This document describes how Realtime API billing works and offers strategies for optimizing costs. Voice-agent sessions accrue input and output tokens across text, audio, and image modalities. Streaming translation and streaming transcription sessions are billed by audio duration. Prices vary per model, with prices listed on the model pages (for example, gpt-realtime-2, gpt-realtime-translate, gpt-realtime-whisper, and gpt-realtime).
Conversational Realtime API sessions are a series of turns, where the user adds input that triggers a Response to produce the model output. The server maintains a Conversation, which is a list of Items that form the input for the next turn. When a Response is returned, the output is automatically added to the Conversation.
Translation and transcription sessions use a different streaming architecture. The client streams audio continuously and receives translated audio, transcript deltas, or transcript events as the source audio arrives. These sessions don’t use the normal Response lifecycle, so estimate and monitor them with their duration-based rates instead of per-Response token usage.
Per-Response costs
Realtime API costs are accrued when a Response is created, and is charged based on the numbers of input and output tokens (except for input transcription costs, see below). There is no cost currently for network bandwidth or connections. A Response can be created manually or automatically if voice activity detection (VAD) is turned on. VAD will effectively filter out empty input audio, so empty audio doesn’t count as input tokens unless the client manually adds it as conversation input.
The entire conversation is sent to the model for each Response. The output from a turn will be added as Items to the server Conversation and become the input to subsequent turns, thus turns later in the session will be more expensive.
Text token costs can be estimated using our tokenization tools. Audio tokens in user messages are 1 token per 100 ms of audio, while audio tokens in assistant messages are 1 token per 50ms of audio. Note that token counts include special tokens aside from the content of a message which will surface as small variations in these counts, for example a user message with 10 text tokens of content may count as 12 tokens.
Example
Here’s a simple example to illustrate token costs over a multi-turn Realtime API session.
For the first turn in the conversation we’ve added 100 tokens of instructions, a user message of 20 audio tokens (for example added by VAD based on the user speaking), for a total of 120 input tokens. Creating a Response generates an assistant output message (20 audio, 10 text tokens).
Then we create a second turn with another user audio message. What will the tokens for turn 2 look like? The Conversation at this point includes the initial instructions, first user message, the output assistant message from the first turn, plus the second user message (25 audio tokens). This turn will have 110 text and 64 audio tokens for input, plus the output tokens of another assistant output message.
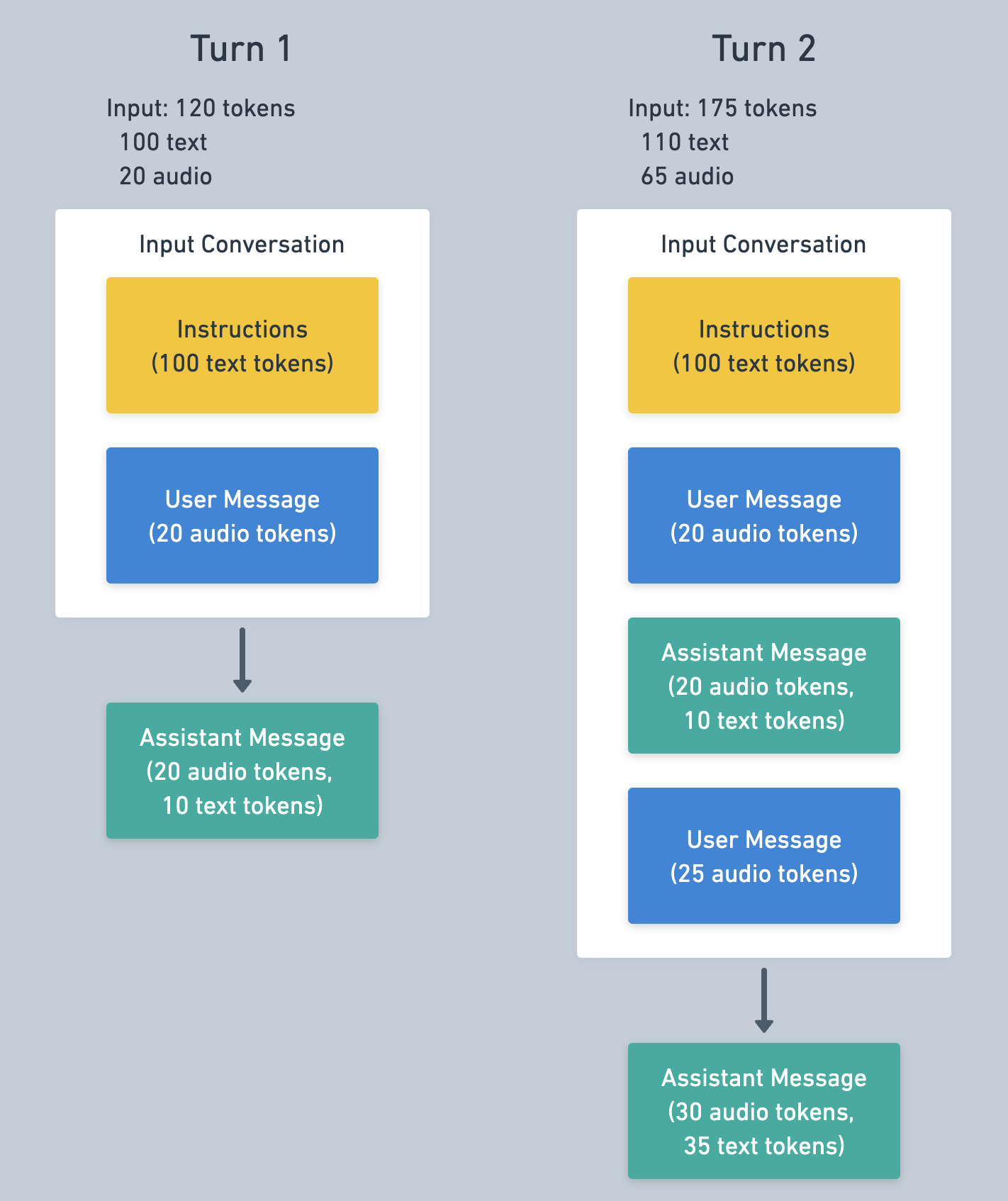
The messages from the first turn are likely to be cached for turn 2, which reduces the input cost. See below for more information on caching.
The tokens used for a Response can be read from the response.done event, which looks like the following.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
{
"type": "response.done",
"response": {
...
"usage": {
"total_tokens": 253,
"input_tokens": 132,
"output_tokens": 121,
"input_token_details": {
"text_tokens": 119,
"audio_tokens": 13,
"image_tokens": 0,
"cached_tokens": 64,
"cached_tokens_details": {
"text_tokens": 64,
"audio_tokens": 0,
"image_tokens": 0
}
},
"output_token_details": {
"text_tokens": 30,
"audio_tokens": 91
}
}
}
}Input transcription costs
Aside from conversational Responses, the Realtime API bills for input transcriptions, if enabled. Input transcription uses a different model than the speech2speech model, such as whisper-1 or gpt-4o-transcribe, and thus are billed from a different rate card. Transcription is performed when audio is written to the input audio buffer and then committed, either manually or by VAD.
Input transcription token counts can be read from the conversation.item.input_audio_transcription.completed event, as in the following example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
{
"type": "conversation.item.input_audio_transcription.completed",
...
"transcript": "Hi, can you hear me?",
"usage": {
"type": "tokens",
"total_tokens": 26,
"input_tokens": 17,
"input_token_details": {
"text_tokens": 0,
"audio_tokens": 17
},
"output_tokens": 9
}
}Caching
Realtime API supports prompt caching, which is applied automatically and can dramatically reduce the costs of input tokens during multi-turn sessions. Caching applies when the input tokens of a Response match tokens from a previous Response, though this is best-effort and not guaranteed.
The best strategy for maximizing cache rate is keep a session’s history static. Removing or changing content in the conversation will “bust” the cache up to the point of the change — the input no longer matches as much as before. Note that instructions and tool definitions are at the beginning of a conversation, thus changing these mid-session will reduce the cache rate for subsequent turns.
Truncation
When the number of tokens in a conversation exceeds the model’s input token limit the conversation be truncated, meaning messages (starting from the oldest) will be dropped from the Response input. A 32k context model with 4,096 max output tokens can only include 28,224 tokens in the context before truncation occurs.
Clients can set a smaller token window than the model’s maximum, which is a good way to control token usage and cost. This is controlled with the token_limits.post_instructions configuration (if you configure truncation with a retention_ratio type as shown below). As the name indicates, this controls the maximum number of input tokens for a Response, except for the instruction tokens. Setting post_instructions to 1,000 means that items over the 1,000 input token limit won’t be sent to the model for a Response.
Truncation busts the cache near the beginning of the conversation, and if truncation occurs on every turn then cache rate will be very low. To mitigate this issue clients can configure truncation to drop more messages than necessary, which will extend the headroom before another truncation is needed. This can be controlled with the session.truncation.retention_ratio setting. The server defaults to a value of 1.0 , meaning truncation will remove only the items necessary. A value of 0.8 means a truncation would retain 80% of the maximum, dropping an additional 20%.
If you’re attempting to reduce Realtime API cost per session (for a given model), we recommend reducing limiting the number of tokens and setting a retention_ratio less than 1, as in the following example. Remember that there may be a tradeoff here in terms of lower cost but lower model memory for a given turn.
1
2
3
4
5
6
7
8
9
10
11
12
{
"event": "session.update",
"session": {
"truncation": {
"type": "retention_ratio",
"retention_ratio": 0.8,
"token_limits": {
"post_instructions": 8000
}
}
}
}Truncation can also be completely disabled, as shown below. When disabled an error will be returned if the Conversation is too long to create a Response. This may be useful if you intend to manage the Conversation size manually.
1
2
3
4
5
6
{
"event": "session.update",
"session": {
"truncation": "disabled"
}
}Other optimization strategies
Using a mini model
The Realtime speech2speech models come in a “normal” size and a mini size, which is significantly cheaper. The tradeoff here tends to be intelligence related to instruction following and function calling, which won’t be as effective in the mini model. We recommend first testing applications with the larger model, refining your application and prompt, then attempting to optimize using the mini model.
Editing the Conversation
While truncation will occur automatically on the server, another cost management strategy is to manually edit the Conversation. A principle of the API is to allow full client control of the server-side Conversation, allowing the client to add and remove items at will.
1
2
3
4
{
"type": "conversation.item.delete",
"item_id": "item_CCXLecNJVIVR2HUy3ABLj"
}Clearing out old messages is a good way to reduce input token sizes and cost. This might remove important content, but a common strategy is to replace these old messages with a summary. Items can be deleted from the Conversation with a conversation.item.delete message as above, and can be added with a conversation.item.create message.
Estimating costs
Given the complexity in Realtime API token usage it can be difficult to estimate your costs ahead of time. A good approach is to use the Realtime Playground with your intended prompts and functions, and measure the token usage over a sample session. The token usage for a session can be found under the Logs tab in the Realtime Playground next to the session id.