relevant papers will be returned as PDFs.
parameters:
- in: query
name: topic
required: true
schema:
type: string
description: The topic the papers should be about.
responses:
"200":
description: Zero to five academic paper PDFs
content:
application/json:
schema:
type: object
properties:
openaiFileResponse:
type: array
items:
type: object
properties:
name:
type: string
description: The name of the file.
mime_type:
type: string
description: The MIME type of the file.
content:
type: string
format: byte
description: The content of the file in base64 encoding.
```
### URL option
Each element of the array is a URL referencing a file to be downloaded. The headers `Content-Disposition` and `Content-Type` must be set such that a file name and MIME type can be determined. The name of the file will be visible to the user. The MIME type of the file determines eligibility and which features have access to the file.
There is a 10 second timeout for fetching each file.
Here’s an example of an `openaiFileResponse` array with two elements:
```json
[
"https://example.com/f/dca89f18-16d4-4a65-8ea2-ededced01646",
"https://example.com/f/01fad6b0-635b-4803-a583-0f678b2e6153"
]
```
Here’s an example of the required headers for each URL:
```
Content-Type: application/pdf
Content-Disposition: attachment; filename="example_document.pdf"
```
OpenAPI example
```yaml
/papers:
get:
operationId: findPapers
summary: Retrieve PDFs of relevant academic papers.
description: Provided an academic topic, up to five relevant papers will be returned as PDFs.
parameters:
- in: query
name: topic
required: true
schema:
type: string
description: The topic the papers should be about.
responses:
'200':
description: Zero to five academic paper PDFs
content:
application/json:
schema:
type: object
properties:
openaiFileResponse:
type: array
items:
type: string
format: uri
description: URLs to fetch the files.
```
---
# Assistants API deep dive
export const snippetFileCreate = {
python: `
file = client.files.create(
file=open("revenue-forecast.csv", "rb"),
purpose='assistants'
)
`.trim(),
"node.js": `
const file = await openai.files.create({
file: fs.createReadStream("revenue-forecast.csv"),
purpose: "assistants",
});
`.trim(),
curl: `
curl https://api.openai.com/v1/files \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-F purpose="assistants" \\
-F file="@revenue-forecast.csv"
`.trim(),
};
export const snippetAssistantCreation = {
python: `
assistant = client.beta.assistants.create(
name="Data visualizer",
description="You are great at creating beautiful data visualizations. You analyze data present in .csv files, understand trends, and come up with data visualizations relevant to those trends. You also share a brief text summary of the trends observed.",
model="gpt-4o",
tools=[{"type": "code_interpreter"}],
tool_resources={
"code_interpreter": {
"file_ids": [file.id]
}
}
)
`.trim(),
"node.js": `
const assistant = await openai.beta.assistants.create({
name: "Data visualizer",
description: "You are great at creating beautiful data visualizations. You analyze data present in .csv files, understand trends, and come up with data visualizations relevant to those trends. You also share a brief text summary of the trends observed.",
model: "gpt-4o",
tools: [{"type": "code_interpreter"}],
tool_resources: {
"code_interpreter": {
"file_ids": [file.id]
}
}
});
`.trim(),
curl: `
curl https://api.openai.com/v1/assistants \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-H "OpenAI-Beta: assistants=v2" \\
-d '{
"name": "Data visualizer",
"description": "You are great at creating beautiful data visualizations. You analyze data present in .csv files, understand trends, and come up with data visualizations relevant to those trends. You also share a brief text summary of the trends observed.",
"model": "gpt-4o",
"tools": [{"type": "code_interpreter"}],
"tool_resources": {
"code_interpreter": {
"file_ids": ["file-BK7bzQj3FfZFXr7DbL6xJwfo"]
}
}
}'
`.trim(),
};
export const snippetThreadCreation = {
python: `
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": "Create 3 data visualizations based on the trends in this file.",
"attachments": [
{
"file_id": file.id,
"tools": [{"type": "code_interpreter"}]
}
]
}
]
)
`.trim(),
"node.js": `
const thread = await openai.beta.threads.create({
messages: [
{
"role": "user",
"content": "Create 3 data visualizations based on the trends in this file.",
"attachments": [
{
file_id: file.id,
tools: [{type: "code_interpreter"}]
}
]
}
]
});
`.trim(),
curl: `
curl https://api.openai.com/v1/threads \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-H "OpenAI-Beta: assistants=v2" \\
-d '{
"messages": [
{
"role": "user",
"content": "Create 3 data visualizations based on the trends in this file.",
"attachments": [
{
"file_id": "file-ACq8OjcLQm2eIG0BvRM4z5qX",
"tools": [{"type": "code_interpreter"}]
}
]
}
]
}'
`.trim(),
};
export const snippetImageCreation = {
python: `
file = client.files.create(
file=open("myimage.png", "rb"),
purpose="vision"
)
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the difference between these images?"
},
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.png"}
},
{
"type": "image_file",
"image_file": {"file_id": file.id}
},
],
}
]
)
`.trim(),
"node.js": `
const file = await openai.files.create({
file: fs.createReadStream("myimage.png"),
purpose: "vision",
});
const thread = await openai.beta.threads.create({
messages: [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the difference between these images?"
},
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.png"}
},
{
"type": "image_file",
"image_file": {"file_id": file.id}
},
]
}
]
});
`.trim(),
curl: `
# Upload a file with an "vision" purpose
curl https://api.openai.com/v1/files \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-F purpose="vision" \\
-F file="@/path/to/myimage.png"
## Pass the file ID in the content
curl https://api.openai.com/v1/threads \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-H "OpenAI-Beta: assistants=v2" \\
-d '{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the difference between these images?"
},
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.png"}
},
{
"type": "image_file",
"image_file": {"file_id": file.id}
}
]
}
]
}'
`.trim(),
};
export const snippetLowHighFidelity = {
python: `
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is this an image of?"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png",
"detail": "high"
}
},
],
}
]
)
`.trim(),
"node.js": `
const thread = await openai.beta.threads.create({
messages: [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is this an image of?"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png",
"detail": "high"
}
},
]
}
]
});
`.trim(),
curl: `
curl https://api.openai.com/v1/threads \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-H "OpenAI-Beta: assistants=v2" \\
-d '{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is this an image of?"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png",
"detail": "high"
}
},
]
}
]
}'
`.trim(),
};
export const snippetMessageAnnotations = {
python: `
# Retrieve the message object
message = client.beta.threads.messages.retrieve(
thread_id="...",
message_id="..."
)
# Extract the message content
message_content = message.content[0].text
annotations = message_content.annotations
citations = []
# Iterate over the annotations and add footnotes
for index, annotation in enumerate(annotations): # Replace the text with a footnote
message_content.value = message_content.value.replace(annotation.text, f' [{index}]')
# Gather citations based on annotation attributes
if (file_citation := getattr(annotation, 'file_citation', None)):
cited_file = client.files.retrieve(file_citation.file_id)
citations.append(f'[{index}] {file_citation.quote} from {cited_file.filename}')
elif (file_path := getattr(annotation, 'file_path', None)):
cited_file = client.files.retrieve(file_path.file_id)
citations.append(f'[{index}] Click