

AI audio capabilities unlock an exciting new frontier of user experiences. Earlier this year we released several new audio models, including gpt-realtime, along with new API features to enable developers to build these experiences.
Last week, we released new audio model snapshots designed to address some of the common challenges in building reliable audio agents by improving reliability and quality across production voice workflows–from transcription and text-to-speech to real-time, natively speech-to-speech agents.
These updates include:
gpt-4o-mini-transcribe-2025-12-15for speech-to-text with the Transcription or Realtime APIgpt-4o-mini-tts-2025-12-15for text-to-speech with the Speech APIgpt-realtime-mini-2025-12-15for native, real-time speech-to-speech with the Realtime APIgpt-audio-mini-2025-12-15for native speech-to-speech with the Chat Completions API
The new snapshots share a few common improvements:
With audio input:
- Lower word-error rates for real-world and noisy audio
- Fewer hallucinations during silence or with background noise
With audio output:
- More natural and stable voice output, including when using Custom Voices
Pricing remains the same as previous model snapshots, so we recommend switching to these new snapshots to benefit from improved performance for the same price.
If you’re building voice agents, customer support systems, or branded voice experiences, these updates will help you make production deployments more reliable. Below, we’ll break down what’s new and how these improvements show up in real-world voice workflows.
Speech-to-speech
We’re deploying new Realtime mini and Audio mini models that have been optimized for better tool calling and instruction following. These models reduce the intelligence gap between the mini and full-size models, enabling some applications to optimize cost by moving to the mini model.
gpt-realtime-mini-2025-12-15
The gpt-realtime-mini model is meant to be used with the Realtime API, our API for low-latency, native multi-modal interactions. It supports features like streaming audio in and out, handling interruptions (with optional voice activity detection), and function calling in the background while the model keeps talking.
The new Realtime mini snapshot is better suited for real-time agents, with clear gains in instruction following and tool calling. On our internal speech-to-speech evaluations, we’ve seen an improvement of 18.6 percentage points in instruction-following accuracy and 12.9 percentage points in tool-calling accuracy compared to the previous snapshot, as well as an improvement on the Big Bench Audio benchmark.
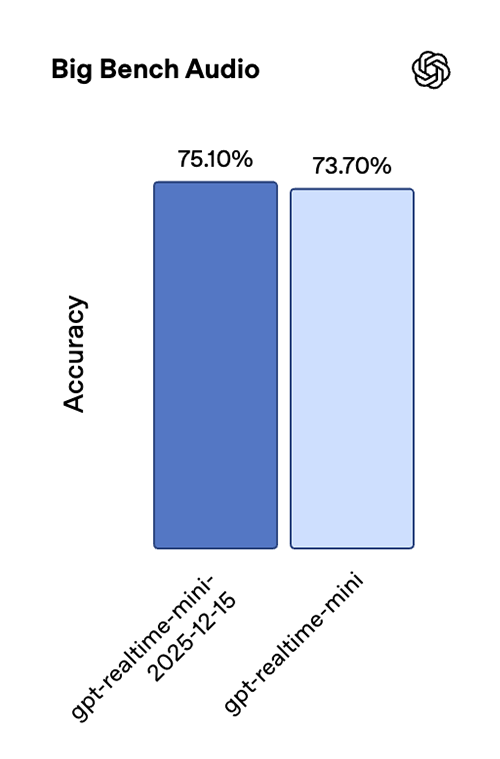
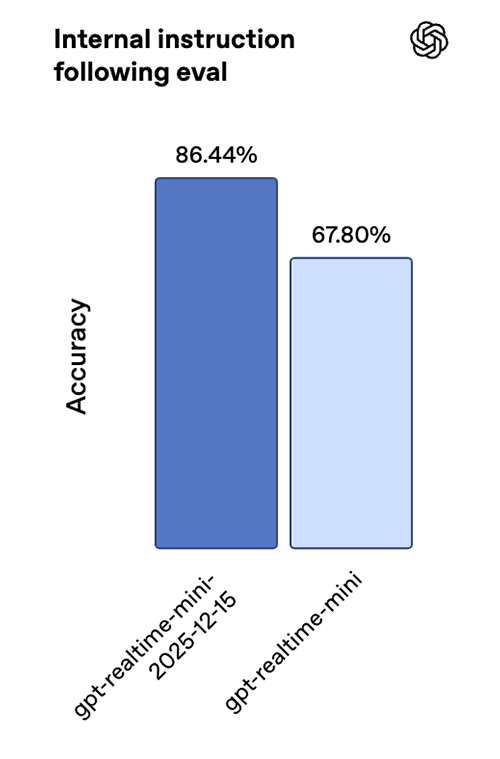
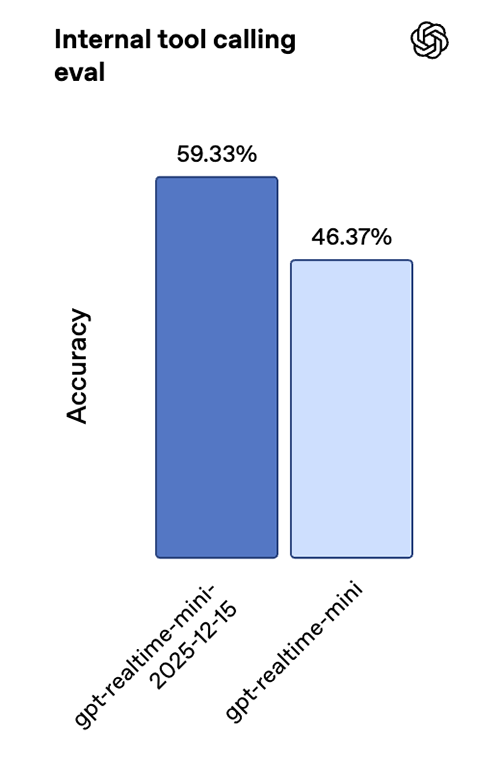
Together, these gains lead to more reliable multi-step interactions and more consistent function execution in live, low-latency settings.
For scenarios where agent accuracy is worth a higher cost, gpt-realtime remains our best performing model. But when cost and latency matter most, gpt-realtime-mini is a great option, performing well on real-world scenarios.
For example, Genspark stress-tested it on bilingual translation and intelligent intent routing, and in addition to the improved voice quality, they found the latency to be near-instant, while keeping the intent recognition spot-on throughout rapid exchanges.
gpt-audio-mini-2025-12-15
The gpt-audio-mini model can be used with the Chat Completions API for speech-to-speech use cases where real-time interaction isn’t a requirement.
Both new snapshots also feature an upgraded decoder for more natural sounding voices, and better maintain voice consistency when used with Custom Voices.
Text-to-speech
Our latest text-to-speech model, gpt-4o-mini-tts-2025-12-15, delivers a significant jump in accuracy, with substantially lower word error rates across standard speech benchmarks compared to the previous generation. On Common Voice and FLEURS, we see roughly 35% lower WER, with consistent gains on Multilingual LibriSpeech as well.
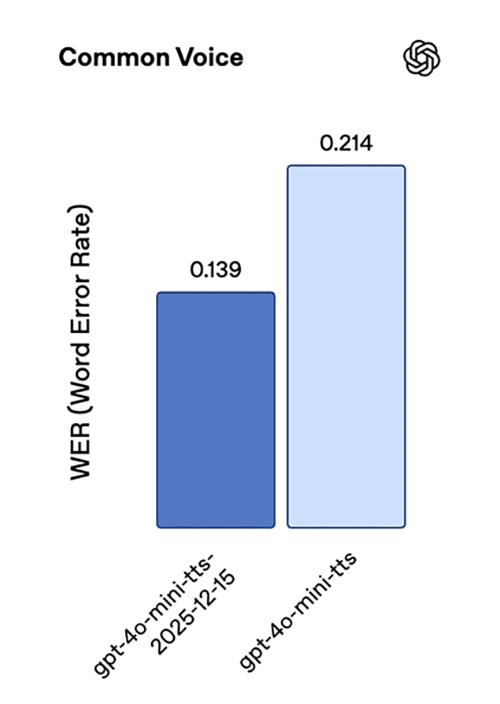
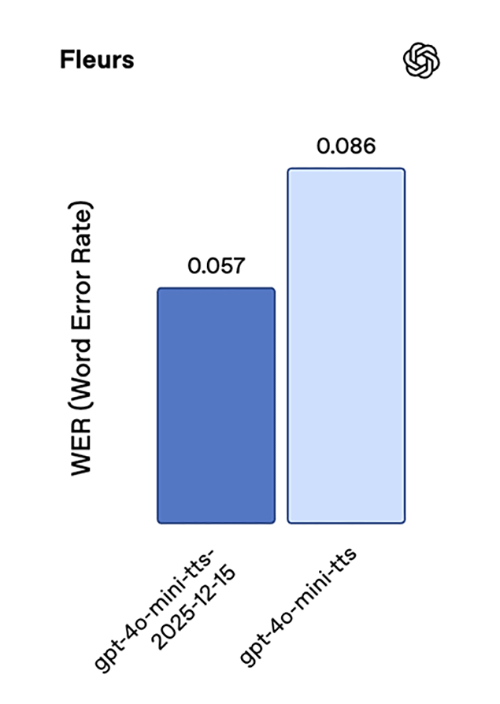
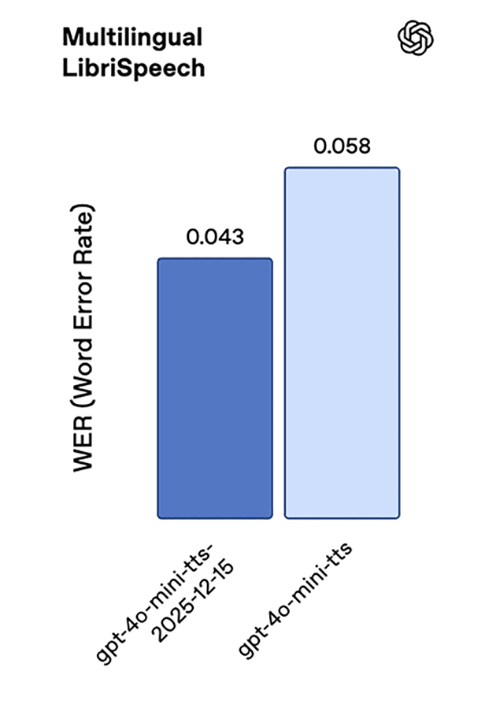
Together, these results reflect improved pronunciation accuracy and robustness across a wide range of languages.
Similar to the new gpt-realtime-mini snapshot, this model sounds much more natural and performs better with Custom Voices.
Speech-to-text
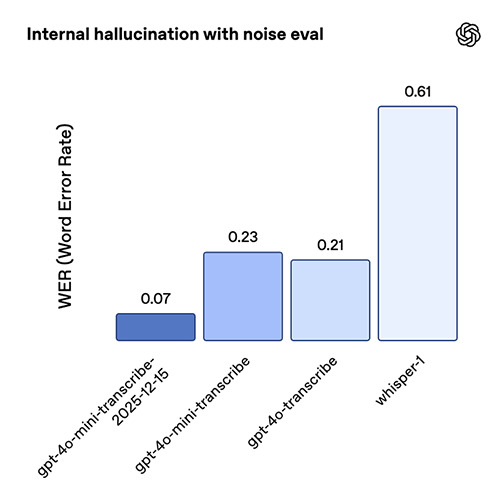
The latest transcription model, gpt-4o-mini-transcribe-2025-12-15, shows strong gains in both accuracy and reliability. On standard ASR benchmarks like Common Voice and FLEURS (without language hints), it delivers lower word error rates than prior models. We’ve optimized this model for behavior on real-world conversational settings, such as short user utterances and noisy backgrounds. In an internal hallucination-with-noise evaluation, where we played clips of real-world background noise and audio with varying speaking intervals (including silence), the model produced ~90% fewer hallucinations compared to Whisper v2 and ~70% fewer compared to previous GPT-4o-transcribe models.
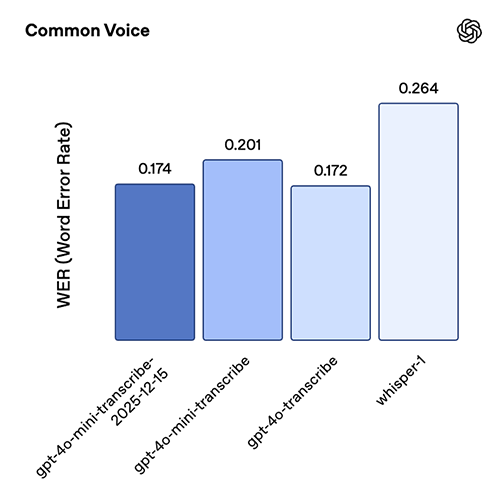
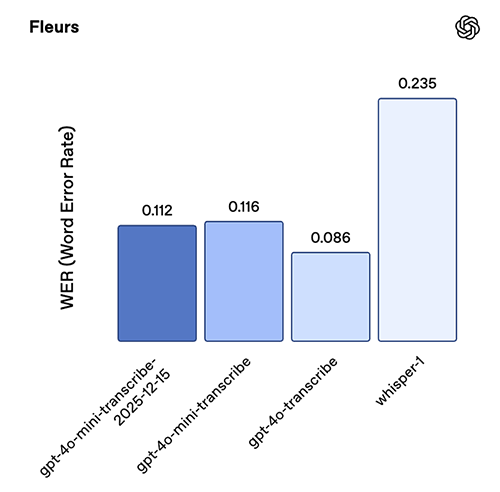
This model snapshot is particularly strong in Chinese (Mandarin), Hindi, Bengali, Japanese, Indonesian, and Italian.
Custom Voices
Custom Voices enable organizations to connect with customers in their unique brand voice. Whether you’re building a customer support agent or a brand avatar, OpenAI’s custom voice technology makes it easy to create distinct, realistic voices.
Theese new speech-to-speech and text-to-speech models unlock improvements for custom voices such as more natural tones, increased faithfulness to the original sample, and improved accuracy across dialects.
To ensure safe use of this technology, Custom Voices are limited to eligible customers. Contact your account director or reach out to our sales team to learn more.
From prototype to production
Voice apps tend to fail in the same places, mainly on long conversations or with edge cases like silence, and tool-driven flows where the voice agent needs to be precise. These updates are focused on those failure modes—lower error rates, fewer hallucinations, more consistent tool use, better instruction following. And as a bonus, we’ve improved the stability of the output audio so your voice experiences can sound more natural.
If you’re shipping voice experiences today, we recommend moving to the new 2025-12-15 snapshots and re-running your key production test cases.
Early testers have confirmed noticeable improvements without changing their instructions and simply switching to the new snapshots, but we recommend experimenting with your own use cases and adjusting your prompts as needed.