

With GPT-5 out in the world, we wanted to give some more context on the best way to integrate it, the Responses API, and why Responses is tailor-made for reasoning models and the agentic future.
Every generation of OpenAI APIs has been built around the same question: what’s the simplest, most powerful way for developers to talk to models?
Our API design has always been guided by how the models themselves work. The very first /v1/completions endpoint was simple, but limiting: you gave the model a prompt, and it would simply finish your thought. Through techniques like few-shot prompting, developers could attempt to guide the model to do things like output JSON and answer questions, but these models were much less capable than what we are used to today.
Then came RLHF, ChatGPT, and the post‑training era. Suddenly models weren’t just finishing your half‑written prose—they were responding like a conversational partner. To keep up, we built /v1/chat/completions (famously in a single weekend). By giving roles like system, user, assistant, we provided scaffolding to quickly build chat interfaces with custom instructions and context.
Our models kept getting better. Soon, they began to see, hear, and speak. Function-calling in late 2023 turned out to be one of our most‑loved features. Around the same time we launched the Assistants API in beta: our first attempt at a fully agentic interface with hosted tools like code interpreter and file search. Some developers liked it, but it never achieved mass adoption due to an API design that was limiting and hard to adopt relative to Chat Completions.
By late 2024 it was obvious we needed a unification: something as approachable as Chat Completions, as powerful as Assistants, but also purpose built for multimodal and reasoning models. Enter /v1/responses.
/v1/responses is an agentic loop
Chat Completions gave you a simple turn‑based chat interface. Responses instead gives you a structured loop for reasoning and acting. Think of it like working with a detective: you give them evidence, they investigate, they may consult experts (tools), and finally they report back. The detective keeps their private notes (reasoning state) between steps, but never hands them to the client.
And here’s where reasoning models really shine: Responses preserves the model’s reasoning state across those turns. In Chat Completions, reasoning is dropped between calls, like the detective forgetting the clues every time they leave the room. Responses keeps the notebook open; step‑by‑step thought processes actually survive into the next turn. That shows up in benchmarks (TAUBench +5%) and in more efficient cache utilization and latency.
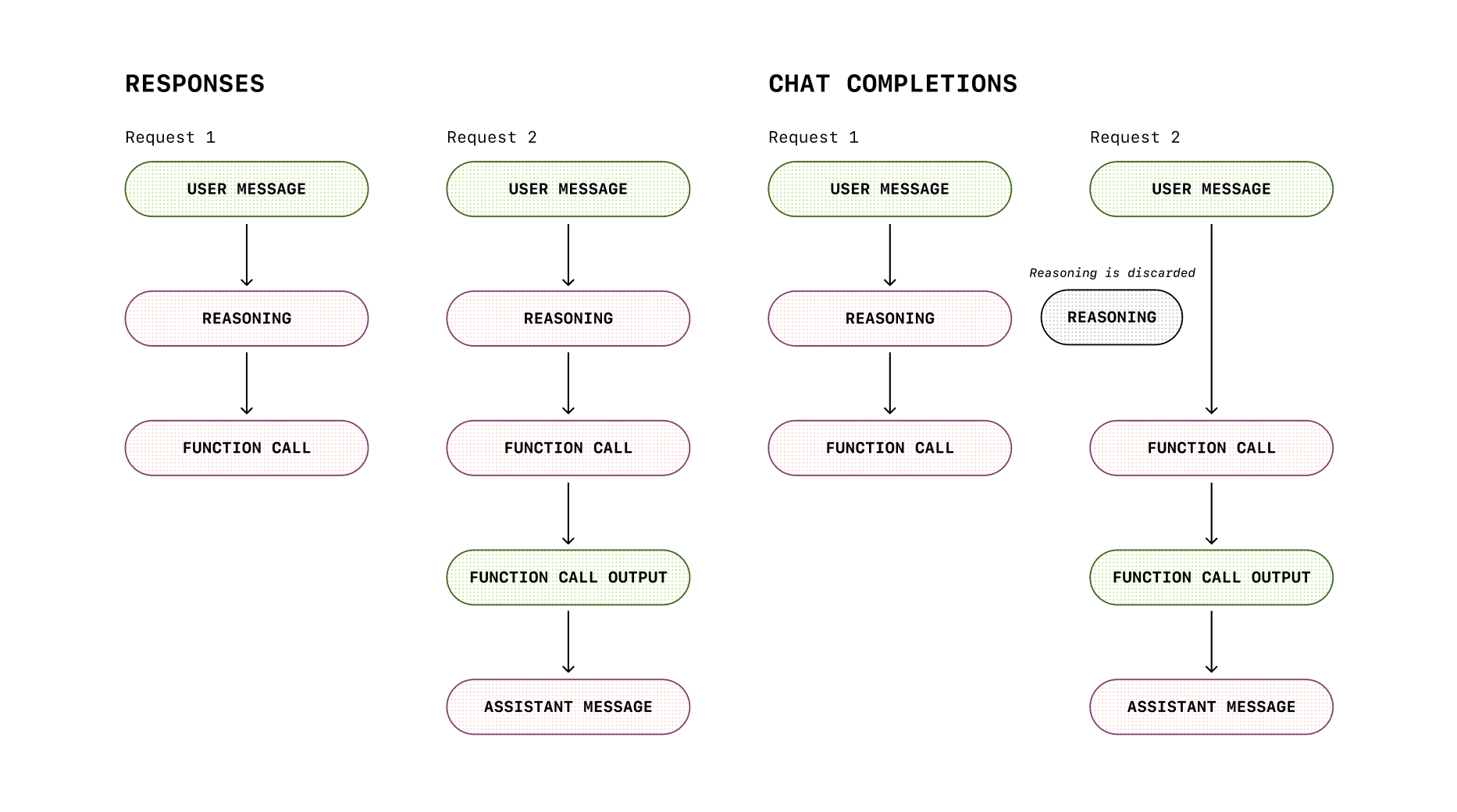
Responses can also emit multiple output items: not just what the model said, but what it did. You get receipts—tool calls, structured outputs, intermediate steps. It’s like getting both the finished essay and the scratchpad math. Useful for debugging, auditing, and building richer UIs.
{
"message": {
"role": "assistant",
"content": "I'm going to use the get_weather tool to find the weather.",
"tool_calls": [
{
"id": "call_88O3ElkW2RrSdRTNeeP1PZkm",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"location\":\"New York, NY\",\"unit\":\"f\"}"
}
}
],
"refusal": null,
"annotations": []
}
} {
"id": "rs_6888f6d0606c819aa8205ecee386963f0e683233d39188e7",
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "**Determining weather response**\n\nI need to answer the user's question about the weather in San Francisco. ...."
},
},
{
"id": "msg_6888f6d83acc819a978b51e772f0a5f40e683233d39188e7",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"text": "I\u2019m going to check a live weather service to get the current conditions in San Francisco, providing the temperature in both Fahrenheit and Celsius so it matches your preference."
}
],
"role": "assistant"
},
{
"id": "fc_6888f6d86e28819aaaa1ba69cca766b70e683233d39188e7",
"type": "function_call",
"status": "completed",
"arguments": "{\"location\":\"San Francisco, CA\",\"unit\":\"f\"}",
"call_id": "call_XOnF4B9DvB8EJVB3JvWnGg83",
"name": "get_weather"
},Moving up the stack with hosted tools
In the early days of function calling we noticed a key pattern: developers were using the model to both invoke APIs and also to search document stores to bring in external data sources–now known as RAG. But if you’re a developer just getting started, building a retrieval pipeline from scratch is a daunting and expensive endeavor. With Assistants, we introduced our first hosted tools: file_search and code_interpreter , allowing the model to do RAG and write code to solve the problems you asked of it. In Responses, we’ve gone even further, adding web search, image gen, and MCP. And because tool execution happens server‑side through hosted tools like code interpreter or MCP, you’re not bouncing every call back through your own backend, ensuring better latency and round‑trip costs.
Preserving reasoning safely
So why go through all this trouble to obfuscate the model’s raw chain-of-thought (CoT)? Wouldn’t it be easier to just expose the CoT and let the clients treat them similar to other model outputs? The short answer is that exposing raw CoT has a number of risks: such as hallucinations, harmful content that wouldn’t be generated in a final response, and for OpenAI, opens up competitive risks.
When we released o1-preview late last year, our Chief Scientist Jakub Pachocki wrote this in our blog:
We believe that a hidden chain of thought presents a unique opportunity for monitoring models. Assuming it is faithful and legible, the hidden chain of thought allows us to “read the mind” of the model and understand its thought process. For example, in the future we may wish to monitor the chain of thought for signs of manipulating the user. However, for this to work the model must have freedom to express its thoughts in unaltered form, so we cannot train any policy compliance or user preferences onto the chain of thought. We also do not want to make an unaligned chain of thought directly visible to users.
Responses addresses this by:
- Preserving reasoning internally, encrypted and hidden from the client.
- Allowing safe continuation via
previous_response_idor reasoning items, without exposing raw CoT.
Why /v1/responses is the best way to build
We designed Responses to be stateful, multimodal, and efficient.
- Agentic tool-use: The Responses API makes it easy to supercharge agentic workflows with tools like File Search, Image Gen, Code Interpreter, and MCP.
- Stateful-by-default. Conversations and tool state are tracked automatically. This makes reasoning and multi-turn workflows dramatically easier. GPT-5 integrated via Responses scores 5% better on TAUBench compared to Chat Completions, purely by taking advantage of preserved reasoning.
- Multimodal from the ground up. Text, images, audio, function calls—all first-class citizens. We didn’t bolt modalities onto a text API; we designed the house with enough bedrooms from day one.
- Lower costs, better performance. Internal benchmarks show 40–80% better cache utilization compared to Chat Completions. That means lower latency and lower costs.
- Better design: We learned a lot from both the Chat Completions and Assistants APIs and made a number of small quality of life improvements in the ResponsesAPI and SDK, including
- Semantic streaming events.
- Internally-tagged polymorphism.
output_texthelpers in the SDK (no morechoices.[0].message.content).- Better organization of multimodal and reasoning params.
What about Chat Completions?
Chat Completions isn’t going away. If it works for you, keep using it. But if you want reasoning that persists, multimodal interactions that feel native, and an agentic loop that doesn’t require duct tape—Responses is the way forward.
Looking ahead
Just as Chat Completions replaced Completions, we expect Responses to become the default way developers build with OpenAI models. It’s simple when you need it to be, powerful when you want it to be, and flexible enough to handle whatever the next paradigm throws at us.
This is the API we’ll be building on for the years ahead.